Keep database and index database synchronized
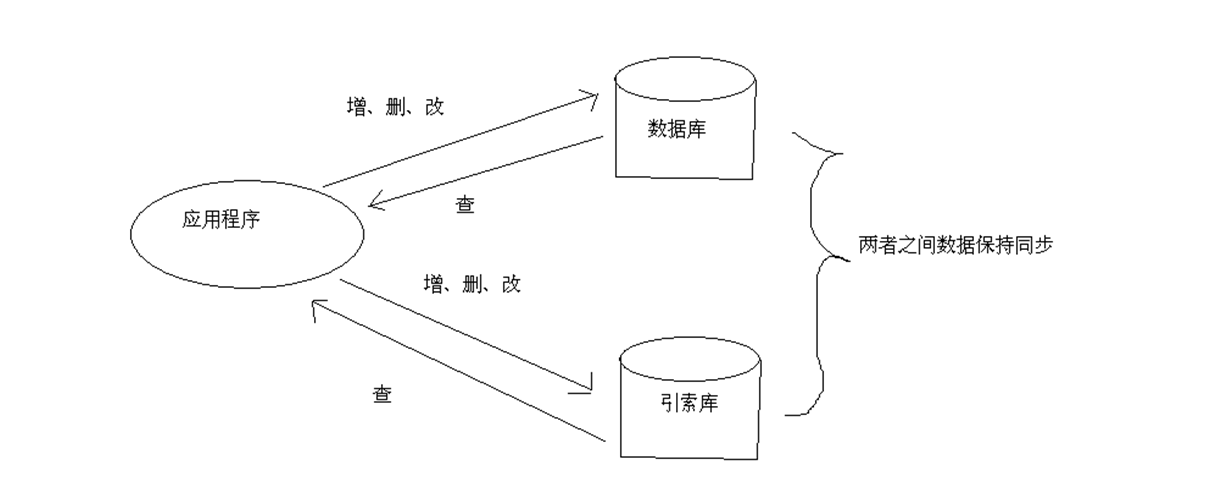
Description: In a system, if the index function exists, then the database and index database should exist simultaneously. At this time, we need to ensure the consistency between the data in the index database and the data in the database. In addition to adding, deleting and changing the database, the index database can also be operated accordingly. In this way, the consistency between database and index database can be guaranteed.
Tool class DocumentUtils
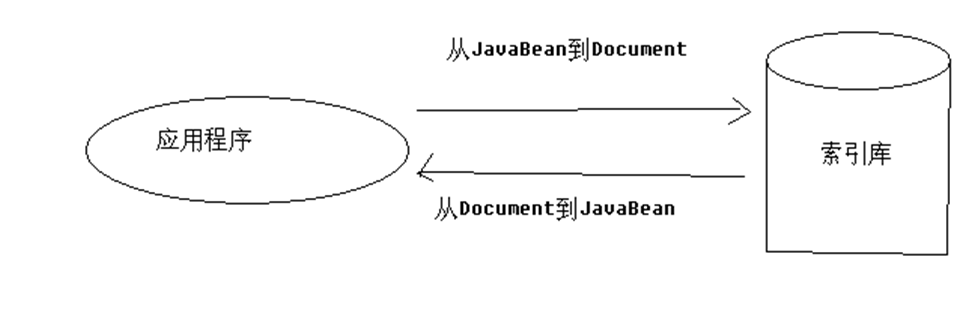
Description: In the operation of index libraries, the process of adding, deleting and changing should encapsulate a JavaBean into a Document, while the process of querying is to convert a Document into a JavaBean. In the maintenance work, we need to do this repeatedly, so we need to build a tool class to reuse the code.
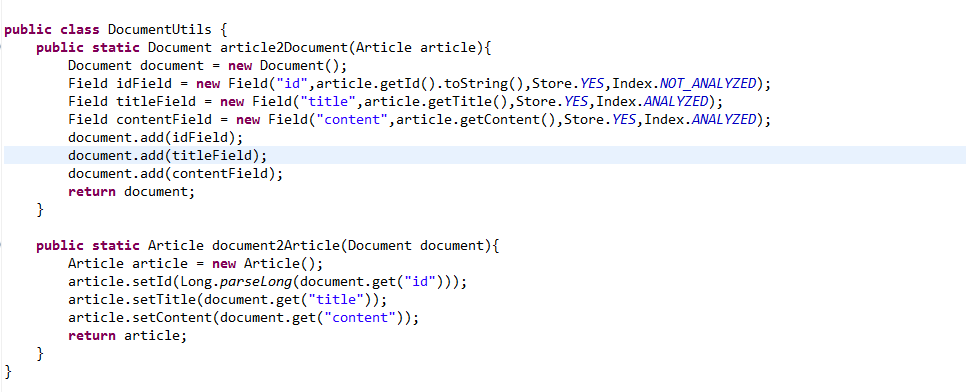
public class DocumentUtils {
public static Document article2Document(Article article){
Document document = new Document();
Field idField = new Field("id",article.getId().toString(),Store.YES,Index.NOT_ANALYZED);
Field titleField = new Field("title",article.getTitle(),Store.YES,Index.ANALYZED);
Field contentField = new Field("content",article.getContent(),Store.YES,Index.ANALYZED);
document.add(idField);
document.add(titleField);
document.add(contentField);
return document;
}
public static Article document2Article(Document document){
Article article = new Article();
article.setId(Long.parseLong(document.get("id")));
article.setTitle(document.get("title"));
article.setContent(document.get("content"));
return article;
}
}
When to use Index.NOT_Analysis YZED
When the value of this attribute represents an indivisible whole, such as ID
When to use Index. Analysis YZED
When the value of this attribute represents a separable whole
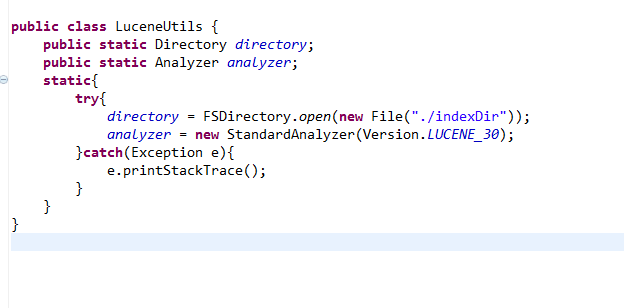
LuceneUtils
The LuceneUtils class wraps Directory and Analezer. Because these two classes are needed to create IndexWriter, and the IndexWriter class is used to manage index libraries, we wrapped Directory and Annalezer.
public class LuceneUtils {
public static Directory directory;
public static Analyzer analyzer;
static{
try{
directory = FSDirectory.open(new File("./indexDir"));
analyzer = new StandardAnalyzer(Version.LUCENE_30);
}catch(Exception e){
e.printStackTrace();
}
}
}
Managing Index Library
Increase index database
@Test
public void testSaveIndex(){
//Create an article object and store the information in it
Article article = new Article();
article.setId(1L);
article.setTitle("lucene Can be a search engine");
article.setContent("baidu,goole They are good search engines.");
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(LuceneUtils.directory,LuceneUtils.analyzer,MaxFieldLength.LIMITED);
Document doc = DocumentUtils.article2Document(article);
indexWriter.addDocument(doc);
indexWriter.commit();
}catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
indexWriter.close();
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
throw new RuntimeException(e);
}
}
}
Note: At the end of the program, you must write the closing operation in final. Because there are read and write operations for IO streams.
Delete Index Library
/**
* In general, key words are used to delete index libraries.
* @throws Exception
*/
@Test
public void testDeleteIndex() throws Exception{
IndexWriter indexWriter = new IndexWriter(LuceneUtils.directory,LuceneUtils.analyzer,MaxFieldLength.LIMITED);
//indexWriter.deleteAll() Deletes all index values
/**
* term Be the object of keywords
*/
Term term = new Term("title", "lucene");
indexWriter.deleteDocuments(term);
indexWriter.close();
}Before deletion: 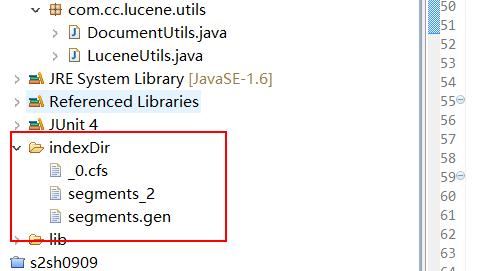
After deletion: 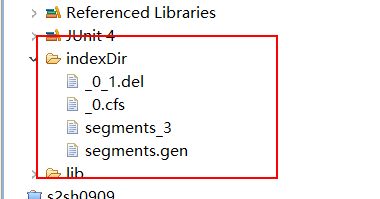
Description: The parameter of indexWriter.deleteDocuments is Term.Term refers to keywords. Because the index saved type of ID is Index. NOT_Analysis YZED, because the ID can be written directly.
Modifying the Index Library
/**
* modify
* Delete before add
*/
@Test
public void testUpdateIndex() throws Exception{
IndexWriter indexWriter = new IndexWriter(LuceneUtils.directory,LuceneUtils.analyzer,MaxFieldLength.LIMITED);
Term term = new Term("title", "lucene");
Article article = new Article();
article.setId(1L);
article.setTitle("lucene Can be a search engine");
article.setContent("Revised content");
/**
* term It's deleted.
* document It's for adding
*/
indexWriter.updateDocument(term, DocumentUtils.article2Document(article));
indexWriter.close();
}Delete index libraries and recreate index libraries: 
Modify the index library: 
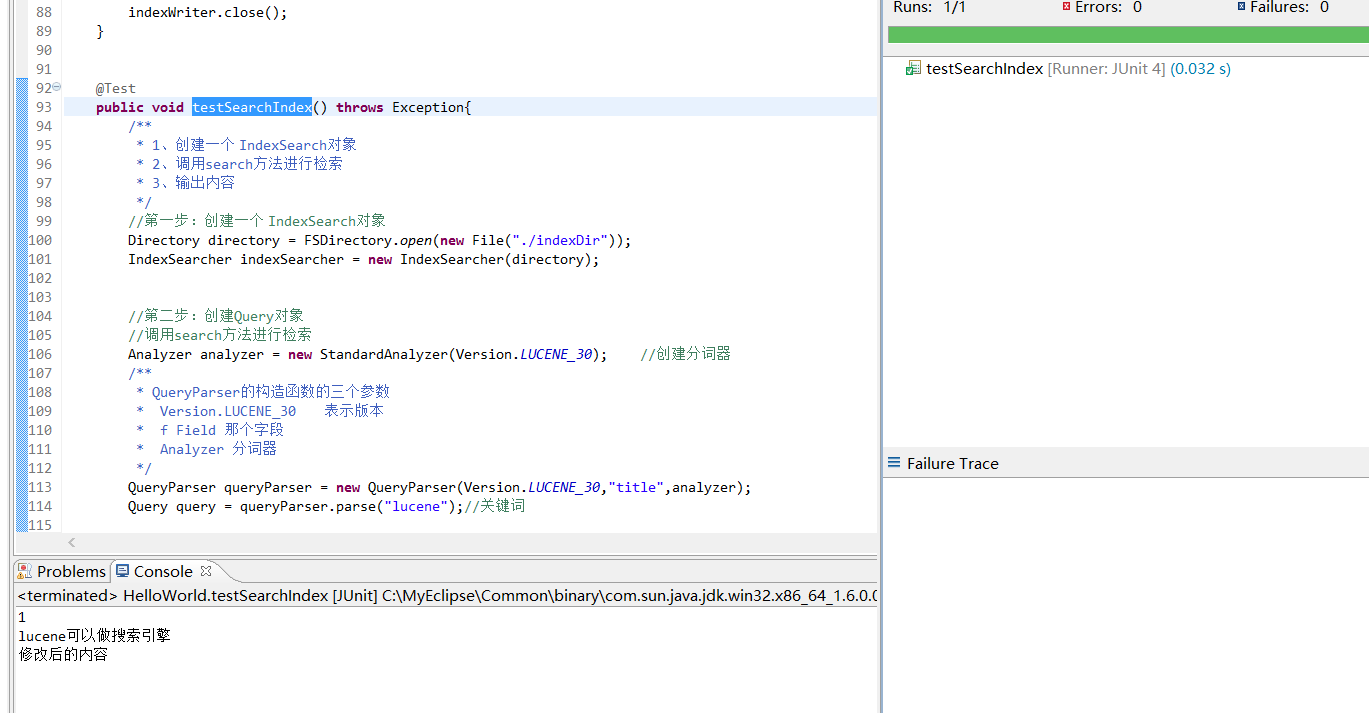
Note: The update operation of lucene is different from that of database. Because when updating, it is possible to change the location of keywords, so the word segmentation has to re-search keywords, and also have to replace them in the directory and content. This is inefficient, so the update operation of lucene is accomplished by deleting and adding two steps.