Brief introduction of fragmented cluster
As mentioned before, the replication set of MongoDB is mainly used to achieve automatic failover to achieve high availability. However, with the growth of business scale and the passage of time, the volume of business data will become larger and larger. Current business data may be less than several hundred GB. A DB server is enough to do all the work, and once the volume of business data expands a few TB. Hundreds of TBs, there will be a server can not store the situation, at this time, the need to allocate data according to certain rules to different servers for storage, query and so on, that is, fragmented cluster. The task of fragmented cluster is data distributed storage.
Piecewise deployment architecture
architecture design
Look at a picture first.

Let's start with some explanations:
1.shard slice: Generally, it is a single server, that is, a data storage node. This storage node needs to make a replica set to achieve high availability and automatic failover. Generally, a fragment cluster has several shard slices.
2. Configuration server: mainly records shard's configuration information (metadata), such as data storage directory, log directory, port number, whether journal is opened or not. In order to ensure the availability of config server, replication set processing is also done. Note that once the configuration server is not available, the whole cluster will not be able to use, generally three independent services. It implements redundant backups, each of which may be an independent replication set architecture.
3.Mongos routing process (Router): The application program connects router directly through the driver. When router starts, it reads shared information from the configuration server replication set, and then writes or reads the data into the specific shard.
Deployment configuration
Note: Since there is only one server (PC) on my side, the implementation here is a pseudo cluster. The deployment architecture is shown in the figure. 
A Shard (replicate set mode), a config process, and a router process are all on the same server
Following the replication set in the previous section as shard,
Start up:
mongod --dbpath=D:\MongoDB\Server\3.2\data\rs0_0 --logpath=D:\MongoDB\Server\3.2\logs\rs0_0.log --port=40000 --replSet=rs0
mongod --dbpath=D:\MongoDB\Server\3.2\data\rs0_1 --logpath=D:\MongoDB\Server\3.2\logs\rs0_1.log --port=40001 --replSet=rs0
mongod --dbpath=D:\MongoDB\Server\3.2\data\rs0_2 --logpath=D:\MongoDB\Server\3.2\logs\rs0_2.log --port=40002 --replSet=rs0Configuration server startup:
mongod --dbpath=D:\MongoDB\Server\3.2\data\db_config --logpath=D:\MongoDB\Server\3.2\logs\dbconfig.log --port=40003 --configsvrRouting server startup
mongos --logpath=D:\MongoDB\Server\3.2\logs\dbrouter.log --port=40004 --configdb=linfl-PC:40003Add fragmentation information to the cluster:
mongo --port 40004
mongos> use admin
switched to db admin
mongos> sh.addShard("rs0/linfl-PC:40000,linfl-PC:40001")
{
"ok" : 0,
"errmsg" : "can't add shard 'rs0/linfl-PC:40000,linfl-PC:40001' because a local database 'config' exists in another config",
"code" : 96
}Wrong report. Because the original rs0 already has config database, delete it:
D:\MongoDB\Server\3.2\bin>mongo --port 40000
2017-02-27T16:14:51.454+0800 I CONTROL [main] Hotfix KB2731284 or later update
is not installed, will zero-out data files
MongoDB shell version: 3.2.9
connecting to: 127.0.0.1:40000/test
rs0:PRIMARY> show dbs
cms 0.000GB
config 0.000GB
local 0.000GB
test 0.000GB
rs0:PRIMARY> use config
switched to db config
rs0:PRIMARY> db.dropDatabase()
{ "dropped" : "config", "ok" : 1 }Then reconnect to 4004 to execute adding fragments. Look at the status:
D:\MongoDB\Server\3.2\bin>mongo --port 40004
2017-02-27T16:15:17.286+0800 I CONTROL [main] Hotfix KB2731284 or later update
is not installed, will zero-out data files
MongoDB shell version: 3.2.9
connecting to: 127.0.0.1:40004/test
mongos> sh.addShard("rs0/linfl-PC:40000,linfl-PC:40001")
{ "shardAdded" : "rs0", "ok" : 1 }
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("58b3d9df84493cb599359c8b")
}
shards:
{ "_id" : "rs0", "host" : "rs0/linfl-PC:40000,linfl-PC:40001" }
active mongoses:
"3.2.9" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 5
Last reported error: remote client 192.168.56.1:51845 tried to initiali
ze this host as shard rs0, but shard name was previously initialized as config
Time of Reported error: Mon Feb 27 2017 16:15:48 GMT+0800
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "cms", "primary" : "rs0", "partitioned" : false }
{ "_id" : "test", "primary" : "rs0", "partitioned" : false }
Explain the various collections in the config database as follows:
mongos> use config
switched to db config
mongos> show collections
actionlog //
changelog //Any metadata change information that holds the fragmented collection, such as chunks migration, segmentation, etc.
chunks //All the block information in the cluster, the data range of the block and the slice where the block is located
databases //All databases in the cluster
lockpings //Tracking Activated Components in Clusters
locks//Lock information generated by equalizer
mongos//All routing information
settings//Configuration information of fragmented cluster, such as chunk size, equalizer status, etc.
shards//All slice information in the cluster
tags
version//Meta Information VersionNote: Cluster operations should be performed through client connection to mongos routing.
Normally, a complete production environment requires at least nine Mongod instances, one Mongos instance and 10 machines to compose. Because some instances can be deployed on a single machine (with lower resource consumption or different types of resource consumption), typical deployment structures can be obtained as follows:
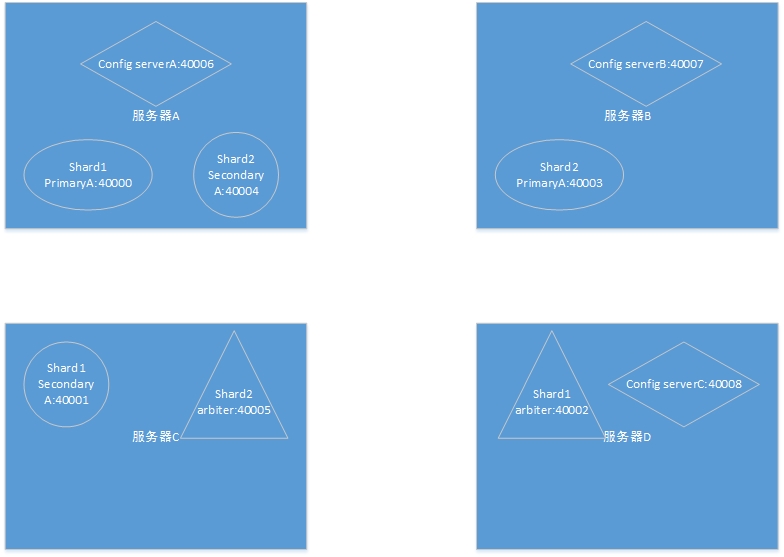
The above deployment scheme makes the nodes in each shard (replica set) completely separate to different servers, and separates the config services, so that any one of the servers is down and the cluster can work properly. Of course, I think that only three servers are needed to form a stable cluster (3 bad 1 can work properly), but it is not a typical architecture.
Fragmentation mechanism
MongoDB fragmentation is based on collections (tables). To fragment a collection, it is necessary to support fragmentation as if the database in which it is located.
Set fragmentation
MongoDB fragmentation is based on returning, that is, any document must be within a certain range of the specified slice key. Once a single key is selected, chunks will logically combine a portion of the documents according to the slice key.
For example, select city as the slice key for users set. If there are `beijing', `guangzhou', `changsha'in the city field, the document is randomly inserted into the cluster at the beginning. Because the initial chunks are relatively small, it does not reach the threshold of 64MB or 10000 documents, and it does not need to be sliced. As the insertion continues, after exceeding the threshold of chunk, the chunk is divided into two, and finally it can be divided step by step. It can be shown as follows:
Start key - end key - in fragmentation
Fragmentation where the start and end keys are located
| Start key value | End key value | Segmentation |
|---|---|---|
| -∞ | beijing | rs0 |
| beijing | changsha | rs1 |
| changsha | guangzhou | rs0 |
| guangzhou | ∞ | rs1 |
It should be noted that the documents contained in chunks are not physically contained, but are logically contained. The indicator is that documents with slice keys fall within that range.
To enable collection support fragmentation, database support fragmentation must first be enabled:
sh.enableSharding('cms')
For existing collections to be fragmented, after choosing a slice key, you need to create an index on the slice key first, and automatically create an index if the initial state of the collection is empty.
Looking at rs.status(), you can see the following information fragments:
databases:
{ "_id" : "cms", "primary" : "rs0", "partitioned" : true }
{ "_id" : "test", "primary" : "rs0", "partitioned" : false }
Prove that cms already supports fragmentation
Fragmentation in Existing Collections
First create the index:
db.user.ensureIndex({city:1})
sh.shardCollection("cms.users",{city:1})Note: Because I'm a single PC, I can't see the effect after slicing, but if there are two slices, rs0 and rs1, inserting data into users, the final result will be as follows:

adopt
db.changelog.find()We can see the specific process of block segmentation. When the storage chunk is less than 64MB, it is not divided. When the storage chunk is greater than 64MB, it begins to be divided into two parts, - beijing,beijing with the further increase of data, Beijing is continued to be divided into beijing~guangzhou,guangzhou so that rs0 has three chunks, and then, - to Beijing chunk begins to shift from rs0. Move to rs1, and by analogy, MongDB implements distributed storage of massive data.
Cluster Balancer
In the last step, we talked about the migration of block chunk from rs0 to rs1, which is done automatically by the background process of the balancer.
When all chunks of a fragmented set are unevenly distributed in the cluster (e.g. 200 chunks on rs0 and 50 on rs1), the balancer moves chunks from the largest to the smallest, until the number of chunks is basically equal. The balancer will trigger block migration according to different rules according to the number of chunks. The default configuration is chunk < 20, the threshold is 2, 20 < chunk < 79, the threshold is 4, chunk > 80, and the threshold is 8. This is why we just need to see the change of the migration process when chunk is 3.
The basic chunk migration process is as follows:
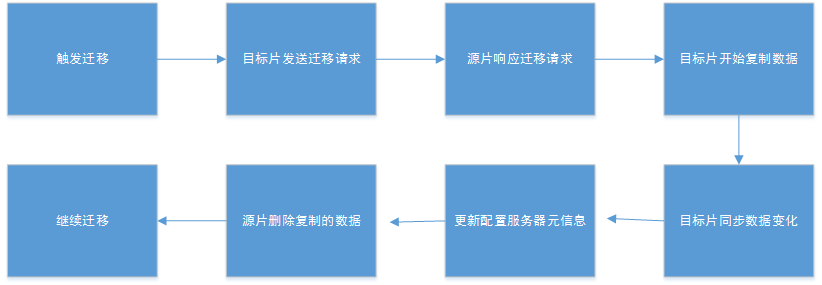
In this example, the source slice refers to rs0 and the target slice refers to rs1.
Writing and Reading of Clusters
Cluster read and write is the same as a single MongoDB read and write. It is transparent to applications. Here we mainly see the impact of fragmented cluster on performance.
Slice keys are the basis for deciding which chunk the query falls on. This information is stored on the configuration server, and the index is for the collection on each slice. Each slice will create index data for its collection. Therefore, whether the query statement contains slice keys and indexes has a great impact on query performance.
There are several points that need to be noted when performing the view through the explain explanation:
nscanned: Number of documents scanned in the index when the index is used for queries
nscannedObjects: Number of documents scanned in a collection
Nscanned AllPlans: Total number of documents scanned in all query plans
nscanned: Total number of documents scanned under a selected query plan
Chip Key Selection Strategy
A good chip bond should have the following characteristics:
- Distribution write operation
- Read operations should not be too randomized (as localized as possible)
- Ensure that chunk s are always partitioned
Usually, we need to combine several fields as slice keys, such as city+_id, to ensure that documents under the same city are distributed as far as possible on the same slice, and _id ensures that chunk s can be segmented all the time.
In practical business, we can consider that company_id and create_date or ID in order table make up a chip key.
Be careful
Fragmentation clustering is suitable only when there is a large amount of data and a high request for reading and writing.
Reference link
https://docs.mongodb.com/manual/core/sharded-cluster-components