SparkSQL 1.x and 2.x programming API s have some changes that are used in enterprises, so both of them will use cases to learn.
The case of using Spark SQL 1.x first
IDEA+Maven+Scala
1. pom dependencies for importing SparkSQL
In the previous Blog Spark case, the following dependencies are added to the pom dependencies of the home location based on the ip address
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>2. Specific code implementation, because the code has been explained in detail, so here is the direct release.
package cn.ysjh0014.SparkSql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkSqlDemo1 {
def main(args: Array[String]): Unit = {
//This program can be submitted to the Spark cluster
val conf = new SparkConf().setAppName("SparkSql").setMaster("local[4]") //The setMaster here is designed to run locally, multithreaded
//Create Spark Sql connections
val sc = new SparkContext(conf)
//SparkContext cannot create a special RDD that wraps Spark Sql and enhances it
val SqlContext = new SQLContext(sc)
//Create a DataFrame (a special RDD, that is, a RDD with schema), first create a normal RDD, and then associate it with schema
val lines = sc.textFile(args(0))
//Processing data
val boyRdd: RDD[Boy] = lines.map(line => {
val fields = line.split(",")
val id = fields(0).toLong
val name = fields(1)
val age = fields(2).toInt
val yz = fields(3).toDouble
Boy(id,name,age,yz)
})
//The RDD is loaded with Boy-type data and has schema information, but it is still an RDD, so RDD should be converted into a DataFrame.
//Import implicit transformation
import SqlContext.implicits._
val df: DataFrame = boyRdd.toDF
//When you become a DataFrame, you can program with two API s
//1. How to use SQL
//Register the DataFrame as a temporary table
df.registerTempTable("body") //Outdated methods
//Writing SQL(sql method is actually Transformation)
val result: DataFrame = SqlContext.sql("SELECT * FROM body ORDER BY yz desc, age asc") //Note: The SQL statement here must be capitalized
//View results (start Action)
result.show()
//Release resources
sc.stop()
}
}
case class Boy(id: Long, name: String, age: Int, yz: Double) //case class3. Create test data
Create a txt file and enter the following data in it
1,zhangsan,15,99 2,lisi,16,98 3,wangwu,20,100 4,xiaoming,11,97 5,xioali,8,92
4. Running test
Pass in the parameter args(0) before running
Operation results:
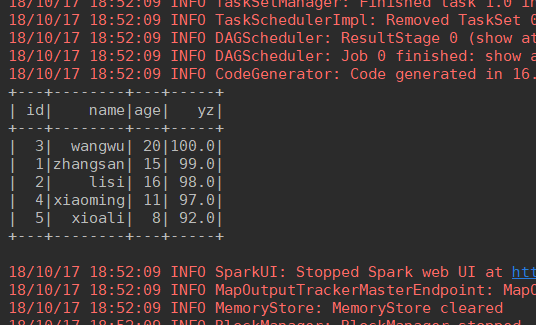
You can see that the output is presented as a table.