Summary
HashMap is most familiar to Java users, but it's used every day. This time, I mainly analyze the working principle of HashMap. Why do I take this thing out for analysis? It's mainly the recently interviewed partners who were asked about HashMap. HashMap involves much more knowledge than put and get.
Why is it called HashMap? How is it achieved internally? When using, most of them use String as their key? Let's learn about HashMap and explain these problems in detail.
The origin of HashMap name
In fact, the origin of HashMap is based on hasing technology. Hasing is to convert a large string or any object into a small value to represent them. These shorter values can be easily used to facilitate indexing and search.
What is HashMap
HashMap is a collection used to store key value pairs. You can use a "key" to store data. When you want to get data, you can get data through "key". Each key value pair is also called Entry. These key value pairs are stored in an array, which is the backbone of HashMap.
As a data structure, HashMap is used for general addition, deletion, modification and query like array and linked list. When storing data, it is not put randomly, but it will first allocate index (which can be understood as "classification") and then store it. Once the index is allocated for storage, the next time you get it, you can greatly shorten the search time. We know that the efficiency of array query and modification is very high, while the efficiency of adding and deleting (not tail) is low. On the contrary, HashMap combines the two to see the data structure of HashMap
Let's first introduce the variables of HashMap
Size is the storage size of HashMap. Threshold is the critical value of HashMap, also known as the threshold value. If the HashMap reaches the critical value, the size needs to be reallocated. loadFactor is the load factor, which is 75% by default. Threshold = current array length ✖ load factor. modCount is the total number of times the HashMap has been modified or deleted.
Storage structure of HashMap
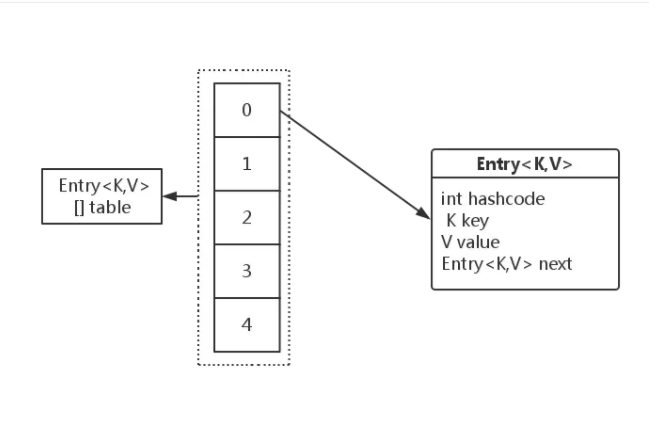
-
Entries are stored in an array table of Entry type. Every data in the table is an Entry object. The Y axis represents the array, and the X axis represents the storage mode of the linked list.
-
The Entry type stored in table contains hashcode variable, key,value and another Entry object. Because this is a linked list structure. Find you through me, and you'll find him again. However, the Entry here is not a LinkedList. It is an internal single chain table structure class serving for HashMap alone.
- Array is characterized by fast query, O(1) time complexity, slow insertion and deletion, O(n) time complexity. The storage mode of linked list is discontinuous, the size is not fixed, the characteristics are opposite to array, fast insertion and deletion, and slow query speed. HashMap references them and selects their segments. It can be said that the query, insert and delete operations will speed up.
The basic principle of HashMap
1. First, judge whether the Key is null. If it is null, directly look for the envy [0]. If it is not null, first calculate the HashCode of the Key, and then get the Hash value through the second Hash.
2. According to the Hash value, the length of Entry [] is subtracted to get the index of the Entry array.
3. Find the corresponding array according to the corresponding index, that is, find the linked list, and then insert, delete and query the Value according to the operation of the linked list.
Hash collision
hash method
We all know that every object in Java has a hashcode() method to return the hash value of the object. HashMap first hashes the hashCode, and then calculates the subscript through the hash value.
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}How does HashMap find the index of an array through hash? Call indexFor, where h is the hash value and length is the length of the array. This bitwise sum algorithm is actually h%length.
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
Where h is the hash value, and length is the length of the array. This bitwise sum algorithm is actually h%length.
In general, when to use the algorithm, a typical grouping. For example, how to group 100 numbers into 16 groups means that. It is widely used.
static int indexFor(int h, int length) {
return h & (length-1);
}For instance
int h=15,length=16;
System.out.println(h & (length-1));
System.out.println(Integer.parseInt("0001111", 2) & Integer.parseInt("0001111", 2));
h=15+16;
System.out.println(h & (length-1));
System.out.println(Integer.parseInt("0011111", 2) & Integer.parseInt("0001111", 2));
h=15+16+16;
System.out.println(h & (length-1));
System.out.println(Integer.parseInt("0111111", 2) & Integer.parseInt("0001111", 2));
h=15+16+16+16;
System.out.println(h & (length-1));
System.out.println(Integer.parseInt("1111111", 2) & Integer.parseInt("0001111", 2));When we do bitwise and, we always calculate the low order. The high order does not participate in the calculation, because the high order is 0. The result is that as long as the low order is the same, no matter what the high order is, the final result is the same. If you rely on this, the hash collision is always on an array, resulting in the infinite length of the list at the beginning of the array, then the query speed is very slow, and how to calculate high performance. So hashmap must solve this problem, and try to distribute the key to the array as evenly as possible. Avoid the accumulation of hash.
When we call the put method, although we try to avoid collisions to improve the performance of HashMap, collisions can occur. It is said that the collision rate is quite high, and the collision will start when the average loading rate reaches 10%.
Source code analysis
HashMap initialization
By default, most people call HashMap hashMap = new HashMap(); to initialize. Here we analyze the constructor of newHashMap (int initialCapacity, float loadFactor).
We all know that every object in Java has a hashcode() method to return the hash value of the object. HashMap first hashes the hashCode, and then calculates the subscript through the hash value.
The code is as follows:
public HashMap(int initialCapacity, float loadFactor) {
// initialCapacity represents the capacity of the initial HashMap, and its maximum capacity is maximum ﹤ capacity = 1 < < 30.
// loadFactor represents its load factor. Default value is default load factor = 0.75, which is used to calculate threshold threshold if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}As can be seen from the above code, you need to know the initialization capacity when initializing. Because you need to calculate the index of the Entry array through the Hash algorithm of bitwise sum, then the array length of the Entry is required to be the nth power of 2.
put operation
How does HashMap store an object? The code is as follows:
public V put(K key, V value) {
//Create array when array is empty
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//① key is empty and treated separately
if (key == null)
return putForNullKey(value);
//② calculate the hash value according to the key
int hash = hash(key);
//② calculate the index in the array according to the hash value and the length of the current array
int i = indexFor(hash, table.length);
//Traverse the entire list
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//③ if the hash value and the key value are the same, replace the previous value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
//Return replaced value
return oldValue;
}
}
modCount++;
//(3) if you do not find the same hash node of the key, either directly store the value or have a hash collision, go here
addEntry(hash, key, value, i);
return null;
}As can be seen from the code, the steps are as follows:
1. First, we will judge whether it can be null. If it is null, we will call pullForNullKey (value) for processing. The code is as follows:
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}If the key is null, it will be stored in the linked list at the beginning of table[0] by default. Then traverse each node Entry of the linked list of table[0]. If the key of node Entry is found to be null, replace the new value, and then return the old value. If no node Entry with key equal to null is found, add a new node.
- Calculate the hashcode of the key, and then use the second hash of the calculation result to find the index i of the Entry array through index for (hash, table. Length).
(3) then traverse the linked list with table[i] as the head node. If there is a node with the same hash and key, replace it with a new value, and then return the old value.
If the same hash node of the key is not found, add a new node, addEntry(), as follows:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
//Judge whether the array capacity is sufficient and insufficient
resize(2 * table.length);
}(4) if the HashMap size exceeds the critical value, you need to reset the size and expand the capacity, which will be explained later.
Attached is a flow chart, which is copied from other bloggers. I think it's a good one.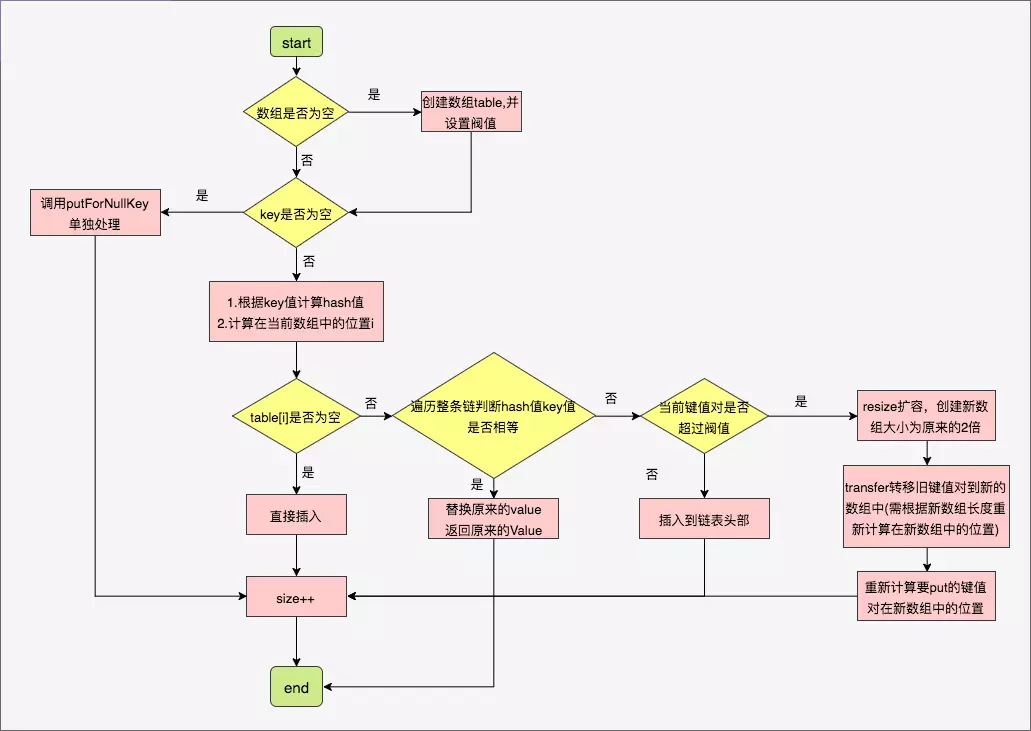
get operation
We use hashMap.get(K key) to get the stored value. The value of key is very simple. We find the Entry directly through the index of the array, and then traverse the Entry. When hashcode and key are the same, they are the original values we stored.
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}Call getEntry(key) to get the entry, and then return the value of the entry to see the getEntry(key) method
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}Compared with put, there are not so many routines for get operation. You only need to calculate the hash value according to the key value and take the modulus of the array length. Then you can find the position in the array (the key is empty, and you can operate separately). Then you can traverse the Entry. When the hash is equal, if the key is equal, you will know the value we want.
There is a null judgment in the get method. The hash value of null is always 0. In the get null key (k key) method, it is also searched according to the traversal method.
The role of modCount
As we all know, HashMap is not thread safe, but in some applications with good fault tolerance, if you don't want to bear the synchronization cost of hashTable just because of the 1% possibility, HashMap uses the fail fast mechanism to deal with this problem, and you will find that modCount is declared in the source code.
reSize
When the put method is called, when the size of the HashMap exceeds the critical value, you need to expand the capacity of the HashMap. The code is as follows:
void resize(int newCapacity) { //Incoming new capacity
//Get reference to old array
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//In extreme cases, the current number of key value pairs has reached the maximum
if (oldCapacity == MAXIMUM_CAPACITY) {
//Modify the threshold value to maximum direct return
threshold = Integer.MAX_VALUE;
return;
}
//Step ① create a new array according to the capacity
Entry[] newTable = new Entry[newCapacity];
//Step 2 transfer the key value pair to the new array
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//Step 3 assign the reference of the new array to table
table = newTable;
//Step ④ modify the threshold
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}Returns if the size exceeds the maximum capacity. Otherwise, a new Entry array will be created, which is twice the length of the old Entry array. Then copy the old Entry [] to the new Entry []. The code is as follows:
void transfer(Entry[] newTable, boolean rehash) {
//Get the length of the new array
int newCapacity = newTable.length;
//Traversing key value pairs in old arrays
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//Calculates the index in the new table and into the new array
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}I believe you are very clear about the inside of HashMap. If this article helps you remember to pay attention to me, I will continue to update the article. Thank you for your support!