What is rule participle
Rule based word segmentation is a mechanical word segmentation method, which is mainly through maintaining the dictionary. When segmenting a sentence, match each string of the sentence with the words in the thesaurus one by one, and if found, it will be segmented, otherwise it will not be segmented.
According to the way of matching segmentation, there are three methods: forward maximum matching method, reverse maximum matching method and two-way maximum matching method.
Forward maximum matching method (MM method)
1. Algorithm description
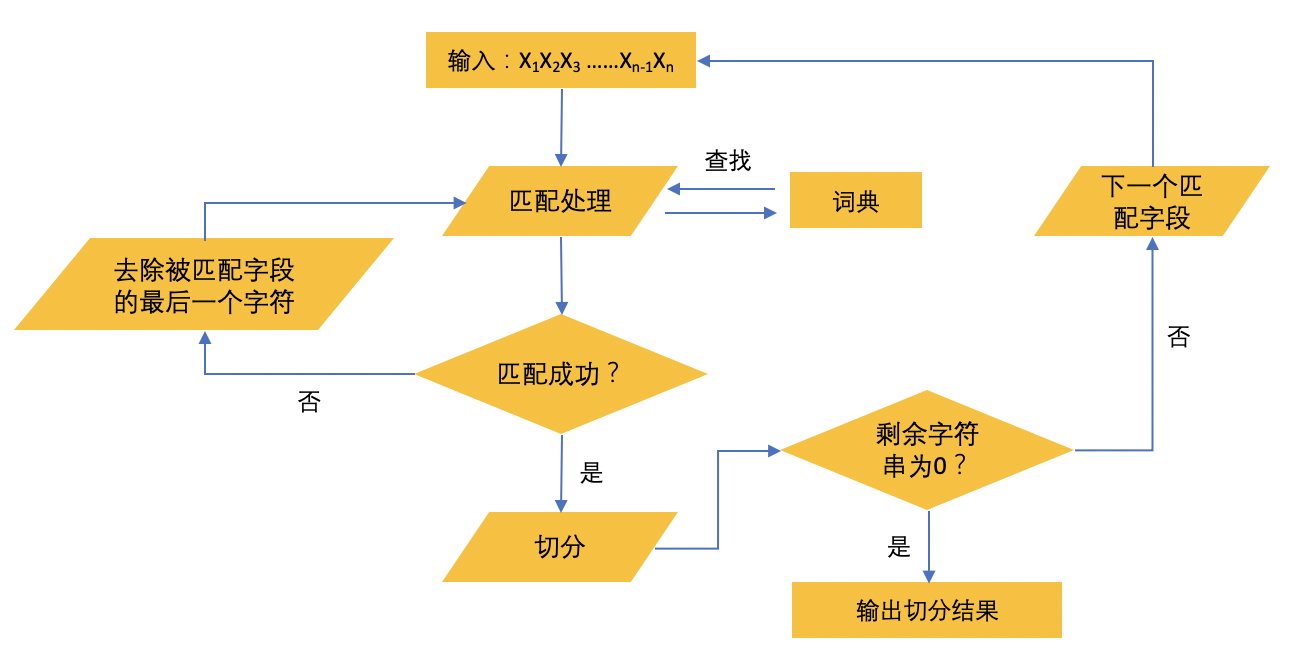
As shown in the figure, the specific steps of the forward maximum matching method are:
- Take m characters of the Chinese sentence to be segmented from left to right as the matching field. m is the number of characters of the longest entry in the machine dictionary;
- Find the machine dictionary and match it. If the matching is successful, the matching field will be cut out as a word. If the matching fails, the last word of the matching field will be removed, and the remaining string will be used as a new matching field for re matching. Repeat the above process until all words are cut out.
2. Main ideas:
Assuming that the longest word in the word segmentation dictionary has i Chinese characters, the first i words in the current string of the processed document are used as the matching field to find the dictionary, so as to obtain the word segmentation result.
3. Example:
The longest length in our existing word segmentation dictionary is 5. There are three words in the dictionary: Nanjing, Yangtze River and bridge. Now we use MM method to segment the sentence of Nanjing Yangtze River Bridge. First, take the first five words of Nanjing Yangtze River from the sentence and find that there is no such word in the dictionary, so reduce the length, take the first four words of Nanjing Mayor and find that there is still no such word in the dictionary, So continue to reduce the length, take the first three words, Nanjing, the word exists in the dictionary, so the word is confirmed to be segmented. Then the remaining Yangtze River bridges are segmented in the same way to get the Yangtze River and bridge, and finally divided into three words: Nanjing / Yangtze River / bridge.
#test.py
def cutA(sentence, dictA):
# Sentence: sentence to be segmented
result = []
sentenceLen = len(sentence)
n = 0
maxDictA = max([len(word) for word in dictA])
# Complete the code description of the forward matching algorithm and save the results to the result variable
# The result variable is the word segmentation result
while sentenceLen>0:
word=sentence[0:maxDictA]
while word not in dictA:
if len(word)==1:
break
word=word[0:len(word)-1]
result.append(word)
sentence=sentence[len(word):]
sentenceLen=len(sentence)
print(result) # Output word segmentation results
#main.py
from test import cutA
str = input()
dict = []
for i in range(0, str.split(" ").__len__()):
dict.append(str.split(" ")[i])
sentence = input()
cutA(sentence, dict)Inverse maximum matching method
1. Algorithm description:
The basic idea of reverse maximum matching (RMM) method is the same as MM method, except that the direction of word segmentation is opposite to MM method. The reverse maximum matching method performs segmentation from right to left. Take the rightmost (end) m characters as the matching field each time. If the matching fails, remove the leftmost (front) word of the matching field and continue the matching.
2. Example:
For example, Nanjing Yangtze River Bridge, according to the reverse maximum matching, the length of the characters of the longest entry in the word segmentation dictionary is 5. There are two words in the word segmentation Dictionary: Nanjing Mayor and Yangtze River Bridge. Now the RMM method is used to segment the sentence Nanjing Yangtze River Bridge. First, take the first five words from right to left from the sentence, and find that there is no such word in the dictionary, so reduce the length, Take the first four words Yangtze River Bridge. The word exists in the dictionary, so the word is confirmed to be segmented. Then the remaining Nanjing city is segmented in the same way to get Nanjing City, which is finally segmented into two words: Nanjing City / Yangtze River Bridge. Of course, such segmentation does not mean that it is completely correct. There may be a mayor of Nanjing called Jiang Bridge.
Because there are too many positive structures in Chinese, the accuracy of reverse maximum matching segmentation is higher than that of positive maximum matching segmentation.
test.py
def cutB(sentence,dictB):
result = []
sentenceLen = len(sentence)
maxDictB = max([len(word) for word in dictB])
# Task: complete the code description of the reverse maximum matching algorithm
while sentenceLen>0:
word=sentence[-maxDictB:]
while word not in dictB:
if len(word)==1:
break
word=word[1:]
result.append(word)
sentence=sentence[0:len(sentence)-len(word)]
sentenceLen=len(sentence)
print(result[::-1],end="")
#main.py
from test import cutB
str = input()
dict = []
for i in range(0, str.split(" ").__len__()):
dict.append(str.split(" ")[i])
sentence = input()
cutB(sentence, dict)Bidirectional maximum matching method
The basic idea of bidirectional maximum matching is to compare the word segmentation results obtained by the forward maximum matching method with the word segmentation results obtained by the reverse maximum matching method, and then select the one with the least word segmentation as the result according to the maximum matching principle. The specific description of the matching algorithm is as follows:
-
The results of forward maximum matching and reverse maximum matching are compared;
-
If the result of the number of participles is different, take the one with the smaller number of participles;
-
If the number of word segmentation results are the same, any one can be returned if the word segmentation results are the same; If the word segmentation results are different, the one with less single words is returned.
For example, if the sentence "Peking University students come to apply for a job", if the result obtained by the forward maximum matching algorithm is Peking University / before life / come / apply for a job, the number of word segments is 4 and the number of single words is 1; The result obtained by the reverse maximum matching algorithm is Beijing / college students / coming / applying, in which the number of word segmentation is 4 and the number of single words is 0. According to the bidirectional maximum matching algorithm, the number of reverse matching words is small, so the result of reverse matching is returned.
The research shows that 90% of Chinese use forward maximum matching segmentation and reverse maximum matching segmentation to get the same results, and ensure the correct segmentation; 9% of the sentences have differences between positive maximum matching segmentation and reverse maximum matching segmentation, but one of them must be correct; Less than 1% of sentences are forward and reverse, and make the same mistake at the same time: give the same result, but they are all wrong. Therefore, in the actual Chinese processing, bidirectional maximum matching word segmentation can be competent for almost all scenarios.
#test.py
class BiMM():
def __init__(self):
self.window_size = 3 # Longest words in dictionary
def MMseg(self, text, dict): # Forward maximum matching algorithm
result = []
index = 0
text_length = len(text)
while text_length > index:
for size in range(self.window_size + index, index, -1):
piece = text[index:size]
if piece in dict:
index = size - 1
break
index += 1
result.append(piece)
return result
def RMMseg(self, text, dict): # Inverse maximum matching algorithm
result = []
index = len(text)
while index > 0:
for size in range(index - self.window_size, index):
piece = text[size:index]
if piece in dict:
index = size + 1
break
index = index - 1
result.append(piece)
result.reverse()
return result
def main(self, text, r1, r2):
#Complete the code description of bidirectional maximum matching algorithm
r1_count=0
r2_count=0
if len(r1)>len(r2):
print(r2,end="")
elif len(r1)<len(r2):
print(r1,end="")
else:
for i in r1:
if len(i)==1:
r1_count=r1_count+1
for j in r2:
if len(j)==1:
r2_count=r2_count+1
if r1_count==r2_count:
print(r1,end="")
elif r1_count>r2_count:
print(r2,end="")
else:
print(r1,end="")
#main.py
from test import BiMM
dict = [ ]
str=input()
for i in range(0, str.split(" ").__len__()):
dict.append(str.split(" ")[i])
text = input()
tokenizer = BiMM()
r1 = tokenizer.MMseg(text, dict)
r2 = tokenizer.RMMseg(text, dict)
tokenizer.main(text, r1, r2)
Test input:
Here are apples, bananas and red apples
Here are red apples and bananas
Output:
['here', 'there', 'Red Apple', 'and', 'Banana']