Preview video: https://www.bilibili.com/video/BV1uT4y1F7ap Spark: be based on Scala language Flink: be based on Java language
01 - [understand] - Spark course arrangement
Generally speaking, it is divided into three major aspects: Spark basic environment, spark offline analysis and spark real-time analysis, as shown in the following figure:
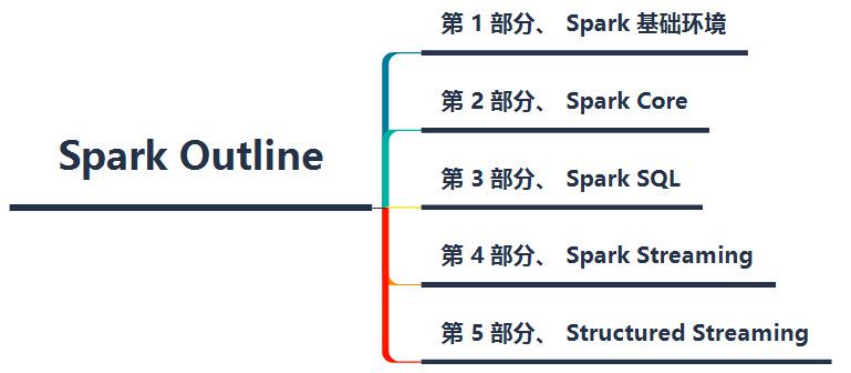
At present, the most used modules in Spark framework in Enterprises: SparkSQL (offline analysis) and structured streaming (real-time streaming analysis).
02 - [understand] - outline of today's course content
It mainly explains two aspects: Spark framework overview and spark quick start.
1,Spark Framework overview What is it? Four characteristics Module (part) Frame operation mode 2,Spark quick get start Environmental preparation Spark Run program in local mode Classic big data program: word frequency statistics WordCount provide WEB UI Monitoring interface
03 - [Master] - overview of Spark framework [what is Spark]
Spark is a general big data framework developed by the University of California, Berkeley AMP Laboratory (Algorithms Machines and People Lab). Spark's development history has gone through several important stages, as shown in the figure below:
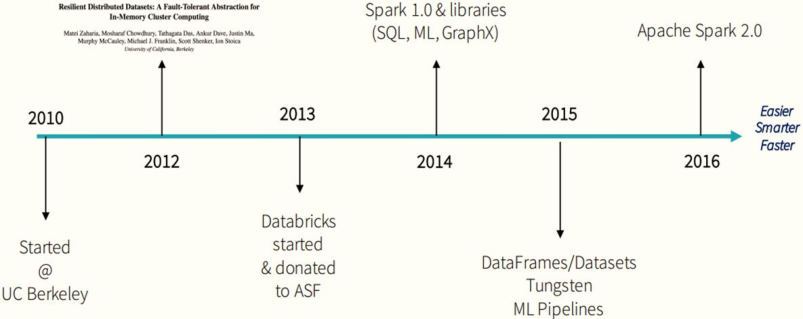
Spark is a fast, universal and scalable big data analysis engine. It was born in AMPLab, University of California, Berkeley in 2009. It was open source in 2010. It became an Apache incubation project in June 2013 and a top-level project in Apache in February 2014. It uses Scala to write the project framework.

Official document definition:

1,Analysis engine similar MapReduce Framework, analyzing data 2,Unify( Unified)Analysis engine Offline analysis, similar MapReduce Interactive analysis, similar Hive Flow analysis, similar Storm,Flink Or double 11 large screen statistics Scientific analysis, Python and R machine learning Figure calculation 3,Unified analysis engine for large-scale and massive data Big data analysis engine [Distributed computing, divide and conquer]
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-5Rk9bK5g-1625406507847)(/img/image-20210419160056620.png)]
The Spark framework is excellent because the core data structure [RDD: Resilient Distributed Datasets] can be regarded as a collection.
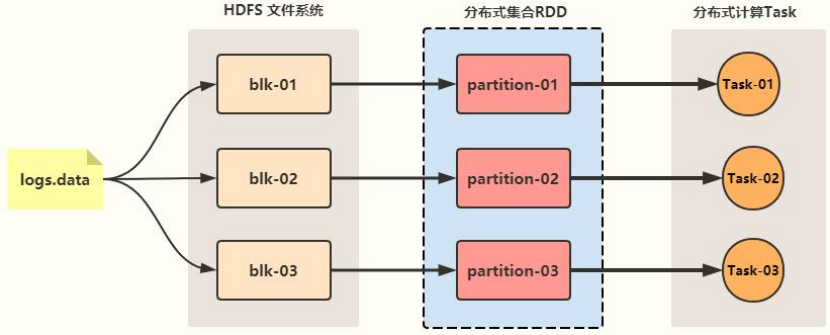
04 - [understand] - overview of Spark framework [four features of Spark]
Spark has the characteristics of fast running speed, good ease of use, strong universality and running everywhere.

Officials claim that its computing speed in memory is 100 times faster than Hadoop's MapReduce and 10 times faster in hard disk.

There are two differences between Spark processing data and MapReduce processing data:
- First, when Spark processes data, it can store the intermediate processing result data in memory;
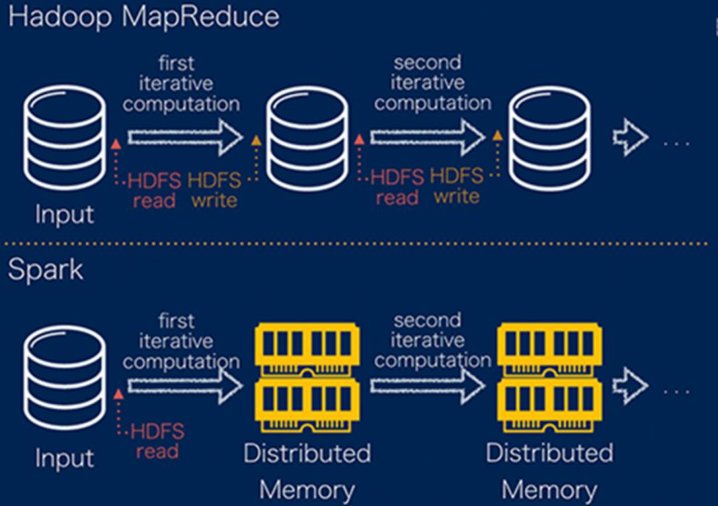
- Second, spark jobs are scheduled in DAG mode, and each Task is executed in Thread mode, not in Process mode like MapReduce.
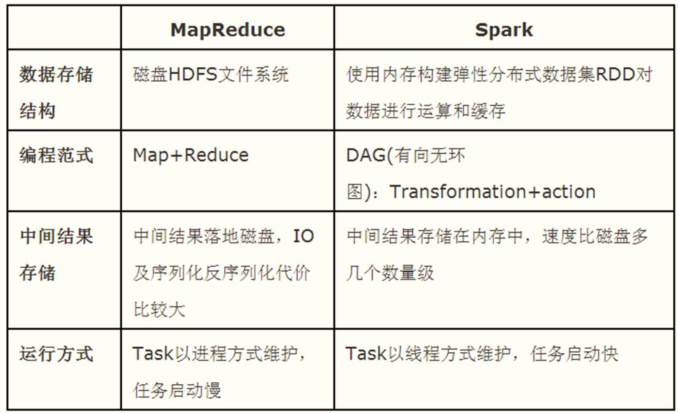
Thinking: Spark framework only deals with the analysis data engine (framework), so the problem is:
- First, where is the processed data stored???
- Any storage device (storage engine), such as HDFS, HBase, Redis, Kafka, Es, etc
- Handle text data, textfile, JSON format data, column storage, etc
- Second, where does Spark data processing program run???
- Local mode
- Hadoop YARN cluster
- Stand alone cluster, similar to YARN cluster
- In containers, such as K8s
05 - [understand] - Spark framework overview [Spark framework module]
Spark framework is a unified analysis engine that can process data for any type of analysis. It is similar to Hadoop framework and contains many modules. Starting with Spark 1.0, the modules are as follows: basic module Core, advanced module SQL, Streaming, MLlib, GraphX, etc

1,Core: Core module Data structure: RDD Encapsulate data into RDD Collection, calling collection functions to process data 2,SQL: Structured data processing module Data structure: DataFrame,DataSet Encapsulate data DF/DS In, use SQL and DSL Method analysis data 3,Streaming: For streaming data processing module Data structure: DStream Split streaming data into Batch Batch, encapsulated to DStream in 4,MLlib: Machine learning library Contains the implementation of the basic algorithm library, which can be called directly be based on RDD and DataFrame Class library API 5,GraphX: Graph calculation library At present, it is not used much and has been widely used Java Domain framework: Neo4J 6,Structured Streaming: from Spark2.0 For streaming data processing module Encapsulate streaming data into DataFrame In, use DSL and SQL Data processing 7,PySpark: support Python voice have access to Python Data analysis database and Spark Database comprehensive analysis data 8,SparkR: support R language http://spark.apache.org/docs/2.4.5/sparkr.html

06 - [understanding] - overview of Spark framework [Spark operation mode]
Applications written by Spark framework can run in Local Mode, Cluster Mode and Cloud service to facilitate development, testing and production deployment. Local mode is often used when developing programs. Cluster mode is used for testing production environment, and Hadoop YARN cluster is the most commonly used
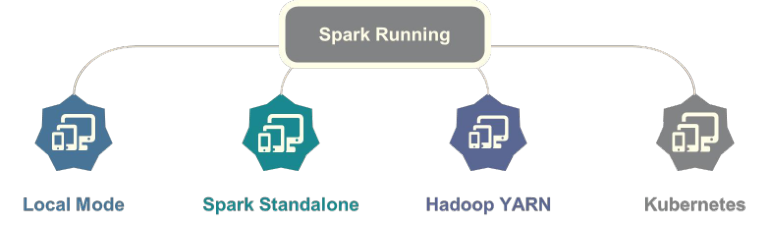
When Spark applications are running in cluster mode, there are three types:
- The first: Spark Standalone cluster, similar to Hadoop YARN cluster
- Second: Hadoop YARN cluster
- The third: Apache Mesos framework, similar to Hadoop YARN cluster
hadoop 2.2.0 Released in 2013, release edition: YARN edition
Local Mode: Local Mode The Task in Spark application is run in a local JVM Process, which is usually used for development and testing.
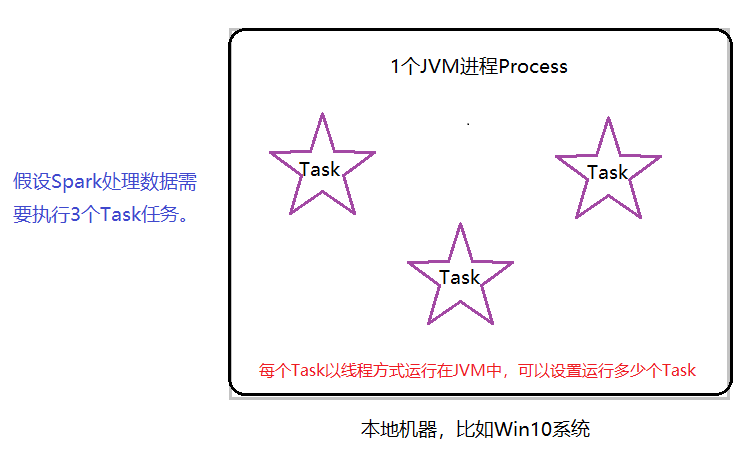
When running Spark applications in local mode, you can set the maximum number of tasks to run simultaneously, which is called parallelism
07 - [learn] - Spark quick start [Environmental preparation]
At present, the latest stable version of Spark: 2.4.x series, which is officially recommended and widely used in enterprises. Website: https://github.com/apache/spark/releases
The cluster environment used in this Spark course is 3 virtual machines, otherwise it is 1 virtual machine. CentOS 7.7 system is installed:
[import and copy the virtual machine into VMWare software according to [Appendix 2].
Super administrator user: root/123456 Ordinary users: itcast/itcast
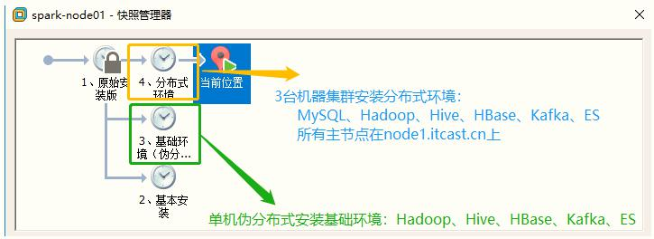
- Virtual machine installation environment and snapshot
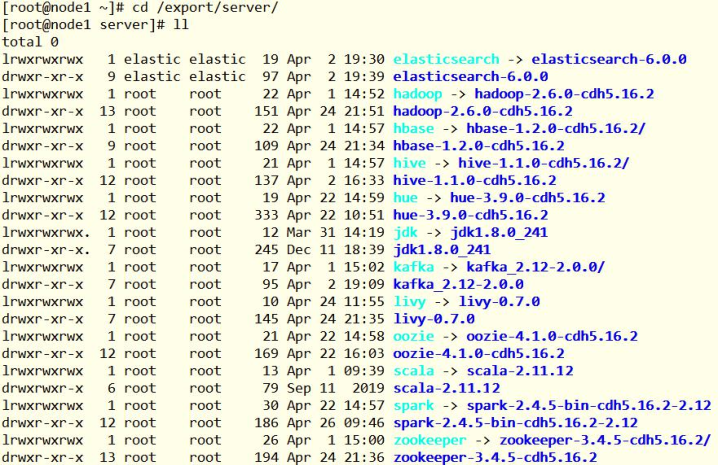
- The software installation directory is / export/server. The Hadoop offline framework uses CDH-5.16.2
In the virtual machine provided, it has been compiled for Spark 2.4.5. The description is as follows:
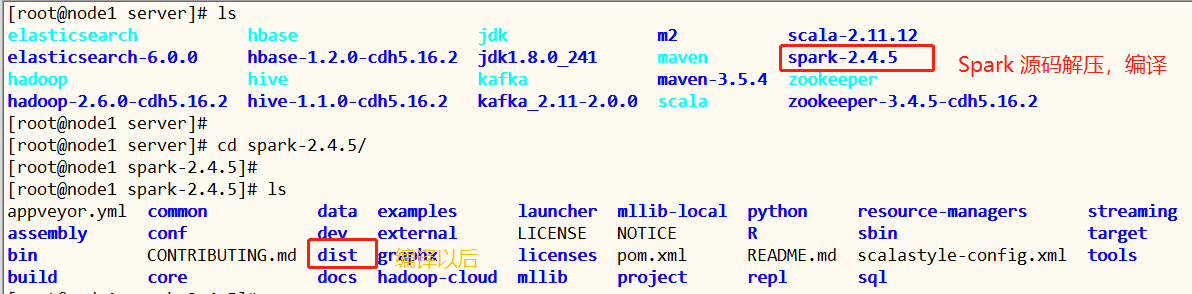
Copy the compiled tar file to the [/ export/software] directory

08 - [Master] - Spark quick start [local mode]
Unzip the compiled spark installation package [spark-2.4.5-bin-cdh5.16.2-2.11.tgz] to the [/ export/server] Directory:
## Unzip package tar -zxf /export/software/spark-2.4.5-bin-cdh5.16.2-2.11.tgz -C /export/server/ ## Create soft connection for later upgrade ln -s /export/server/spark-2.4.5-bin-cdh5.16.2-2.11 /export/server/spark
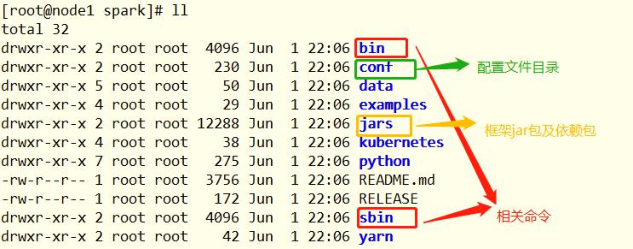
The meanings of each directory are as follows:
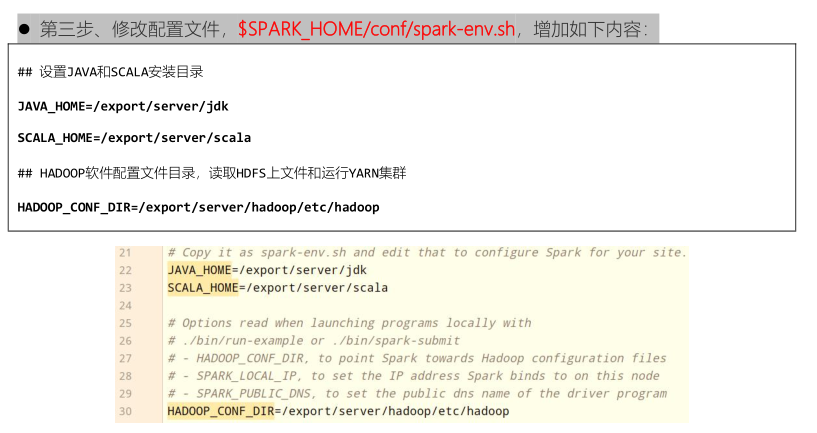
Basic configuration for Spark

After modifying the configuration file name, set the basic environment variables
Start the HDFS cluster and read data files from HDFS
# Start NameNode hadoop-daemon.sh start namenode # Start DataNode hadoop-daemon.sh start datanode
09 - [Master] - Spark quick start [run Spark shell]
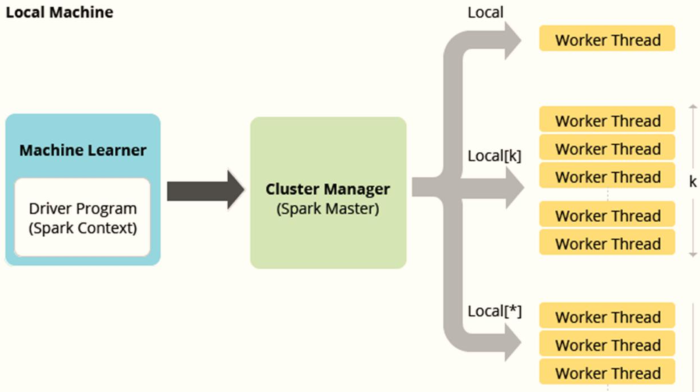
The spark framework runs in the local mode and provides an interactive command line: Spark shell. The local mode LocalMode means: start a JVM Process process and execute a Task. The usage method is as follows:

1,--master local JVM Start 1 thread running in the process Task task There is no parallel computing concept at this time 2,--master local[K] K Positive integer greater than or equal to 2 Indicates in JVM Processes can run simultaneously K individual Task Tasks are threads Thread Mode operation 3,--master local[*] Indicates that the program obtains the currently running application on the cluster CPU Core Kernel number
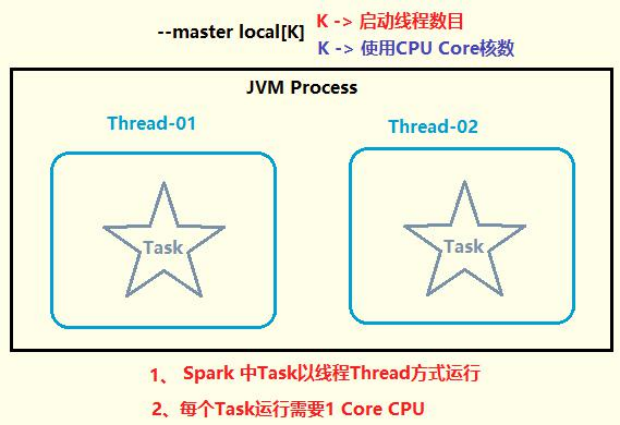
Start spark shell in local mode:
## Enter Spark installation directory cd /export/server/spark ## Start spark shell bin/spark-shell --master local[2]
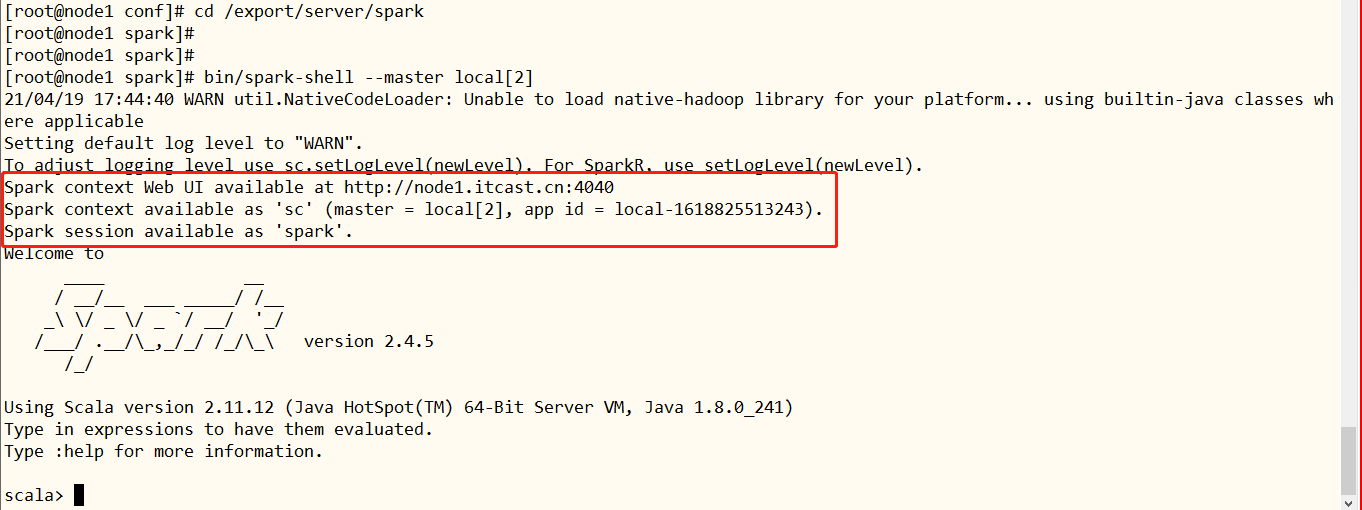
The SparkContext instance object: sc, SparkSession instance object: spark, and port number of start application monitoring page: 4040. The details are as follows: When each Spark application runs, it provides a WEB UI monitoring page: 4040 port number

## Upload HDFS file
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /export/server/spark/README.md /datas
## read file
val datasRDD = sc.textFile("/datas/README.md")
## Number of entries
datasRDD.count
## Get the first data
datasRDD.first10 - [Master] - Spark quick start [word frequency statistics WordCount]
Classic case of big data framework: word frequency statistics WordCount, reading data from files and counting the number of words.
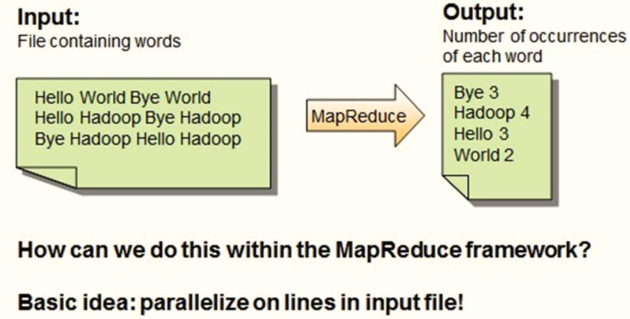
It is realized by Spark programming, which is divided into three steps:
1,Step 1: from HDFS Read file data, sc.textFile Method to encapsulate data into RDD in 2,Step 2: call RDD Medium and high order functions, To perform conversion processing, function: flapMap,map and reduceByKey 3,Step 3: the final processing result RDD Save to HDFS Or print console
The higher-order function flatMap in Scala collection class is different from the map function * *. Map function: it will perform the specified func operation on each input, and then return an object for each input; flatMap function: map first and then flatten**
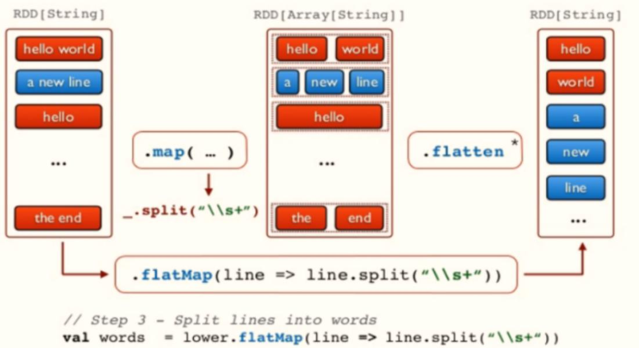
The use cases of reduce function in Scala are as follows:
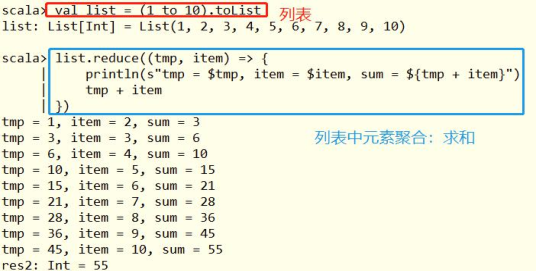
Interview questions: Scala Collection class List In the list, advanced functions: reduce,reduceLeft and reduceRight difference????
In the Spark data structure RDD, the reduceByKey function is equivalent to the combination of shuffle and reduce functions in MapReduce: group by Key, put the same Value in the iterator, and then use the reduce function to aggregate the data in the iterator.
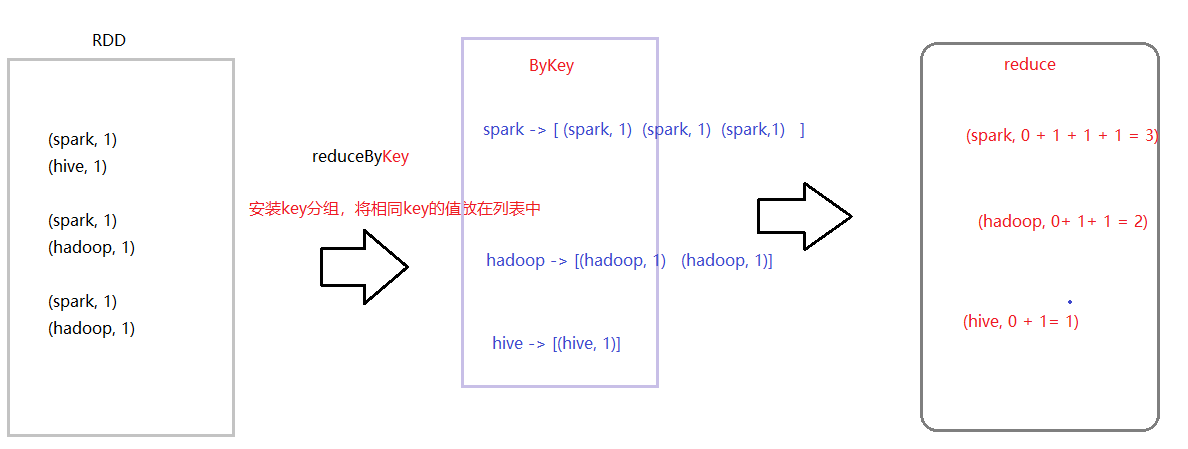
Prepare the data file: wordcount.data. The contents are as follows. Upload the HDFS directory [/ data]/
## create a file vim wordcount.data ## The contents are as follows spark spark hive hive spark hive hadoop sprk spark ## Upload HDFS hdfs dfs -put wordcount.data /datas/
Write code for word frequency statistics:
## Read the HDFS text data and package it into the RDD set. Each data in the text is each data in the set
val inputRDD = sc.textFile("/datas/wordcount.data")
## Divide each data in the collection according to the separator and use the regular: https://www.runoob.com/regexp/regexp-syntax.html
val wordsRDD = inputRDD.flatMap(line => line.split("\\s+"))
## Converted to a binary, indicating that each word occurs once
val tuplesRDD = wordsRDD.map(word => (word, 1))
# The values are grouped by Key and aggregated. The binary in scala is the Key/Value pair in Java
## reduceByKey: group first, then aggregate
val wordcountsRDD = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
## View results
wordcountsRDD.take(5)
## Save result data to HDFs
wordcountsRDD.saveAsTextFile("/datas/spark-wc")
## Check result data
hdfs dfs -text /datas/spark-wc/par*11 - [understanding] - Spark quick start [WEB UI monitoring]
When each Spark Application is running, start the WEB UI monitoring page. The default port number is 4040. Open the page with a browser, as follows: If the 4040 port number is occupied, by default, automatically push back the slogan and try 40414042 until it is available
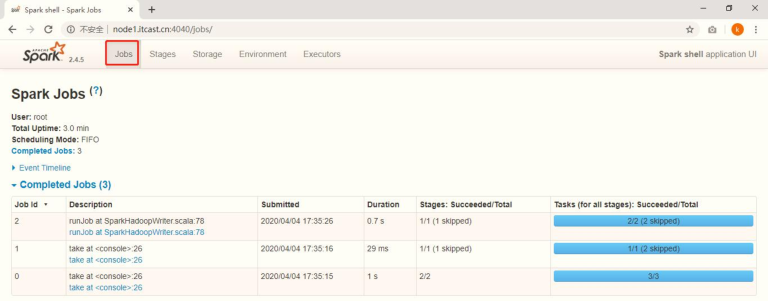
Click [Job 2] to enter the Job scheduling interface, which is displayed through DAG diagram. The specific meaning will be described later.
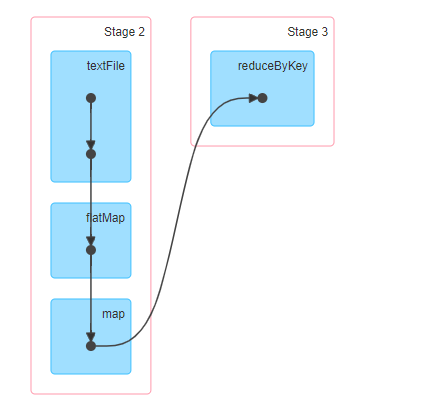
- 1) , first point and black point represent RDD dataset
- 2) , the second point and the blue rectangular box indicate that the function is called to output RDD
- 3) , third point, 2-type line, vertical downward straight line and directed S-type curve: Shuffle is generated, which means that data needs to be written to disk
12 - [learn] - Spark quick start [run PI]
The case Example provided with Spark framework covers PI calculation program, which can be submitted for application execution using [$park_home / bin / Spark submit] and run in local mode.
- Self contained case jar package: [/ export / server / spark / examples / jars / spark examples_2.11-2.4.5. Jar]
- Submit and run PI program
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \
10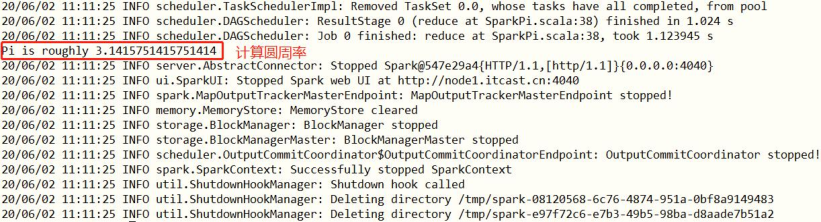
Spark has its own PI program, which is calculated by Monte Carlo estimation algorithm
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-IG5NRA7a-1625406507867)(/img/image-20210419183112123.png)]
Appendix I. creating Maven module
1) . Maven engineering structure
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-merImWMx-1625406507868)(img/1595891933073.png)]
MAVEN engineering GAV three elements:
<parent>
<artifactId>bigdata-spark_2.11artifactId>
<groupId>cn.itcast.sparkgroupId>
<version>1.0.0version>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>spark-chapter01_2.11artifactId>2) . POM file content
Contents in the POM document of Maven project (Yilai package):
aliyun
http://maven.aliyun.com/nexus/content/groups/public/
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
jboss
http://repository.jboss.com/nexus/content/groups/public
2.11.12
2.11
2.4.5
2.6.0-cdh5.16.2
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${scala.binary.version}
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
target/classes
target/test-classes
${project.basedir}/src/main/resources
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompileConfigure remote connection server in IDEA
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-e2fJeQzR-1625406507869)(/img/1605688796757.png)]
Appendix II. Importing virtual machines
Step 1: set the VMWare network segment address
Edit - > virtual network editor
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-niQYA1mY-1625406507869)(img/1599709639408.png)]
Change settings:
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG lkepazed-1625406507870) (IMG / 1599709683354. PNG)]
It can be determined finally.
Step 2: import the virtual machine to VMWare
Note: VMWare virtualization software version: 12.5.5 [the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-3g6kDbgC-1625406507870)(img/1599709239714.png)] Decompression directory of virtual machine: D: \ newsparkstructure \ sparklinux [the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-HoAlszUG-1625406507871)(img/1599709323673.png)]
Select the vmx file in the virtual machine
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-0tAt5oyb-1625406507871)(img/1599709367924.png)]
Step 3: start the virtual machine
When starting the virtual machine, the following dialog box pops up and select [I have moved and changed the virtual machine]
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-pyav82qn-1625406507872) (IMG / 15996341000. PNG)]
Step 4: configure host name and IP address mapping
File path: C:\Windows\System32\drivers\etc\hosts The contents are as follows: 192.168.88.100 node1.itcast.cn node1 192.168.88.101 node2.itcast.cn node2 192.168.88.102 node3.itcast.cn node3
Yes.
Step 2: import the virtual machine to VMWare
Note: VMWare virtualization software version: 12.5.5 [external chain picture transferring... (img-3g6kDbgC-1625406507870)] Decompression directory of virtual machine: D: \ newsparkstructure \ sparklinux [external chain picture transferring... (IMG hoalszug-1625406507871)]
Select the vmx file in the virtual machine
[external chain picture transferring... (img-0tAt5oyb-1625406507871)]
Step 3: start the virtual machine
When starting the virtual machine, the following dialog box pops up and select [I have moved and changed the virtual machine]
[external chain picture transferring... (img-pYAV82Qn-1625406507872)]
Step 4: configure host name and IP address mapping
File path: C:\Windows\System32\drivers\etc\hosts The contents are as follows: 192.168.88.100 node1.itcast.cn node1 192.168.88.101 node2.itcast.cn node2 192.168.88.102 node3.itcast.cn node3