Pooledbytebufalocator is responsible for initializing PoolArena(PA) and PoolThreadCache(PTC). It provides a series of interfaces to create PooledByteBuf objects that use heap memory or direct memory. These interfaces are just a skin. PA and PTC capabilities are fully used internally. The initialization process is divided into two steps, first initializing a series of default parameters, then initializing the PTC object and PA array.
Default parameters and their values
Default [page] size: - pageSize of page in PoolChunk, set with - Dio.netty.allocator.pageSize, default: 8192.
Default menu Max menu order: height of binary tree in PoolChunk: maxOrder, set with - Dio.netty.allocator.maxOrder, default value: 11.
Default menu num heap arena: length of PA array using heap memory, set with - Dio.netty.allocator.numHeapArenas, default value: number of CPU cores * 2.
Default menu num menu direct menu arena: length of PA array using direct memory, set with - Dio.netty.allocator.numHeapArenas, default value: number of CPU cores * 2.
Default > Tiny > cache > size: the length of the queue in each MemoryRegionCache object used to cache Tiny memory in the PTC object. Use the - Dio.netty.allocator.tinyCacheSize setting, and the default value is 512.
Default? Small? Cache? Size: the length of the queue in each MemoryRegionCache object used to cache small memory in the PTC object, set with - Dio.netty.allocator.smallCacheSize, default value: 256.
Default menu Normal menu cache menu size: the length of the queue in each MemoryRegionCache object used to cache Normal memory in the PTC object, set with - Dio.netty.allocator.normalCacheSize, default value: 64.
Default? Max? Cached? Buffer? Capacity: the maximum size of the cache Normal memory in the PTC object. Use the - Dio.netty.allocator.maxCachedBufferCapacity setting, the default value is 32 * 1024.
Default menu cache menu trim menu interval: the memory threshold in the PTC object to release the cache. When the number of times PTC allocates memory is greater than this value, the cache memory will be released. Use - Dio.netty.allocator.cacheTrimInterval setting, default: 8192.
Default use cache for all threads: whether to use cache for all threads. Use - Dio.netty.allocator.useCacheForAllThreads setting, default: true.
Default menu direct menu memory menu cache menu alignment: alignment parameter of direct memory. The size of allocated direct memory must be an integer multiple of it. Use the - Dio.netty.allocator.directMemoryCacheAlignment setting, default: 0, for misalignment.
Initialize PoolArena array
Pooledbytebufalocator maintains two arrays:
PoolArena<byte[]>[] heapArenas; PoolArena<ByteBuffer>[] directArenas;
heapArenas is used to manage heap memory and directarena is used to manage direct memory. These two arrays are initialized in the construction method, which is defined as:
public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder, int tinyCacheSize, int smallCacheSize, int normalCacheSize, boolean useCacheForAllThreads, int directMemoryCacheAlignment)
prefreDirect: whether direct memory is preferred when pooledbyebuf is created.
nHeapArena: default menu num heap arena is used by default.
nDirectArena: default menu num direct menu arena is used by default.
pageSize: default page size used by default.
maxOrder: default menu Max menu is used.
tinyCacheSize: default? Tiny? Cache? Size is used by default.
smallCacheSize: default? Small? Cache? Size is used by default.
normalCacheSize: default? Normal? Cache? Size is used by default.
useCacheForAllThreads: default use cache for all threads is used by default.
directMemoryCacheAlignment: default? Direct? Memory? Cache? Alignment is used by default.
The initialization codes of these two arrays are as follows:
1 int pageShifts = validateAndCalculatePageShifts(pageSize); 2 3 if (nHeapArena > 0) { 4 heapArenas = newArenaArray(nHeapArena); 5 List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(heapArenas.length); 6 for (int i = 0; i < heapArenas.length; i ++) { 7 PoolArena.HeapArena arena = new PoolArena.HeapArena(this, 8 pageSize, maxOrder, pageShifts, chunkSize, 9 directMemoryCacheAlignment); 10 heapArenas[i] = arena; 11 metrics.add(arena); 12 } 13 heapArenaMetrics = Collections.unmodifiableList(metrics); 14 } else { 15 heapArenas = null; 16 heapArenaMetrics = Collections.emptyList(); 17 } 18 19 if (nDirectArena > 0) { 20 directArenas = newArenaArray(nDirectArena); 21 List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(directArenas.length); 22 for (int i = 0; i < directArenas.length; i ++) { 23 PoolArena.DirectArena arena = new PoolArena.DirectArena( 24 this, pageSize, maxOrder, pageShifts, chunkSize, directMemoryCacheAlignment); 25 directArenas[i] = arena; 26 metrics.add(arena); 27 } 28 directArenaMetrics = Collections.unmodifiableList(metrics); 29 } else { 30 directArenas = null; 31 directArenaMetrics = Collections.emptyList(); 32 }
1 line, calculate pageShifts, the algorithm is pageShifts =? Integer.SIZE - 1 - Integer.numberOfLeadingZeros(pageSize) = 31 -? Integer.numberOfLeadingZeros(pageSize). Integer.numberOfLeadingZeros(pageSize) is the number of digits that pageSize(32-bit integer) is 0 from the highest order, so pageShifts can be simplified to pageShifts = log2(pageSize).
4,20 lines, create array, new PoolArena[size].
Line 6-12, line 22-17, initialize the PoolArena object in the array, and use two internal classes of PoolArena: heaparena and directarena.
Initialize PoolThreadCache
PoolThreadCache is indirectly initialized with PoolThreadLocalCache(PTLC), which is the internal part of pooledbytebufalocator. Its definition is as follows:
final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache>
This class is derived from io.netty.util.concurrent.fastthreadlocal < T >. Like java.lang.threadlocal < T >. It implements the function of thread local storage (TLS). The difference is that fastthreadlocal < T > optimizes access performance. PTLC overrides the parent class's initialValue method, which initializes the PoolThreadCache object local to the thread. This method is called the first time the get method of a PTLC object is called.
1 @Override 2 protected synchronized PoolThreadCache initialValue() { 3 final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas); 4 final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas); 5 6 if (useCacheForAllThreads || Thread.currentThread() instanceof FastThreadLocalThread) { 7 return new PoolThreadCache( 8 heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize, 9 DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL); 10 } 11 // No caching for non FastThreadLocalThreads. 12 return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0); 13 }
Line 3 and line 4, respectively, take a PoolArena object with the least number of uses from headarena and directarena. PoolArena has a numThreadCaches property, which is an atomic variable of type AtomicInteger. Its purpose is to record the number of times it is used by the poolthreadcache object. The PoolThreadCache object will call its getAndIncrement method in the construction method when it is created, and its getAndDecrement method will be invoked in the free0 method when it is released.
Line 6, if every thread runs with cache (userCacheForAllThreads==true), or if the thread object is FastThreadLocalThread, create a thread specific PTC object in line 8.
PoolChunkList(PCKL)
Key attributes
PoolChunkList<T> nextList
PoolChunkList<T> prevList
These two attributes indicate that the PCKL object is a node of a two-way linked list.
PoolChunk<T> head
This property indicates that the PCKL object also maintains a PCK type linked list, and the head points to the head of the linked list.
int minUsage;
int maxUsage;
int maxCapacity;
minUsage is the minimum memory usage of each PCK object in the PCK list, and maxusage is the maximum memory usage of PCK. These two values are percentages, for example: minUsage=10, maxUse=50, which means that only PCK objects with a usage rate of [10%, 50%) can be saved in the PCK list maxCapacity is the maximum amount of memory that PCK can allocate. The algorithm is: maxCapacity = (int)(chunkSize * (100L - minUseage) / 100L).
Initialize PCKL list
The PCKL linked list is maintained by PoolArena, which is initialized in the construction method of PoolArena:
1 // io.netty.buffer.PoolArena#PoolArena(PooledByteBufAllocator parent, int pageSize, 2 // int maxOrder, int pageShifts, int chunkSize, int cacheAlignment) 3 4 q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize); 5 q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize); 6 q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize); 7 q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize); 8 q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize); 9 qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize); 10 11 q100.prevList(q075); 12 q075.prevList(q050); 13 q050.prevList(q025); 14 q025.prevList(q000); 15 q000.prevList(null); 16 qInit.prevList(qInit);
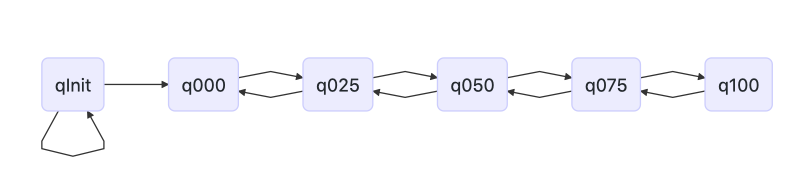
Line 4-9, initialize the PCKL node. The name of each node is q{num}, where num represents the minimum usage of this node, such as minUsage=%75 of q075 node.
Line 11-16, assemble the PCKL node into a linked list.
If q(minUsage, maxUsage) is used to represent a node, then:
qInit = q(Integer.MIN_VALUE, 25%)
q000 = q(1%, 50%)
q025 = q(25%, 75%)
q075 = q(75%, 100%)
q100 = q(100%, Integer.MAX_VALUE)
The structure of this list is shown in the following figure:
PoolChunk(PCK) moves in PoolChunkList(PCKL)
A newly created PCK object whose memory usage is usage=%0 is put into the qInit node. Every time memory is allocated from this PCK object, its usage will increase. When usage > = 25%, i.e. maxUsage greater than or equal to qInit, it will be moved to q000. Continue to allocate memory from the PCK object, and its usage continues to increase. When the usage is greater than or equal to the maxUsage of its PCKL, move it to the next node in the PKCL list until q100. Here is the code of PCK movement caused by memory allocation:
1 //io.netty.buffer.PoolChunkList#allocate 2 boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) { 3 if (head == null || normCapacity > maxCapacity) { 4 // Either this PoolChunkList is empty or the requested capacity is larger then the capacity which can 5 // be handled by the PoolChunks that are contained in this PoolChunkList. 6 return false; 7 } 8 9 for (PoolChunk<T> cur = head;;) { 10 long handle = cur.allocate(normCapacity); 11 if (handle < 0) { 12 cur = cur.next; 13 if (cur == null) { 14 return false; 15 } 16 } else { 17 cur.initBuf(buf, handle, reqCapacity); 18 if (cur.usage() >= maxUsage) { 19 remove(cur); 20 nextList.add(cur); 21 } 22 return true; 23 } 24 } 25 }
Lines 9-12, trying to allocate the required memory from all PCK nodes in the PCK linked list.
14 lines, no PCK node was found to allocate memory.
17 lines from the cur node to the required memory, and initializes the pooledbyebuf object.
The 18-21 row, such as the usage rate of the cur node is greater than or equal to the current PCKL node maxUsage, calls the remove method to delete cur from the head list, and then calls the add method of the next node in the PCKL list to move cur to the next node.
If the memory is released continuously and the memory is returned to the PCK object, the usage will continue to decrease. When the usage is less than the miniusage of the PCKL to which it belongs, move it to the previous node in the PCKL list until q000 bits. When freeing memory causes the usage of PCK object to be equal to% 0, this PCK object will be destroyed and the entire chunk memory will be freed. Here is the code that freeing memory causes PCK objects to move:
1 //io.netty.buffer.PoolChunkList#free 2 boolean free(PoolChunk<T> chunk, long handle) { 3 chunk.free(handle); 4 if (chunk.usage() < minUsage) { 5 remove(chunk); 6 // Move the PoolChunk down the PoolChunkList linked-list. 7 return move0(chunk); 8 } 9 return true; 10 } 11 12 //io.netty.buffer.PoolChunkList#move0 13 private boolean move0(PoolChunk<T> chunk) { 14 if (prevList == null) { 15 // There is no previous PoolChunkList so return false which result in having the PoolChunk destroyed and 16 // all memory associated with the PoolChunk will be released. 17 assert chunk.usage() == 0; 18 return false; 19 } 20 return prevList.move(chunk); 21 }
Line 3, release the memory and return the memory to the PCK object.
The 4-7 row, such as the usage rate of PCK, is less than the current PCKL minUsage. Calling remove method removes the PCK object from the current PCKL object, and then calls the move0 method to move it to the previous PCKL node.
Line 13-31, move PCK to the previous PCKL.
Complete memory allocation and release process
memory allocation
Entry method:
Io.netty.buffer.abstractbytebufalocator ා heapbuffer (int, int), create ByteBuf using heap memory, and call newHeapBuffer method.
Io.netty.buffer.abstractbytebufalocator ා directbuffer (int, int), create ByteBuf using direct memory, and call newDirectBuffer method.
Specific implementation:
io.netty.buffer.PooledByteBufAllocator#newHeapBuffer(int initialCapacity, int maxCapacity).
io.netty.buffer.PooledByteBufAllocator#newDirectBuffer(int initialCapacity, int maxCapacity).
The two methods are to get the thread specific PoolArena object from the PoolThreadCache object, and then call the allocate method of PoolArena to create the PoolByteBuf object.
PoolArena entry method:
Io.netty.buffer.PoolArena - allocate (io.netty.buffer.poolthreadcache, int, int). This method is the entry method for PoolArena to allocate memory and create PoolByteBuf objects. It first calls the newByteBuf implemented by the subclass to create a PoolByteBuf object. This method has two implementations:
Io.netty.buffer.poolarena.heaparena ා newbytebuf (int maxcapacity), to create PooledByteBuf objects that use heap memory.
Io.netty.buffer.poolarena.directarena - newbytebuf (int maxcapacity) to create a PooledByteBuf object using direct memory.
Then we call io.netty.buffer.PoolArena#allocate (io.netty.buffer.PoolThreadCache, io.netty.buffer.PooledByteBuf<T>, int) to allocate memory for PoolByteBuf objects, which is the core method of distributing memory.
1 private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) { 2 final int normCapacity = normalizeCapacity(reqCapacity); 3 if (isTinyOrSmall(normCapacity)) { // capacity < pageSize 4 int tableIdx; 5 PoolSubpage<T>[] table; 6 boolean tiny = isTiny(normCapacity); 7 if (tiny) { // < 512 8 if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) { 9 // was able to allocate out of the cache so move on 10 return; 11 } 12 tableIdx = tinyIdx(normCapacity); 13 table = tinySubpagePools; 14 } else { 15 if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) { 16 // was able to allocate out of the cache so move on 17 return; 18 } 19 tableIdx = smallIdx(normCapacity); 20 table = smallSubpagePools; 21 } 22 23 final PoolSubpage<T> head = table[tableIdx]; 24 25 /** 26 * Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and 27 * {@link PoolChunk#free(long)} may modify the doubly linked list as well. 28 */ 29 synchronized (head) { 30 final PoolSubpage<T> s = head.next; 31 if (s != head) { 32 assert s.doNotDestroy && s.elemSize == normCapacity; 33 long handle = s.allocate(); 34 assert handle >= 0; 35 s.chunk.initBufWithSubpage(buf, handle, reqCapacity); 36 incTinySmallAllocation(tiny); 37 return; 38 } 39 } 40 synchronized (this) { 41 allocateNormal(buf, reqCapacity, normCapacity); 42 } 43 44 incTinySmallAllocation(tiny); 45 return; 46 } 47 if (normCapacity <= chunkSize) { 48 if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) { 49 // was able to allocate out of the cache so move on 50 return; 51 } 52 synchronized (this) { 53 allocateNormal(buf, reqCapacity, normCapacity); 54 ++allocationsNormal; 55 } 56 } else { 57 // Huge allocations are never served via the cache so just call allocateHuge 58 allocateHuge(buf, reqCapacity); 59 } 60 }
Line 2: calculate the standard memory size that can be allocated, normCapacity, according to the required memory size, reqCapacity. It must meet the following requirements: (1) normCapacity > = reqCapacity; (2) normCapacity is an integral multiple of directMemoryCacheAlignment; in addition, it can be divided into three cases according to the size of reqCapacity:
Reqcapacity > = chunksize: normCapacity takes the minimum value that satisfies both (1) and (2).
Reqcapacity > = 512 and reqcapacity < chunksize: (3) normcapacity > = 512 * 2K, (4) normcapacity < = chunksize, normCapacit takes the minimum value that simultaneously satisfies (1), (2), (3), (4).
Reqcapacity < 412: (5) normCapacity < 512, (6) normCapacity is an integer multiple of 16. normCapacity takes the minimum value that satisfies (1), (2), (5), (6) at the same time.
8-13 lines to allocate Tiny type memory (< 512) Lines 8-10. If memory is allocated in the PoolThreadCache cache object, the internal allocation process ends. Lines 12-13, if not in the cache, allocate a piece of memory from the Tiny memory pool.
15-20 lines, allocate Small type memory (> = 512 and < PageSize). Same logic as allocating Tiny memory.
Line 29-27, use the index of Tiny or Small memory from the previous two steps to allocate a piece of memory from the subpage pool. 33 lines to allocate memory from subpages. Line 35. Initialize the PoolByteBuf object with the allocated memory. If you can get here, the process of allocating memory will end.
Line 41. If there is no memory available in the subpage pool, call the allocatenarmal method to allocate a subpage from the PoolChunk object, and then allocate the required memory from the subpage.
47-55 lines to allocate Normal type memory (> = PageSize and < chunksize). 48,49 lines, allocate memory from the cache. If successful, the process of allocating memory ends. 53 lines. There is no memory available in the cache. Call the allocadenormal method to allocate memory from PoolChunk.
58 lines, if memory > chunksize is allocated. This memory will not enter the PCKL list.
The allocatenarmal method in the above code encapsulates the logic of creating PCK objects, allocating memory from PCK objects, and then putting PCK objects into PCKL linked list, which is also very important code.
1 private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) { 2 if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) || 3 q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) || 4 q075.allocate(buf, reqCapacity, normCapacity)) { 5 return; 6 } 7 8 // Add a new chunk. 9 PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize); 10 long handle = c.allocate(normCapacity); 11 assert handle > 0; 12 c.initBuf(buf, handle, reqCapacity); 13 qInit.add(c); 14 }
Line 2-5, try to allocate memory from each PCKL node in turn. If successful, the process of allocating memory ends.
In lines 9-13, create a new PCK object, allocate memory from it, initialize PooledByteBuf object with memory, and add PCK object to qInit, the header node of PCKL chain. The add method of PKCL object will be the same as allocate method. According to the memory usage of PCK object, it will be moved to the appropriate location in the linked list.
Memory release
Io.netty.buffer.pooledbybuf ා deallocate method calls io.netty.buffer.poolarena ා free method, which is responsible for the whole memory release process.
1 void free(PoolChunk<T> chunk, long handle, int normCapacity, PoolThreadCache cache) { 2 if (chunk.unpooled) { 3 int size = chunk.chunkSize(); 4 destroyChunk(chunk); 5 activeBytesHuge.add(-size); 6 deallocationsHuge.increment(); 7 } else { 8 SizeClass sizeClass = sizeClass(normCapacity); 9 if (cache != null && cache.add(this, chunk, handle, normCapacity, sizeClass)) { 10 // cached so not free it. 11 return; 12 } 13 14 freeChunk(chunk, handle, sizeClass); 15 } 16 }
This code focuses on lines 8-14. In lines 8 and 9, the priority is to put the memory in the cache, so that the next time you can get it directly from the cache quickly. In line 14, the memory is returned to the PCK object if it cannot be put into the cache.
1 void freeChunk(PoolChunk<T> chunk, long handle, SizeClass sizeClass) { 2 final boolean destroyChunk; 3 synchronized (this) { 4 switch (sizeClass) { 5 case Normal: 6 ++deallocationsNormal; 7 break; 8 case Small: 9 ++deallocationsSmall; 10 break; 11 case Tiny: 12 ++deallocationsTiny; 13 break; 14 default: 15 throw new Error(); 16 } 17 destroyChunk = !chunk.parent.free(chunk, handle); 18 } 19 if (destroyChunk) { 20 // destroyChunk not need to be called while holding the synchronized lock. 21 destroyChunk(chunk); 22 } 23 }
In line 17, drop the free method of PCKL object to return the memory to PCK object, and move the PCK object in the PCKL list. If the PCK object's usage rate at this time becomes 0, destroyChunk=true.
Line 21, call the destroyChunk method to destroy the PCK object.