1, Bayes theorem
1. Introduction
Bayesian theory is named after Thomas Bayes, A theologian in the 18th century. Generally, the probability of event A under the condition of event B (occurrence) is different from that of event B under the condition of event A (occurrence); However, there is A definite relationship between the two, and Bayesian theorem is the statement of this relationship.
2. Advantages and disadvantages
Advantages: it is still effective when there is less data, and can deal with multi category problems
Disadvantages: it is sensitive to the preparation method of input data.
Suppose we have a data set, which is composed of two types of data. The data distribution is shown in the figure below:
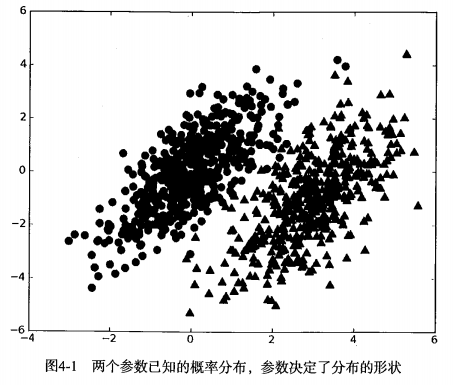
We now use p1(x,y) to represent the probability that the data point (x,y) belongs to category 1 (the category represented by the circle in the figure) and p2(x,y) to represent the probability that the data point (x,y) belongs to category 2 (the category represented by the triangle in the figure). Then for a new data point (x,y), its category can be determined by the following rules:
If P1 (x, y) > P2 (x, y), the category is 1
If P1 (x, y) < P2 (x, y), the category is 2
That is, we will select the category with high probability. This is the core idea of Bayesian decision theory, that is, to choose the decision with the highest probability.
The application of decision tree will not be very successful. Compared with simple probability calculation, KNN calculation is too large. Therefore, for the above problems, the best choice is the probability comparison method.
Next, in order to learn how to calculate p1 and p2 probabilities, it is necessary to discuss conditional probabilities.
2, Probability formula
1. Conditional probability
Conditional probability means event Probability of occurrence of A under the condition of occurrence of event B. condition probability Expressed as: P (A|B), read as "probability of A under the condition of B". If there are only two events A and B, then,
2. Full probability formula
If events A1, A2,... Constitute a Complete event group If there is a positive probability, the following formula holds for any event B:
P(B)=P(BA1)+P(BA2)+...+P(BAn)=P(B|A1)P(A1) + P(B|A2)P(A2) + ... + P(B|An)P(An).
This formula is the full probability formula.
In particular, for any two random events A and B, the following holds: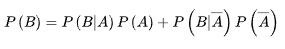
3, Naive Bayes
1. Formula derivation
The formula is obtained through the deformation of conditional probability formula:

We call P(A) A priori probability, that is, we judge the probability of event A before event B.
P(A|B) is called "A posteriori probability", that is, after the occurrence of event B, we reassess the probability of event A.
P(B|A)/P(B) is called "possibility function", which is an adjustment factor to make the estimated probability closer to the real probability.
A priori probability refers to the probability obtained according to previous experience and analysis, such as the full probability formula. It often appears as the "cause" in the problem of "seeking result from cause". A posteriori probability refers to the probability of re correction after obtaining the information of "result", which is the "cause" in the problem of "finding the cause of implementing the result". A posteriori probability is a probability estimation closer to the actual situation after modifying the original a posteriori probability based on new information
Therefore, the conditional probability can be understood as the following formula:
A posteriori probability = a priori probability * adjustment factor a posteriori probability = a priori probability * adjustment factor
This is the meaning of Bayesian inference: we first estimate a "prior probability", and then add the experimental results to see whether the experiment enhances or weakens the "prior probability", so as to obtain a "posterior probability" closer to the fact.
If the "possibility function" P (b|A) / P (b) > 1, it means that the "A priori probability" is enhanced and the possibility of event A becomes greater;
If "possibility function" = 1, it means that event B is not helpful to judge the possibility of event A;
If the "possibility function" < 1, it means that the "A priori probability" is weakened and the possibility of event A becomes smaller.
4, Code implementation (spam filtering)
1. Process description
Training of naive Bayesian classifier model: first, provide two groups of identified mail, one is normal mail, the other is spam, and then "train" the filter with these two groups of mail. Firstly, all emails are parsed, each word is extracted, and then the probability of each word in normal emails and spam is calculated. For example, if the word "cut" appears 200 times in spam with 4000 words (no repetition), then the frequency of the word in spam is 5%; If it appears 1000 times in a normal email with 4000 words (no repetition), the frequency of the word in a normal email is 25%. At this time, the filtering model of the word "cut" has been preliminarily established.
The naive Bayesian classifier model is used for filtering test: read in a new e-mail that is not classified, and then analyze the e-mail. It is found that it contains the word "cut". P(W|S) and P(W|H) are used to represent the probability of this word in spam and normal e-mail respectively. Then, the probability of each word parsed in the email (corresponding training model has been established) belonging to normal email and spam is multiplied respectively. Finally, the probability of the email belonging to normal email and spam is compared, and the email can be classified as the one with higher probability.
2. Construct word vector
We regard the text as a word vector or entry vector, that is, convert the sentence into a vector. Consider all the words that appear in all documents, then decide which words to include in the vocabulary or the vocabulary set, and then you must convert each document into a vector on the vocabulary.
# Create experimental samples
def loadDataSet():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
return postingList,classVec
def createVocabList(dataset):
vocabSet = set([])
for document in dataset:
# Union set
vocabSet = vocabSet | set(document)
return list(vocabSet)
# Convert dataset to word vector
def setOfWords2Vec(vocabList, inputSet):
# Create a list with 0 elements
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print('the word: %s is not in my Vocabulary!' % word)
return returnVec
if __name__ == '__main__':
postingList, classVec = loadDataSet()
myVocabList = createVocabList(postingList)
print('myVocabList:\n', myVocabList)
print(setOfWords2Vec(myVocabList, postingList[0]))
3. Word vector calculation probability
Note w represents a vector (can be understood as an email after vectorization), which is composed of multiple values. In this example, if the number of numerical values is the same as the number of entries in the vocabulary, the Bayesian formula can be expressed as:
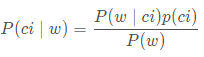
def trainNBO(trainMatrix,trainCategory):
#Number of documents (6)
numTrainDocs = len(trainMatrix)
#Number of words
numWords = len(trainMatrix[0])
##Initialization probability
pAbusive = sum(trainCategory) / float(numTrainDocs)
#If one of the probability values of the array initialized with zeros() is 0, the final result is also 0, so use ones()
# The ndarray object in numpy is used to store multidimensional arrays of elements of the same type.
p0Num = np.ones(numWords)
p1Num = np.ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
#Vector addition
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
# Calculate the proportion of an entry in a category (the total number of all entries in the category)
p1Vect = np.log(p1Num/p1Denom)
p0Vect = np.log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
if __name__ == '__main__':
postingList, classVec = loadDataSet()
myVocabList = createVocabList(postingList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0Vect, p1Vect, pAbusive = trainNBO(trainMat, classVec)
print('p0Vect:\n', p0Vect)
print('p1Vect:\n', p1Vect)
print('Probability that the document is insulting:', pAbusive)
4. Naive Bayesian classification function
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
if __name__ == '__main__':
postingList, classVec = loadDataSet()
myVocabList = createVocabList(postingList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNBO(np.array(trainMat),np.array(classVec))
testEntry = ['love', 'my', 'dalmation']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'It belongs to the insult category')
else:
print(testEntry,'It belongs to the non insulting category')
testEntry = ['stupid', 'love', 'cute']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'It belongs to the insult category')
else:
print(testEntry,'It belongs to the non insulting category') 
5. Cross validation using naive Bayes
def bagOfWords2Vec(vocabList,inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
def textParse(bigString):
#Take any string other than numbers and words as the segmentation flag
listOfTokens = re.split('\\W*',bigString)
#In order to unify the form of all words, all words become lowercase except a single letter, such as capital I
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
def spamTest():
docList = [];classList = [];fullTest = []
#Import and parse 50 files and record the corresponding tag value. The spam is marked as 1
for i in range(1,26):
wordList = textParse(open('C:/Users/cool/Desktop/mach/email/spam/%d.txt'% i,'r').read())
docList.append(wordList)
fullTest.append(wordList)
classList.append(1)
wordList = textParse(open('C:/Users/cool/Desktop/mach/email/ham/%d.txt'% i,'r').read())
docList.append(wordList)
fullTest.append(wordList)
classList.append(0)
#Get a word list of 50 files
vocabList = createVocabList(docList)
trainingSet = list(range(50))
testSet = []
#Randomly select the test set, remove it from the training set, and retain the cross validation
for i in range(10):
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat = [];trainClass = []
#Build training set word vector list and training set label
for docIndex in trainingSet:
trainMat.append(setOfWords2Vec(vocabList,docList[docIndex]))
trainClass.append(classList[docIndex])
#Training algorithm to calculate the probability required for classification
p0V,p1V,pSpam = trainNBO(np.array(trainMat),np.array(trainClass))
#The number of classification errors is initialized to 0
errorCount = 0
#, traverse the test set and verify the error rate of the algorithm
for docIndex in testSet:
wordVector = setOfWords2Vec(vocabList,docList[docIndex])
if classifyNB(np.array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
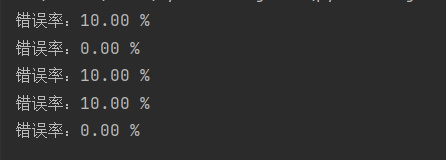
print('Error rate:%.2f%%'%(float(errorCount)/len(testSet)*100))
if __name__ == '__main__':
spamTest()