Article directory
Preface
This section will take a look at the decoder that Netty provides to users out of the box: DelimiterBasedFrameDecoder.
Before reading, try to make sure there is a certain ByteBuf foundation. For example, you must know the readerIndex and writerIndex. Please refer to my previous blog records [about ByteBuf].
If there is any doubt about the general process of decoder, it is recommended to go back and have a look [ByteToMessageDecoder] In this paper, we will not talk about the whole process, and focus on the decode method of decoder.
Netty Version: 4.1.6
Experimental code
Also take the unit test provided by Netty:
import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled; import io.netty.channel.embedded.EmbeddedChannel; import io.netty.util.CharsetUtil; import io.netty.util.ReferenceCountUtil; import org.junit.Test; import java.nio.charset.Charset; import static io.netty.util.ReferenceCountUtil.releaseLater; import static org.junit.Assert.*; public class DelimiterBasedFrameDecoderTest { @Test public void testMultipleLinesStrippedDelimiters() { EmbeddedChannel ch = new EmbeddedChannel(new DelimiterBasedFrameDecoder(8192, true, delimiter())); ch.writeInbound(Unpooled.copiedBuffer("firstgasecondga", Charset.defaultCharset())); System.out.println(releaseLater((ByteBuf) ch.readInbound()).toString(Charset.defaultCharset())); System.out.println(releaseLater((ByteBuf) ch.readInbound()).toString(Charset.defaultCharset())); System.out.println(releaseLater((ByteBuf) ch.readInbound()).toString(Charset.defaultCharset())); ch.finish(); } // Custom separator private static ByteBuf[] delimiter() { return new ByteBuf[] { Unpooled.wrappedBuffer(new byte[] { 'a' }), Unpooled.wrappedBuffer(new byte[] { 'g' }), }; } }
Output results:
first second
- first and second are indeed separated. That is to say, the second readInbound does not have a string. It's not that I wrote markdown wrong.
- Why read in bound for the second time? After reading the analysis of this article, you see.
- If the "firstgasecondga" of the experiment code is replaced by "firstgeeasecondga", the blank in the middle of the output result will become "ee"
Follow up source code
DelimiterBasedFrameDecoder inheritance relationship
Let's first look at the inheritance diagram of DelimiterBasedFrameDecoder:
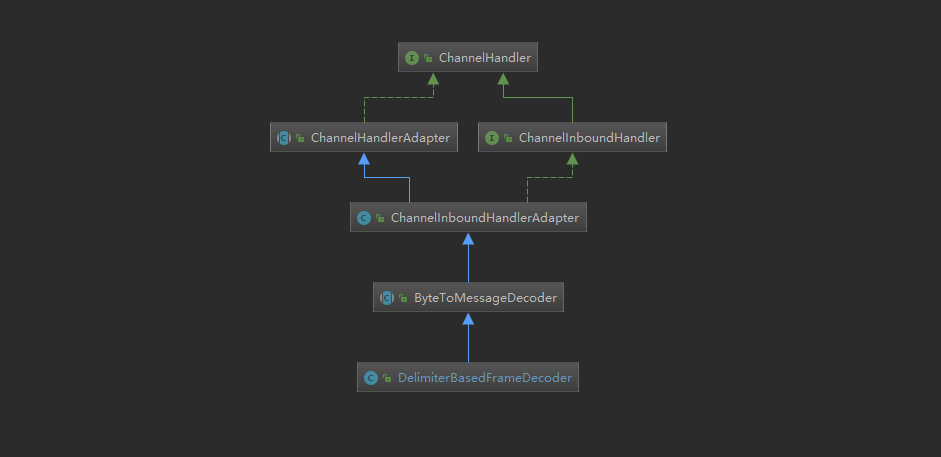
- On some classes in the graph, I [difference between inbound and outbound events] Mentioned.
- ByteToMessageDecoder in [previous section] Mentioned.
From the above class diagram, combined with the previous learning experience of pipeline, it is not difficult to find that we can actually regard LineBasedFrameDecoder as a channel handler, that is to say, decoding is actually one of the links in event propagation and processing. The code is similar to the following:
// slightly .childHandler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) { ch.pipeline().addLast(new Base64Decoder()); ch.pipeline().addLast(new DelimiterBasedFrameDecoder()); ch.pipeline().addLast(new FixedLengthFrameDecoder(3)); ch.pipeline().addLast(new LineBasedFrameDecoder(10, false, false)); }
- (the above passage has been said in the previous section. It's just for me to emphasize.)
Properties of DelimiterBasedFrameDecoder
I still annotate the source code:
public class DelimiterBasedFrameDecoder extends ByteToMessageDecoder { /** Separator, multiple */ private final ByteBuf[] delimiters; /** How long is the maximum packet capacity */ private final int maxFrameLength; /** Do packets need to keep delimiters */ private final boolean stripDelimiter; /** Whether to throw an exception after maxFrameLength is exceeded */ private final boolean failFast; /** Whether it belongs to discard mode */ private boolean discardingTooLongFrame; /** Bytes discarded */ private int tooLongFrameLength; /** Set only when decoding with "\n" and "\r\n" as the delimiter. */ /** As mentioned before, line decoder means that if the separator is only \ N and \ r\n, it will be directly thrown to line decoder (code reuse)*/ private final LineBasedFrameDecoder lineBasedDecoder; ...(Non attribute omitted)
Analysis of construction method
You may wonder: why does the LineBasedFrameDecoder mentioned in the previous section appear in the separator decoder? When is this LineBasedFrameDecoder!=null? The answers to these questions are actually in the construction method. Let's take a look at the following:
io.netty.handler.codec.DelimiterBasedFrameDecoder#DelimiterBasedFrameDecoder(int, boolean, boolean, io.netty.buffer.ByteBuf...)
public DelimiterBasedFrameDecoder( int maxFrameLength, boolean stripDelimiter, boolean failFast, ByteBuf... delimiters) { validateMaxFrameLength(maxFrameLength); if (delimiters == null) { throw new NullPointerException("delimiters"); } if (delimiters.length == 0) { throw new IllegalArgumentException("empty delimiters"); } // If split by line break only if (isLineBased(delimiters) && !isSubclass()) { // Create a newline decoder object lineBasedDecoder = new LineBasedFrameDecoder(maxFrameLength, stripDelimiter, failFast); this.delimiters = null; } else { this.delimiters = new ByteBuf[delimiters.length]; for (int i = 0; i < delimiters.length; i ++) { ByteBuf d = delimiters[i]; validateDelimiter(d); this.delimiters[i] = d.slice(d.readerIndex(), d.readableBytes()); } // If the separator is not just a line feed or does not include a line feed, it is left blank. lineBasedDecoder = null; } this.maxFrameLength = maxFrameLength; this.stripDelimiter = stripDelimiter; this.failFast = failFast; }
Follow up the isLineBased method and verify if you want to:
io.netty.handler.codec.DelimiterBasedFrameDecoder#isLineBased
// Determine if only line breaks are used as separators private static boolean isLineBased(final ByteBuf[] delimiters) { // If the number of delimiters is less than 2, it must not be a line break (line breaks include \ r\n and \ n) and return false if (delimiters.length != 2) { return false; } // Get the first two separators ByteBuf a = delimiters[0]; ByteBuf b = delimiters[1]; if (a.capacity() < b.capacity()) { a = delimiters[1]; b = delimiters[0]; } // Determine if it is split by \ n & & \ R \ n return a.capacity() == 2 && b.capacity() == 1 && a.getByte(0) == '\r' && a.getByte(1) == '\n' && b.getByte(0) == '\n'; }
To put it bluntly: if the separator is just two line breaks, it can be directly thrown to the LineBasedFrameDecoder instance for processing. Reuse Principle~
decode implementation
Next is the core part, which decodes the data from the ByteToMessageDecoder accumulator.
Find the decode method and look at the code directly:
io.netty.handler.codec.DelimiterBasedFrameDecoder#decode(io.netty.channel.ChannelHandlerContext, io.netty.buffer.ByteBuf, java.util.List<java.lang.Object>)
@Override protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { Object decoded = decode(ctx, in); if (decoded != null) { // The decoded object is added to out and handed to ByteToMessageDecoder for propagation out.add(decoded); } }
Continue to follow up the decode method, and also write what the code does into the comments. The following will also draw a picture for analysis:
io.netty.handler.codec.DelimiterBasedFrameDecoder#decode(io.netty.channel.ChannelHandlerContext, io.netty.buffer.ByteBuf)
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception { // If the separator is a line break (determined when constructing this decoder) if (lineBasedDecoder != null) { // Direct throw to line processor return lineBasedDecoder.decode(ctx, buffer); } // Try all delimiters and choose the delimiter which yields the shortest frame. // index for recording the minimum separator int minFrameLength = Integer.MAX_VALUE; // Minimum length separator ByteBuf minDelim = null; for (ByteBuf delim: delimiters) { int frameLength = indexOf(buffer, delim); // Calculate which separator reads the minimum data length if (frameLength >= 0 && frameLength < minFrameLength) { // Record minimum length minFrameLength = frameLength; // Minimum record length separator minDelim = delim; } } // Start decoding logic below if (minDelim != null) { // Returns the length occupied by the separator int minDelimLength = minDelim.capacity(); ByteBuf frame; // If it belongs to discard mode if (discardingTooLongFrame) { // We've just finished discarding a very large frame. // Go back to the initial state. discardingTooLongFrame = false; buffer.skipBytes(minFrameLength + minDelimLength); int tooLongFrameLength = this.tooLongFrameLength; this.tooLongFrameLength = 0; if (!failFast) { fail(tooLongFrameLength); } return null; } // Len gt h of packets read > maximum packets currently allowed if (minFrameLength > maxFrameLength) { // Discard read frame. // Read pointer moves after separator buffer.skipBytes(minFrameLength + minDelimLength); // Throw exception (not exception propagation) fail(minFrameLength); return null; } // Need to keep separator if (stripDelimiter) { // Do not keep separator frame = buffer.readRetainedSlice(minFrameLength); buffer.skipBytes(minDelimLength); } else { // Keep separator frame = buffer.readRetainedSlice(minFrameLength + minDelimLength); } // Return packets read return frame; } // If you don't read the separator else { // Non discard mode if (!discardingTooLongFrame) { // Packet length greater than maximum capacity if (buffer.readableBytes() > maxFrameLength) { // Discard the content of the buffer until a delimiter is found. tooLongFrameLength = buffer.readableBytes(); buffer.skipBytes(buffer.readableBytes()); // Enable discard mode discardingTooLongFrame = true; // Whether to throw an exception (not exception propagation) if (failFast) { fail(tooLongFrameLength); } } } else { // Discard mode // Still discarding the buffer since a delimiter is not found. tooLongFrameLength += buffer.readableBytes(); buffer.skipBytes(buffer.readableBytes()); } return null; } }
Before looking at the overall process, you may be confused by the above code segment:
// Minimum length separator ByteBuf minDelim = null; for (ByteBuf delim: delimiters) { int frameLength = indexOf(buffer, delim); // Calculate which separator reads the minimum data length if (frameLength >= 0 && frameLength < minFrameLength) { // Record minimum length minFrameLength = frameLength; // Minimum record length separator minDelim = delim; } }
Here is a picture to explain: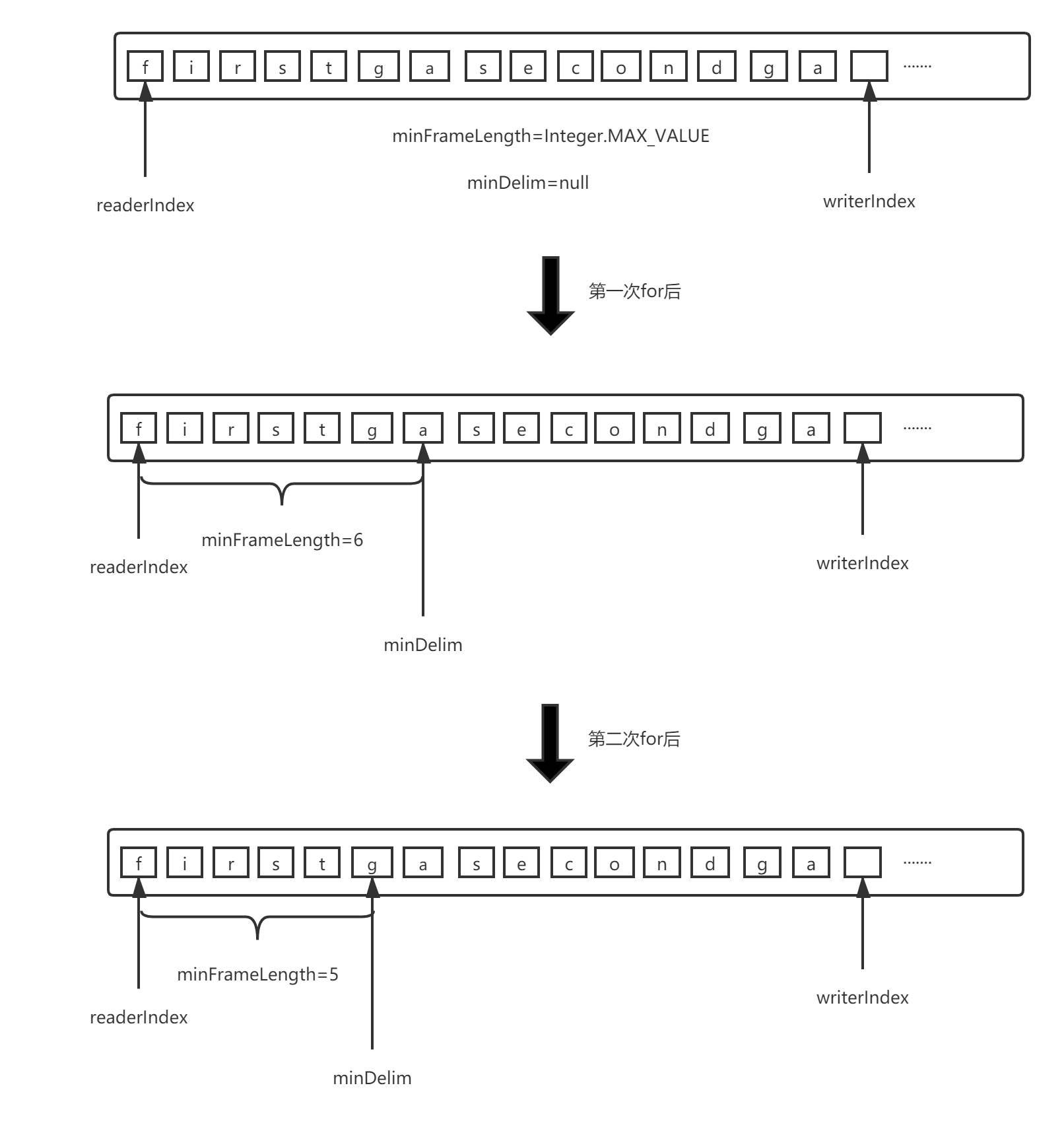
- To put it bluntly, it is to obtain the separator with the shortest distance from the record readerIndex and the distance from the readerIndex to the separator.
Combined with the experimental code, the above decode process is roughly as follows:
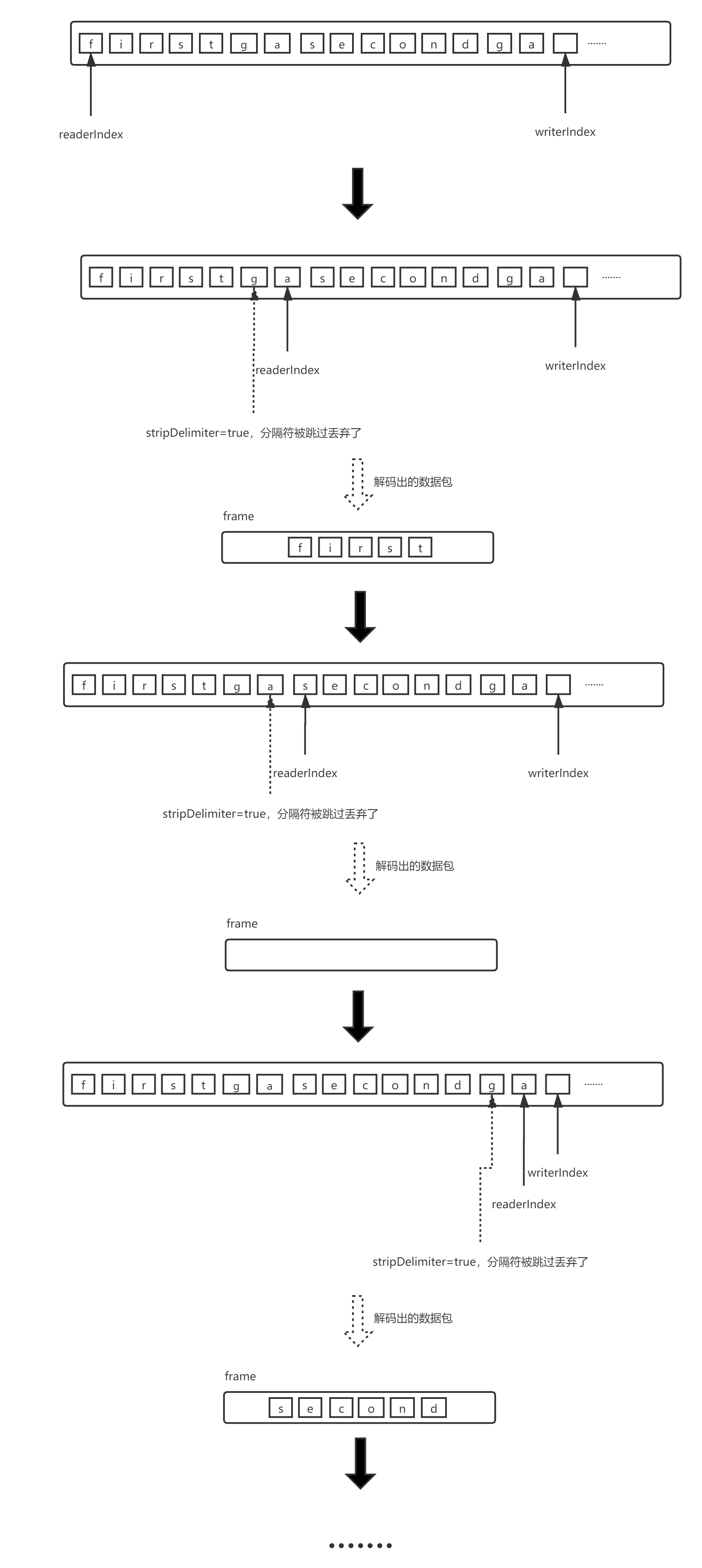
Well, the general process of decode experimental code test data with decode method is as shown in the figure above. I believe that the above doubts can be solved after reading. For exceptions such as discard mode, you can continue to follow up with unit tests provided by Netty if you are interested. I won't go into details here.

