Keras
Keras is a Python deep learning framework, which can easily define and train almost all types of deep learning models. Keras was originally developed for researchers with the aim of rapid experimentation.
Key features of Keras
The same code can be switched seamlessly on the CPU or GPU. With user-friendly API, it is easy to develop the principle of deep learning model quickly. Built-in support for convolution networks (for computer vision), cyclic networks (for sequence processing) and any combination of the two.
Support arbitrary architecture network: multi-input or multi-output model, layer sharing, model sharing, etc. That is to say, Keras can build any deep learning model.
Keras is based on a relaxed MIT licensing scheme, which means it can be used free of charge in commercial projects and is compatible with all Python versions.
The Extension of Keras
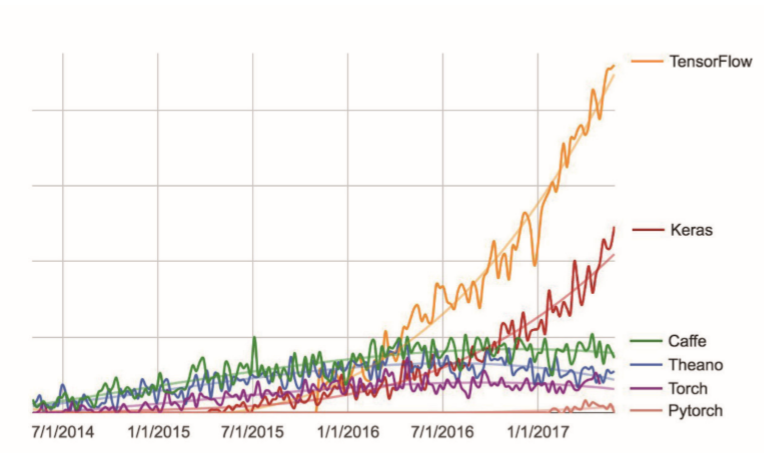
Keras has more than 200,000 users. Google, Netflix, Uber, CERN, Yelp, Square and hundreds of startups are using them.
Keras is also a popular framework on the machine learning contest website Kaggle. In the latest in-depth learning contest, almost all the winners use the Keras model.
Keras Architecture
Keras is a model-level library, which provides a high-level building module for the development of in-depth learning model.
It relies on a specialized, highly optimized tensor library, the Keras back end engine, to perform these operations.
Instead of selecting a single tensor library and binding the Keras implementation to it, Keras addresses this issue in a modular manner.
Currently, Keras has three back-end implementations: Tensorflow, Theano and Microsoft cognitive toolkit.
Keras workflow
(1) Define training data: input tensor and target tensor
(2) A network (or model) consisting of a definition layer that maps input to the target
(3) Configuration learning process: selecting loss function, optimizer and indicators to be monitored
(4) Invoking fit method of model to iterate on training data
There are two ways to define a model:
One is to use the Sequential class (only for linear stacking of layers, which is the most common network architecture today)
The other is a functional API (directed acyclic graph of layers that allows you to build any form of architecture)
Keras Compilation and Training
Keras compilation: Configuration learning process, where you can specify the optimizer and loss function used by the model, as well as the indicators you want to monitor during training.
Keras training: Numpy arrays of input data (and corresponding target data) are passed into the model through fit() method, which is similar to Scikit-Learn and other machine learning libraries.
Sequence model
Mathematical Symbol Definition of Sequential Model
x: As soon as I entered the door, I saw Chang Wei beating Laifu.
Y: x<1> , x<2> , , , x<14>
What is cyclic neural network?
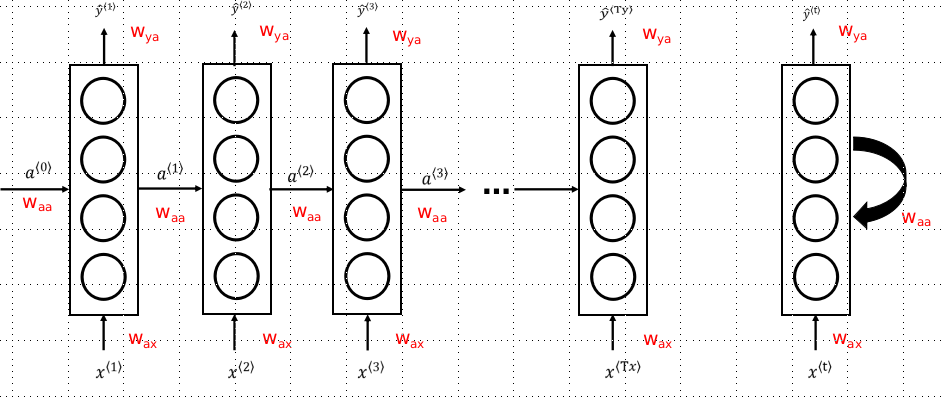
Simplification of Forward Propagation of Cyclic Neural Networks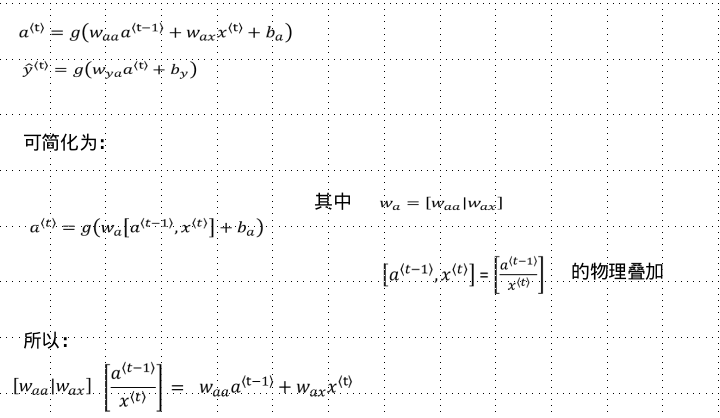
Back Propagation of Cyclic Neural Networks: Traveling Time
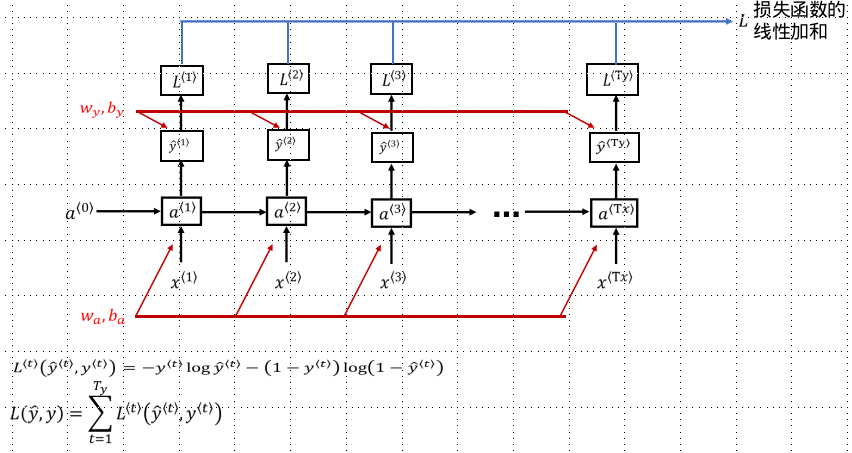
How to Construct Language Model and Sequence Generation with RNN
The basic task of the language model is to input a sentence (or text sequence). For the language model, it is better to represent these sequences in y than in x. Then the language model estimates the possibility of each word appearing in a sentence sequence.
(1) A training set is needed, which contains a large (Chinese/English) text corpus.
Corpus: A text consisting of a long, or a large number of (Chinese/English) sentences
(2) Marking up a corpus: It means building a dictionary and then transforming each word into a one-hot vector, which is the index in the dictionary.
Note: At the end of each sentence, <EOS> can be added to indicate the end of each sentence. If there is an unknown word, we replace it with <UNK>.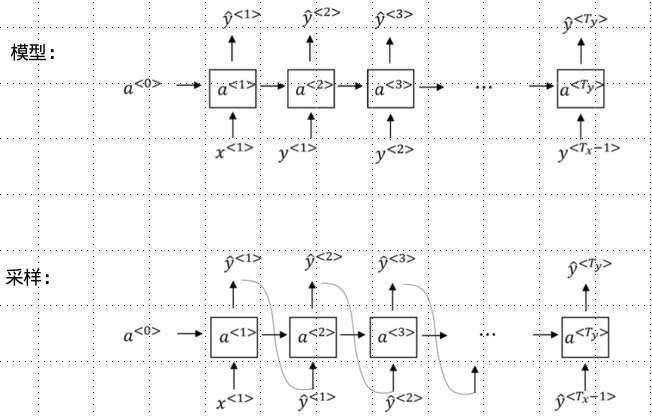
Code implementation:
"""
Date: 2019--25 16:10
User: yz
Email: 1147570523@qq.com
Desc:
"""
import numpy as np
data_dir = './Data/jena_climate_2009_2016.csv'
f = open(data_dir)
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',')
lines = lines[1:]
float_data = np.zeros((len(lines), len(header) - 1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]]
float_data[i, :] = values
print(float_data.shape[-1])
from matplotlib import pyplot as plt
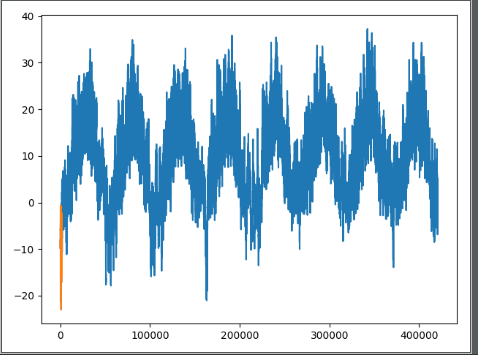
temp = float_data[:, 1]
plt.plot(range(len(temp)), temp)
plt.plot(range(1440), temp[:1440])
plt.show()
mean = float_data[:200000].mean(axis=0)
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std
def generator(data, lookback, delay, min_index, max_index, shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index = lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows), lookback // step, data.shape[-1]))
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
lookback = 1440
step = 6
delay = 144
batch_size = 128
train_gen = generator(float_data, lookback=lookback, delay=delay, min_index=0, max_index=200000, shuffle=True,
batch_size=batch_size, step=step)
val_gen = generator(float_data, lookback=lookback, delay=delay, min_index=200001, max_index=300000,
batch_size=batch_size, step=step)
test_gen = generator(float_data, lookback=lookback, delay=delay, min_index=300001, max_index=None,
batch_size=batch_size, step=step)
val_steps = (300000 - 200001 - lookback) // batch_size
test_steps = (len(float_data) - 300001 - lookback) // batch_size
def evaluate_navie_method():
batch_maes=[]
for step in range(val_steps):
samples,targets=next(val_gen)
preds=samples[:,-1,1]
mae=np.mean(np.abs(preds-targets))
batch_maes.append(mae)
print(np.mean(batch_maes))
evaluate_navie_method()
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model =Sequential()
model.add(layers.GRU(32,input_shape=(None,float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history=model.fit_generator(train_gen,steps_per_epoch=500,epochs=20,
validation_data=val_gen,validation_steps=val_steps)
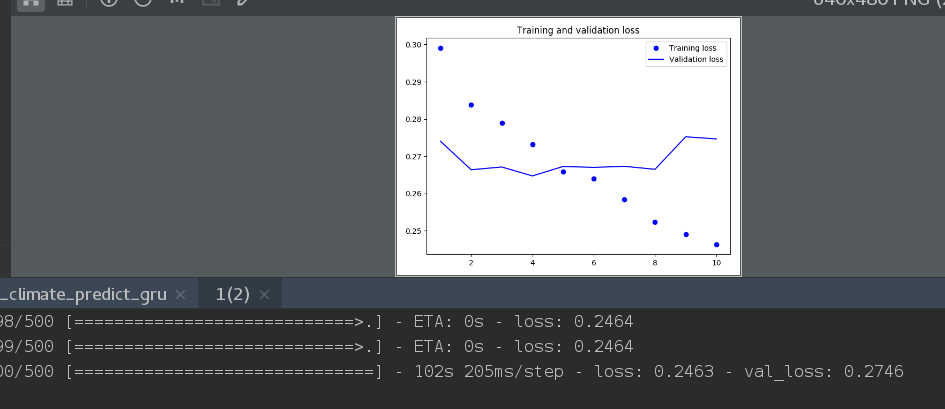
import matplotlib.pyplot as plt
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(1,len(loss)+1)
plt.figure()
plt.plot(epochs,loss,'bo',lable='Training loss')
plt.plot(epochs,val_loss,'b',lable='Validation loss')
plt.title('Training ans validation loss')
plt.legend()
plt.show()
GRU (Gated Recurrent Unit) - Gated Recurrent Unit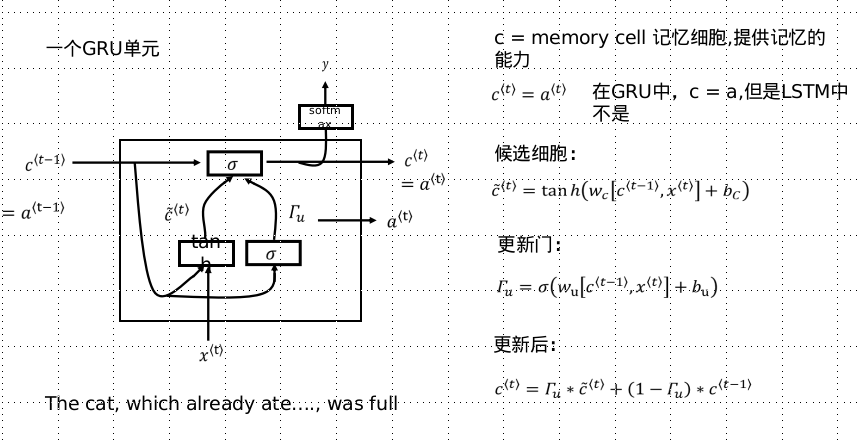
Code implementation:
"""
Date: 2019--25 15:53
User: yz
Email: 1147570523@qq.com
Desc:
"""
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features=10000
maxlen=500
batch_size=32
(input_train,y_train),(input_test,y_test)=imdb.load_data(path='/home/kiosk/Linear/190727/day9/test_data_home/imdb.npz',num_words=max_features)
print('loading data......')
print(len(input_train),'train sequences')
print(len(input_test),'test sequences')
print(input_train[0])
print('Pad sequences (samples x time)')
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
from keras.layers import Embedding, Dense, SimpleRNN
from keras.models import Sequential
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss = history.history['loss']
val_loss= history.history['val_loss']
epochs = range(1, len(acc)+1)
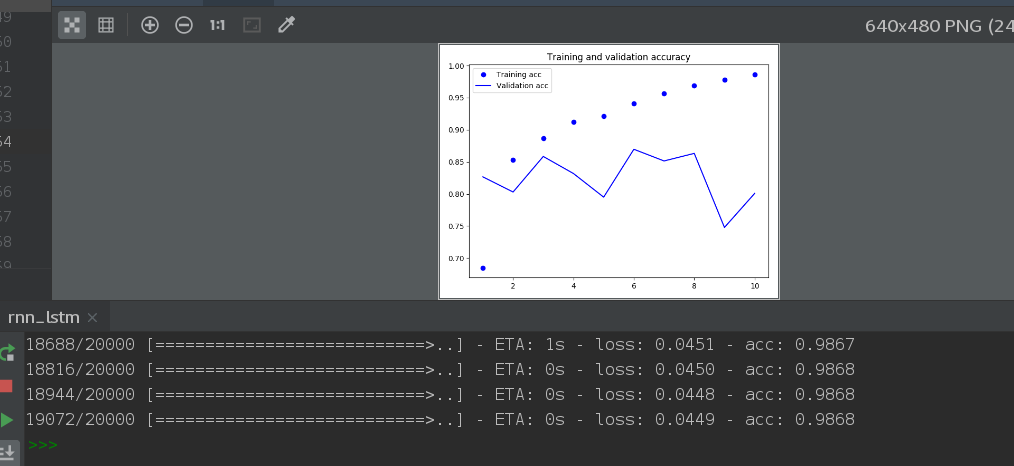
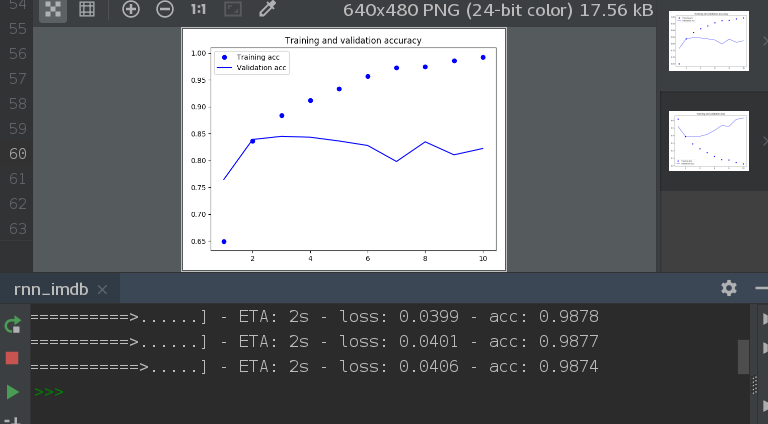
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.show()
LSTM (Long short term memory) - Long short term memory Network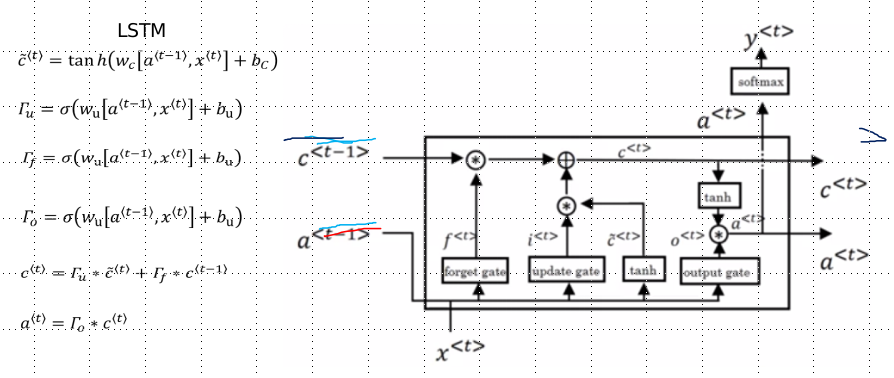
Code implementation:
"""
Date: 2019--25 15:53
User: yz
Email: 1147570523@qq.com
Desc:
"""
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features=10000
maxlen=500
batch_size=32
(input_train,y_train),(input_test,y_test)=imdb.load_data(path='/home/kiosk/Linear/190727/day9/test_data_home/imdb.npz',num_words=max_features)
print('loading data......')
print(len(input_train),'train sequences')
print(len(input_test),'test sequences')
print(input_train[0])
print('Pad sequences (samples x time)')
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
from keras.layers import Embedding, Dense, SimpleRNN
from keras.models import Sequential
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss = history.history['loss']
val_loss= history.history['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.show()