1, Packet capture analysis of network protocol
1, Continue to practice wireshark grabbing network packets. Run the "crazy chat room" program on two or more computers (known IPv4 addresses) and capture packets through wireshark:
1) Analyze what protocol (TCP, UDP) and port number are used for network connection of this program?
2) Try to find the stolen chat information in the captured packet (English characters and Chinese characters may have undergone some coding conversion, and the data packet is not clear text)
3) If the network connection adopts TCP, analyze the three handshakes when establishing the connection and the four handshakes when disconnecting the connection; If it is UDP, explain why the program can transmit chat data between multiple computers (only the same chat room number) at the same time?
Open crazy chat program
Message sending
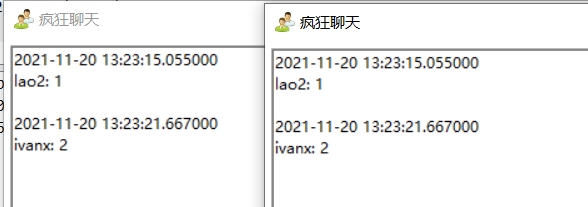
wireshark grab
By analyzing the program source code, you can know that the program sends information to 255.255.255.255 through UDP
Enter filter ip.dst==255.255.255.255 in wireshark to filter
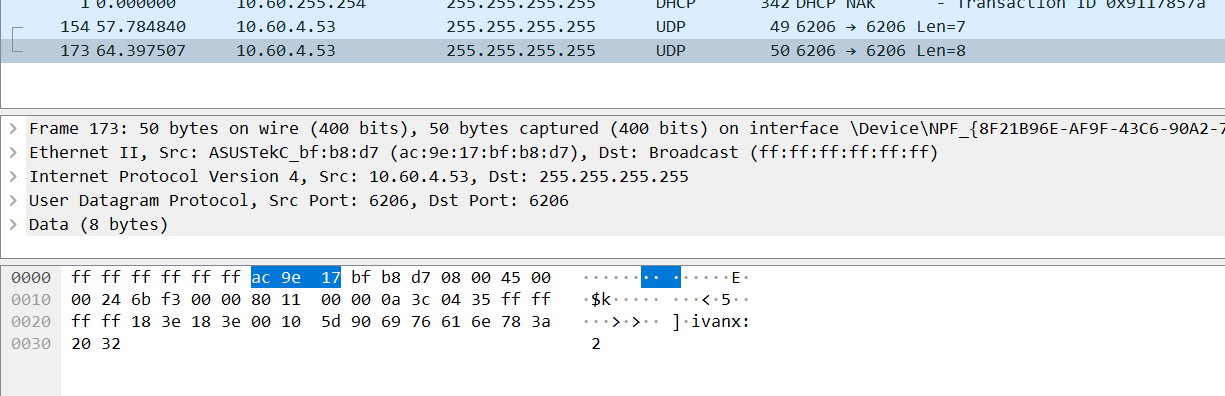
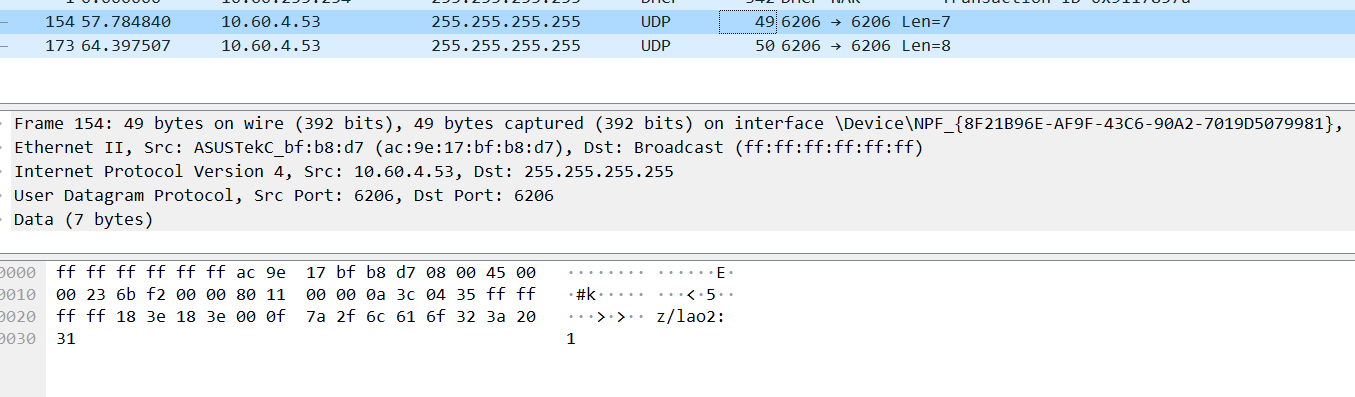
It is found that such a packet exists, and it is also verified that it is sent based on udp protocol and to the broadcast address 255.255.255.255
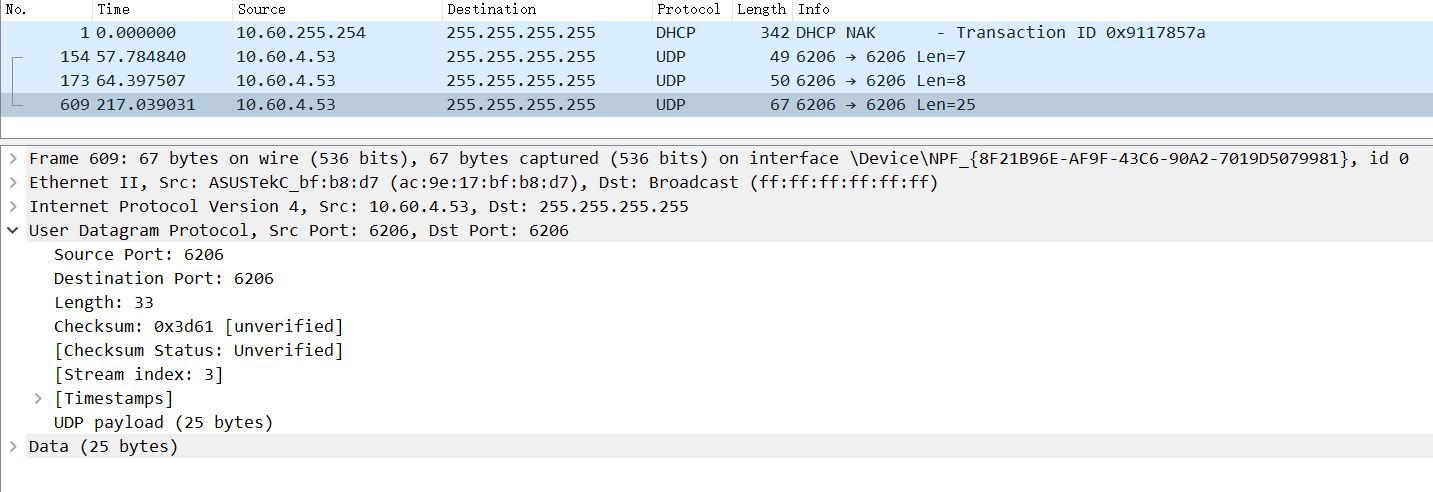
The port number is 6206. By analyzing the source code, we can know that the port number is room number + 5000, and our room number is 1206, which is correct

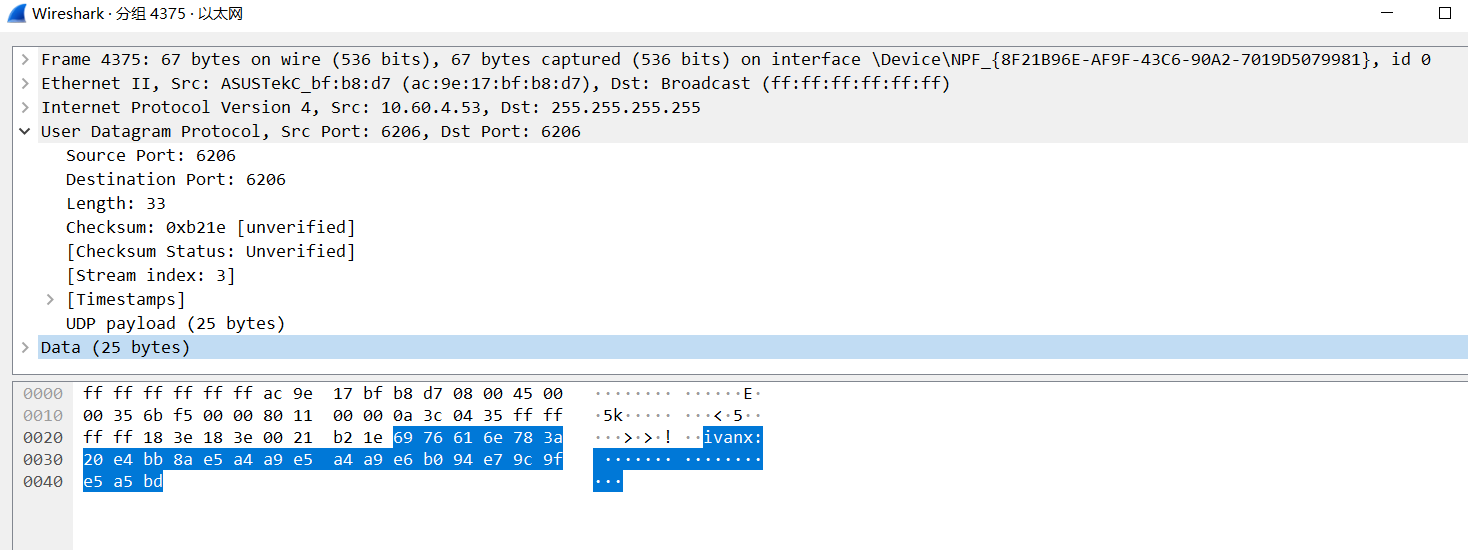
When sending English numbers, you can see the information directly, but when sending Chinese, you can only see
Through the character conversion tool and analysis code, it can be found that Chinese has undergone utf-8 conversion, and a Chinese occupies three bytes. Compared with the previous English, it can be found that English only occupies one byte.
2, Introduction to reptiles
1. Capture and storage of subject data
Learn the sample code, write detailed comments on the key code statements, and complete the ACM topic website of Nanyang Institute of technology http://www.51mxd.cn/ Practice capturing and saving topic data;
code:
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# Simulate browser access
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# Header
csvHeaders = ['Question number', 'difficulty', 'title', 'Passing rate', 'Number of passes/Total submissions']
# Topic data
subjects = []
# Crawling problem
print('Topic information crawling:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# Storage topic
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n Topic information crawling completed!!!')

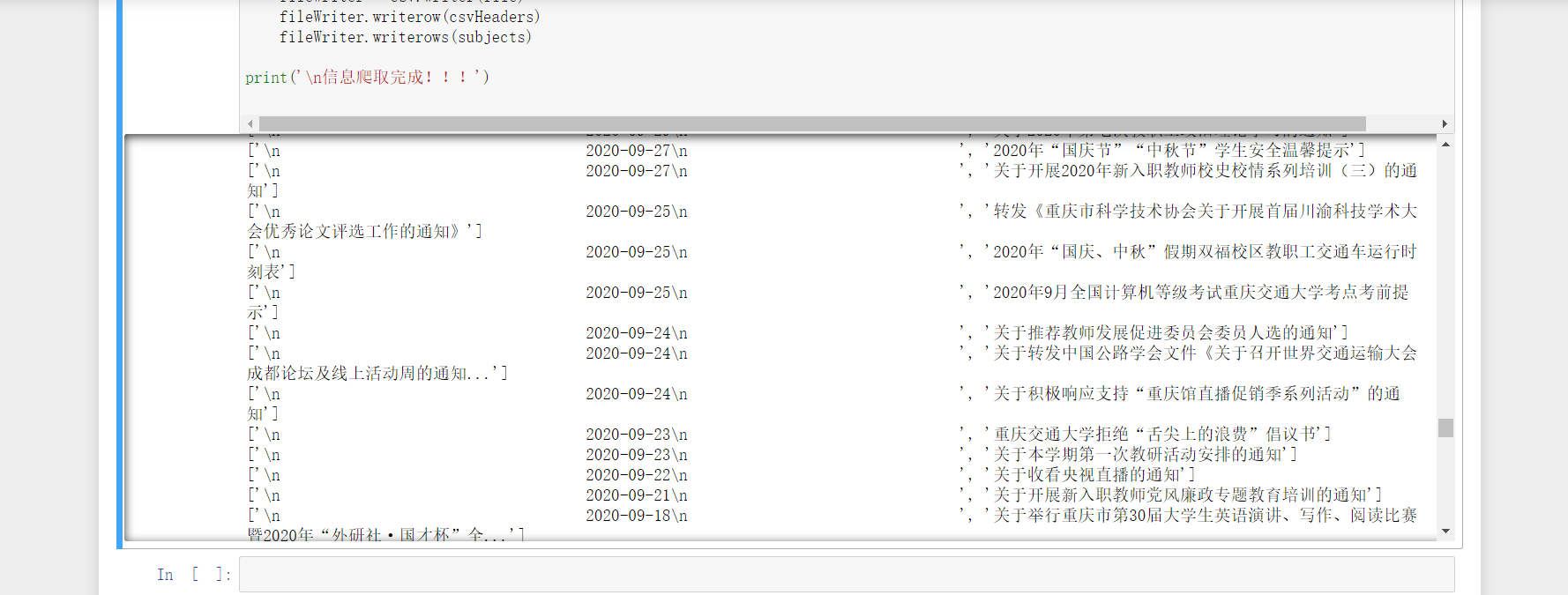
2. Crawling traffic information notice
Rewrite the crawler sample code to notify all the information in the news website of Chongqing Jiaotong University in recent years( http://news.cqjtu.edu.cn/xxtz.htm )The release date and title of are all crawled down and written to the CSV spreadsheet.
Chongqing Jiaotong University news website: http://news.cqjtu.edu.cn/xxtz.htm
Enter the news website and right-click to view the page source code

Find the location of the news title. If the news time and title are in the div tag and are contained by a li tag at the same time, you can find all li tags and find the appropriate div tag from inside.

code:
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # Make URL to get web page data
# All news
subjects = []
# Simulate browser access
Headers = { # Simulate browser header information
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# Header
csvHeaders = ['time', 'title']
print('Information crawling:\n')
for pages in tqdm(range(1, 65 + 1)):
# Make a request
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# If the request is successful, get the web page content
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# Parsing web pages
soup = BeautifulSoup(html, 'html5lib')
# Store a news item
subject = []
# Find all li Tags
li = soup.find_all('li')
for l in li:
# Find div tags that meet the criteria
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# time
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# title
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# Save data
with open('news.csv', 'w', newline='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n Information crawling completed!!!')

3, Summary
Packet capture can help us analyze network protocols and test network communication
The complex work can be effectively reduced through reptiles, which is convenient