Catalog
One-click analysis of your online behavior, to see what you usually do online?
brief introduction
Want to see what you've been doing in the last year? See if you are fishing or working hard on the internet? Want to write an annual report summary, but suffer from no data? Now it's coming.
This is a Chrome browsing history analyzer that lets you know your browsing history. Of course, it is only suitable for Chrome browsers or browsers with Chrome as the core.
On this page, you will be able to view the top ten rankings of the domain names, URL s and busy days you visited in the past time, as well as related data charts.
Partial screenshots
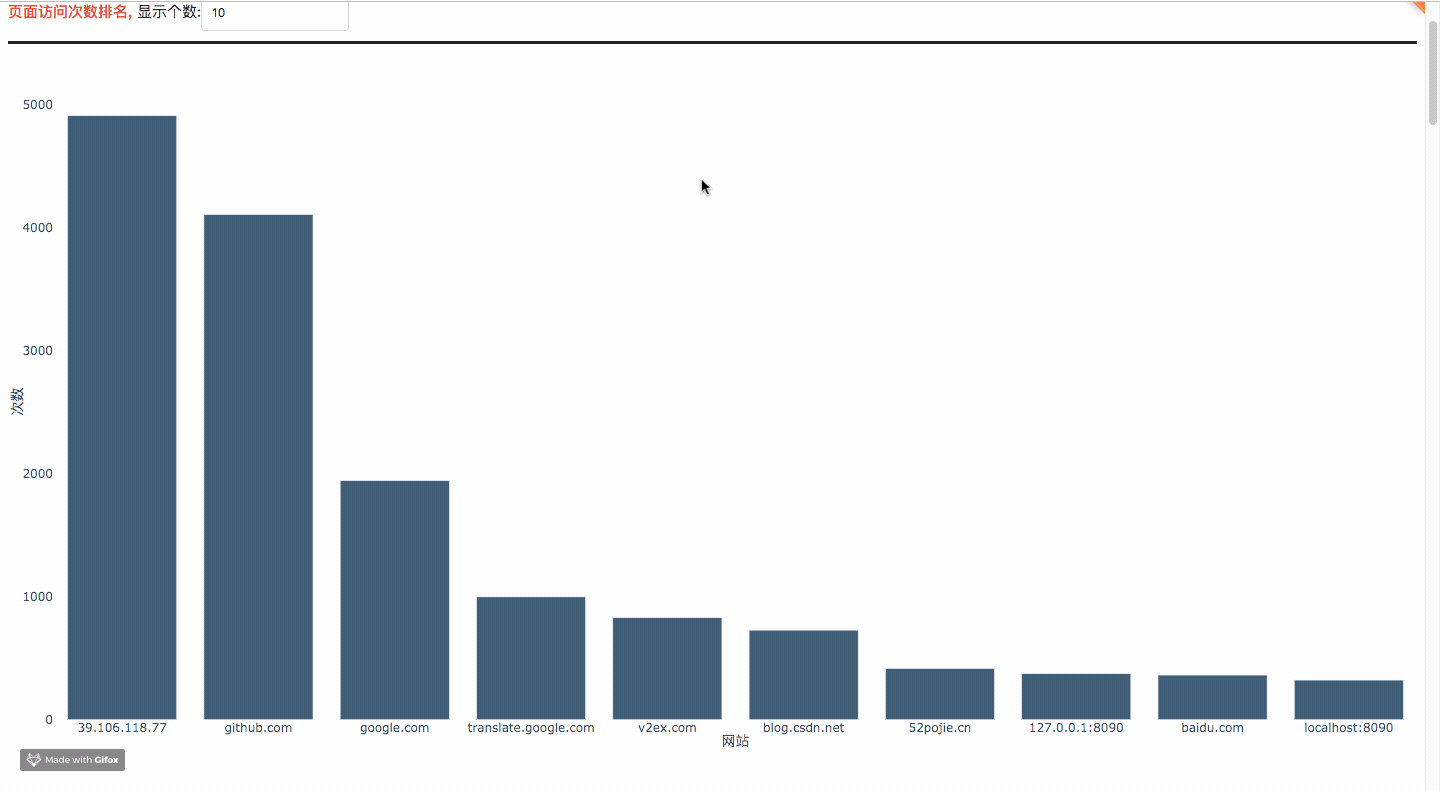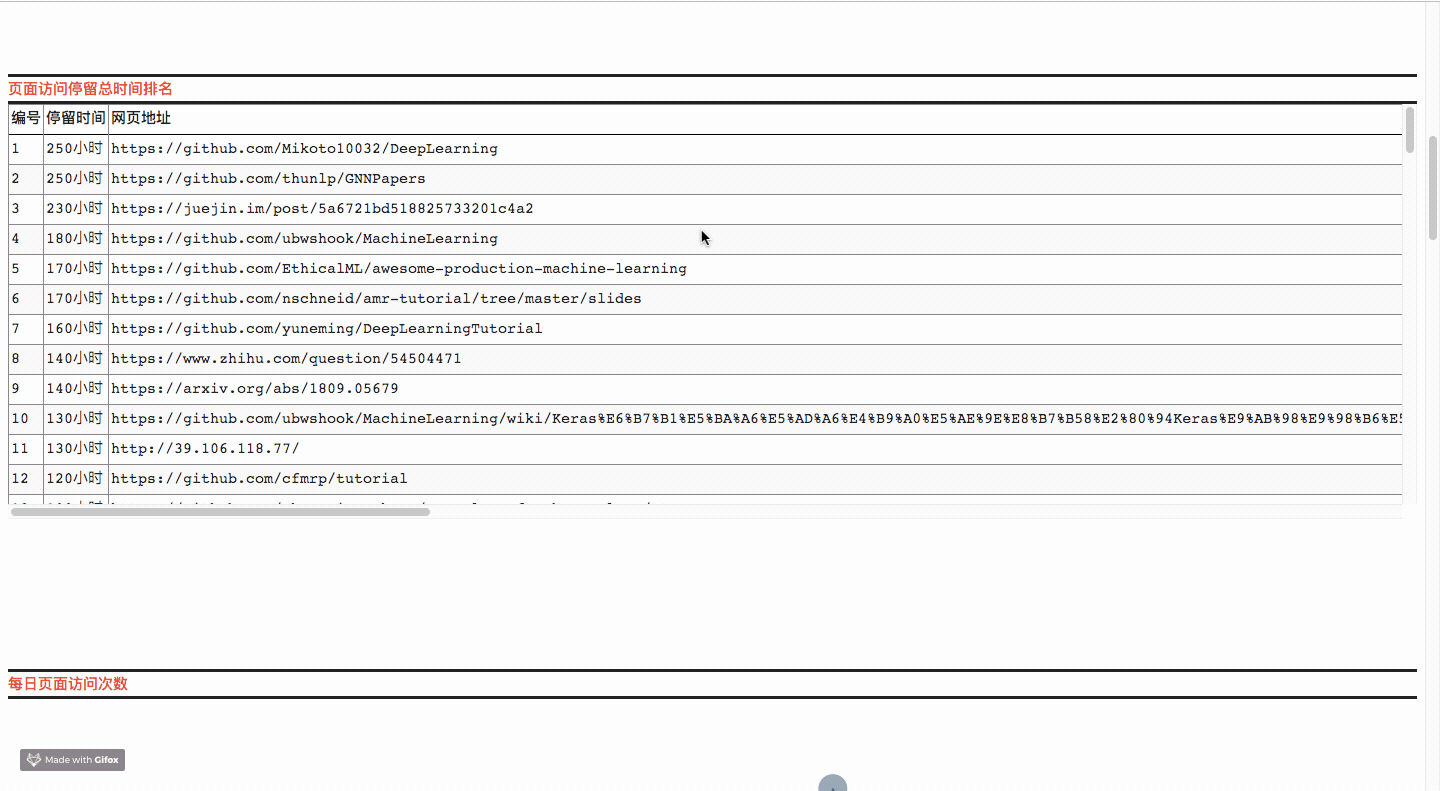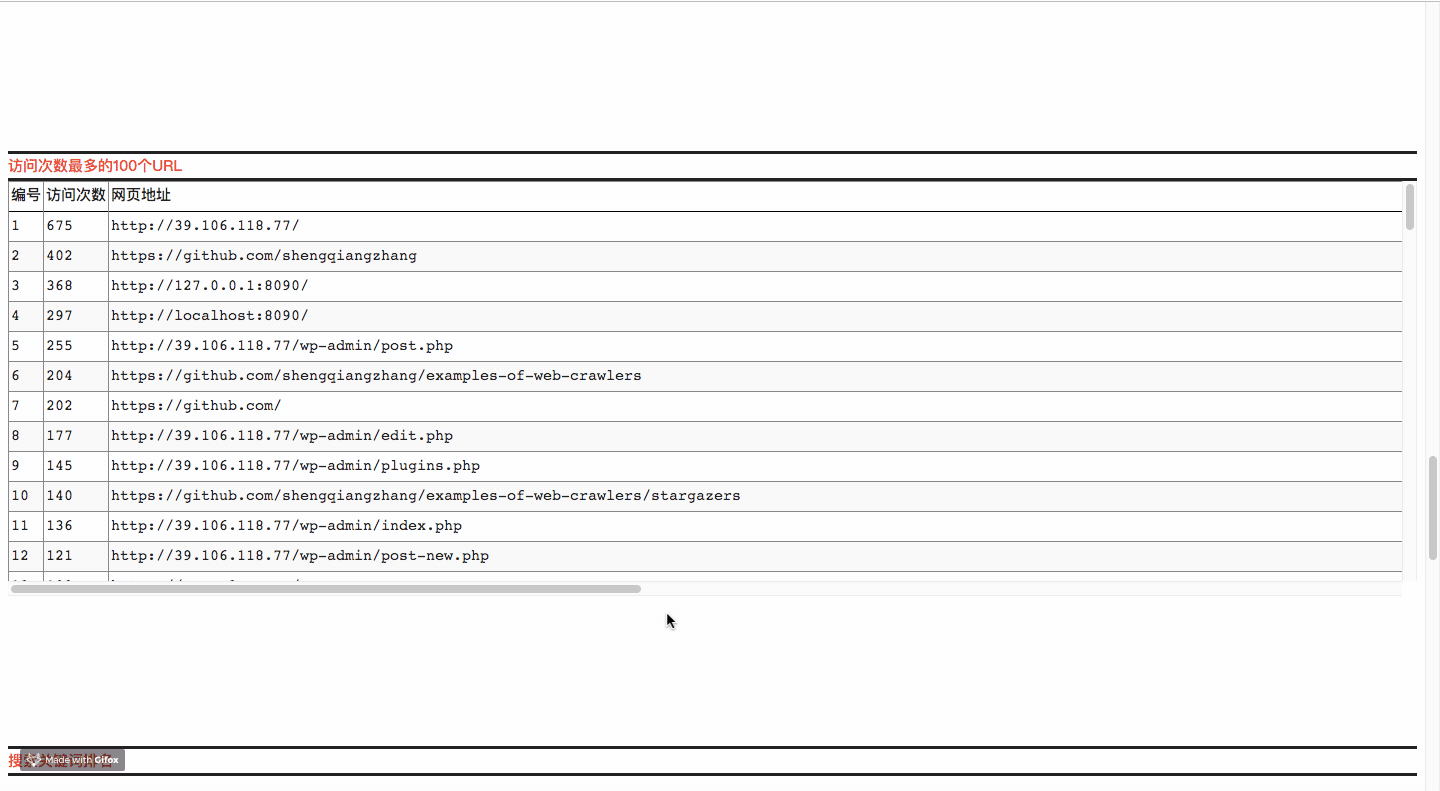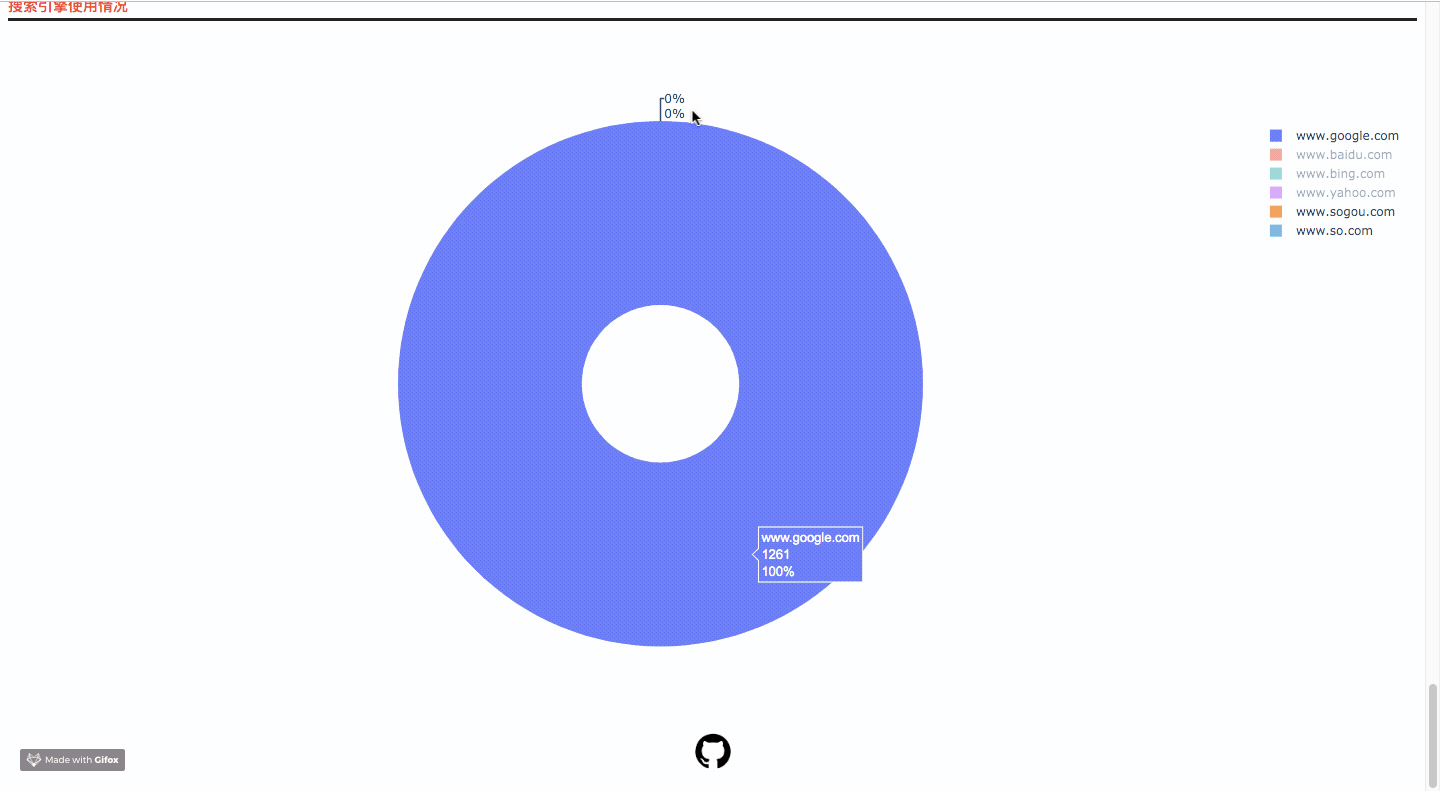
Code Ideas
1. Directory structure
First, let's look at the overall directory structure.
Code ├─ app_callback.py Callback function to realize background function ├─ app_configuration.py web Server configuration ├─ app_layout.py web Front-end page configuration ├─ app_plot.py web Chart drawing ├─ app.py web Server startup ├─ assets web Some static resource files needed │ ├─ css web Front-end element layout file │ │ ├─ custum-styles_phyloapp.css │ │ └─ stylesheet.css │ ├─ image web Front end logo Icon │ │ ├─ GitHub-Mark-Light.png │ └─ static web Front Help Page │ │ ├─ help.html │ │ └─ help.md ├─ history_data.py analysis chrome Historical Record Documents └─ requirement.txt Dependency libraries required by programs
app_callback.py
The program is based on python and deployed using dash web lightweight framework. app_callback.py is mainly used for callbacks, which can be understood as background functions.app_configuration.py
As the name implies, some configuration operations on the web server.app_layout..py
web front-end page configuration, including html, css elements.app_plot.py
This is mainly for the realization of some web front-end chart data.app.py
Start up the web server.assets
The static resource directory is used to store some static resource data that we need.history_data.py
Connect to sqlite database and parse Chrome history file.requirement.txt
Dependency libraries needed to run this program.
2. Parsing historical records file data
The file related to parsing historical record file data is history_data.py file. Let's analyze it one by one.
# Query database content
def query_sqlite_db(history_db, query):
# Query sqlite database
# Note that History is a file with no suffix name. It's not a directory.
conn = sqlite3.connect(history_db)
cursor = conn.cursor()
# Using sqlite to view the software, you can clearly see the field url of table visits = the field id of table urls
# Connect the tables urls and visits and get the specified data
select_statement = query
# Execute database query statements
cursor.execute(select_statement)
# Get data in tuple format
results = cursor.fetchall()
# Close
cursor.close()
conn.close()
return results
The code flow of this function is as follows:
- Connect sqlite database, execute query statement, return query structure, and finally close database connection.
# Get sorted historical data
def get_history_data(history_file_path):
try:
# Getting database content
# Data format is tuple
select_statement = "SELECT urls.id, urls.url, urls.title, urls.last_visit_time, urls.visit_count, visits.visit_time, visits.from_visit, visits.transition, visits.visit_duration FROM urls, visits WHERE urls.id = visits.url;"
result = query_sqlite_db(history_file_path, select_statement)
# Sort the results by the first element
# The sort and sort built-in functions prioritize the first element, then the second element, and so on.
result_sort = sorted(result, key=lambda x: (x[0], x[1], x[2], x[3], x[4], x[5], x[6], x[7], x[8]))
# Returns sorted data
return result_sort
except:
# print('Error reading!')
return 'error'
The code flow of this function is as follows:
- Set up the database query statement select_statement and call the query_sqlite_db() function to get the parsed history file data. The returned historical data files are sorted according to different element rules. So far, the sorted and parsed historical records data files have been successfully obtained.
3. Basic configuration of web server
The files related to the basic configuration of the web server are app_configuration.py and app.py files. Including setting the port number of the web server, access rights, static resource directory and so on.
4. Front-end page deployment
The files related to the front-end deployment are app_layout.py and app_plot.py, as well as the assets directory.
The front-end layout mainly includes the following elements:
- Upload History File Component
- Draw page access number component
- Drawing Page Access Stay Total Time Ranking Component
- Scatter Chart Component for Daily Page Access Number
- Scatter Chart Component of Access Number at Different Times of a Day
- Top 10 URL components accessed
- Search keyword ranking component
- Search Engine Usage Component
In app_layout.py, the configuration of these components is mostly the same as that of normal HTML and CSS configurations, so we only take the configuration of page access ranking components as an example.
# Ranking of page visits
html.Div(
style={'margin-bottom':'150px'},
children=[
html.Div(
style={'border-top-style':'solid','border-bottom-style':'solid'},
className='row',
children=[
html.Span(
children='Ranking of page visits, ',
style={'font-weight': 'bold', 'color':'red'}
),
html.Span(
children='Number of Displays:',
),
dcc.Input(
id='input_website_count_rank',
type='text',
value=10,
style={'margin-top':'10px', 'margin-bottom':'10px'}
),
]
),
html.Div(
style={'position': 'relative', 'margin': '0 auto', 'width': '100%', 'padding-bottom': '50%', },
children=[
dcc.Loading(
children=[
dcc.Graph(
id='graph_website_count_rank',
style={'position': 'absolute', 'width': '100%', 'height': '100%', 'top': '0',
'left': '0', 'bottom': '0', 'right': '0'},
config={'displayModeBar': False},
),
],
type='dot',
style={'position': 'absolute', 'top': '50%', 'left': '50%', 'transform': 'translate(-50%,-50%)'}
),
],
)
]
)As you can see, although written by python, as long as people with front-end experience can easily add or delete elements on this basis, so we will not elaborate on how to use html and css.
In app_plot.py, it is mainly related to drawing graphs. The plotly library is used, which is a drawing component library for web interaction.
This paper takes drawing the ranking bar chart of page visiting frequency as an example to show how to use plotly library to draw.
# Draw a bar chart of page access frequency ranking
def plot_bar_website_count_rank(value, history_data):
# Frequency Dictionary
dict_data = {}
# Traversing historical records
for data in history_data:
url = data[1]
# Simplified url
key = url_simplification(url)
if (key in dict_data.keys()):
dict_data[key] += 1
else:
dict_data[key] = 0
# Screen out the data with the highest frequency of the first k
k = convert_to_number(value)
top_10_dict = get_top_k_from_dict(dict_data, k)
figure = go.Figure(
data=[
go.Bar(
x=[i for i in top_10_dict.keys()],
y=[i for i in top_10_dict.values()],
name='bar',
marker=go.bar.Marker(
color='rgb(55, 83, 109)'
)
)
],
layout=go.Layout(
showlegend=False,
margin=go.layout.Margin(l=40, r=0, t=40, b=30),
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
xaxis=dict(title='website'),
yaxis=dict(title='frequency')
)
)
return figureThe code flow of this function is as follows:
- First, the history_data returned after parsing the database file is traversed to obtain the URL data, and the url_simplification(url) alignment is called to simplify. Then, the simplified URL is stored in the dictionary in turn.
- Call get_top_k_from_dict(dict_data, k) to get the data of the first k maximum values from dictionary dict_data.
- Then we started to draw the bar chart. Use go.Bar() to draw a histogram, where x and y represent the values corresponding to the attributes and attributes, in the list format. xaxis and yaxis `respectively set the title of the corresponding coordinate axis
- Returns a figure object for easy transfer to the front end.
The assets directory contains image s and css, which are used for front-end layout.
5. Background deployment
The files related to background deployment are app_callback.py files. This file uses callbacks to update the front-end page layout.
First, let's look at the callback function for ranking page access frequencies:
# Page Access Frequency Ranking
@app.callback(
dash.dependencies.Output('graph_website_count_rank', 'figure'),
[
dash.dependencies.Input('input_website_count_rank', 'value'),
dash.dependencies.Input('store_memory_history_data', 'data')
]
)
def update(value, store_memory_history_data):
# Acquiring the History Document Correctly
if store_memory_history_data:
history_data = store_memory_history_data['history_data']
figure = plot_bar_website_count_rank(value, history_data)
return figure
else:
# Cancel updating page data
raise dash.exceptions.PreventUpdate("cancel the callback")The code flow of this function is as follows:
- First, determine what the input is (the data triggering the callback), what the output is (the data of the callback output), and what data you need to bring with you. dash.dependencies.Input refers to the data that triggers the callback, and dash.dependencies.Input ('input_website_count_rank','value') indicates that the callback is triggered when the value of the component whose id is input_website_count_rank changes. The result of the callback after update(value, store_memory_history_data) is output to the value with id graph_website_count_rank, which in general means changing its value.
- Analysis of def update(value, store_memory_history_data). First, it determines whether the input data store_memory_history_data is not an empty object, then reads the history_data of the history file, then calls the plot_bar_website_count_rank() in the app_plot.py file just mentioned, returns a figure object, and returns the object to the front end. At this point, the layout of the front-end page will show the chart of page access frequency ranking.
There is another need to say about the process of the last file, here we first post the code:
# Upload File Callback
@app.callback(
dash.dependencies.Output('store_memory_history_data', 'data'),
[
dash.dependencies.Input('dcc_upload_file', 'contents')
]
)
def update(contents):
if contents is not None:
# Receiving base64-encoded data
content_type, content_string = contents.split(',')
# base64 decoding of files uploaded by client
decoded = base64.b64decode(content_string)
# Adding suffixes to files uploaded by clients to prevent duplicate overwriting of files
# Ensure that the filename does not duplicate as follows
suffix = [str(random.randint(0,100)) for i in range(10)]
suffix = "".join(suffix)
suffix = suffix + str(int(time.time()))
# Final filename
file_name = 'History_' + suffix
# print(file_name)
# Create a directory to store files
if (not (exists('data'))):
makedirs('data')
# File path to write
path = 'data' + '/' + file_name
# Write to local disk file
with open(file=path, mode='wb+') as f:
f.write(decoded)
# Using sqlite to read local disk files
# Obtaining historical data
history_data = get_history_data(path)
# Getting search keyword data
search_word = get_search_word(path)
# Determine whether the read data is correct
if (history_data != 'error'):
# find
date_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print('New data received from a client, Correct data, time:{}'.format(date_time))
store_data = {'history_data': history_data, 'search_word': search_word}
return store_data
else:
# Can't find
date_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print('New data received from a client, data error, time:{}'.format(date_time))
return None
return NoneThe code flow of this function is as follows:
Firstly, it judges whether the data content uploaded by the user is not empty, and then decodes the file uploaded by the client with base64. In addition, suffixes are added to the files uploaded by the client to prevent the file from overlapping repeatedly, and finally the files uploaded by the client are written to the local disk files.
After writing, sqlite is used to read the local disk file. If it is read correctly, the parsed data will be returned. Otherwise, it will be returned to None.
How to run
Online Demonstration Program: http://39.106.118.77:8090 (Ordinary server, no pressure measurement)
Running this program is very simple, just follow the following commands to run:
# Jump to the current directory cd Catalog Name # Unload dependency libraries first pip uninstall -y -r requirement.txt # Re-install Dependency Library pip install -r requirement.txt # Start running python app.py # After running successfully, open http://localhost:8090 through browser
supplement
The full version of the source code is stored in github Up, download if necessary
The project is continuously updated. You are welcome. star project