Neural network learning (I)
Learning content:
1. Watch the teaching video of neural network, the use video of pytorch and the training video of mnist using keras framework, and have a preliminary understanding of neural network and classical training model
2. Read the group file introduction pdf to deepen the understanding of neural networks and convolutional neural networks
3. Install anaconda, pytorch and the required libraries (numpy, tensorflow, keras,...) according to the blog and video content, and preliminarily configure the required running environment
4. Read the code and refer to LetNet-5 model to train mnist using keras framework and torch framework
5. Learn to read the official pytorch documentation to view function parameters and related information
code:
- keras framework:
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import RMSprop
from keras import models,layers,regularizers
from keras.datasets import mnist
import matplotlib.pyplot as plt
# Load dataset
(train_images, train_labels),(test_images,test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28,28,1)).astype('float')/255
test_images = test_images.reshape((10000, 28,28,1)).astype('float')/255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
def LeNet5():
network = models.Sequential()
network.add(layers.Conv2D(filters=6,kernel_size=(3,3),activation='relu',input_shape=(28, 28, 1),kernel_regularizer=regularizers.l1(0.0001)))
network.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
network.add(layers.Dropout(0.01))
network.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu'))
network.add(layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
network.add(layers.Dropout(0.01))
network.add(layers.Conv2D(filters=120, kernel_size=(3, 3), activation='relu'))
network.add(layers.Flatten())
network.add(layers.Dense(84,activation='relu'))
network.add(layers.Dropout(0.01))
network.add(layers.Dense(10, activation='softmax'))
return network
network = LeNet5()
#Compilation steps
network.compile(optimizer=RMSprop(lr=0.001),loss='categorical_crossentropy',metrics=['accuracy'])
#Training network, using fit function, epochs represents how many rounds of training, batch_size indicates how large packets are given for each training
network.fit(train_images, train_labels, epochs=20, batch_size=120, verbose=2)
# print(network.summary())
test_loss, test_accuracy = network.evaluate(test_images, test_labels)
print("test_loss:",test_loss," test_accuracy:",test_accuracy)
-
result:
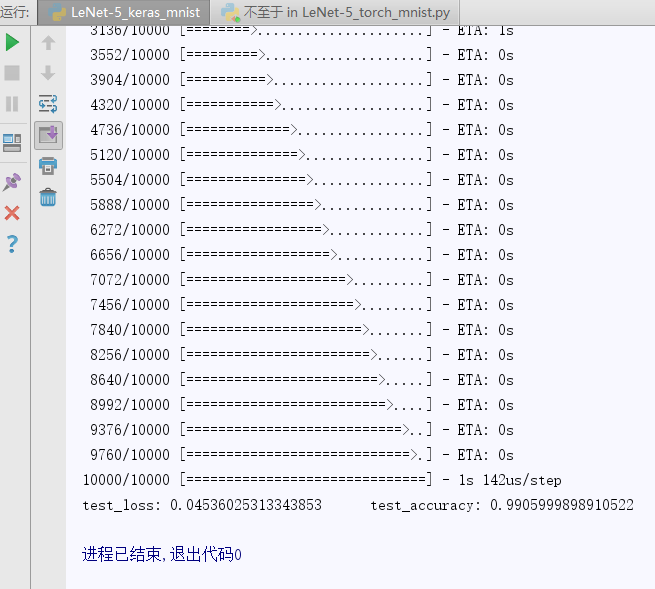
-
torch frame:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
#Parameter setting
batch_size = 4 # Batch size
EPOCHS=20 # Total training batches
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # Let torch judge whether to use GPU. It is recommended to use GPU environment because it will be much faster
total_train_step = 0
total_test_step=0
transform = transforms.Compose([
transforms.ToTensor(), # To Tensor
transforms.Normalize((0.5,), (0.5,)), # normalization
])
train_dataset = torchvision.datasets.MNIST(root='./MNIST_data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.MNIST(root='./MNIST_data', train=False, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
#Build neural network
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1) # Expand into one-dimensional
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
#Create network model
model = ConvNet().to(DEVICE)
criterion = nn.CrossEntropyLoss() # Cross entropy loss function
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # optimizer
#Add tensorboard
writer = SummaryWriter("logs")
def train(model, device, train_loader, optimizer, epoch, total_train_step):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
#input data
data, target = data.to(device), target.to(device)
#Gradient clearing
optimizer.zero_grad()
output = model(data)
#loss function
loss = criterion(output, target)
loss.backward()
#Update parameters
optimizer.step()
#Output training results
total_train_step = total_train_step + 1
if (batch_idx + 1) % 1000 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
writer.add_scalar("train_loss",loss.item(),)
def test(model, device, test_loader, total_test_step):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # Add up the losses of a batch
pred = output.max(1, keepdim=True)[1] # Find the subscript with the highest probability
correct += pred.eq(target.view_as(pred)).sum().item()
writer.add_scalar("test_loss", test_loss, total_test_step)
writer.add_scalar("test_loss", correct / len(test_loader.dataset), total_test_step)
total_test_step = total_test_step + 1
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch, total_train_step)
test(model, DEVICE, test_loader,total_test_step)
writer.close()
- result:
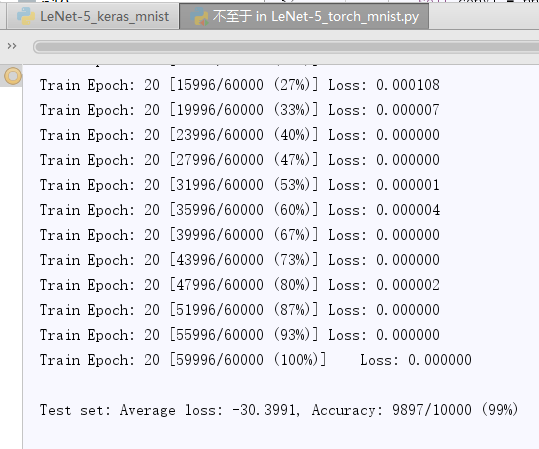
Problems encountered (start browsing records):
Configuration and installation:
(1) For the first time, I tried to install pytorch through anaconda using the conda instruction on the official website. During the installation process, several cases were very slow or even failed to download. Later, I found the image source of Tsinghua University according to the blog and downloaded it successfully, but the downloaded version did not match (I didn't find a matching version at that time, but I just found the download method of pip
(2) The second time I tried to download through pip, it was very fast, but I found that python in win was version 3.8 (too high), so I reinstalled python 3.6.0
(3) When using keras, I found that python should be above 3.6.2, so I reinstalled version 3.6.4 (if I also installed win32 version by mistake, I found that no library can be downloaded, [error 193]% 1 is not a valid win32 Application in python)
(4) There are no examples in tensorflow, and there are no examples in tensorflow 2.0
(5) It was found that there was a version matching problem between keras and tensorflow, so they reinstalled
(6) It can run, but there is still a mismatch
Code:
(1) First, use the keras framework, and then torch. It is found that keras trains very fast and the code is very simple. yeah
(2) Differences between maxpooling and avgpooling:
Average pooling can reduce the increase of estimation variance caused by limited neighborhood size, and retain more background information of the image
Max pooling can reduce the deviation of the estimated mean caused by the parameter error of convolution layer and retain more texture information
At first, average pooling was used. Later, it was found that Max pooling can make the accuracy higher
(3) transforms.ToTensor(): when loading data, the PIL.Image or numpy.array data type should be changed into torch.FloatTensor type
(4) batch_size should not be set too large, otherwise an error RuntimeError: CUDA error may be reported
(5) There is a problem of over fitting in the results (the accuracy of the training set (99.8) is higher than that of the test set (99.0))
Solution strategies: 1. Data set expansion 2. Regularization method (both l1 and l2 have been used, and it seems that there is little difference for mnist) 3.Dropout (used, it is recommended to set the parameter to 0.5, and the most randomly generated networks)
(6) Error reporting: IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 10)
Error building network, wrong dimension
Similar error:
mat1 and mat2 shapes cannot be multiplied ( )
(7) When using tensorboard visualization, the saved log will not be updated, and the original log should be deleted
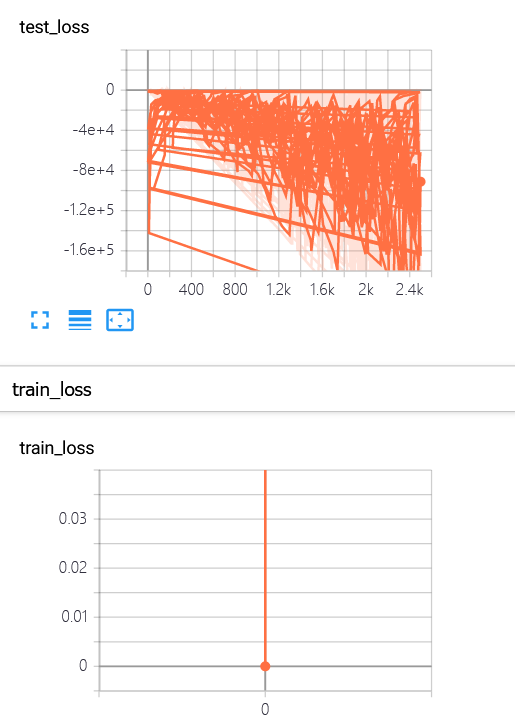
And the position of statement insertion is not quite right. It should be placed in the outer loop
(8) The difference between model. Train() and model.eval() mainly lies in the two layers of Batch Normalization and Dropout. If there are BN layers (Batch Normalization) and Dropout in the model, add model.eval() during the test. model.eval() ensures that the BN layer can use the mean and variance of all training data, that is, ensure that the mean and variance of BN layer remain unchanged during the test. For Dropout, model.eval() All network connections are used, that is, neurons are not randomly discarded.
(9) Why does loss appear negative? The continuous cross entropy is - \ int p(x)log q(x) dx. It can be negative, or it is too small?
(10) pytorch.nn.Conv2d how to calculate the size of output characteristic drawing

Summary:
By modifying the neural network structure, the highest accuracy can be achieved at 99.2% (there seems to be 99.3%, but there is no screenshot)

In general, it takes a lot of time to configure the environment. This thing is really difficult to install. Then, after learning the theoretical knowledge, it will be a little different from the actual operation. It is still necessary to clarify the training process step by step by viewing other people's code analysis. For the calculation of input and output between layers, we need to continue to learn and solve the over fitting problem. For the optimizer There is no in-depth research on and loss function, the use of tensorboard visualization is not very skilled, and there is still a great lack of the use of torch. I hope to learn further.