This weekend, I patched the jade template engine to generate static html files. This article needs to know about jade and read my last article. First, I give their reference links:
Node.js Template Engine Tutorial-jade Speed and Actual Warfare 1-Basic Usage
Node.js Template Engine Tutorial-jade Speed and Practical 3-mixin
Node.js Implements a Simple Crawler-Grab All List Information of Blog Articles
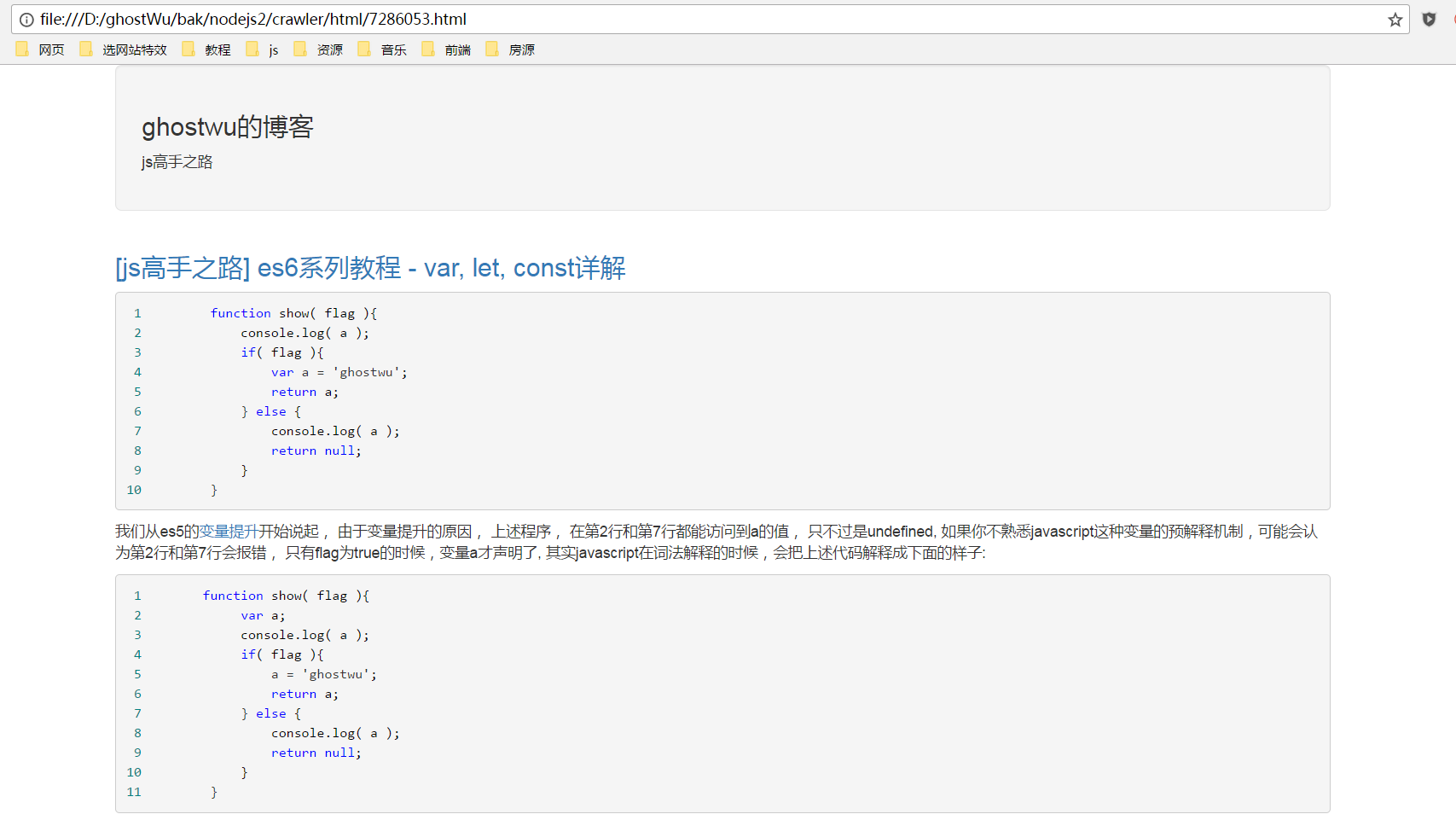
In the article I shared above, I grabbed a list of all the articles on my blog. I didn't collect them into the library, nor did I do anything else. In this article, we will sort out all the information of the list of articles collected above, and start collecting articles and generating static html files. First, look at my collection effect. My blog currently has 77 articles, and all of them are collected and generated in less than one minute. Here I cut off some pictures, the name of the file is generated by the id of the article, and the generated articles, I wrote a paper. Simple static template, all articles are generated from this template.
Project structure:
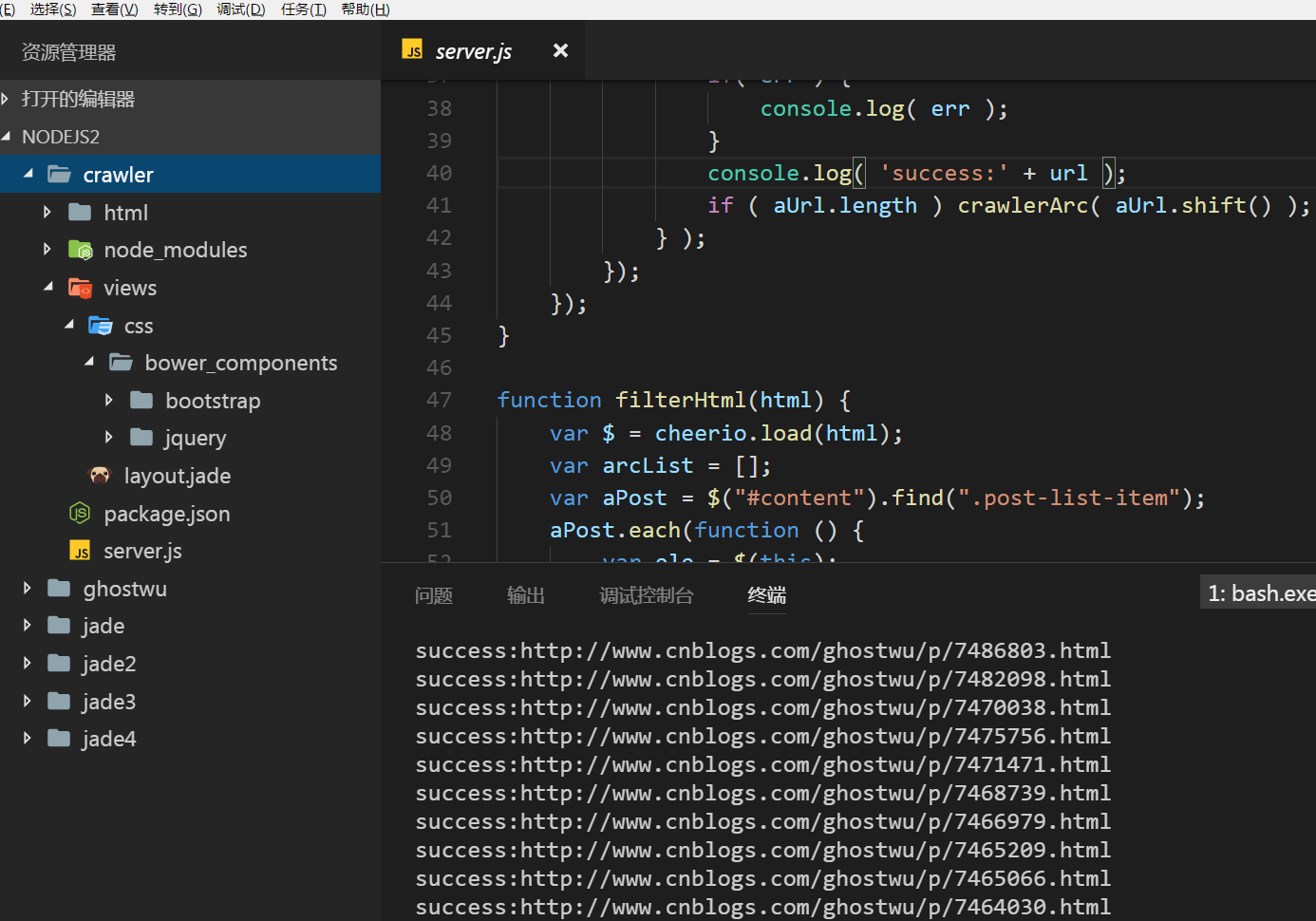

Well, next, let's talk about the main functions of this article:
1. Grabbing articles, mainly grabbing the title, content, hyperlink, article id (used to generate static html files)
2. Generate html files based on jade templates
First, how to grasp the article?
Very simple, follow Above The implementation of grabbing the list of articles is similar.
1 function crawlerArc( url ){ 2 var html = ''; 3 var str = ''; 4 var arcDetail = {}; 5 http.get(url, function (res) { 6 res.on('data', function (chunk) { 7 html += chunk; 8 }); 9 res.on('end', function () { 10 arcDetail = filterArticle( html ); 11 str = jade.renderFile('./views/layout.jade', arcDetail ); 12 fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){ 13 if( err ) { 14 console.log( err ); 15 } 16 console.log( 'success:' + url ); 17 if ( aUrl.length ) crawlerArc( aUrl.shift() ); 18 } ); 19 }); 20 }); 21 }
The parameter url is the address of the article. After the content of the article is captured, the filter Article (html) is called to filter out the required article information (id, title, hyperlink, content). Then the template content is replaced by the renderFile api of jade.
After the template content is replaced, the html file must be generated, so when writing to the file with writeFile, use id as the name of the html file. This is the implementation of generating a static html file.
Next is the loop to generate the static html file, which is the following line:
Complete implementation code server.js:
1 var fs = require( 'fs' ); 2 var http = require( 'http' ); 3 var cheerio = require( 'cheerio' ); 4 var jade = require( 'jade' ); 5 6 var aList = []; 7 var aUrl = []; 8 9 function filterArticle(html) { 10 var $ = cheerio.load( html ); 11 var arcDetail = {}; 12 var title = $( "#cb_post_title_url" ).text(); 13 var href = $( "#cb_post_title_url" ).attr( "href" ); 14 var re = /\/(\d+)\.html/; 15 var id = href.match( re )[1]; 16 var body = $( "#cnblogs_post_body" ).html(); 17 return { 18 id : id, 19 title : title, 20 href : href, 21 body : body 22 }; 23 } 24 25 function crawlerArc( url ){ 26 var html = ''; 27 var str = ''; 28 var arcDetail = {}; 29 http.get(url, function (res) { 30 res.on('data', function (chunk) { 31 html += chunk; 32 }); 33 res.on('end', function () { 34 arcDetail = filterArticle( html ); 35 str = jade.renderFile('./views/layout.jade', arcDetail ); 36 fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){ 37 if( err ) { 38 console.log( err ); 39 } 40 console.log( 'success:' + url ); 41 if ( aUrl.length ) crawlerArc( aUrl.shift() ); 42 } ); 43 }); 44 }); 45 } 46 47 function filterHtml(html) { 48 var $ = cheerio.load(html); 49 var arcList = []; 50 var aPost = $("#content").find(".post-list-item"); 51 aPost.each(function () { 52 var ele = $(this); 53 var title = ele.find("h2 a").text(); 54 var url = ele.find("h2 a").attr("href"); 55 ele.find(".c_b_p_desc a").remove(); 56 var entry = ele.find(".c_b_p_desc").text(); 57 ele.find("small a").remove(); 58 var listTime = ele.find("small").text(); 59 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/; 60 listTime = listTime.match(re)[0]; 61 62 arcList.push({ 63 title: title, 64 url: url, 65 entry: entry, 66 listTime: listTime 67 }); 68 }); 69 return arcList; 70 } 71 72 function nextPage( html ){ 73 var $ = cheerio.load(html); 74 var nextUrl = $("#pager a:last-child").attr('href'); 75 if ( !nextUrl ) return getArcUrl( aList ); 76 var curPage = $("#pager .current").text(); 77 if( !curPage ) curPage = 1; 78 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 ); 79 if ( curPage < nextPage ) crawler( nextUrl ); 80 } 81 82 function crawler(url) { 83 http.get(url, function (res) { 84 var html = ''; 85 res.on('data', function (chunk) { 86 html += chunk; 87 }); 88 res.on('end', function () { 89 aList.push( filterHtml(html) ); 90 nextPage( html ); 91 }); 92 }); 93 } 94 95 function getArcUrl( arcList ){ 96 for( var key in arcList ){ 97 for( var k in arcList[key] ){ 98 aUrl.push( arcList[key][k]['url'] ); 99 } 100 } 101 crawlerArc( aUrl.shift() ); 102 } 103 104 var url = 'http://www.cnblogs.com/ghostwu/'; 105 crawler( url );
The layout.jade file:
doctype html
html
head
meta(charset='utf-8')
title jade+node.js express
link(rel="stylesheet", href='./css/bower_components/bootstrap/dist/css/bootstrap.min.css')
body
block header
div.container
div.well.well-lg
h3 ghostwu Blogs
p js Master's Road
block container
div.container
h3
a(href="#{href}") !{title}
p !{body}
block footer
div.container
footer Copyright - by ghostwu
Follow-up plans:
1. Using mongodb to store
2. Supporting breakpoint acquisition
3. Collect pictures
4. Collecting Novels
Wait....