Configure corosync
Install corosync pacemaker in both server5 and server6
yum install corosync pacemaker -y
Edit the corosync configuration file in server5
mv /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
vim /etc/corosync/corosync.conf
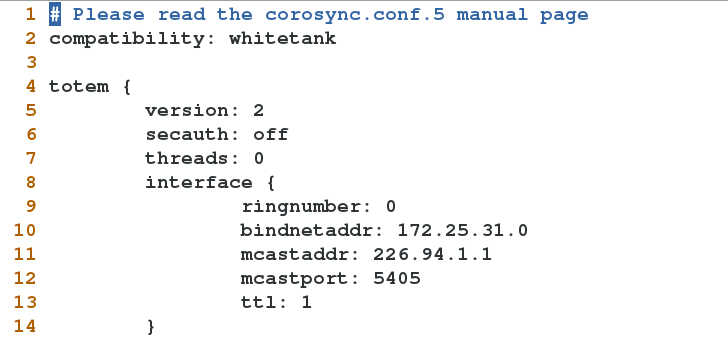
# Please read the corosync.conf.5 manual page
compatibility: whitetank
totem {
version: 2
secauth: off #Open authentication or not
threads: 0 #When authentication is implemented, the number of concurrent threads is 0, which means the default
interface {
ringnumber: 0 #Ring number. Define a unique ring number for this network card to avoid heartbeat message ring sending
bindnetaddr: 172.25.31.0 #Bound network address
mcastaddr: 226.94.1.1 #Broadcast address
mcastport: 31 #Broadcast port
ttl: 1 #Only one broadcast out
}
}
logging {
fileline: off
to_stderr: no
to_logfile: yes
to_syslog: yes
logfile: /var/log/cluster/corosync.log
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
service { #Define a service to start pacemaker
ver: 0 #pacemaker will be automatically started when corosync is started
name: pacemaker
use_mgmtd: yes
}

scp /etc/corosync/corosync.conf 172.25.31.6:/etc/corosync/ #scp the configuration file to server6 /etc/init.d/corosync start #Open corosync in both server5 and server6
Configure cluster with crm
yum localinstall crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm
Check the configuration file and an error will be reported, because we have not configured stonith at this time
crm_verify -LV
Disable fence
crm
crm(live)# configure
crm(live)configure# property stonith-enabled=false
crm(live)configure# commit #SubmissionCheck again at this time, no error is reported
crm_verify -LV
View current cluster
crm configure show 
Set no quorum policy to ignore
In the two nodes, when the node fails to reach the legal votes, i.e. one of the two nodes is broken and cannot vote, and the normal node fails to reach the legal votes. In this case, if it is the default parameter, i.e. the normal machine cannot work, it needs to be ignore so that the normal machine can take over
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit Add vip
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.31.100 cidr_netmask=24 op monitor interval=1min
crm(live)configure# commitAdd haproxy
crm(live)configure# primitive haproxy lsb:haproxy op monitor interval=1min
crm(live)configure# commit It is found that two resources are not running on the same node and resource drift occurs. Adding resource group can solve this problem 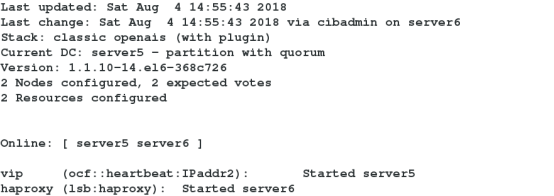
Add resource group
crm(live)configure# group westos vip haproxy
crm(live)configure# commit
Execute the crm node standby command on node server5 to disable the node
Resources will be transferred to server6 
Execute the crm node online command on server5 to activate the node
Resources will not be transferred 
Add fence
Ensure that the fence ﹣ virtd service on the host is turned on
stonith_admin -I #Query fence device stonith_admin -M -a fence_xvm #View related configuration content
We are going to use fence [XVM. If not, install the following software on server5 and Server6
yum install -y fence-virt.x86_64 fence-agents.x86_64
Add fence resource
crm(live)configure# primitive vmfence stonith:fence_xvm params pcmk_host_map="server5:test5;server6:test6" op monitor interval=1min
#Add fence resource, and map cluster node name and real server name
crm(live)configure# property stonith-enabled=true #Open fence function
crm(live)configure# commit #Submission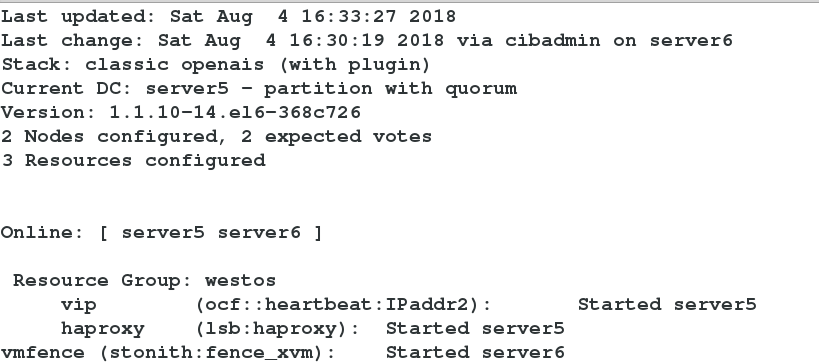
Test:
Execute echo C > / proc / sysrq trigger in server5 to crash its kernel
server5 will restart automatically
Fence - H TEST6 - Manual fence test6