If you have a basic knowledge of babel, it is recommended to skip the pre knowledge section and go directly to the "plug-in writing" section.
Pre knowledge
What is AST
To learn babel, the necessary knowledge is to understand AST.
What is AST?
Let's take a look at the Wikipedia explanation:
In computer science, Abstract Syntax Tree (AST), or Syntax tree for short, is an abstract representation of the syntax structure of source code. It represents the syntax structure of the programming language in the form of a tree, and each node on the tree represents a structure in the source code
The words "an abstract representation of the syntax structure of source code" should be emphasized, which is the key to our understanding of AST. Speaking human language is to describe our code in a tree data structure according to some agreed specification, so that js engine and translator can understand it.
For example: just as the framework will use virtual dom to describe the real dom structure and then operate, AST is a good tool to describe the code for the lower level code.
Of course, AST is not unique to js. The code of each language can be converted into the corresponding ast, and there are many specifications of AST structure. Most of the specifications used in js are estree Of course, this is just a simple understanding.
What does AST look like
After understanding the basic concept of AST, what does ast look like?
astexplorer.net This website can generate ast online. We can try to generate AST in it to learn the structure
babel process
Q: how many stages does it take to put the refrigerator into the elephant?
Open the refrigerator - > insert the elephant - > close the refrigerator
babel is the same. babel compiles the code in the way of AST. First of all, it naturally needs to change the code into ast, then process the ast, and then convert the ast back after processing
This is the following process
Convert code to ast - > process ast - > Convert AST to code
Then we give them a more professional name
Parse - > Transform - > generate
parse
Turn the source code into an abstract syntax tree (AST) through parser
The main task of this stage is to convert code to AST, which will go through two stages: lexical analysis and syntax analysis. When the parse phase starts, the document is scanned first and lexical analysis is performed during this period. If we compare a code we wrote to a sentence, what lexical analysis does is to split the sentence. Just as the sentence "I'm eating" can be disassembled into "I", "I'm eating" and "eating", so is code. For example, const a = '1' will be disassembled into the most fine-grained words (tokon): 'const', 'a', 'a' = ',' 1 ', which is what the lexical analysis stage does.
After the lexical analysis, the tokens obtained from the analysis are handed over to the syntax analysis. The task of the syntax analysis stage is to generate AST according to the tokens. It will traverse tokens and finally generate a tree according to a specific structure, which is AST.
As shown in the following figure, we can see the structure of the above statement. We found several important information. The outermost layer is a VariableDeclaration, which means variable declaration. The type used is const. There is also a VariableDeclarator [variable declarator] object in the field declarations. We found two keywords a and 1. 
In addition to these keywords, you can also find important information such as line number, which will not be described one by one here. In short, this is what we finally got as AST.
That's the problem. How to convert code into AST in babel? At this stage, we will use the parser @ babel/parser provided by babel, formerly known as Babylon. It is not developed by babel team, but acorn project based on fork.
It provides us with a method to convert code into AST. The basic usage is as follows:

More information can be found in the official documentation @babel/parser
transform
After the parse phase, we have successfully obtained the ast. After babel receives the ast, it will use @ babel/traverse to traverse it in depth first. The plug-in will be triggered at this stage to access each different type of AST node in the form of visitor function. Taking the above code as an example, we can write a VariableDeclaration function to access the VariableDeclaration node. This method will be triggered whenever this type of node is encountered. As follows:

The method accepts two parameters,
path
Path is the current access path, and contains node information, parent node information and many methods to operate on the node. These methods can be used to add, update, move and delete ATS.
state
state contains the information and parameter information of the current plugin, and can also be used to customize the transfer of data between nodes.
generate
Generate: print the converted AST into object code and generate sourcemap
This stage is relatively simple. After the AST is processed in the transform stage, the task of this stage is to convert the ast back to code. During this period, the ast will be depth first traversed, the corresponding code will be generated according to the information contained in the node, and the corresponding sourcemap will be generated.
Classic case attempt
As the saying goes, the best learning is hands-on. Let's try a simple classic case: convert the const of es6 in the above case into the var of es5
Step 1: convert to AST
Generate AST using @ babel/parser
It's simple. It's the same as the above case. At this time, the AST variable is the converted AST
const parser = require('@babel/parser');
const ast = parser.parse('const a = 1');Step 2: process AST
Use @ babel/traverse to process AST
At this stage, by analyzing the generated AST structure, we determine that const is controlled by the kind field in variable declaration, so can we try to rewrite kind into the var we want? In that case, let's try

const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default
const ast = parser.parse('const a = 1');
traverse(ast, {
VariableDeclaration(path, state) {
// Access the actual AST node through path.node
path.node.kind = 'var'
}
});OK, at this time, we modify kind based on Conjecture and change it to var, but we still don't know whether it is actually effective, so we need to convert it back to code to see the effect.
Step 3: generate code
Use @ babel/generator to process AST
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default
const generate = require('@babel/generator').default
const ast = parser.parse('const a = 1');
traverse(ast, {
VariableDeclaration(path, state) {
path.node.kind = 'var'
}
});
// Put the processed AST into generate
const transformedCode = generate(ast).code
console.log(transformedCode)Let's look at the effect:

The implementation is completed and successful. It is the effect we want ~
How to develop plug-ins
Through the above classic case, I have learned about the use of babel, but how should we write our usual plug-ins?
In fact, the basic idea of plug-in development is the same as that above, but as a plug-in, we only need to pay attention to the transformation stage
Our plug-in needs to export a function / object. If it is a function, it needs to return an object. We only need to do the same thing in the visitor of the changed object, and the function will accept several parameters. The api inherits a series of methods provided by babel. options are the parameters passed when we use the plug-in, and dirname is the file path during processing.
Take the above case as follows:
module.exports = {
visitor: {
VariableDeclaration(path, state) {
path.node.kind = 'var'
}
}
}
// Or functional form
module.exports = (api, options, dirname) => {
return {
visitor: {
VariableDeclaration(path, state) {
path.node.kind = 'var'
}
}
}
}Plug in writing
On the basis of prior knowledge, we will explain and develop a babel plug-in step by step. First, we define the core requirements of the plug-in to be developed:
- A function can be automatically inserted and called.
- Automatically import dependencies related to insert functions.
- You can specify the function to be inserted and the function to be inserted by annotation. If it is not specified by annotation, the default insertion position is in the first column.
The basic effects are shown as follows:
Before treatment
// log declares the method that needs to be inserted and called
// @inject:log
function fn() {
console.log(1)
// Specify the insertion line with @ inject:code
// @inject:code
console.log(2)
}After treatment
// After importing package xxx, provide configuration in plug-in parameters
import log from 'xxx'
function fn() {
console.log(1)
log()
console.log(2)
}Thought arrangement
After understanding the general requirements, we don't have to worry about it. We have to think about how we want to start. We have envisaged the problems that need to be handled in the process.
- Find the function marked with @ inject, and then check whether there is a location mark of @ inject:code inside it.
- Import the appropriate packages for all inserted functions.
- When the tag is matched, all we need to do is insert the function. At the same time, we also need to deal with the functions in various cases, such as object method, iife, arrow function and so on.
Design plug-in parameters
In order to improve the flexibility of plug-ins, we need to design a more appropriate parameter rule. The plug-in parameter accepts an object.
key as the function name of the insertion function.
kind represents the import form. There are three import methods named, default and named. This is a design reference babel-helper-module-imports
- named corresponds to import {a} from "B"
- default corresponds to import a from "b"
- Named corresponds to import * as a from "b"
require is the dependent package name
For example, I need to insert the log method, which needs to be imported from the package log4js in the form of named, and the parameters are as follows.
// babel.config.js
module.exports = {
plugins: [
// Fill in the js file address of our plugin
['./babel-plugin-myplugin.js', {
log: {
// The import method is named
kind: 'named',
require: 'log4js'
}
}]
]
}start
OK, after knowing what to do and designing the rules of parameters, we can start.
First we enter https://astexplorer.net/ The code to be processed is generated into AST to facilitate us to sort out the structure, and then we carry out specific coding
The first is the function declaration statement. Let's analyze its AST structure and how to deal with it. Let's take a look at the demo
// @inject:log
function fn() {
console.log('fn')
}The AST structure generated is as follows. You can see two key attributes:
- leadingComments indicates the front comments. You can see that there is an element inside, which is @ inject:log written in our demo
- Body is the specific content of the function body. The console.log('fn ') written in the demo is in it at this time. We will wait for the code insertion operation to operate it

OK, you can know whether the function needs to be inserted through leading comments. For the body operation, you can realize our code insertion requirements..
First, we have to find the function declaration layer, because only this layer has the leadingComments attribute, and then we need to traverse it to match the function to be inserted. Then insert the matched function into the body, but we need to pay attention to the level of the pluggable body. The body in the function declaration is not an array, but a BlockStatement, which represents the function body of the function, and it also has a body, so our actual operation position is in the body of the BlockStatement

The code is as follows:
module.exports = (api, options, dirname) => {
return {
visitor: {
// Match function declaration node
FunctionDeclaration(path, state) {
// path.get('body ') is equivalent to path.node.body
const pathBody = path.get('body')
if(path.node.leadingComments) {
// Filter out all comments matching @ inject:xxx characters
const leadingComments = path.node.leadingComments.filter(comment => /\@inject:(\w+)/.test(comment.value) )
leadingComments.forEach(comment => {
const injectTypeMatchRes = comment.value.match(/\@inject:(\w+)/)
// Match successful
if( injectTypeMatchRes ) {
// The first matching result is xxx in @ inject:xxx. Let's take it out
const injectType = injectTypeMatchRes[1]
// Get the key of the plug-in parameter to see if xxx has been declared in the plug-in parameter
const sourceModuleList = Object.keys(options)
if( sourceModuleList.includes(injectType) ) {
// Search for @ code:xxx comments inside the body
// Because the comment cannot be accessed directly, you need to access the leadingComments attribute of each AST node in the body
const codeIndex = pathBody.node.body.findIndex(block => block.leadingComments && block.leadingComments.some(comment => new RegExp(`@code:\s?${injectType}`).test(comment.value) ))
// If not declared, the default insertion position is the first line
if( codeIndex === -1 ) {
// Operate the body of 'BlockStatement'
pathBody.node.body.unshift(api.template.statement(`${state.options[injectType].identifierName}()`)());
}else {
pathBody.node.body.splice(codeIndex, 0, api.template.statement(`${state.options[injectType].identifierName}()`)());
}
}
}
})
}
}
}
})
After writing, we look at the results. Log was successfully inserted. Because @ code:log is not used, it is inserted in the first line by default 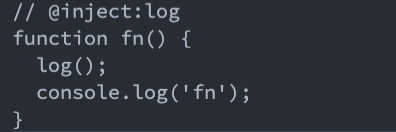
Then we try to use the @ code:log identifier. We change the demo code to the following
// @inject:log
function fn() {
console.log('fn')
// @code:log
}Run the code again to check the results. It is indeed successfully inserted at @ code:log 
After handling the function declaration of our first case, someone may ask, what do you do with arrow functions without function bodies, such as:
// @inject:log () => true
Is there a problem? no problem!

Without a function body, we just give it a function body. How to do it?
First, let's learn to analyze the AST structure. First, we see that the outermost layer is actually an ExpressionStatement expression declaration, and then the ArrowFunctionExpression arrow function expression is inside. It can be seen that the structure generated by the function declaration is very different from our previous structure. In fact, we don't have to be fascinated by such a multi-layer structure, We just need to find the information that is useful to us. In a word, we can find the layer on which there are leading comments. The leading comments here are on the expression statement, so we can just find it

After analyzing the structure, how to judge whether there is a function body? Remember the BlockStatement we saw in the body when processing the function declaration above, and the body of our arrow function you saw was Boolean literal. Therefore, we can judge the body type to know whether there is a function body. The specific method can use the type judgment method path.isBlockStatement() provided by babel to distinguish whether there is a function body.
module.exports = (api, options, dirname) => {
return {
visitor: {
ExpressionStatement(path, state) {
// Access to ArrowFunctionExpression
const expression = path.get('expression')
const pathBody = expression.get('body')
if(path.node.leadingComments) {
// Does the regular match comment have @ inject:xxx characters
const leadingComments = path.node.leadingComments.filter(comment => /\@inject:(\w+)/.test(comment.value) )
leadingComments.forEach(comment => {
const injectTypeMatchRes = comment.value.match(/\@inject:(\w+)/)
// Match successful
if( injectTypeMatchRes ) {
// The first matching result is xxx in @ inject:xxx. Let's take it out
const injectType = injectTypeMatchRes[1]
// Get the key of the plug-in parameter to see if xxx has been declared in the plug-in parameter
const sourceModuleList = Object.keys(options)
if( sourceModuleList.includes(injectType) ) {
// Determine whether there is a function body
if (pathBody.isBlockStatement()) {
// Search for @ code:xxx comments inside the body
// Because the comment cannot be accessed directly, you need to access the leadingComments attribute of each AST node in the body
const codeIndex = pathBody.node.body.findIndex(block => block.leadingComments && block.leadingComments.some(comment => new RegExp(`@code:\s?${injectType}`).test(comment.value) ))
// If not declared, the default insertion position is the first line
if( codeIndex === -1 ) {
pathBody.node.body.unshift(api.template.statement(`${injectType}()`)());
}else {
pathBody.node.body.splice(codeIndex, 0, api.template.statement(`${injectType}()`)());
}
}else {
// Case without function body
// Use the ` @ Babel / template 'API provided by AST to generate ast with code snippets
const ast = api.template.statement(`{${injectType}();return BODY;}`)({BODY: pathBody.node});
// Replace the original body
pathBody.replaceWith(ast);
}
}
}
})
}
}
}
}
}
It can be seen that except for the judgment of the new function body, the generated function body insertion code, and then the new AST to replace the original node, the logic is generally no different from the processing process of the previous function declaration.
The API usage of @ babel/template used to generate AST can be viewed in the document @babel/template
The functions in different cases are basically the same. The summary is as follows:
Analyze AST, find the node of leadingComments - > find the node of the pluggable body - > write the insertion logic
There are many actual processing situations, such as object attributes, iife, function expressions, etc. the processing ideas are the same, but they are repeated here. I will post the full plug-in code at the bottom of the article.
Automatic introduction
The first item is completed, and the second item of the requirement, how to automatically import the package we use, such as log4js used in the above case, then our processed code should automatically add:
import { log } from 'log4js'At this point, we can consider that we need to deal with the following two situations
- log has been imported
- The log variable name is already occupied
For question 1, we need to search whether log4js has been imported and import log in the form of named. For question 2, we need to give log a unique alias and ensure that this alias is also used in subsequent code insertion. Therefore, this requires us to complete the logic of automatic introduction at the beginning of the file.
We have a general idea, but how can we complete the automatic introduction of logic in advance. In doubt, let's look at the structure of AST. You can see that the outermost layer of AST is the File node. It has a comments attribute, which contains all the comments in the current File. With this, we can analyze the functions to be inserted in the File and introduce them in advance. Let's look down. There is a Program inside. We will access it first because it will be called before other types of nodes, so we need to implement automatic introduction of logic at this stage.
Little knowledge: babel provides the path.traverse method, which can be used to synchronously access and process the child nodes under the current node.
As shown in the figure: 
The code is as follows:
const importModule = require('@babel/helper-module-imports');
// ......
{
visitor: {
Program(path, state) {
// Copy a copy of the options and hang it on the state. The original options cannot be operated
state.options = JSON.parse(JSON.stringify(options))
path.traverse({
// First, access the original import node to check whether the log has been imported
ImportDeclaration (curPath) {
const requirePath = curPath.get('source').node.value;
// Traversal options
Object.keys(state.options).forEach(key => {
const option = state.options[key]
// The judgment package is the same
if( option.require === requirePath ) {
const specifiers = curPath.get('specifiers')
specifiers.forEach(specifier => {
// If it is the default type import
if( option.kind === 'default' ) {
// Determine import type
if( specifier.isImportDefaultSpecifier() ) {
// Found an import with an existing default type
if( specifier.node.imported.name === key ) {
// Hang to identifierName for subsequent calls
option.identifierName = specifier.get('local').toString()
}
}
}
// In case of named import
if( option.kind === 'named' ) {
//
if( specifier.isImportSpecifier() ) {
// Found an import with an existing default type
if( specifier.node.imported.name === key ) {
option.identifierName = specifier.get('local').toString()
}
}
}
})
}
})
}
});
// Process packages that are not imported
Object.keys(state.options).forEach(key => {
const option = state.options[key]
// require is required and the identifierName field was not found
if( option.require && !option.identifierName ) {
// default form
if( option.kind === 'default' ) {
// Add default import
// Generate a random variable name, roughly like this_ log2
option.identifierName = importModule.addDefault(path, option.require, {
nameHint: path.scope.generateUid(key)
}).name;
}
// named form
if( option.kind === 'named' ) {
option.identifierName = importModule.addNamed(path, key, option.require, {
nameHint: path.scope.generateUid(key)
}).name
}
}
// If require is not passed, it will be considered as a global method and will not be imported
if( !option.require ) {
option.identifierName = key
}
})
}
}
}In the Program node, we first copied a copy of the received plug-in configuration options and hung it on the state. Previously, it was said that state can be used for data transmission between AST nodes. Then, we first access the import declaration, that is, the import statement under the Program to see whether log4js has been imported. If so, it will be recorded in the identifier name field, After accessing the import statement, we can judge whether it has been imported according to the identifier name field. If not, use the @babel/helper-module-imports Create import and create a unique variable name using the generateUid method provided by babel.
In this way, we also need to adjust the previous code slightly. Instead of directly using the method name extracted from the comment @ inject:xxx, we should use the identifierName. The key part of the code is modified as follows:
if( sourceModuleList.includes(injectType) ) {
// Determine whether there is a function body
if (pathBody.isBlockStatement()) {
// Search for @ code:xxx comments inside the body
// Because the comment cannot be accessed directly, you need to access the leadingComments attribute of each AST node in the body
const codeIndex = pathBody.node.body.findIndex(block => block.leadingComments && block.leadingComments.some(comment => new RegExp(`@code:\s?${injectType}`).test(comment.value) ))
// If not declared, the default insertion position is the first line
if( codeIndex === -1 ) {
// Use identifierName
pathBody.node.body.unshift(api.template.statement(`${state.options[injectType].identifierName}()`)());
}else {
// Use identifierName
pathBody.node.body.splice(codeIndex, 0, api.template.statement(`${state.options[injectType].identifierName}()`)());
}
}else {
// Case without function body
// Use the ` @ Babel / template 'API provided by AST to generate ast with code snippets
// Use identifierName
const ast = api.template.statement(`{${state.options[injectType].identifierName}();return BODY;}`)({BODY: pathBody.node});
// Replace the original body
pathBody.replaceWith(ast);
}
}The final effect is as follows:
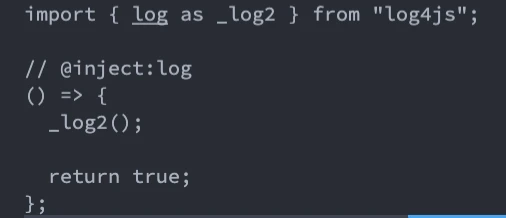
We implement automatic function insertion and automatic introduction of dependent packages.
ending
This article is a summary of my study of the booklet "babel plug-in customs clearance secrets". I began to be like most of the students who wanted to write babel plug-ins but couldn't start, so this article is mainly written according to the ideas I explored when writing plug-ins. I hope it can also provide you with an idea.
The full version supports the insertion of custom code fragments, and the full code has been uploaded to github , also posted to npm . Welcome to star and issue.
It's a favor to star, not an accident, ha ha.

This article is composed of blog one article multi posting platform OpenWrite release!