regular expression
Actually, there are four main steps for reptiles:
- Clear goals (know where you are going to search or where you are going to search)
- Crawling (crawling all the contents of the website)
- Take out (get rid of the data that is useless to us)
- Process data (store and use as we want)
Regular expressions, also known as regular expressions, are usually used to retrieve and replace the text that conforms to a certain pattern (rule).
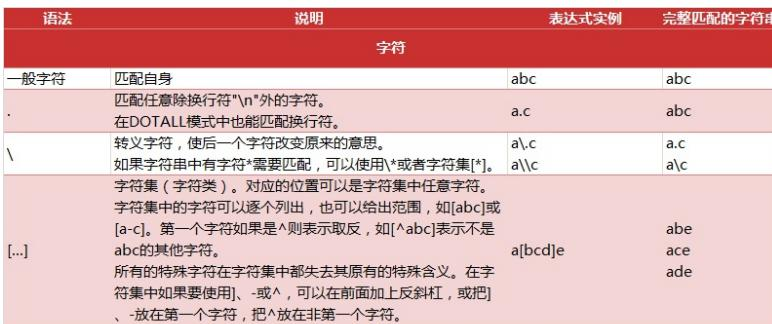
Regular expression matching rules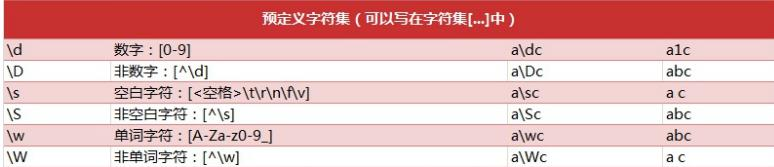
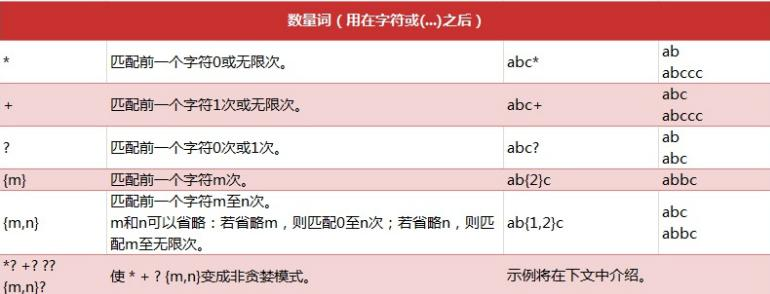

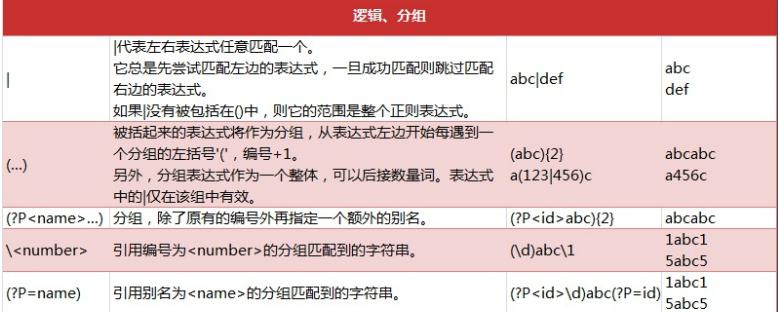
General use steps of re module
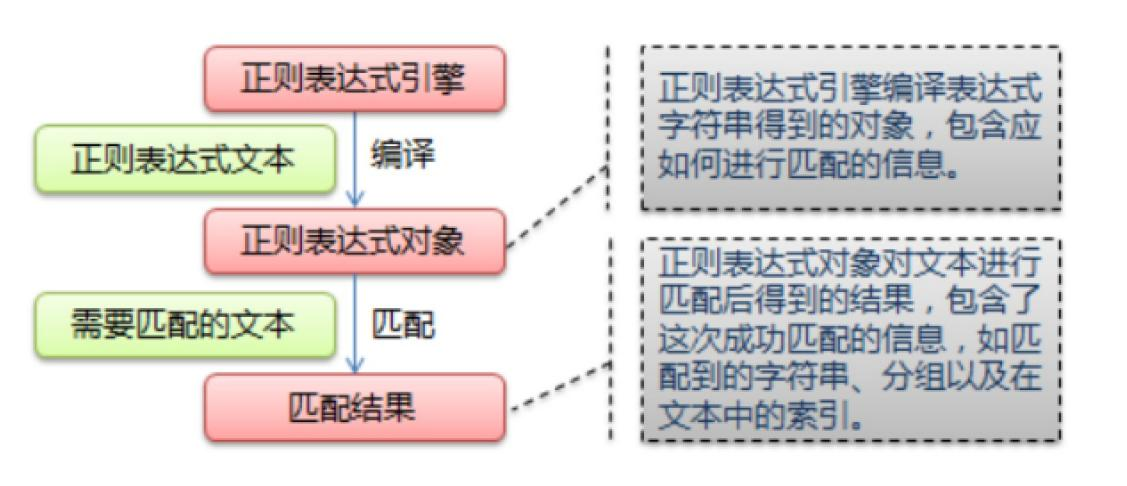
- Using the compile() function to compile the string form of a regular expression into a Pattern object
Note: re escapes special characters. If you use the original string, you only need to add an r prefix - Through the Pattern object to Match the text to find out the matching results, a Match object.
- Use the properties and methods provided by the Match object to get information and do other operations as needed
import re
text = """
2020-10-10
2020-11-11
2030/12/12
"""
#1. Use the compile() function to compile the string form of regular expression into a Pattern object
#Note: re escapes special characters. If you use the original string, you only need to add an r prefix
#pattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}') # April 11, 2020, no grouping rules
#pattern = re.compile(r'(\d{4})-(\d{1,2})-(\d{1,2})') # April 11, 2020, with grouping rules
pattern = re.compile(r'(?P<year>\d{4})-(?P<month>\d{1,2})-(?P<day>\d{1,2})') # 2020-4-11, rules for naming groups
# 2. Through the Pattern object to Match the text, we can get the matching result, a Match object.
# search finds a regular string from the given string and returns only one
result = re.search(pattern, text)
print(result)
# 3. Use the properties and methods provided by the Match object to obtain information, and perform other operations as required
print("Matched information:", result.group()) # Returns the matched text information
print("Matched information:", result.groups()) # Return location group ('2020', '10', '10')
print("Matched information:", result.groupdict()) # Returns the keyword grouping. {'year': '2020', 'month': '10', 'day': '10'}Pattern object
Regular expressions are compiled into pattern objects, which can be used to match and find the text by a series of methods of pattern
Now.
Some common methods of Pattern object are as follows:
• match method: starting from the starting position, one match
• search method: search from any location, one match
• findall method: match all, return list
• finditor method: match all, return iterator
• split method: split string, return list
• sub method: replace
match method
The match method is used to find the header of the string (or specify the starting position), which is a match, as long as
When a match is found, it is returned instead of finding all the matches. Its general use form is as follows:
• string string string to be matched
• starting position of pos string, default value is 0
• the end position of the endpos string. The default value is len (string length)
Match object
• the group([group1,...]) method is used to get one or more group matching strings, when you want to get the whole matching substring
group() or group(0) can be used directly;
• the start([group]) method is used to get the starting position of the substring matched by the group in the whole string (the first character of the substring
Index), the default value of the parameter is 0;
• end([group]) method is used to obtain the end position (the last character of the substring) of the matched substring in the whole string
The default value of the parameter is 0;
• span([group]) method return (start(group), end(group))
search method
The search method is used to find any position of the string. It is also a match, as long as a matching is found
The result is returned instead of finding all matching results. Its general use form is as follows:
When the Match is successful, a Match object is returned, and if there is no Match, None is returned.
findall method and findier method
The findall method searches the entire string for all matching results. The use form is as follows
The behavior of the finder method is similar to that of findall. It also searches the entire string to get
All matching results. But it returns a sequential access to each Match (Match object)
Iterator for.
split method
The split method splits the string according to the matching substring and returns the list. Its usage is as follows:
• maxplit specifies the maximum number of splits, not all splits
sub method
The sub method is used for replacement. Its use form is as follows:
import re
#****************************split***************************
#text = '1+2*4+8-9/10'
##String method: '172.25.254.250'. Split ('.') = > ['172 ',' 25 ',' 254 ',' 250 ']
#pattern = re.compile(r'\+|-|\*|/')
##Cut the string according to + or - or * or /
#result = re.split(pattern, text)
#print(result)
#***********************sub**************************************
def repl_string(matchObj):
# matchObj method: group, groups, group Dict
items = matchObj.groups()
#print("Matched group content: ", items) # ('2019', '10', '10')
return "-".join(items)
#2019/10/10 ====> 2019-10-10
text = "2019/10/10 2020/12/12 2019-12-10 2020-11-10"
pattern = re.compile(r'(\d{4})/(\d{1,2})/(\d{1,2})') # Note: do not leave any spaces in the regular rules
#Replace all qualified information with '2019-10-10'
#result = re.sub(pattern, '2019-10-10', text)
#Replace all eligible information with 'Year Month Day'
result = re.sub(pattern, repl_string, text)
print(result)• repl can be a string or a function:
1) . if repl is a string, repl will be used to replace each matching substring of the string and return the replacement
In addition, repl can also use the form of id to refer to the group, but cannot use the number 0;
2) If repl is a function, this method should take only one parameter (Match object) and return one word
The string is used for replacement (the returned string can no longer reference grouping).
• count is used to specify the maximum number of replacement times. If not specified, replace all.
In some cases, if we want to match the Chinese characters in the text, we need to pay attention to the unicode code of Chinese
The scope is mainly in [u4e00-u9fa5], which is mainly because it is not complete, such as not including full angle (Chinese) punctuation, but in most cases, it should be sufficient
Greedy mode and non greedy mode: ABB BC
- Greedy pattern: on the premise that the whole expression matches successfully, match as many as possible ();
Using the regular expression ab of greedy quantifier, match the result: abbb.- It's decided to match as many b as possible, so all b's after a appear.
- Non greedy pattern: on the premise that the whole expression matches successfully, match as few (?) as possible;
Use the regular expression ab? Of non greedy quantifier to match the result: a.
Even if there is one in front, but? Decided to match b as little as possible, so there is no b. - In Python, quantifiers are greedy by default.
Common regular constants:
"ASCII": 'A'
"IGNORECASE": 'I'
"MULTILINE":'M'
"DOTALL":'S'
import re
#******************************** 1. re.ASCII *****************************
#text = "the regular expression re module is a built-in model in python."
##Match all \ w + (alphanumeric underline, also match Chinese by default). If you don't want to match Chinese, specify flags=re.A
#result = re.findall(r'\w+', string=text, flags=re.A)
#print(result)
#******************************** 2. re.IGNORECASE *****************************
#text = 'hello world heLLo westos Hello python'
##Match all he\w+o, ignore case, re.I
#result = re.findall(r'he\w+o', text, re.I)
#print(result) # ['hello', 'heLLo', 'Hello']
##******************************** 3. re.S *****************************
#text = 'hello \n world'
#result = re.findall(r'^he.*?ld$', text, re.S)
#print(result)
##************************Match Chinese**********************
#pattern = r'[\u4e00-\u9fa5]'
#text = "the regular expression re module is a built-in model in python."
#result = re.findall(pattern, text)
#print(result)XPath Library
lxml is a parsing library of python, which supports the parsing of HTML and XML, and the parsing of XPath
Very efficient.
XPath (XML Path Language) is a language for finding information in xml documents. It can be used to find information in xml documents
/Elements and attributes are traversed in html documents.
Predicates
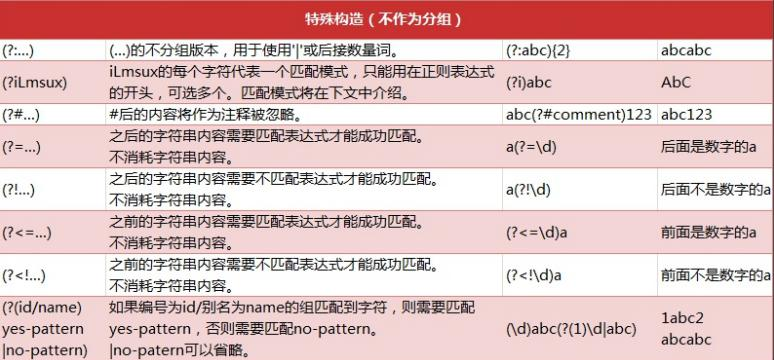
The predicate is used to find a specific node or a node containing a specified value, which is embedded in square brackets.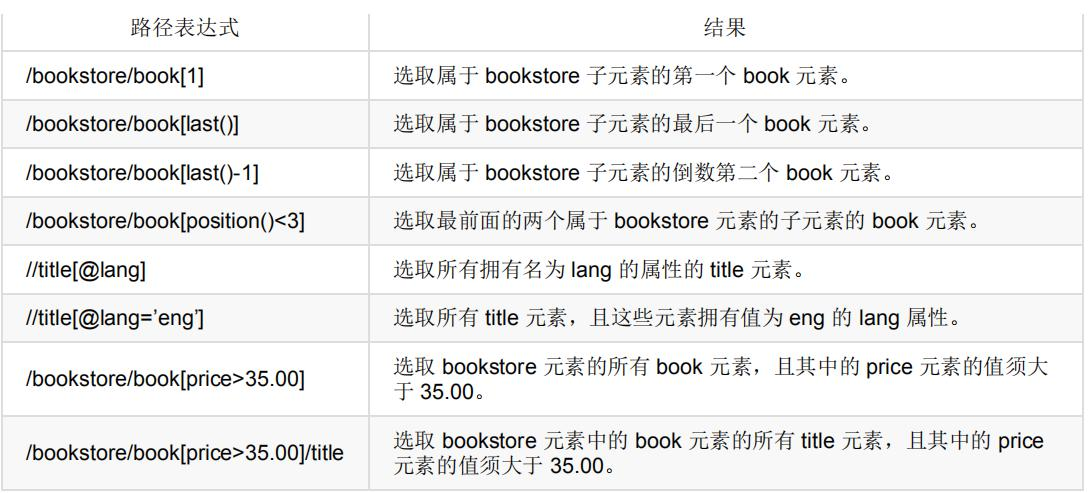
Summary of common XPath rules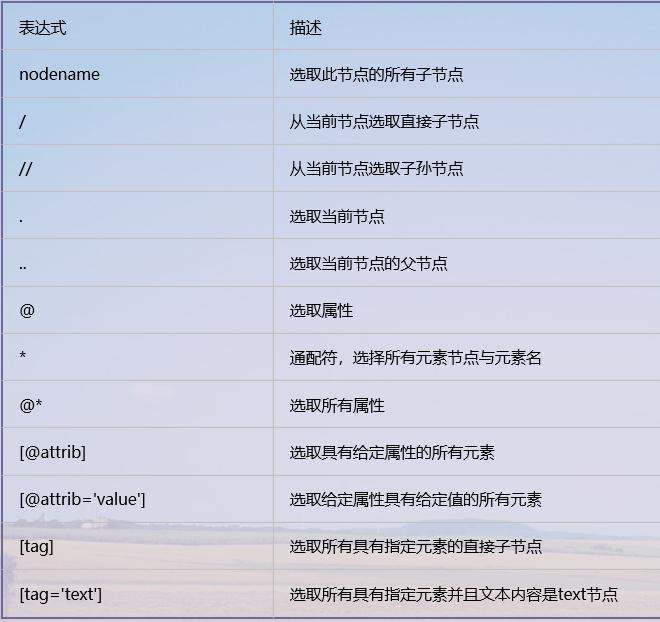
Tibbe programming language leaderboard oriented crawler based on requests and Xpath.py
import csv
import requests
from colorama import Fore
from fake_useragent import UserAgent
from lxml import etree
from requests import HTTPError
def download_page(url, parmas=None):
"""
//Download html page according to url address
:param url:
:param parmas:
:return: str
"""
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
}
#When requesting the https protocol, an error is returned: SSLError
#Verify = false do not verify certificate
response = requests.get(url, params=parmas, headers=headers)
except HTTPError as e:
print(Fore.RED + '[-] Crawling website%s fail: %s' % (url, str(e)))
return None
else:
# content returns bytes type, text returns string type
return response.text
def parse_html(html):
"""
//Last year's ranking, this year's ranking, programming language name, Rating and Change rate of programming language.
:param html:
:return:
"""
#1) . parse the page information through the lxml parser and return the Element object
html = etree.HTML(html)
#2) Find the syntax according to the path of Xpath to obtain the information about programming language
#Get the Element object of each programming language
#<table id="top20" class="table table-striped table-top20">
languages = html.xpath('//table[@id="top20"]/tbody/tr')
# Obtain last year's ranking, this year's ranking, programming language name, Rating, Change rate and other information of each language in turn.
for language in languages:
# Note: when indexing in Xpath, start from 1
now_rank = language.xpath('./td[1]/text()')[0]
last_rank = language.xpath('./td[2]/text()')[0]
name = language.xpath('./td[4]/text()')[0]
rating = language.xpath('./td[5]/text()')[0]
change = language.xpath('./td[6]/text()')[0]
yield {
'now_rank': now_rank,
'last_rank': last_rank,
'name': name,
'rating': rating,
'change': change
}
def save_to_csv(data, filename):
# 1). data is the dictionary object returned by yield
# 2) . open file as append and write
# 3) . the encoding format of the file is utf-8
# 4) . there will be a blank line in the default csv file write, newline = ''
with open(filename, 'a', encoding='utf-8', newline='') as f:
csv_writer = csv.DictWriter(f, ['now_rank', 'last_rank', 'name', 'rating', 'change'])
# Write header of csv file
# csv_writer.writeheader()
csv_writer.writerow(data)
def get_one_page(page=1):
url = 'https://www.tiobe.com/tiobe-index/'
filename = 'tiobe.csv'
html = download_page(url)
items = parse_html(html)
for item in items:
save_to_csv(item, filename)
print(Fore.GREEN + '[+] write file%s Success' %(filename))
if __name__ == '__main__':
get_one_page()