Well... It's coming again... It's not over after all.
Following the previous article, I finished writing Series and DataFrame, and then I should start some table operations.
1. Connection of tables
1.1. join operation
Parameters:
- other: the second Dataframe, Series, or column in the Dataframe
- on: duplicate column names in the second DataFrame with the first
- how: ('parameter optional' left ',' right ',' outer ',' inner '), the default is' left', which means to use the index of the table on the left as the index after connection. Similarly, right, inner means to take the intersection. If there is an index with the same name in two tables, the final result is the table composed of indexes with the same name, and outer is the union set, This is the table that displays the indexes of the left table and the right table
- lsuffix: suffix of duplicate column in the first DataFrame
- rsuffix: suffix of duplicate column in the second DataFrame
- Sort: sort by connection key. The default value is False
Upper Code:
import pandas as pd
album_dict = {'An ordinary day':['An ordinary day','Here you are. Give it to me','One meat and one vegetable'],'Xiao Wang's Diary':['Water town','Xiao Wang','Babble'],'Chick Guide':['City evening','Sea diary','Chick Guide']}
album = pd.DataFrame(album_dict)
album1 = pd.DataFrame({'An ordinary day':['get rid of-blues','midsummer','No questions'],'Xiao Wang's Diary':['Northeast ballad','two zero three','Hutong'],'Chick Guide':['Limit seventeen','Xiang Yu and Yu Ji','enter the sea']})
album.join(album1,on = None,how = 'left',lsuffix = '_left',rsuffix = '_right',sort = False) 
Error code:
album.join(album1,on = None)
Will cause ValueError!!! Because the column name is repeated at this time, there are two methods: either you change the column name or add the parameters lsuffix and rsuffix.
1.2. merge operation (connection, automatic matching)
Parameter Description:
- Left: the left DataFrame participating in the merge
- Right: the right DataFrame participating in the merge
- on: the column name used for connection must exist in the left and right dataframes
- how: the optional parameters are "inner", "outer", "left", "right", and the default is "inner"
- left_on: the column used as the join key in the DataFrame on the left
- right_on: the column used as the join key in the right DataFrame
- left_index: use the line reference on the left as its connection key
- right_index: use the line reference on the right as its connection key
- indicator: if True, the name will be_ The category type column of merge is added to the output object with value
how='left ', the connection method is the column with duplicate column names in the first DataFrame and the second DataFrame after merging:
import pandas as pd
album_dict = {'An ordinary day':['An ordinary day','Here you are. Give it to me','One meat and one vegetable'],'Xiao Wang's Diary':['Water town','Xiao Wang','Babble'],'Chick Guide':['City evening','Sea diary','Chick Guide']}
album = pd.DataFrame(album_dict)
album1 = pd.DataFrame({'An ordinary day':['get rid of-blues','midsummer','No questions'],'Xiao Wang's Diary':['Northeast ballad','two zero three','Hutong'],'Chick Guide':['Limit seventeen','Xiang Yu and Yu Ji','enter the sea']})
album2 = pd.merge(album, album1, how='left',on=['An ordinary day','Xiao Wang's Diary'],indicator=True)
album2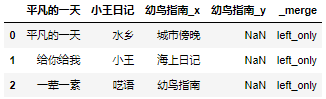
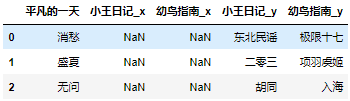
how='left ', the connection method is the column with duplicate column names in the second DataFrame and the first DataFrame after merging:
album2 = pd.merge(album, album1, how='right',on='An ordinary day') album2
Use left_on and right_ Connect on:
import pandas as pd
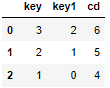
result = pd.DataFrame({'key':[0,1,2],'key1':[1,2,3],'ab':[4,5,6]})
result1 = pd.DataFrame({'key':[3,2,1],'key1':[2,1,0],'cd':[6,5,4]})
final = pd.merge(result,result1,left_on='ab',right_on='cd')
final
Use left_on and right_index=True to connect:
import pandas as pd
result = pd.DataFrame({'key':[0,1,2],'key1':[1,2,3],'ab':[4,5,6]})
result1 = pd.DataFrame({'key':[3,2,1],'key1':[2,1,0],'cd':[6,5,4]})
final = pd.merge(result,result1,left_on='ab',right_index=True)
final
Will become this sub son because it is used at this time right_index=True. This means that the index of the table on the right is associated with the column of the table on the left (in the example, the column named ab). Since they do not have the same elements, they display almost an empty table. Just look at the index of the table on the right. The index is 0, 1 and 2.
1.3 concat (splicing)
Parameter Description:
- object: Series,DataFrame
- Axis: axis to be merged and connected. 0 indicates row and 1 indicates column
- keys: after selection, multiple indexes can be created
- join: optional parameters are 'inner' and 'outer'
final = pd.concat([result,result1]) final
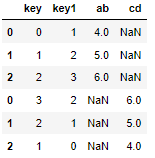
Use the keys parameter:
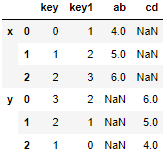
final = pd.concat([result,result1],keys = ['x','y']) final
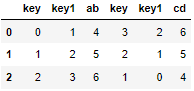
Use the axis parameter: (set to 1 to splice along the column)
final = pd.concat([result,result1], axis=1) final
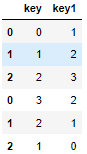
Use the join parameter (which means taking intersection):
final = pd.concat([result,result1], join='inner') final
2. Simple operation of table
2.1. Simple addition of tables
Append column:
result['key3'] = result.apply(lambda x:x.sum(),axis =1) result

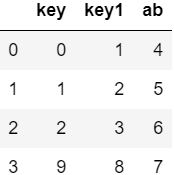
Append row( ignore_index: if True, the index in the source DataFrame object will be ignored):
ser = pd.Series([9,8,7], index=['key', 'key1', 'ab']) df = result.append(ser, ignore_index=True) df
2.2. Table row and column summation
Column summation:
result.loc['key2'] = result.apply(lambda x:x.sum(),axis =0) result
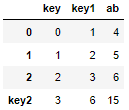
Line summation:
result['key3'] = result.apply(lambda x:x.sum(),axis =1) result
