In daily work, we often need to develop reports or count the percentage and total of some data. At this time, the following functions can solve the problem quickly. They have fewer sql statements and better performance. The figure below shows the results of our statistics.
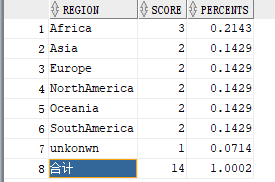
Common functions are as follows: case when...then...else...end, regexp_like, ratio_to_report(score) OVER(), roll up, grouping. This article just shows how to use these functions to calculate this effect cleverly in sql. For specific usage, please refer to the data for more details.
First of all, you need to count things like this:
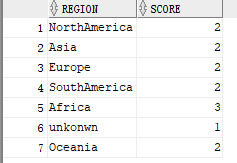
My table needs to be converted, so I need to use the following sql statement for processing. If different, please skip this paragraph.
SELECT region, SUM(CASE region WHEN 'Africa' THEN 1 WHEN 'Asia' THEN 1 WHEN 'Europe' THEN 1 WHEN 'NorthAmerica' THEN 1 WHEN 'Oceania' THEN 1 WHEN 'SouthAmerica' THEN 1 WHEN 'unkonwn' THEN 1 ELSE 0 END) AS score FROM ( SELECT CASE WHEN regexp_like(substr(TRANSDAY, 0, 1), '[A-C]') THEN 'Africa' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[J-R]') THEN 'Asia' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[S-Z]') THEN 'Europe' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[1-5]') THEN 'NorthAmerica' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[6-7]') THEN 'Oceania' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[8-9]') THEN 'SouthAmerica' ELSE 'unkonwn' END AS region FROM test ) GROUP BY region
Next, your statistical data display can be converted to the following again, that is, the percentage can be calculated in this step:
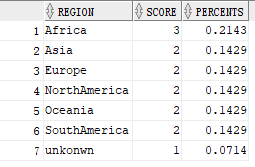
My data needs to be converted, so I need to use the following sql statement for processing. In fact, it is in this step to use ration_ To_ report( aa.score )Over() processing. If different, please skip this paragraph.
SELECT aa.region, aa.score , round(ratio_to_report(aa.score) OVER (), 4) AS percents FROM ( SELECT region, SUM(CASE region WHEN 'Africa' THEN 1 WHEN 'Asia' THEN 1 WHEN 'Europe' THEN 1 WHEN 'NorthAmerica' THEN 1 WHEN 'Oceania' THEN 1 WHEN 'SouthAmerica' THEN 1 WHEN 'unkonwn' THEN 1 ELSE 0 END) AS score FROM ( SELECT CASE WHEN regexp_like(substr(TRANSDAY, 0, 1), '[A-C]') THEN 'Africa' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[J-R]') THEN 'Asia' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[S-Z]') THEN 'Europe' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[1-5]') THEN 'NorthAmerica' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[6-7]') THEN 'Oceania' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[8-9]') THEN 'SouthAmerica' ELSE 'unkonwn' END AS region FROM test ) GROUP BY region ) aa ORDER BY aa.region
Next, we need to group and aggregate. At this time, roll up is useful.
After using rollup, our data display becomes:
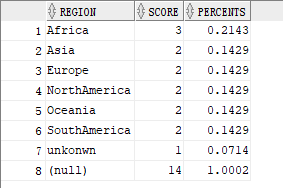
The following sql statement is to show the effect of roll up, not the final effect. You can skip this paragraph:
SELECT region, SUM(score) AS score, SUM(percents) AS percents FROM ( SELECT aa.region, aa.score , round(ratio_to_report(aa.score) OVER (), 4) AS percents FROM ( SELECT region, SUM(CASE region WHEN 'Africa' THEN 1 WHEN 'Asia' THEN 1 WHEN 'Europe' THEN 1 WHEN 'NorthAmerica' THEN 1 WHEN 'Oceania' THEN 1 WHEN 'SouthAmerica' THEN 1 WHEN 'unkonwn' THEN 1 ELSE 0 END) AS score FROM ( SELECT CASE WHEN regexp_like(substr(TRANSDAY, 0, 1), '[A-C]') THEN 'Africa' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[J-R]') THEN 'Asia' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[S-Z]') THEN 'Europe' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[1-5]') THEN 'NorthAmerica' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[6-7]') THEN 'Oceania' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[8-9]') THEN 'SouthAmerica' ELSE 'unkonwn' END AS region FROM test ) GROUP BY region ) aa ORDER BY aa.region ) t_test GROUP BY region WITH ROLLUP;
When we use rollup, we find that in the row of the lowest total, the lowest value of the classification field region to be totaled is empty. Therefore, with the function of grouping, we will achieve the final effect we want.
The grouping function can take a column and return 0 or 1. If the column value is empty, grouping() returns 1; if the column value is not empty, it returns 0. Grouping can only be used in queries that use rollup or cube. Grouping () is useful when you need to display a value where a null value is returned.
The following figure is the final sql statement:
SELECT CASE WHEN grouping(region) = 1 THEN 'total' ELSE region END AS region, SUM(score) AS score, SUM(percents) AS percents FROM ( SELECT aa.region, aa.score , round(ratio_to_report(aa.score) OVER (), 4) AS percents FROM ( SELECT region, SUM(CASE region WHEN 'Africa' THEN 1 WHEN 'Asia' THEN 1 WHEN 'Europe' THEN 1 WHEN 'NorthAmerica' THEN 1 WHEN 'Oceania' THEN 1 WHEN 'SouthAmerica' THEN 1 WHEN 'unkonwn' THEN 1 ELSE 0 END) AS score FROM ( SELECT CASE WHEN regexp_like(substr(TRANSDAY, 0, 1), '[A-C]') THEN 'Africa' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[J-R]') THEN 'Asia' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[S-Z]') THEN 'Europe' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[1-5]') THEN 'NorthAmerica' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[6-7]') THEN 'Oceania' WHEN regexp_like(substr(TRANSDAY, 0, 1), '[8-9]') THEN 'SouthAmerica' ELSE 'unkonwn' END AS region FROM test ) GROUP BY region ) aa ORDER BY aa.region ) t_test GROUP BY region WITH ROLLUP;
The above is the final display effect of our data. sql statements can be further optimized. Due to the time problem, there is time for further optimization.