1, What is a transaction
Transaction refers to a program execution unit that accesses and updates various data in the database. MySQL transactions are mainly used to process data with large amount of operations and high complexity.
(1) . four features (ACID): ★
(1) Atomicity / indivisibility: all operations in a transaction are either completed or not completed, and will not end in an intermediate link. If an error occurs during the execution of a transaction, it will be rolled back to the state before the start of the transaction, as if the transaction had never been executed
(2) Consistency: the integrity of the database is not destroyed before and after the transaction. This means that the written data must fully comply with all preset rules, including the accuracy and serialization of the data, and the subsequent database can spontaneously complete the predetermined work
(3) Isolation: the ability of a database to allow multiple concurrent transactions to read, write and modify their data at the same time. Isolation can prevent data inconsistency caused by cross execution when multiple transactions are executed concurrently. Transaction isolation is divided into different levels, including Read uncommitted, read committed, repeatable read, and Serializable
(4) Durability: after the transaction is completed, the modification of data is permanent and will not be lost even if the system fails.
Transaction control statement:
START TRANSACTION: BEGIN or START TRANSACTION
Commit transaction: COMMT or COMMT WORK
ROLLBACK transaction: ROLLBACK or ROLLBACK WORK
Create transaction marker point: SAVEPOINT identifier
Set transaction isolation level: SET TARNSACTION
Rollback transaction marker point: ROLLBACK TO identifier
Delete transaction marker point: retain savepoint identifier
Steps:
Start transaction → write SQL statement (insert, update, delete, mark point) → commit
Function of marker points: when you have a large number of sql operations in a thing, if the efficiency of rollback (returning to the original state by default) is very low, you can consider returning to a marker point.
(2) . transaction control statement:
mysql database automatically submits transactions by default, which is related to the variable autocommit. The default is 1, that is, it is turned on (ON). You can view it through the black window (cmd window). The effect is as follows:
Command: show variables like 'autocommit';
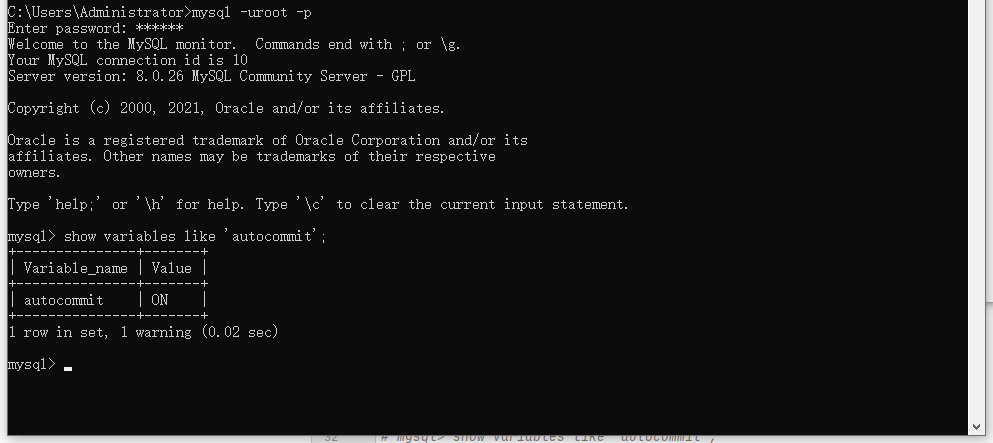
Note: whether autocommit is 1 or 0; After the start transaction, the commit data will take effect only when it is rolled back.
When autocommit is 0; No matter whether there is a STARTTRANSACTION or not, the commit data will take effect only when it is rolled back.
create database if not exists db_0918;
use db_0918;
create table if not exists new_date(
id int,
name varchar(15),
age int
);
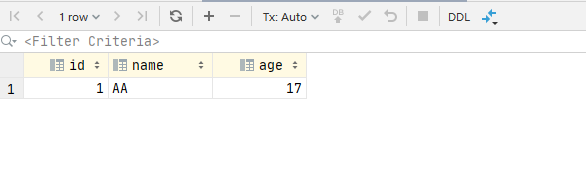
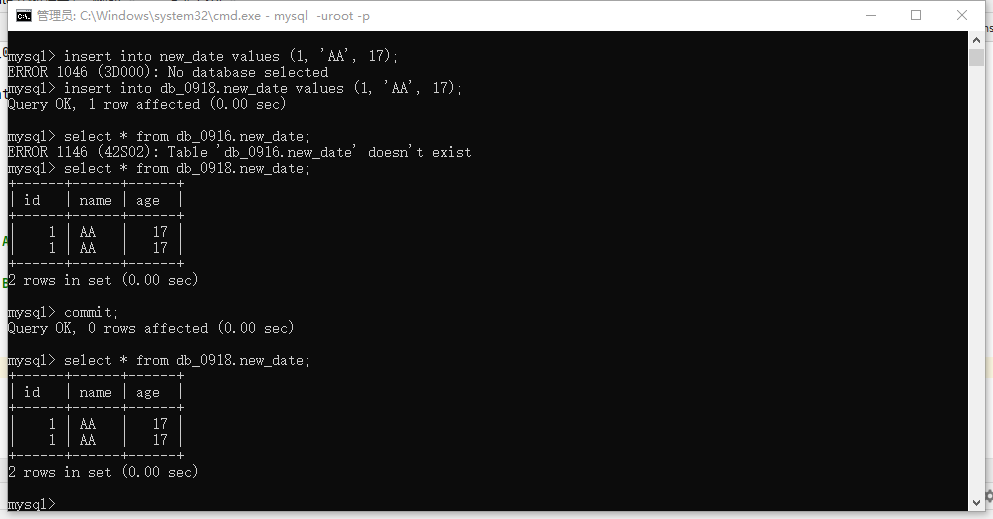
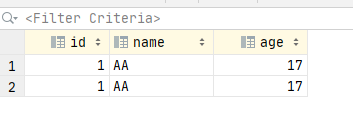
-- Create a data table first-- hypothesis autocommit When 0, insert data begin; insert into new_date values (1, 'AA', 17); insert into new_date values (1, 'BB', 16); -- If the above statement is executed, the database will not submit data after inserting data, but it has been executed, as shown in Figure 1 and 2 below. commit; -- After this statement is run, the data will be submitted, as shown in Figure 3 and 4 below.
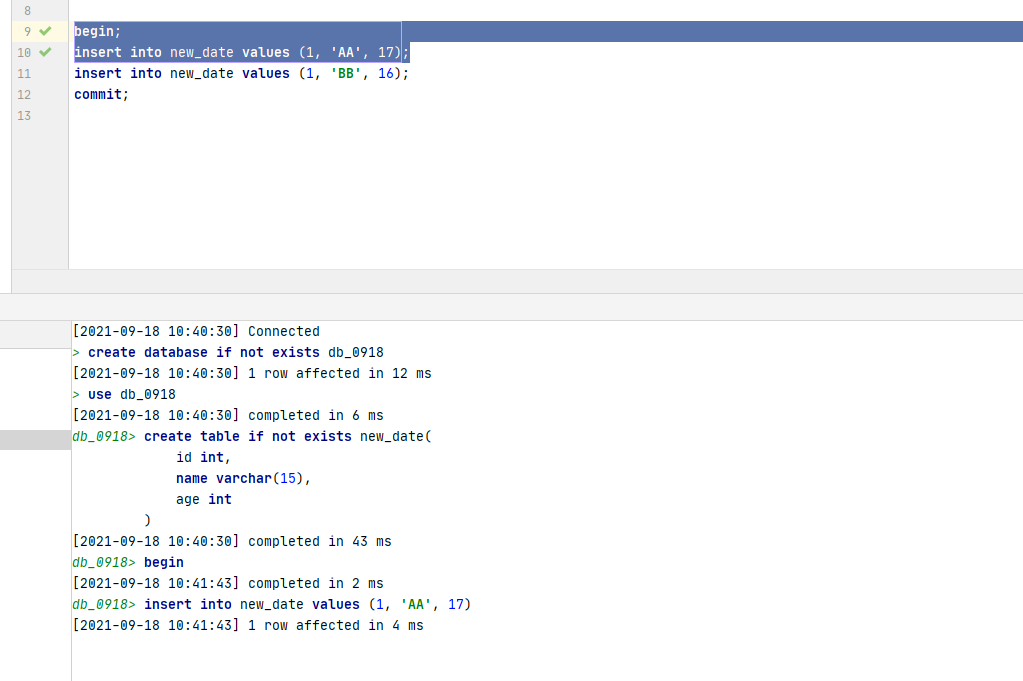

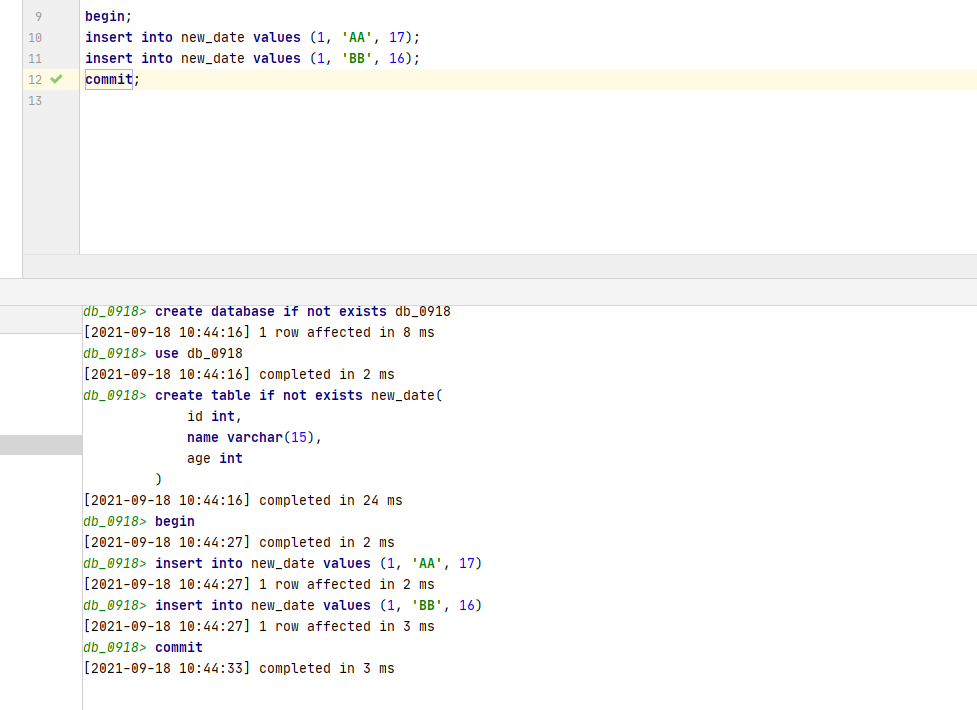
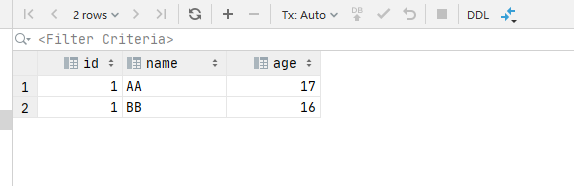
begin; insert into new_date values (1, 'AA', 17); rollback; # Rollback will cancel the insertion of the above data insert into new_date values (1, 'BB', 16); commit; # The running result only inserts a BB data # After meeting rpllback, the effect of commit is the same begin; insert into new_date values (1, 'AA', 17); rollback; insert into new_date values (1, 'BB', 16); # The insertion result is the same
Rollback effect:
begin; insert into new_date values (1, 'AA', 17); savepoint p1; # Insert a restore point insert into new_date values (1, 'BB', 16); rollback to p1; # Rollback to restore point commit; # There is only one data under this submission.

How to set auto submit:
Start mysql in the black window (cmd) and enter: SET AUTOCOMMIT=0;
Note: after setting, only the current connection is allowed. When the database is disconnected and enters again, this value will be restored to the default value, i.e. 1.

Note: if automatic submission is turned off in the black window, even if the data is inserted, the data does not exist in other people's database. The data is temporarily submitted in their own database. The data will be updated to the database only after you enter commit. This is the isolation mechanism of the database, that is, enter the inserted data in the black window, You can see the data in the black window, but the data refresh does not exist in the database unless you run commit, as follows:

Scenario of rollback application:
For example, bank transfer, when a user transfers money to another user, it will be deducted from the transfer user and added to the receiving user's card. However, when either party fails, it will be rolled back, that is, the transaction fails.
Dirty read:
Dirty reading, which occurs when reading uncommitted isolation levels. When a transaction is accessing data and making changes to the data, but the changes have not been committed to the database, another transaction also accesses the data and uses the data.
| time | transfer | withdraw money |
| 1 | Start transaction | |
| 2 | Start transaction | |
| 3 | The query balance is 2000 | |
| 4 | Withdraw 1000, the balance has been changed to 1000 (not submitted) | |
| 5 | The query balance is 1000 (this is dirty data) | |
| 6 | There is an error in withdrawal, the transaction is rolled back, and the balance returns to 2000 | |
| 7 | Transferred to 2000, the balance is actually 3000 (dirty reading 1000 + 2000) | |
| 8 | Submit | |
| Normally, this account should be 4000 |
Non repeatable reads:
Non repeatable reading, which occurs when reading the committed isolation level. The same data is read many times before and after, and the data content is inconsistent.
Unreal reading:
Unreal reading, a phenomenon that occurs at the repeatable read isolation level. Read multiple times before and after to read the data inserted by other transactions.
| time | Transaction A | Transaction B |
| 1 | start | |
| 2 | For the first query, the total amount of data is 100 | |
| 3 | Start transaction | |
| 4 | Other operations | |
| 5 | 100 new data | |
| 6 | Commit transaction | |
| 7 | For the second query, the total amount of data is 200 | |
| Normally, the total amount of data read before and after transaction A should be the same |
2, What is a view
A view is a virtual table exported from one or more base tables (or views). A view cannot have the same name as the table name. Data is mostly used as queries, and data is generally not modified through views.
characteristic:
1. Views can simplify user operations
2. Views can increase security (Views generally use query statements)
3. Views provide a certain degree of logical independence for refactoring the database
View operation:
Create view: create view name as SQL statement (mostly select);
Modify view: alter view name as SQL statement;
Delete view: drop view name;
Code section: create a table first
create database if not exists db_0918;
use db_0918;
create table if not exists People(
id int not null auto_increment primary key,
age int,
sid char(20),
sex bit,
name char(20),
isDelete bit default 0
) ;Insert partial data:
insert into People(age,sex,name) values (18, 1, 'Cleo'); insert into People(age,sid,sex,name) values (18, '', 1, 'Abra'); insert into People(age,sex,name) values (36, 1, 'Louis'),(20, 1, 'Burt'),(30, 1, 'Mason'),(30, 1, 'lilia'); insert into People(age,sex,name) values (34, 1, 'Jane');
Create view:
create view VPeople as select * from People where id>3; -- Filter out id Information greater than 3 and create a view VPeople select * from VPeople where age > 30; -- Exhibition id>3 Information older than 30 select * from (select * from People where id>3) as stu where age > 30; -- Equivalent to the above query, so the view query is simpler in this case.
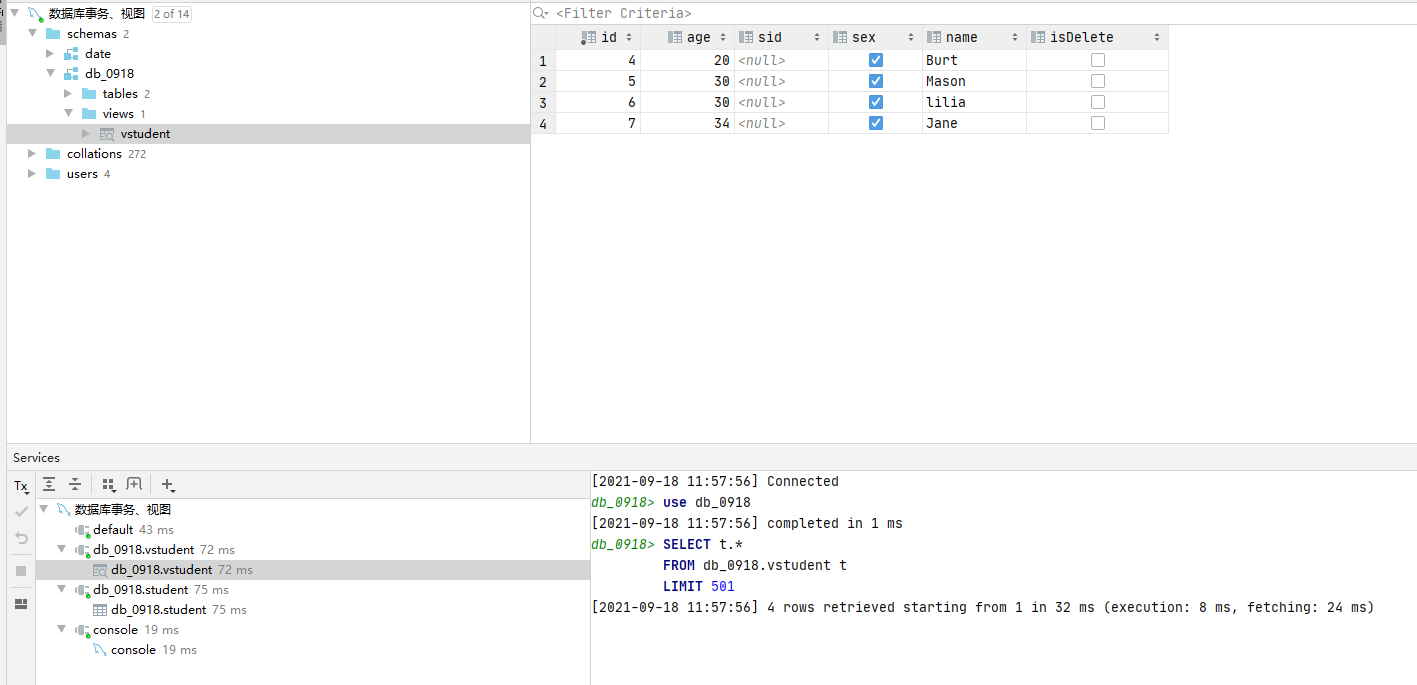

Modify view:
alter view VPeople as
select * from People where People.name like 'A%'; -- Query to A First name
select * from VPeople; -- Presentation view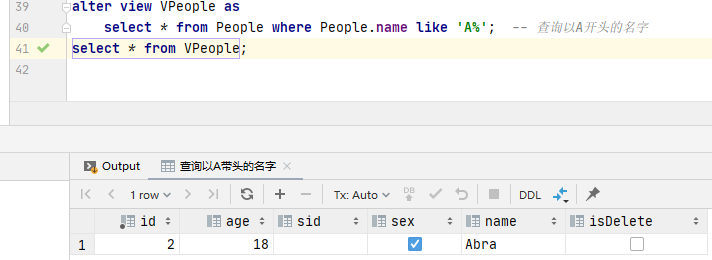 Delete view:
Delete view:
drop view VPeople; -- Delete view
Views are mostly used for statements with high query frequency or scenes with complex logic. You can consider establishing views.
For example: website home page data; Filter at the top of the site.
Storage process:
Stored procedure (StoredProcedure) is a large set of database systems in which a set of SQL statements for specific functions is stored in the database. After the first compilation, the call does not need to be compiled again. The user executes it by specifying the name of the stored procedure and giving the parameter (if the stored procedure has parameters). Stored procedure is an important object in database.
Syntax (similar to SQL writer):
create procedure stored procedure name ()
BEGIN
sql statement set
END
call stored procedure name (); -- Calling process
-- Create a file named dba Library files, in dba Create a file named tb1 Table with id,name These two fields. Create a file named ad1 Stored procedures, ad1 The function of a stored procedure is to insert three records into tb1 In the table.
create database if not exists dba;
use dba;
create table if not exists tb1(
id int,
name varchar(255)
);
delimiter $$ -- Modify the Terminator (this terminator can be any, usually two $End), or you'll think;The statement is a whole to report an error
create procedure ad1() -- Define storage process
begin
insert into tb1(id, name) values (1, 'Joke');
end;$$
delimiter ; -- When you're finished, reply this terminator as;
call ad1() -- Call statementExtension, using the while loop to insert three data:
create database if not exists dba; -- Create Library
use dba; -- Use library
create table if not exists tb1( -- Create table
id int,
name varchar(255)
);
delimiter $$ -- Defining symbols
create procedure ad1() -- Define storage
begin
declare i int default 1; -- Declare a variable i,Integer type. The default value is 1
while (i < 3) do
insert into tb1(id, name) VALUES (i, 'Andy');
set i = i + 1; -- Every run i value+1
end while;
end; $$
delimiter ; -- Set back to end symbol
call ad1(); -- call
3, Trigger
4, Functions