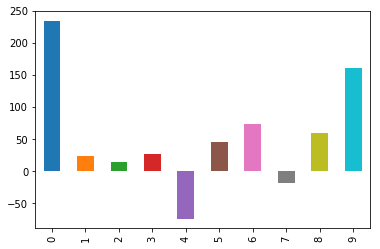XIX. Data sorting (5)
Standardization column
# Import required modules
import pandas as pd
from sklearn import preprocessing
# Set chart inline
%matplotlib inline
# Create a sample data frame with an denormalized column
data = {'score': [234,24,14,27,-74,46,73,-18,59,160]}
df = pd.DataFrame(data)
df
|
score |
| 0 |
234 |
| 1 |
24 |
| 2 |
14 |
| 3 |
27 |
| 4 |
-74 |
| 5 |
46 |
| 6 |
73 |
| 7 |
-18 |
| 8 |
59 |
| 9 |
160 |
# View as denormalized data
df['score'].plot(kind='bar')
# <matplotlib.axes._subplots.AxesSubplot at 0x11b9c88d0>
# Create x, where the value of the resulting column of X is a floating-point number
x = df[['score']].values.astype(float)
# Creating a minmax processor object
min_max_scaler = preprocessing.MinMaxScaler()
# Create an object, transform the data, and fit the minmax processor
x_scaled = min_max_scaler.fit_transform(x)
# Running the normalizer on a data frame
df_normalized = pd.DataFrame(x_scaled)
# View data frame
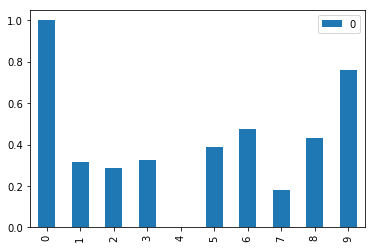
df_normalized
|
0 |
| 0 |
1.000000 |
| 1 |
0.318182 |
| 2 |
0.285714 |
| 3 |
0.327922 |
| 4 |
0.000000 |
| 5 |
0.389610 |
| 6 |
0.477273 |
| 7 |
0.181818 |
| 8 |
0.431818 |
| 9 |
0.759740 |
# Draw data frame
df_normalized.plot(kind='bar')
# <matplotlib.axes._subplots.AxesSubplot at 0x11ba31c50>
Cascading tables in Pandas
# Import module
import pandas as pd
raw_data = {'regiment': ['Nighthawks', 'Nighthawks', 'Nighthawks', 'Nighthawks', 'Dragoons', 'Dragoons', 'Dragoons', 'Dragoons', 'Scouts', 'Scouts', 'Scouts', 'Scouts'],
'company': ['1st', '1st', '2nd', '2nd', '1st', '1st', '2nd', '2nd','1st', '1st', '2nd', '2nd'],
'TestScore': [4, 24, 31, 2, 3, 4, 24, 31, 2, 3, 2, 3]}
df = pd.DataFrame(raw_data, columns = ['regiment', 'company', 'TestScore'])
df
|
regiment |
company |
TestScore |
| 0 |
Nighthawks |
1st |
4 |
| 1 |
Nighthawks |
1st |
24 |
| 2 |
Nighthawks |
2nd |
31 |
| 3 |
Nighthawks |
2nd |
2 |
| 4 |
Dragoons |
1st |
3 |
| 5 |
Dragoons |
1st |
4 |
| 6 |
Dragoons |
2nd |
24 |
| 7 |
Dragoons |
2nd |
31 |
| 8 |
Scouts |
1st |
2 |
| 9 |
Scouts |
1st |
3 |
| 10 |
Scouts |
2nd |
2 |
| 11 |
Scouts |
2nd |
3 |
# Create a PivotTable of group mean by company and team
pd.pivot_table(df, index=['regiment','company'], aggfunc='mean')
|
|
TestScore |
| regiment |
company |
|
| Dragoons |
1st |
3.5 |
|
2nd |
27.5 |
| Nighthawks |
1st |
14.0 |
|
2nd |
16.5 |
| Scouts |
1st |
2.5 |
|
2nd |
2.5 |
# Create a PivotTable of group counts by company and team
df.pivot_table(index=['regiment','company'], aggfunc='count')
|
|
TestScore |
| regiment |
company |
|
| Dragoons |
1st |
2 |
|
2nd |
2 |
| Nighthawks |
1st |
2 |
|
2nd |
2 |
| Scouts |
1st |
2 |
|
2nd |
2 |
Quick modification of string columns in Pandas
I often need or want to change the case of all items in a string (for example, Brazil to Brazil, etc.). There are many ways to achieve this, but I've determined that this is the easiest and fastest way.
# Import pandas
import pandas as pd
# Create a list of names
first_names = pd.Series(['Steve Murrey', 'Jane Fonda', 'Sara McGully', 'Mary Jane'])
# Print column
first_names
'''
0 Steve Murrey
1 Jane Fonda
2 Sara McGully
3 Mary Jane
dtype: object
'''
# Print column lowercase
first_names.str.lower()
'''
0 steve murrey
1 jane fonda
2 sara mcgully
3 mary jane
dtype: object
'''
# Print upper case of columns
first_names.str.upper()
'''
0 STEVE MURREY
1 JANE FONDA
2 SARA MCGULLY
3 MARY JANE
dtype: object
'''
# Print column header case
first_names.str.title()
'''
0 Steve Murrey
1 Jane Fonda
2 Sara Mcgully
3 Mary Jane
dtype: object
'''
# Print columns separated by spaces
first_names.str.split(" ")
'''
0 [Steve, Murrey]
1 [Jane, Fonda]
2 [Sara, McGully]
3 [Mary, Jane]
dtype: object
'''
# Print initial capital columns
first_names.str.capitalize()
'''
0 Steve murrey
1 Jane fonda
2 Sara mcgully
3 Mary jane
dtype: object
'''
I see. More string methods in Here.
Random sampling data frame
# Import module
import pandas as pd
import numpy as np
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'preTestScore': [4, 24, 31, 2, 3],
'postTestScore': [25, 94, 57, 62, 70]}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'preTestScore', 'postTestScore'])
df
|
first_name |
last_name |
age |
preTestScore |
postTestScore |
| 0 |
Jason |
Miller |
42 |
4 |
25 |
| 1 |
Molly |
Jacobson |
52 |
24 |
94 |
| 2 |
Tina |
Ali |
36 |
31 |
57 |
| 3 |
Jake |
Milner |
24 |
2 |
62 |
| 4 |
Amy |
Cooze |
73 |
3 |
70 |
# Do not put back a random subset of size 2
df.take(np.random.permutation(len(df))[:2])
|
first_name |
last_name |
age |
preTestScore |
postTestScore |
| 1 |
Molly |
Jacobson |
52 |
24 |
94 |
| 4 |
Amy |
Cooze |
73 |
3 |
70 |
Row ranking of data frames
# Import module
import pandas as pd
# Create data frame
data = {'name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'year': [2012, 2012, 2013, 2014, 2014],
'reports': [4, 24, 31, 2, 3],
'coverage': [25, 94, 57, 62, 70]}
df = pd.DataFrame(data, index = ['Cochice', 'Pima', 'Santa Cruz', 'Maricopa', 'Yuma'])
df
|
coverage |
name |
reports |
year |
| Cochice |
25 |
Jason |
4 |
2012 |
| Pima |
94 |
Molly |
24 |
2012 |
| Santa Cruz |
57 |
Tina |
31 |
2013 |
| Maricopa |
62 |
Jake |
2 |
2014 |
| Yuma |
70 |
Amy |
3 |
2014 |
5 rows × 4 columns
# Create a new column that is the ascending rank of the coverage value
df['coverageRanked'] = df['coverage'].rank(ascending=1)
df
|
coverage |
name |
reports |
year |
coverageRanked |
| Cochice |
25 |
Jason |
4 |
2012 |
1 |
| Pima |
94 |
Molly |
24 |
2012 |
5 |
| Santa Cruz |
57 |
Tina |
31 |
2013 |
2 |
| Maricopa |
62 |
Jake |
2 |
2014 |
3 |
| Yuma |
70 |
Amy |
3 |
2014 |
4 |
5 rows × 5 columns
Regular expression basis
# Import regular package
import re
import sys
text = 'The quick brown fox jumped over the lazy black bear.'
three_letter_word = '\w{3}'
pattern_re = re.compile(three_letter_word); pattern_re
re.compile(r'\w{3}', re.UNICODE)
re_search = re.search('..own', text)
if re_search:
# Print search results
print(re_search.group())
# brown
re.match
re.match() is only used to match the beginning of a string or the entire string. For anything else, use re.search.
Match all three letter words in text
# Match all three letter words in text
re_match = re.match('..own', text)
if re_match:
# Print all matches
print(re_match.group())
else:
# Print this
print('No matches')
# No matches
re.split
# Use 'e' as the separator to split the string.
re_split = re.split('e', text); re_split
# ['Th', ' quick brown fox jump', 'd ov', 'r th', ' lazy black b', 'ar.']
re.sub
Replace the regular expression pattern string with something else. 3 represents the maximum number of replacements to make.
# Replace the first three 'e' instances with 'e' and print them out
re_sub = re.sub('e', 'E', text, 3); print(re_sub)
# ThE quick brown fox jumpEd ovEr the lazy black bear.
Regular expression example
# Import regex
import re
# Create some data
text = 'A flock of 120 quick brown foxes jumped over 30 lazy brown, bears.'
re.findall('^A', text)
# ['A']
re.findall('bears.$', text)
# ['bears.']
re.findall('f..es', text)
# ['foxes']
# Find all vowels
re.findall('[aeiou]', text)
# ['o', 'o', 'u', 'i', 'o', 'o', 'e', 'u', 'e', 'o', 'e', 'a', 'o', 'e', 'a']
# Find all characters that are not lowercase vowels
re.findall('[^aeiou]', text)
'''
['A',
' ',
'f',
'l',
'c',
'k',
' ',
'f',
' ',
'1',
'2',
'0',
' ',
'q',
'c',
'k',
' ',
'b',
'r',
'w',
'n',
' ',
'f',
'x',
's',
' ',
'j',
'm',
'p',
'd',
' ',
'v',
'r',
' ',
'3',
'0',
' ',
'l',
'z',
'y',
' ',
'b',
'r',
'w',
'n',
',',
' ',
'b',
'r',
's',
'.']
'''
re.findall('a|A', text)
# ['A', 'a', 'a']
# Find any instances of 'fox'
re.findall('(foxes)', text)
# ['foxes']
# Find all five letter words
re.findall('\w\w\w\w\w', text)
# ['flock', 'quick', 'brown', 'foxes', 'jumpe', 'brown', 'bears']
re.findall('\W\W', text)
# [', ']
re.findall('\s', text)
# [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ']
re.findall('\S\S', text)
'''
['fl',
'oc',
'of',
'12',
'qu',
'ic',
'br',
'ow',
'fo',
'xe',
'ju',
'mp',
'ed',
'ov',
'er',
'30',
'la',
'zy',
'br',
'ow',
'n,',
'be',
'ar',
's.']
'''
re.findall('\d\d\d', text)
# ['120']
re.findall('\D\D\D\D\D', text)
'''
['A flo',
'ck of',
' quic',
'k bro',
'wn fo',
'xes j',
'umped',
' over',
' lazy',
' brow',
'n, be']
'''
re.findall('\AA', text)
# ['A']
re.findall('bears.\Z', text)
# ['bears.']
re.findall('\b[foxes]', text)
# []
re.findall('\n', text)
# []
re.findall('[Ff]oxes', 'foxes Foxes Doxes')
# ['foxes', 'Foxes']
re.findall('[Ff]oxes', 'foxes Foxes Doxes')
# ['foxes', 'Foxes']
re.findall('[a-z]', 'foxes Foxes')
# ['f', 'o', 'x', 'e', 's', 'o', 'x', 'e', 's']
re.findall('[A-Z]', 'foxes Foxes')
# ['F']
re.findall('[a-zA-Z0-9]', 'foxes Foxes')
# ['f', 'o', 'x', 'e', 's', 'F', 'o', 'x', 'e', 's']
re.findall('[^aeiou]', 'foxes Foxes')
# ['f', 'x', 's', ' ', 'F', 'x', 's']
re.findall('[^0-9]', 'foxes Foxes')
# ['f', 'o', 'x', 'e', 's', ' ', 'F', 'o', 'x', 'e', 's']
re.findall('foxes?', 'foxes Foxes')
# ['foxes']
re.findall('ox*', 'foxes Foxes')
# ['ox', 'ox']
re.findall('ox+', 'foxes Foxes')
# ['ox', 'ox']
re.findall('\d{3}', text)
# ['120']
re.findall('\d{2,}', text)
# ['120', '30']
re.findall('\d{2,3}', text)
# ['120', '30']
re.findall('^A', text)
# ['A']
re.findall('bears.$', text)
# ['bears.']
re.findall('\AA', text)
# ['A']
re.findall('bears.\Z', text)
# ['bears.']
re.findall('bears(?=.)', text)
# ['bears']
re.findall('foxes(?!!)', 'foxes foxes!')
# ['foxes']
re.findall('foxes|foxes!', 'foxes foxes!')
# ['foxes', 'foxes']
re.findall('fox(es!)', 'foxes foxes!')
# ['es!']
re.findall('foxes(!)', 'foxes foxes!')
# ['!']
Re index sequence and data frame
# Import module
import pandas as pd
import numpy as np
# Create a fire risk sequence for Southern Arizona
brushFireRisk = pd.Series([34, 23, 12, 23], index = ['Bisbee', 'Douglas', 'Sierra Vista', 'Tombstone'])
brushFireRisk
'''
Bisbee 34
Douglas 23
Sierra Vista 12
Tombstone 23
dtype: int64
'''
# Reindex the sequence and create a new sequence variable
brushFireRiskReindexed = brushFireRisk.reindex(['Tombstone', 'Douglas', 'Bisbee', 'Sierra Vista', 'Barley', 'Tucson'])
brushFireRiskReindexed
'''
Tombstone 23.0
Douglas 23.0
Bisbee 34.0
Sierra Vista 12.0
Barley NaN
Tucson NaN
dtype: float64
'''
# Reindex the sequence and fill in 0 at any missing index
brushFireRiskReindexed = brushFireRisk.reindex(['Tombstone', 'Douglas', 'Bisbee', 'Sierra Vista', 'Barley', 'Tucson'], fill_value = 0)
brushFireRiskReindexed
'''
Tombstone 23
Douglas 23
Bisbee 34
Sierra Vista 12
Barley 0
Tucson 0
dtype: int64
'''
# Create data frame
data = {'county': ['Cochice', 'Pima', 'Santa Cruz', 'Maricopa', 'Yuma'],
'year': [2012, 2012, 2013, 2014, 2014],
'reports': [4, 24, 31, 2, 3]}
df = pd.DataFrame(data)
df
|
county |
reports |
year |
| 0 |
Cochice |
4 |
2012 |
| 1 |
Pima |
24 |
2012 |
| 2 |
Santa Cruz |
31 |
2013 |
| 3 |
Maricopa |
2 |
2014 |
| 4 |
Yuma |
3 |
2014 |
# Change row order (index)
df.reindex([4, 3, 2, 1, 0])
|
county |
reports |
year |
| 4 |
Yuma |
3 |
2014 |
| 3 |
Maricopa |
2 |
2014 |
| 2 |
Santa Cruz |
31 |
2013 |
| 1 |
Pima |
24 |
2012 |
| 0 |
Cochice |
4 |
2012 |
# Change column order (index)
columnsTitles = ['year', 'reports', 'county']
df.reindex(columns=columnsTitles)
|
year |
reports |
county |
| 0 |
2012 |
4 |
Cochice |
| 1 |
2012 |
24 |
Pima |
| 2 |
2013 |
31 |
Santa Cruz |
| 3 |
2014 |
2 |
Maricopa |
| 4 |
2014 |
3 |
Yuma |
Rename column title
Come from StackOverflow Upper rgalbo.
# Import required modules
import pandas as pd
# Create a dictionary for the list as a value
raw_data = {'0': ['first_name', 'Molly', 'Tina', 'Jake', 'Amy'],
'1': ['last_name', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'2': ['age', 52, 36, 24, 73],
'3': ['preTestScore', 24, 31, 2, 3]}
# Create data frame
df = pd.DataFrame(raw_data)
# View data frame
df
|
0 |
1 |
2 |
3 |
| 0 |
first_name |
last_name |
age |
preTestScore |
| 1 |
Molly |
Jacobson |
52 |
24 |
| 2 |
Tina |
Ali |
36 |
31 |
| 3 |
Jake |
Milner |
24 |
2 |
| 4 |
Amy |
Cooze |
73 |
3 |
# Create a new variable named header from the first row of the dataset
header = df.iloc[0]
'''
0 first_name
1 last_name
2 age
3 preTestScore
Name: 0, dtype: object
'''
# Replace the data frame with a new data frame without the first row
df = df[1:]
# Rename column values for data frames using the header variable
df.rename(columns = header)
|
first_name |
last_name |
age |
preTestScore |
| 1 |
Molly |
Jacobson |
52 |
24 |
| --- |
--- |
--- |
--- |
--- |
| 2 |
Tina |
Ali |
36 |
31 |
| --- |
--- |
--- |
--- |
--- |
| 3 |
Jake |
Milner |
24 |
2 |
| --- |
--- |
--- |
--- |
--- |
| 4 |
Amy |
Cooze |
73 |
3 |
| --- |
--- |
--- |
--- |
--- |
Rename column names for multiple data frames
# Import module
import pandas as pd
# Set the maximum row display of ipython
pd.set_option('display.max_row', 1000)
# Set the maximum column width of ipython
pd.set_option('display.max_columns', 50)
# Create sample data frame
data = {'Commander': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'Date': ['2012, 02, 08', '2012, 02, 08', '2012, 02, 08', '2012, 02, 08', '2012, 02, 08'],
'Score': [4, 24, 31, 2, 3]}
df = pd.DataFrame(data, index = ['Cochice', 'Pima', 'Santa Cruz', 'Maricopa', 'Yuma'])
df
|
Commander |
Date |
Score |
| Cochice |
Jason |
2012, 02, 08 |
4 |
| Pima |
Molly |
2012, 02, 08 |
24 |
| Santa Cruz |
Tina |
2012, 02, 08 |
31 |
| Maricopa |
Jake |
2012, 02, 08 |
2 |
| Yuma |
Amy |
2012, 02, 08 |
3 |
# Rename column name
df.columns = ['Leader', 'Time', 'Score']
df
|
Leader |
Time |
Score |
| Cochice |
Jason |
2012, 02, 08 |
4 |
| Pima |
Molly |
2012, 02, 08 |
24 |
| Santa Cruz |
Tina |
2012, 02, 08 |
31 |
| Maricopa |
Jake |
2012, 02, 08 |
2 |
| Yuma |
Amy |
2012, 02, 08 |
3 |
df.rename(columns={'Leader': 'Commander'}, inplace=True)
df
|
Commander |
Time |
Score |
| Cochice |
Jason |
2012, 02, 08 |
4 |
| Pima |
Molly |
2012, 02, 08 |
24 |
| Santa Cruz |
Tina |
2012, 02, 08 |
31 |
| Maricopa |
Jake |
2012, 02, 08 |
2 |
| Yuma |
Amy |
2012, 02, 08 |
3 |
Replacement value
# Import module
import pandas as pd
import numpy as np
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'preTestScore': [-999, -999, -999, 2, 1],
'postTestScore': [2, 2, -999, 2, -999]}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'preTestScore', 'postTestScore'])
df
|
first_name |
last_name |
age |
preTestScore |
postTestScore |
| 0 |
Jason |
Miller |
42 |
-999 |
2 |
| 1 |
Molly |
Jacobson |
52 |
-999 |
2 |
| 2 |
Tina |
Ali |
36 |
-999 |
-999 |
| 3 |
Jake |
Milner |
24 |
2 |
2 |
| 4 |
Amy |
Cooze |
73 |
1 |
-999 |
# Replace all - 999 with NAN
df.replace(-999, np.nan)
|
first_name |
last_name |
age |
preTestScore |
postTestScore |
| 0 |
Jason |
Miller |
42 |
NaN |
2.0 |
| 1 |
Molly |
Jacobson |
52 |
NaN |
2.0 |
| 2 |
Tina |
Ali |
36 |
NaN |
NaN |
| 3 |
Jake |
Milner |
24 |
2.0 |
2.0 |
| 4 |
Amy |
Cooze |
73 |
1.0 |
NaN |
Save data frame as CSV
# Import module
import pandas as pd
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'preTestScore': [4, 24, 31, 2, 3],
'postTestScore': [25, 94, 57, 62, 70]}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'preTestScore', 'postTestScore'])
df
|
first_name |
last_name |
age |
preTestScore |
postTestScore |
| 0 |
Jason |
Miller |
42 |
4 |
25 |
| 1 |
Molly |
Jacobson |
52 |
24 |
94 |
| 2 |
Tina |
Ali |
36 |
31 |
57 |
| 3 |
Jake |
Milner |
24 |
2 |
62 |
| 4 |
Amy |
Cooze |
73 |
3 |
70 |
Save the data frame named df as csv.
df.to_csv('example.csv')