Persistent data structures can store all historical versions of data structures and reduce time and space consumption by reusing data. That is, after each operation, only the modified part is copied and reused for other parts, so that all the historical structure states of the data structure can be recorded efficiently
The following explains the persistent segment tree
1 weighted segment tree
It is similar to the segment tree, except that the stored contents are different, that is, the number of stored in each interval is stored in each interval after each operation
Note: the root node interval represents the maximum and minimum
Example: for array \ (a[]={(3,1,4,2,3,5,3,4)} \)
Save the line segment tree one by one as follows (all saved):
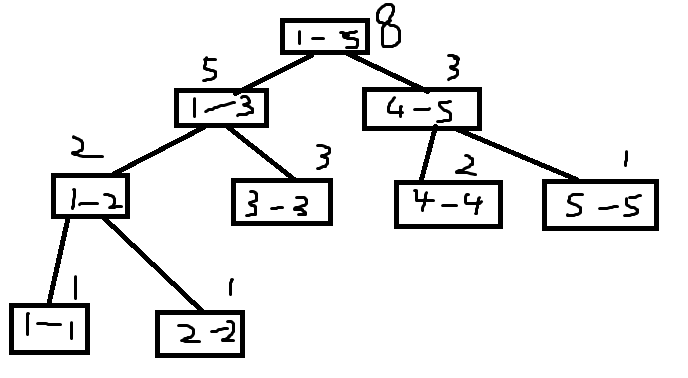
Save 5 numbers as follows:
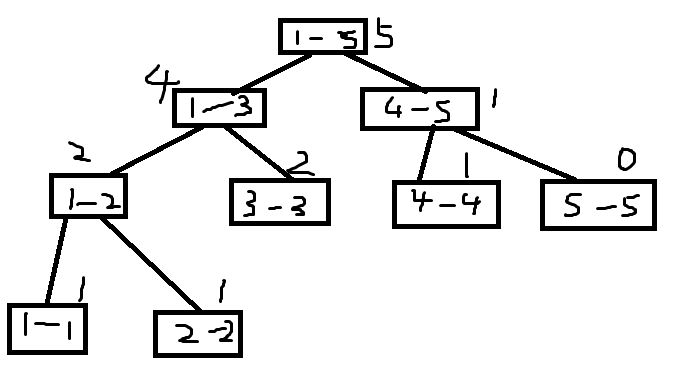
You can see that the sequence tree of \ ([6,8] \) can be obtained by subtracting the fifth tree from the eighth tree, that is \ (5,3,4 \)
It can be seen that it is actually prefix and thought

2 sustainable segment tree
The weight segment tree is also used for storage
The first state \ (rt[0] \) is the tree root -- all are assigned 0
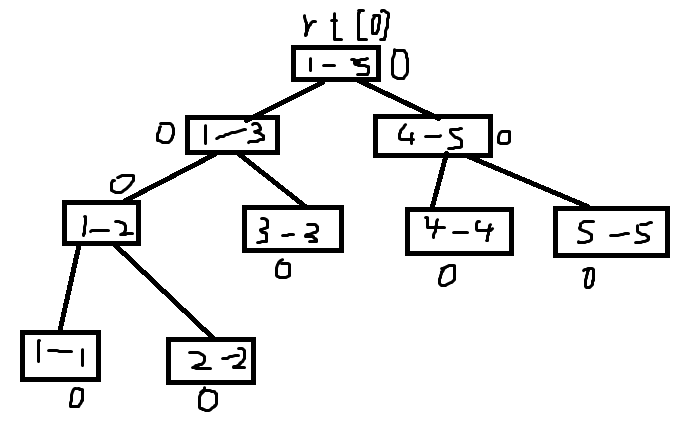
Insert the elements into the segment tree one by one to get a new tree with \ (rt[1], rt[2],... rt[n] \) as the root node, and connect with the previous one, that is, expand to the right
When you want to query the segment tree after the third element is inserted, you only need to start from the third tree \ (rt[3] \)
Small operation: array discretization
After entering the sequence \ (a \), copy a copy to \ (b \), sort \ (b \), and then use a new function
sort(b+1,b+n+1); int tot=unique(b+1,b+n+1)-b-1;
You can get the number of sequence elements after de duplication
meanwhile
lower_bound(b+1,b+tot+1,a[i])-b;//Find the subscript of the first element greater than or equal to a[i] in b []
That is, insert the subscript of \ (a[i] \) into the line segment tree (for each number of \ (a[i] \), find its position in \ (b [] \)
Then you can start creating a sustainable segment tree
for(int i=1,i<=n;i++) update(rt[i],rt[i-1],1,tot,lower_bound(b+1,b+tot+1,a[i])-b);
Insert operation
int cnt=0;
void update(int &i,int j,int l,int r,int k){//Insert element k
i=++cnt;
t[i]=t[j];//Copy previous version
t[i].num++;//Number of elements++
if(l==r) return ;
if(k<=mid) update(lc,Lc,l,mid,k);//lc and rc represent the left and right nodes of t[i]
else update(rc,Rc,mid+1,r,k);//Lc and Rc represent the left and right child nodes of t[j]
}
Examples Interval k decimal
In this problem, copy the n numbers first, remove the duplication in sorting, insert the subscript in \ (b [] \) of each number of \ (a[i] \) into the chairman tree, and start the query when entering \ (l,r,k \)
while(m--){
scanf("%d%d%d",&l,&r,&k);
cout<<b[query(rt[l-1],rt[r],1,tot,k)]<<endl;
}
Start from the tree roots \ (rt[r] \) and \ (rt[l-1] \). If \ (l==r \), return \ (L \); Then subtract the weights of the left subtree of the current two nodes to obtain \ (s \), indicating that the interval of a sequence \ ([l,r] \) has inserted the number of \ (s \). If \ (k < = s \), indicating that K is in a small range, find it in the left subtree. On the contrary, indicating that K is in a large range, find the number k-s smaller in the right subtree (that is, find the subscript of the kth decimal of \ ([l,r] \) in the chairman tree in \ (b [] \) (the range of the left subtree is always smaller than that of the right subtree)
Query code:
int query(int i,int j,int l,int r,int k){//Note that the returned subscript is also the stored subscript
if(l==r) return l;
int s=t[Lc].num-t[lc].num;
if(k<=s) return query(lc,Lc,l,mid,k);
else return query(rc,Rc,mid+1,r,k-s);
}
Total code:
#include<bits/stdc++.h>
#define lc t[i].ch[0]
#define rc t[i].ch[1]
#define Lc t[j].ch[0]
#define Rc t[j].ch[1]
#define mid (l+r>>1)
#define N 200005
using namespace std;
int a[N],b[N];
int cnt,rt[N];
struct tree{
int num,ch[2];
}t[N*20];
void update(int &i,int j,int l,int r,int k){
i=++cnt;
t[i]=t[j];
t[i].num++;
if(l==r) return ;
if(k<=mid) update(lc,Lc,l,mid,k);//lc and rc represent the left and right nodes of t[i]
else update(rc,Rc,mid+1,r,k);//Lc and Rc represent the left and right child nodes of t[j]
}
int query(int i,int j,int l,int r,int k){
if(l==r) return l;
int s=t[Lc].num-t[lc].num;
if(k<=s) return query(lc,Lc,l,mid,k);
else return query(rc,Rc,mid+1,r,k-s);
}
int main(){
int n,m;
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
b[i]=a[i];
}
sort(b+1,b+n+1);
int tot=unique(b+1,b+n+1)-b-1;
cnt=0,rt[0]=0;
for(int i=1;i<=n;i++)
update(rt[i],rt[i-1],1,tot,lower_bound(b+1,b+tot+1,a[i])-b);
int l,r,k;
while(m--){
scanf("%d%d%d",&l,&r,&k);
cout<<b[query(rt[l-1],rt[r],1,tot,k)]<<endl;
}
return 0;
}
Thanks for watching
PS.
