1. Problem description
Independent variables: the influencing factors of the optimal distillation structure are the feed composition A, B, C, the ratio of relative volatility ESI, and the separation requirements GESI, where A+B+C=1, so the degrees of freedom of the five independent variables are 4.
Dependent variable: there are 7 kinds of three component distillation structures (relative volatility from light to heavy A,B,C), and the optimal distillation structure represents the structure with the lowest annual total cost among the 7 structures.
The traditional chemical simulation software is used to calculate the optimal distillation structure under different independent variables a, B, C, ESI and Gesi, and 200 data are obtained. In this paper, a method to solve the optimal distillation structure of three components according to independent variables is obtained by using decision tree algorithm.
2. Data exploration
View results after importing data
df.head() df.describe()
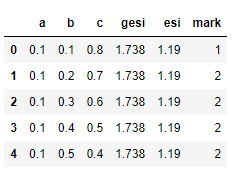
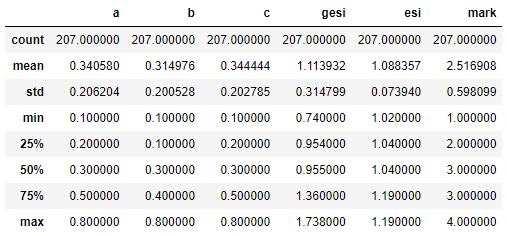
A. B and C are numbers between 0-1, GESI is numbers in the range of 0.74-1.74, and ESI is relatively concentrated, which is numbers between 1.02-1.19. mark represents the optimal distillation structure. It can be seen that there are only four optimal structures among the seven distillation structures.
3. Data processing
Since the original data has been processed in excel and there is no missing value, it only needs to be standardized. In fact, the decision tree is not sensitive to data standardization. The standardization is for subsequent comparison with other classification algorithms such as naive Bayes, SVM and KNN. Naive Bayes requires that the independent variable should not be less than 0, so min max is used for standardization.
Independent variable selection: for the problem of two out of three ABC, first select ABC into the independent variables. After the decision tree runs the results, it is found that B has the least impact on the dependent variable, so AC is used as the independent variable.
features=df[['a','c','gesi','esi']] targets=df['mark'] train_x,test_x,train_y,test_y=train_test_split(features,targets,test_size=0.33,random_state=1) mm=preprocessing.MinMaxScaler() train_mm_x=mm.fit_transform(train_x) test_mm_x=mm.transform(test_x)
4. Decision tree modeling
Directly use the algorithm encapsulated in python's own library sklearn, which is convenient and fast.
#The decision tree uses information gain to divide the results
clf = DecisionTreeClassifier(criterion='entropy')
clf=clf.fit(train_mm_x,train_y)
test_predict_en=clf.predict(test_mm_x)
score_en=accuracy_score(test_y,test_predict_en)
print('The decision tree is divided by information gain rate, and the accuracy is%.4f'%score_en)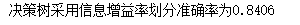
In the model, the adjustable parameter criterion, entropy represents the division of nodes by information gain rate, and gini represents the division of gini coefficient. The actual operation result is that the accuracy of information gain rate division is higher.
The model can also be further optimized to optimize the maximum depth of the decision tree. When the maximum depth is 4, the accuracy of the decision tree in dividing the training set data is the highest, and the accuracy reaches 0.8696. This step is equivalent to decision tree pruning.
clfo=GridSearchCV(estimator=clf,param_grid={'max_depth':range(1,20)})
clfo=clfo.fit(train_mm_x,train_y)
clfo.best_params_ 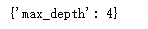
Finally, the generated decision tree is visualized.
dot_data = tree.export_graphviz(clf,out_file=None,filled=True,feature_names=train_x.columns,
class_names=['SS','DWC','DB','IF'])
graphviz.Source(dot_data)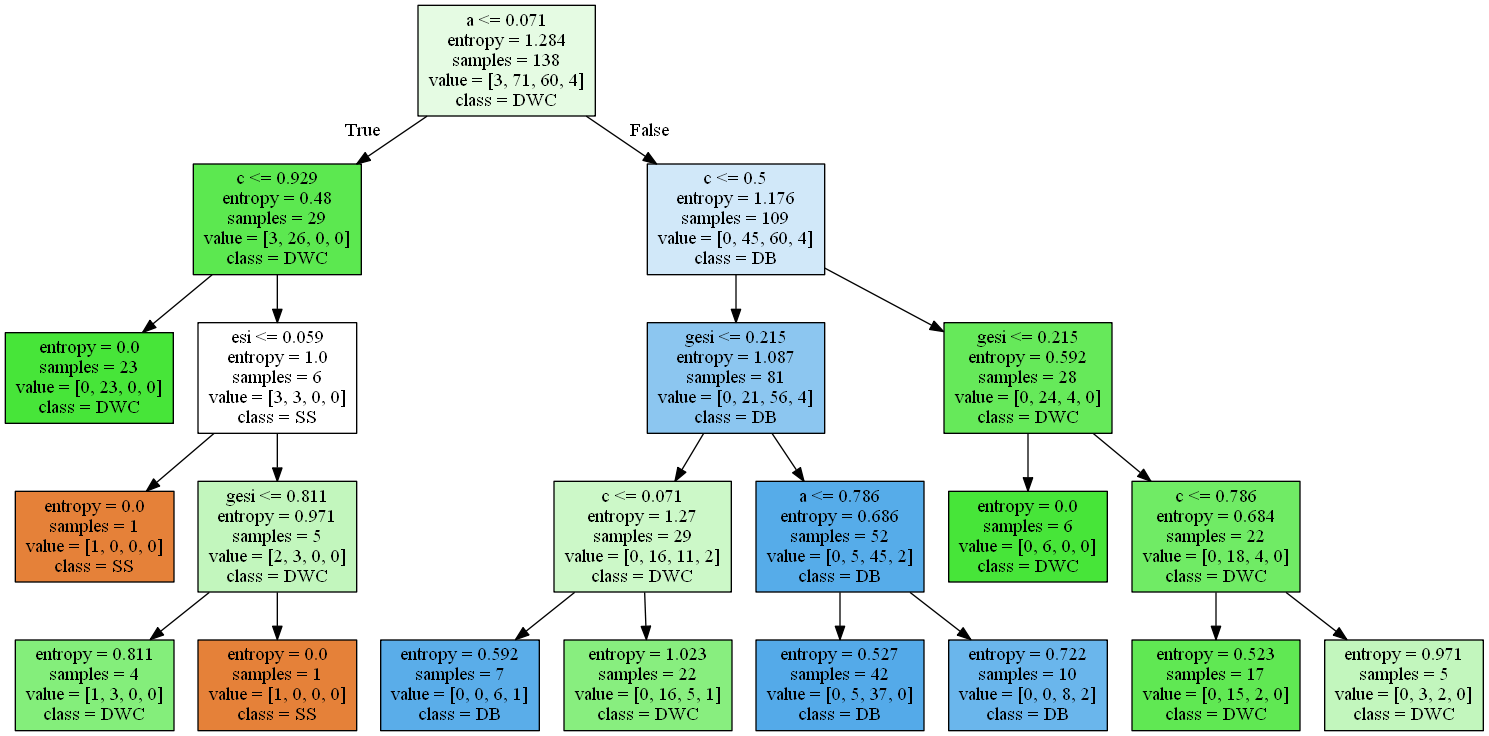
Therefore, the general rules of three component optimal distillation sequence are obtained by decision tree method
The feed concentration of 1.A has the greatest influence on the optimal distillation structure
2. When the feed concentration of C is greater than 0.5, ESI has a greater impact on the optimal distillation structure than GESI. It is still necessary to make classification decisions in combination with GESI
3. When the C feed concentration is less than 0.5, Gesi has a greater impact on the optimal distillation structure than ESI, and there is no need to make classification decision combined with ESI
5. Comparison with other machine learning algorithms
Naive Bayes, SVM, support vector machine and KNN are used to train the original data and compare the accuracy
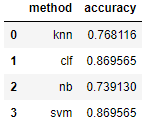
knowable
SVM also has quite good model accuracy, and naive Bayes has the worst accuracy.
The decision tree has good accuracy, is easy to explain, and can generate an intuitive tree diagram for easy judgment. Therefore, the decision tree method is used to judge the optimal distillation structure of three components.
Attached code
ss=preprocessing.StandardScaler()
train_ss_x=ss.fit_transform(train_x)
test_ss_x=ss.transform(test_x)
#Bayes
from sklearn.naive_bayes import MultinomialNB
mnb=MultinomialNB()
mnb=mnb.fit(train_mm_x,train_y)
predict_yb=mnb.predict(test_mm_x)
nb_ac=accuracy_score(test_y,predict_yb)
print('Bayesian accuracy is%.4f'%nb_ac)
#Optimization of SVM with penalty coefficient
from sklearn.svm import SVC
svm=SVC()
svmo = GridSearchCV(estimator=svm, param_grid={'C':range(1,10)})
svmo=svmo.fit(train_ss_x,train_y)
print('SVC Optimal parameters%s'%svmo.best_params_)
svm_ac=svmo.score(test_ss_x,test_y)
print('SVM The accuracy is%.4f'%svm_ac)
#Optimization of KNN with k value
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()
knno=GridSearchCV(estimator=knn,param_grid={'n_neighbors':range(1,20)})
knno=knno.fit(train_ss_x,train_y)
knn_ac=knno.score(test_ss_x,test_y)
print('knn Optimal parameters%s'%knno.best_params_)
print('knn The accuracy is%.4f'%knn_ac)
results={'method':['knn','clf','nb','svm'],'accuracy':[knn_ac,score_en,nb_ac,svm_ac]}
pd.DataFrame(results)6. Summary
A decision tree algorithm for the selection of three-component optimal distillation structure is generated. The algorithm is simple and explanatory. The effects of feed concentration ABC, ESI and GESI on the optimal structure decision are found. Compared with other machine learning algorithms, the decision tree method has better modeling accuracy.