- 📢 Blog home page: https://blog.csdn.net/as604049322
- 📢 Welcome to praise 👍 Collection ⭐ Leaving a message. 📝 Welcome to discuss!
- 📢 This article was originally created by Xiaoming code entity and was first launched in CSDN 🙉
- 📢 The future is long, and it is worth our efforts to go to a better life ✨
At the end of last year, I shared how to extract text from the specified area of PDF through python. See the following for details:
Take a screenshot of the specified area of pdf and extract the text
https://blog.csdn.net/as604049322/article/details/111939952
We still need to feel when constantly testing the area range with code. Imagine that if we can develop an imaging tool and directly select the extraction area with the mouse frame, there will be too much accuracy and there is no need for continuous testing.
After several days of research, it will not wxpython finally realize a very simplified image PDF region selection and extraction tool. The overall effect is as follows:
Function introduction
After opening the software, the interface is as follows:
Click the open file button to open the previous PDF file. The effect is as follows:
After the selected area is framed, the text extracted from the currently selected area will be automatically displayed in the title bar. You can also switch between the left and right buttons:
In fact, there may be more than one area where we need to extract text, so the program supports multi area box selection:
After selecting the area box, you can click save file to save the text extracted from each page of PDF to a csv file. The saving results of the current selection are as follows:
You can see that the strings of each region have been saved in the order of box selection.
If the extraction result is found to be inaccurate when selecting an area, you can cancel and reselect:
Saving a picture will save the whole page of the PDF as a picture. If no area is selected, save the picture with the page number as the file name:
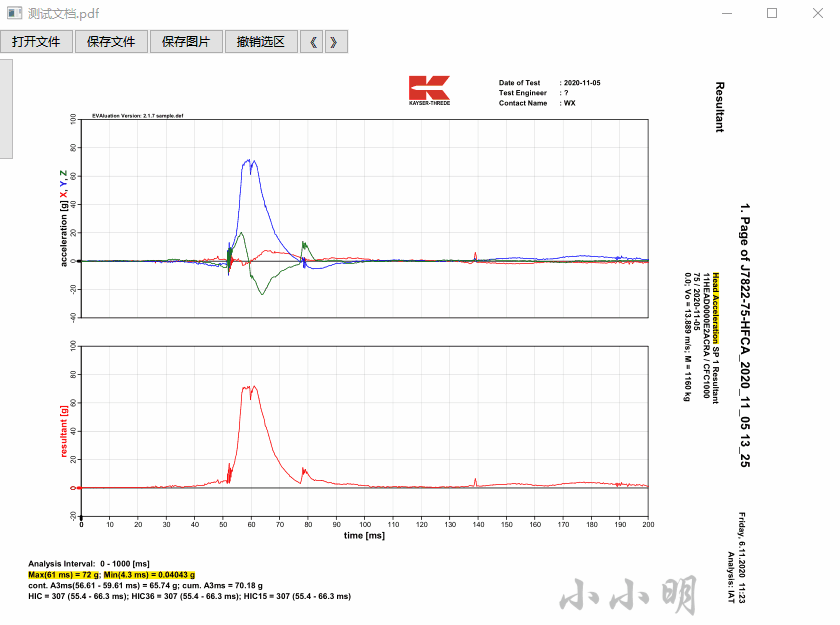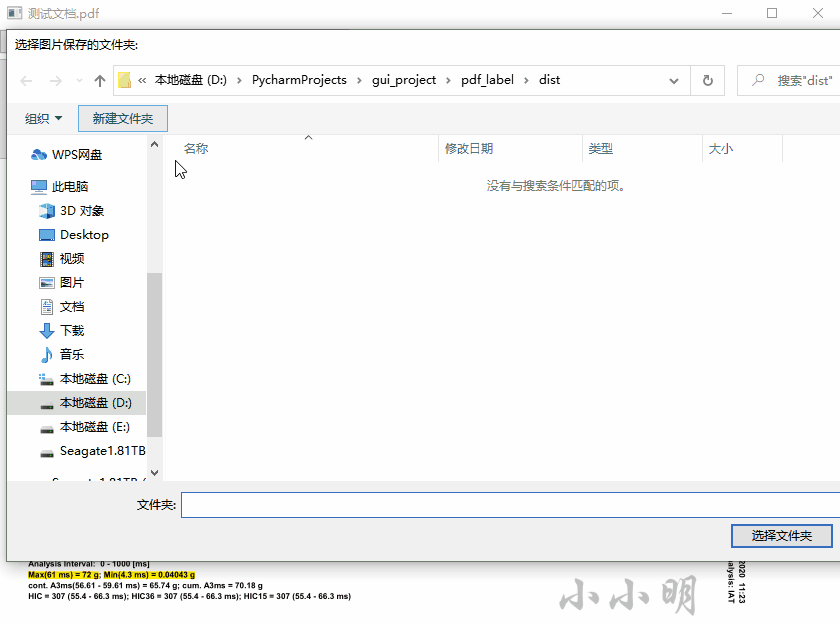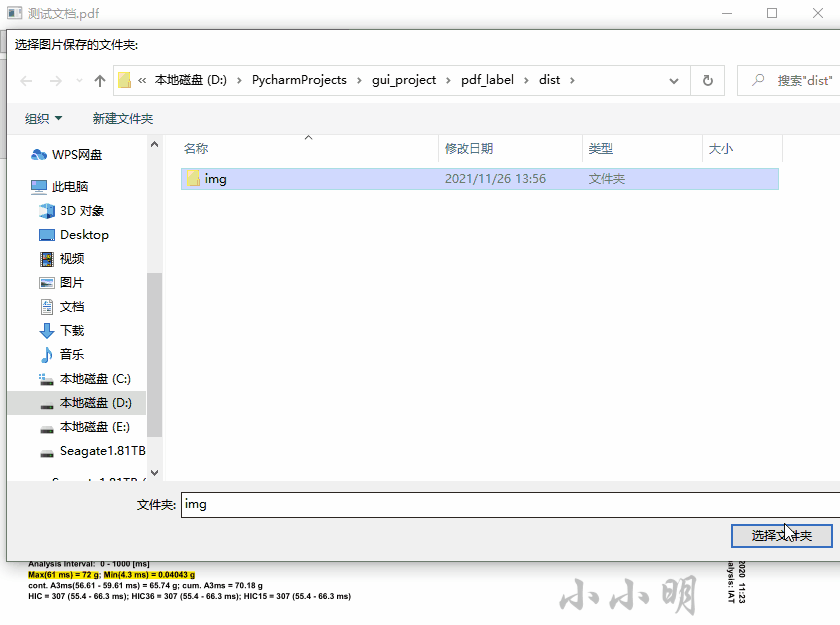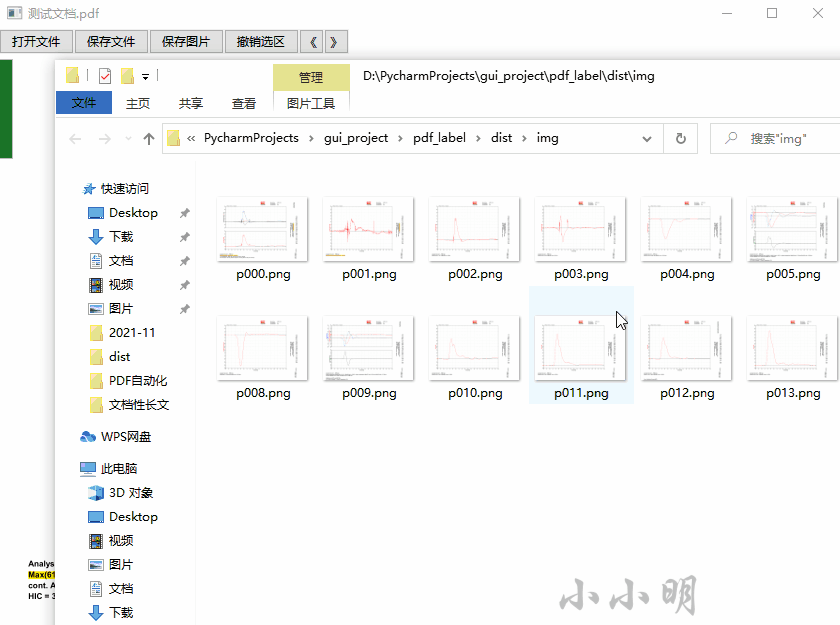
When selecting a region, the text extracted from the last region will be automatically extracted as the file name of the current page:
Development code
Of course, because I used wxpython for the first time, the function is very simple. Now I open source the complete code and look forward to your improvement.
Download address of source code and compiled tools:
https://codechina.csdn.net/as604049322/python_gui
Full code:
"""
Xiao Ming's code
CSDN Home page: https://blog.csdn.net/as604049322
"""
__author__ = 'Xiao Ming'
__time__ = '2021/11/24'
import csv
import wx
import os
import fitz
class MyCanvas(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
self.parent = parent
self.rects = []
self.Bind(wx.EVT_LEFT_DOWN, self.OnLeftButtonEvent)
self.Bind(wx.EVT_LEFT_UP, self.OnLeftButtonEvent)
self.Bind(wx.EVT_MOTION, self.OnLeftButtonEvent)
self.Bind(wx.EVT_PAINT, self.DoDrawing)
b = wx.Button(self, -1, "Open file", (0, 0))
self.Bind(wx.EVT_BUTTON, self.OnButton, b)
b = wx.Button(self, -1, "Save file", (75, 0))
self.Bind(wx.EVT_BUTTON, self.save_file, b)
b = wx.Button(self, -1, "Save picture", (150, 0))
self.Bind(wx.EVT_BUTTON, self.save_img, b)
b = wx.Button(self, -1, "Revoke constituency", (225, 0))
self.Bind(wx.EVT_BUTTON, self.back_select, b)
b = wx.Button(self, -1, "<", (300, 0), size=(25, 25))
self.Bind(wx.EVT_BUTTON, self.previous, b)
b = wx.Button(self, -1, ">", (325, 0), size=(25, 25))
self.Bind(wx.EVT_BUTTON, self.next, b)
self.g1 = wx.Gauge(self, -1, 100, (0, 30), (-1, 100), wx.GA_VERTICAL)
def previous(self, evt):
if not hasattr(self, "pdfDoc"):
return
if self.i > 0:
self.i -= 1
self.change_pdf_page(self.i, False)
self.DoDrawing(-1)
if self.rects:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
def next(self, evt):
if not hasattr(self, "pdfDoc"):
return
if self.i < self.pageCount - 1:
self.i += 1
self.change_pdf_page(self.i, False)
self.DoDrawing(-1)
if self.rects:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
def back_select(self, evt):
if self.rects:
self.rects.pop()
self.DoDrawing(-1)
def OnButton(self, evt):
dlg = wx.FileDialog(
self, message="Select one PDF file",
defaultDir=os.getcwd(),
defaultFile="",
wildcard="PDF file(*.pdf)|*.pdf",
style=wx.FD_OPEN | wx.FD_CHANGE_DIR |
wx.FD_FILE_MUST_EXIST | wx.FD_PREVIEW
)
if dlg.ShowModal() == wx.ID_OK:
self.rects = []
path = dlg.GetPath()
self.pdfDoc = fitz.open(path)
self.i = 0
self.pageCount = self.pdfDoc.pageCount
self.change_pdf_page(self.i)
self.path = os.path.basename(path)
self.parent.SetTitle(self.path)
self.DoDrawing(-1)
dlg.Destroy()
def change_pdf_page(self, i, move=True):
page = self.pdfDoc[i]
rect = page.rect
print("pdf Range:", rect)
mat = fitz.Matrix(1, 1)
pix = page.get_pixmap(matrix=mat, alpha=False, clip=rect)
pix.save("tmp.png")
self.change_img("tmp.png", move)
def save_FileDialog(self, format="csv"):
dlg = wx.FileDialog(
self, message=f"Save a{format}file", defaultDir=os.getcwd(),
defaultFile="", wildcard=f"{format}file(*.{format})|*.{format}", style=wx.FD_SAVE | wx.FD_OVERWRITE_PROMPT
)
path = None
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
dlg.Destroy()
return path
def save_img(self, evt):
if not hasattr(self, "pdfDoc"):
return
dlg = wx.DirDialog(self, "Select a folder to save pictures to:",
style=wx.DD_DEFAULT_STYLE
# | wx.DD_DIR_MUST_EXIST
# | wx.DD_CHANGE_DIR
)
mat = fitz.Matrix(1, 1)
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
for i in range(self.pdfDoc.pageCount):
page = self.pdfDoc[i]
clip = page.rect
pix = page.get_pixmap(matrix=mat, alpha=False, clip=clip)
if self.rects:
name = self.extract_pdf_text(page=page, rect=self.rects[-1])
else:
name = f"p{i:0>3d}"
pix.save(f"{path}/{name}.png")
self.g1.SetValue((i + 1) * 100 // self.pdfDoc.pageCount)
dlg.Destroy()
os.system(f"explorer {path}")
def save_file(self, evt):
if not hasattr(self, "pdfDoc"):
return
path = self.save_FileDialog()
if path is None:
return
data = []
for i in range(self.pdfDoc.pageCount):
page = self.pdfDoc[i]
row = [self.extract_pdf_text(page, rect)
for i, rect in enumerate(self.rects)]
data.append(row)
with open(path, "w") as f:
writer = csv.writer(f, lineterminator="\n")
row = [f"region{i}" for i in range(1, len(row) + 1)]
writer.writerow(row)
for row in data:
writer.writerow(row)
os.system(f"cmd /c start {path}")
def extract_pdf_text(self, page=None, rect=None):
if page is None:
page = self.pdfDoc[self.i]
if rect is None:
rect = self.rects[-1]
a, b, c, d = rect
clip = fitz.Rect(a, b, a + c, b + d)
text = page.get_text(clip=clip).strip()
return text
def change_img(self, img_path, move=True):
self.bmp = wx.Bitmap(img_path)
self.SetSize(self.bmp.GetSize())
self.parent.SetSize(self.parent.GetBestSize())
if move:
self.parent.Center()
def DoDrawing(self, evt):
if not hasattr(self, "bmp"):
return
dc = wx.ClientDC(self)
dc.DrawBitmap(self.bmp, 0, 0, True)
dc.SetPen(wx.Pen('blue'))
dc.SetBrush(wx.Brush('white', wx.BRUSHSTYLE_TRANSPARENT))
dc.DrawRectangleList(self.rects)
def OnLeftButtonEvent(self, event):
if event.LeftDown():
self.x, self.y = event.GetPosition()
self.rects.append([self.x, self.y, 0, 0])
elif event.Dragging():
x, y = event.GetPosition()
self.rects[-1][2] = x - self.x
self.rects[-1][3] = y - self.y
self.DoDrawing(-1)
elif event.LeftUp():
print(self.rects)
if self.rects[-1][2] < 5 or self.rects[-1][3] < 5:
self.rects.pop()
else:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
app = wx.App()
frm = wx.Frame(None)
pnl = MyCanvas(frm)
frm.Center()
frm.Show()
frm.SetTitle("PDF Text extractor")
app.MainLoop()