Relatively speaking, the writing is fairly complete. Basically, that's all you can use in your work. A good brain is better than a bad pen. Stored procedures, stored functions, engines, transactions, scheduled tasks, triggers, variables and so on are included. You can collect those you are interested in!
1. Connect to mysql
mysql is divided into client and server. The client includes Navcat, sqlyog, etc. if you use the client, you can't use this command. However, if the computer only installs the server and wants to view the database, you need to use it. Open the computer cmd command window and execute it. If it is linux, you can execute it directly.
The customer service side is nothing more than helping us encapsulate the underlying commands of mysql into visual software. That's all. The underlying logic remains unchanged.
mysql -h host name(ip) -u user name -P port -p password
Example:
mysql -h127.0.0.1 -uroot -P3306 -proot
2. Mysql statement classification
SQL statement: structured query statement, which uses SQL to "communicate" with the database to complete corresponding database operations.
DDL (Data Definition Languages) statement: that is, database definition statement, which is used to create tables, indexes, views, stored procedures, triggers, etc. in the database. The commonly used statement keywords are: CREATE,ALTER,DROP,TRUNCATE,COMMENT,RENAME. Structure of addition, deletion and modification table
DML (Data Manipulation Language) statements: data manipulation statements used to query, add, update, delete, etc. common statement keywords include: SELECT,INSERT,UPDATE,DELETE,MERGE,CALL,EXPLAIN PLAN,LOCK TABLE, including general addition, deletion, modification and query. Adding, deleting and modifying table data
DCL (Data Control Language) statement: that is, a data control statement used to authorize / revoke the permissions of the database and its fields (DCL is short name of Data Control Language which includes commands such as grant and most concerned with rights, permissions and other controls of the database system). Common statement keywords are grant and revoke.
TCL (Transaction Control Language) statement: transaction control statement, used to control transactions. Common statement keywords include: COMMIT,ROLLBACK,SAVEPOINT,SET TRANSACTION.
3. Database command operation
3.1 display database
mysql> SHOW DATABASES;
3.2. Create database
CREATE DATABASE Database name CHARSET='Coding format'
mysql> CREATE DATABASE testa CHARSET = 'utf8';
3.3. Using database
Use current database:
use Database name;
3.4. View the current database
SELECT DATABASE();
3.5. Delete database
DROP DATABASE Database name;
4. Data type
4.1 value type
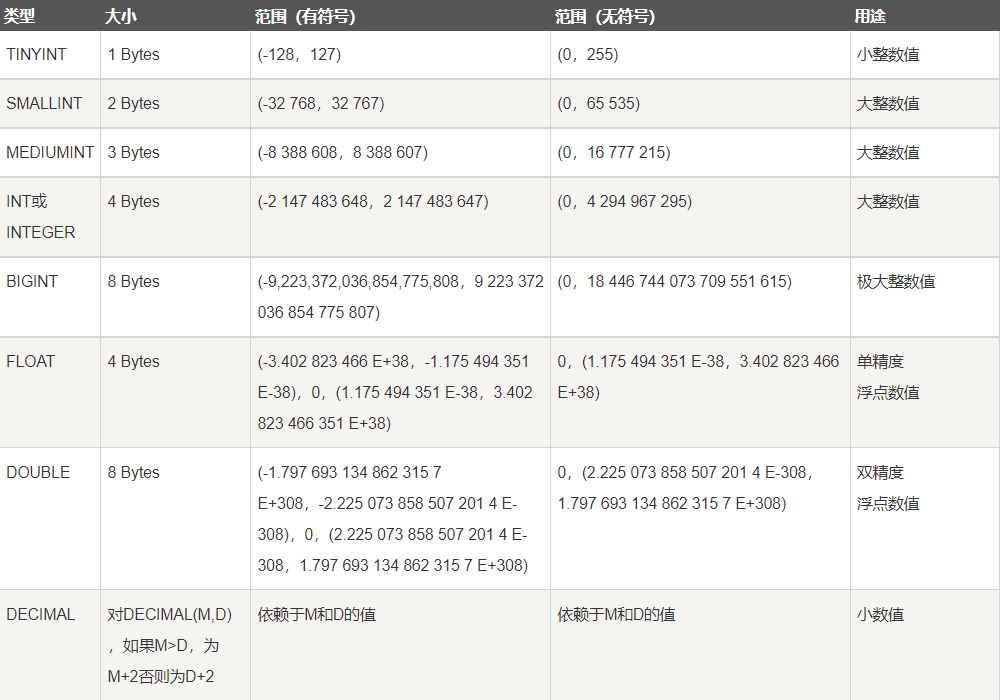
4.2 date and time type
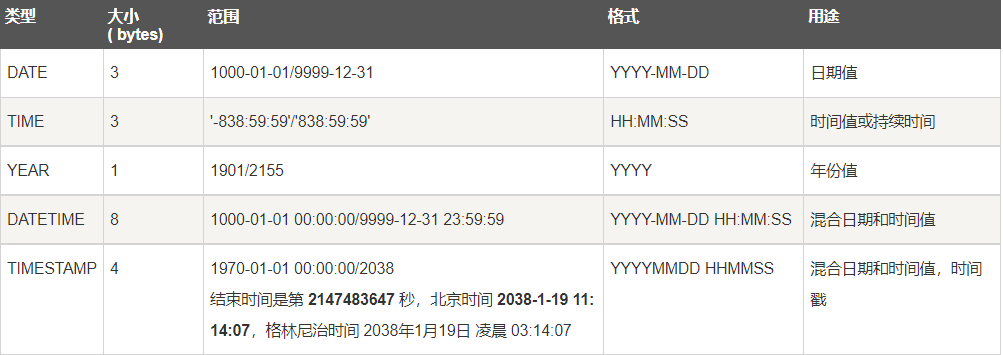
4.3. String type
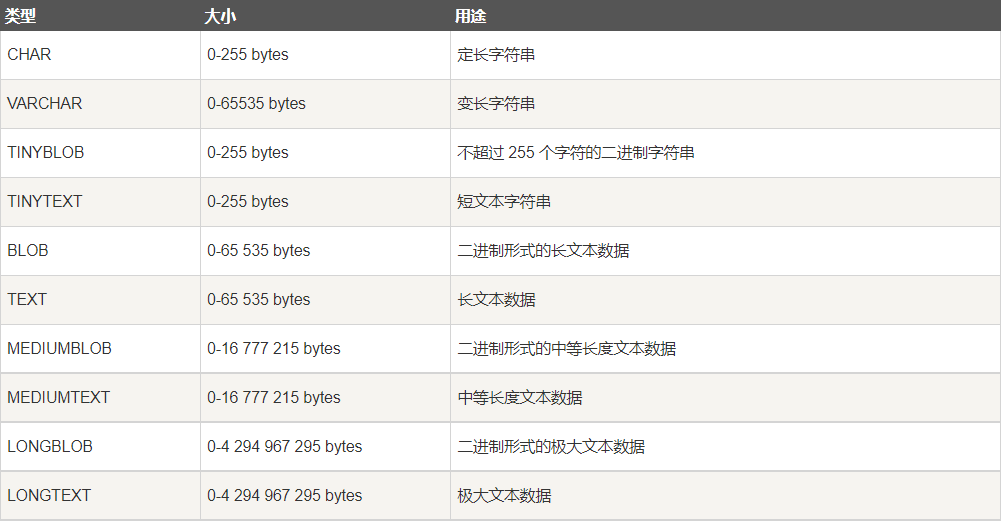
be careful:
-
The length of char type is fixed, and the length of varchar is variable.
This means that the stored string 'abc' uses char(10), indicating that the stored characters will occupy 10 bytes (including 7 null characters)
If varchar2(10) is used, it means that only 3 bytes are occupied. 10 is the maximum value. When the stored characters are less than 10, they are stored according to the actual length. -
varchar2 saves more space than char, but it is slightly less efficient than char. To achieve efficiency, we must sacrifice a little space, which is the "space for time" in design
-
BLOB is a large binary object that can hold a variable amount of data. There are four types of blobs: TINYBLOB, BLOB, mediablob and LONGBLOB. The difference is that they can accommodate different storage ranges.
-
There are four TEXT types: TINYTEXT, TEXT, mediamtext and LONGTEXT. The corresponding four BLOB types have different maximum lengths that can be stored, which can be selected according to the actual situation.
5. Table operation
5.1. Create table
if not exists is optional when creating a table:
Existence means that if the table has been created, no error will be reported, but the created table will not be overwritten. if not exists to create a table, it means that if the table already exists, run directly and report an error.
For online distribution, it is recommended to bring it, because there are usually many sql for distribution. If the statement creating the table is followed by some sql statements, but the table already exists, the sql will be terminated directly. The presence of the attached call table does not affect the normal execution of subsequent sql.
CREATE TABLE IF NOT EXISTS `Table name` ( `Field name` Column type [attribute] [notes] `Field name` Column type [attribute] [notes], Index type (`Field name`) ) [Table type] [Character set settings]
Example:
AUTO_INCREMENT: id self increment
NOT NULL: cannot be null when inserting
PRIMARY KEY: PRIMARY KEY
CREATE TABLE IF NOT EXISTS `runoob_tbl`( `runoob_id` INT UNSIGNED AUTO_INCREMENT COMMENT 'notes', `runoob_title` VARCHAR(100) NOT NULL COMMENT 'notes', `runoob_author` VARCHAR(40) NOT NULL COMMENT 'notes', `submission_date` DATE, PRIMARY KEY ( `runoob_id` ), UNIQUE (`runoob_title`) )ENGINE=InnoDB DEFAULT CHARSET=utf8;
5.2. Create a temporary table
Mysql temporary tables are very useful when we need to save some temporary data. Temporary tables are only visible in the current connection. When the connection is closed, Mysql will automatically delete the table and free up all space.
Temporary tables are added in MySQL version 3.23. If your MySQL version is lower than 3.23, you cannot use MySQL temporary tables.
mysql> CREATE TEMPORARY TABLE SalesSummary (
-> product_name VARCHAR(50) NOT NULL
-> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00
-> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00
-> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO SalesSummary
-> (product_name, total_sales, avg_unit_price, total_units_sold)
-> VALUES
-> ('cucumber', 100.25, 90, 2);
mysql> SELECT * FROM SalesSummary;
+--------------+-------------+----------------+------------------+
| product_name | total_sales | avg_unit_price | total_units_sold |
+--------------+-------------+----------------+------------------+
| cucumber | 100.25 | 90.00 | 2 |
+--------------+-------------+----------------+------------------+
1 row in set (0.00 sec)
Delete temporary table
DROP TABLE SalesSummary;
5.3 update table
5.3.1 adding columns
ALTER TABLE Table name ADD Field name data type(length) COMMENT "notes";
Example: in runoob_tbl creates an attribute whose field is bb not empty.
ALTER TABLE runoob_tbl ADD bb INT(11) NOT NULL COMMENT "test";
5.3.2. Modify column
ALTER TABLE Table name MODIFY COLUMN Field name data type(length) COMMENT "notes";
5.3.3 delete column
ALTER TABLE Table name DROP COLUMN Field name;
5.4. View all tables
show tables;
5.5. View table structure
DESC Table name;
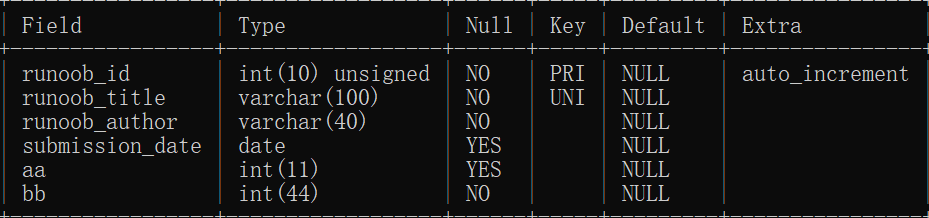
5.6. View table details
Storage engine, table creation time, etc.
SHOW TABLE STATUS LIKE 'Table name' \G
5.7 rename table
Both are OK.
ALTER TABLE Table name RENAME TO New table name; RENAME TABLE Table name TO New table name;
5.8 delete table
DROP TABLE table_name ;
5.9 copy table
Step 1:
Gets the complete structure of the data table to be copied.
mysql> SHOW CREATE TABLE runoob_tbl \G;
*************************** 1. row ***************************
Table: runoob_tbl
Create Table: CREATE TABLE `runoob_tbl` (
`runoob_id` int(11) NOT NULL auto_increment,
`runoob_title` varchar(100) NOT NULL default '',
`runoob_author` varchar(40) NOT NULL default '',
`submission_date` date default NULL,
PRIMARY KEY (`runoob_id`),
UNIQUE KEY `AUTHOR_INDEX` (`runoob_author`)
) ENGINE=InnoDB
1 row in set (0.00 sec)
ERROR:
No query specified
Step 2:
Modify the data table name of the SQL statement and execute the SQL statement.
mysql> CREATE TABLE `clone_tbl` ( -> `runoob_id` int(11) NOT NULL auto_increment, -> `runoob_title` varchar(100) NOT NULL default '', -> `runoob_author` varchar(40) NOT NULL default '', -> `submission_date` date default NULL, -> PRIMARY KEY (`runoob_id`), -> UNIQUE KEY `AUTHOR_INDEX` (`runoob_author`) -> ) ENGINE=InnoDB; Query OK, 0 rows affected (1.80 sec)
Step 3:
After the second step, you will create a new clone table clone in the database_ tbl. If you want to copy the data of the data table, you can use
INSERT INTO... SELECT Statement.
mysql> INSERT INTO clone_tbl (runoob_id,
-> runoob_title,
-> runoob_author,
-> submission_date)
-> SELECT runoob_id,runoob_title,
-> runoob_author,submission_date
-> FROM runoob_tbl;
Query OK, 3 rows affected (0.07 sec)
Records: 3 Duplicates: 0 Warnings: 0
6. Data operation
6.1. Query data
6.1.1. Query multiple columns
AS is not case sensitive and can be omitted when aliasing.
SELECT Listing AS alias , Listing AS alias FROM Table name;
6.1.2. Retrieve unique value
Use the DISTINCT keyword to query the unique value of the field pwd.
SELECT DISTINCT pwd FROM user;
6.1.3 paging query
There are two ways to write:
SELECT * FROM table LIMIT offset, rows; SELECT * FROM table LIMIT rows OFFSET offset;
offset: the index of the row at the beginning of the row. 0 means to display from line 1 (including line 1), and so on.
Rows: the number of rows displayed.
SELECT * FROM table LIMIT 5; -- Retrieve the first 5 data --amount to SELECT * from table LIMIT 0,5; -- Retrieve 5 pieces of data from row 0 --amount to SELECT * FROM table LIMIT 5 OFFSET 0; -- Start to retrieve 5 pieces of data from row 0, and pay attention to the LIMIT 5 refers to quantity
One of the most frequently asked questions during the interview:
How to get 200 - 300 data from mysql?
First of all, we have to find out whether it includes 200 articles and 300 articles
include: select * from table limit 199,101 Not included: select * from table limit 200,99
6.1.4 sorting
ASC ascending, DESC descending
ORDER defaults to ascending sort. Specifies the DESC keyword to sort in descending ORDER (from Z to A).
When specifying an ORDER BY clause, you should ensure that it is the last clause in the SELECT statement. You can have multiple sorting fields at the same time. Just separate them with commas.
SELECT * FROM TABLE_NAME ORDER BY Listing, Listing DESC;
6.1.5 notes
-- Single-Line Comments # Single-Line Comments /* multiline comment */
6.2. Insert data
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
If the data is character type, you must use single quotation marks or double quotation marks, such as "value".
6.2.1. Insert complete line
Inserting a complete row can omit the attribute name behind the table, but the value must also be consistent with the attribute order queried by desc, otherwise the type is inconsistent or the value will be inserted incorrectly.
mysql> desc user; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | uid | int(11) | NO | PRI | NULL | auto_increment | | uname | varchar(30) | NO | UNI | NULL | | | pwd | varchar(30) | NO | | NULL | | | age | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 4 rows in set (0.01 sec) mysql> insert into user values (10,"123","123",22); Query OK, 1 row affected (0.01 sec)
6.2.2 insert some lines
insert into user(uname,pwd) value ("3323","123");
6.2.3 batch insert data
insert into user(uname,pwd) value ("3323","123"),
("4444","555");
6.2.4 copy from one table to another
CREATE TABLE user_test AS SELECT * FROM user;
- Any SELECT option and clause can be used, including WHERE and GROUP BY.
- Joins can be used to insert data from multiple tables.
- No matter how many tables you retrieve data from, data can only be inserted into one table.
Main purpose: it is a good tool for table replication before testing new SQL statements. Copy first. You can test the SQL code on the copied data without affecting the actual data.
6.3. Update data
You can change the values of multiple columns at once, or you can change the values of a single column. For multiple columns, use commas to separate them.
UPDATE Table name SET Listing=New value, Listing=New value;
You can update one or more fields at the same time.
You can specify any condition in the WHERE clause.
You can update data simultaneously in a separate table.
The WHERE clause is very useful when you need to update the data of the specified row in the data table.
The following example updates the runoob in the data table_ Runoob with ID 3_ Title Field Value:
UPDATE runoob_tbl SET runoob_title='study C++' WHERE runoob_id=3;
6.4. Delete data
DELETE FROM Table name WHERE name = 'Zhang San';
If the WHERE clause is not specified, all records in the MySQL table will be deleted.
You can specify any condition in the WHERE clause
You can delete records in a single table at once.
The WHERE clause is very useful when you want to delete the specified records in the data table.
If you want to delete all rows from the table, it is recommended to use the TRUNCATE TABLE statement, which completes the same work and is faster (because changes in data are not recorded).
Note: TRUNCATE belongs to data definition language (DDL), and cannot be rolled back after the TRUNCATE command is executed. It is best to back up the data in the current table before using the TRUNCATE command.
TRUNCATE TABLE Table name;
7. where conditional filtering
7.1 WHERE clause operator
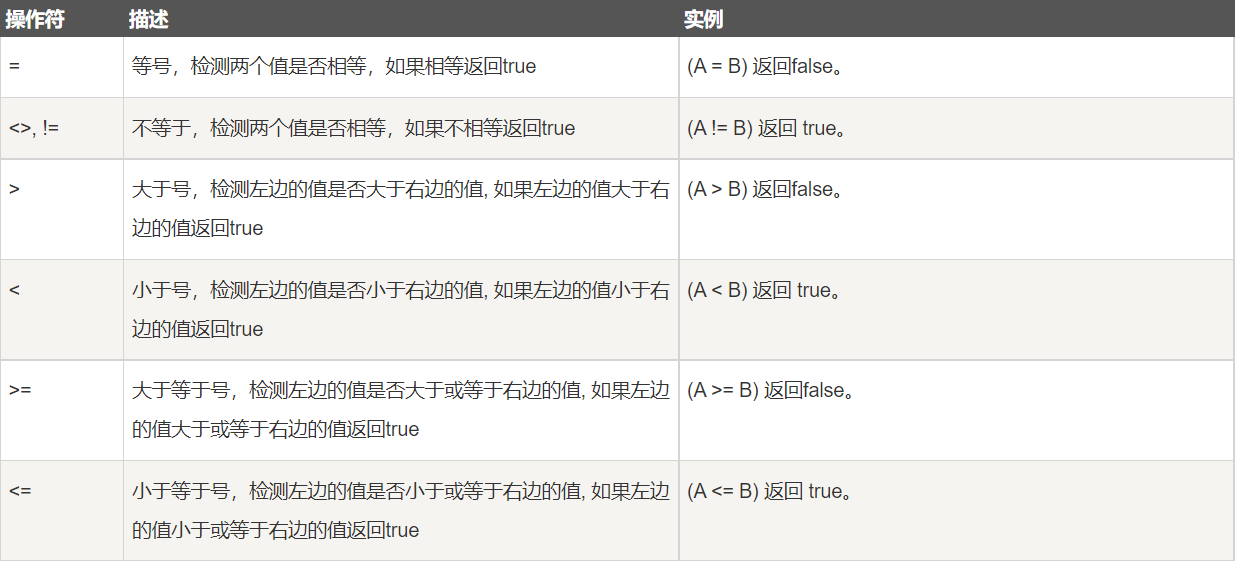
7.2 range value inspection
Use the WHERE keyword and BETWEEN AND to check the range value
Query the data of > = 5 and < = 10 in the field age.
SELECT age FROM user WHERE age BETWEEN 5 AND 10;
7.3. LIKE fuzzy query
%Indicates that any character occurs any number of times. For example, to find all name s that start with a path.
SELECT name, age FROM user WHERE name LIKE 'road%';
Wildcard_ The same purpose as% is to match any character, but it only matches a single character, not multiple characters.
SELECT name, age FROM user WHERE name LIKE 'Black_universal';
7.4. NULL value processing
- IS NULL: this operator returns true when the value of the column IS NULL.
- IS NOT NULL: the operator returns true when the value of the column IS NOT NULL.
The conditional comparison operation of null is special. You cannot use = null or= null finds a null value in a column= null and= The null operator does not work.
Example: query data with empty name field
SELECT * FROM user WHERE name IS NULL;
7.5 logical operators
Logical operators are used to judge whether an expression is true or false. If the expression is true, the result returns 1. If the expression is false, the result returns 0.
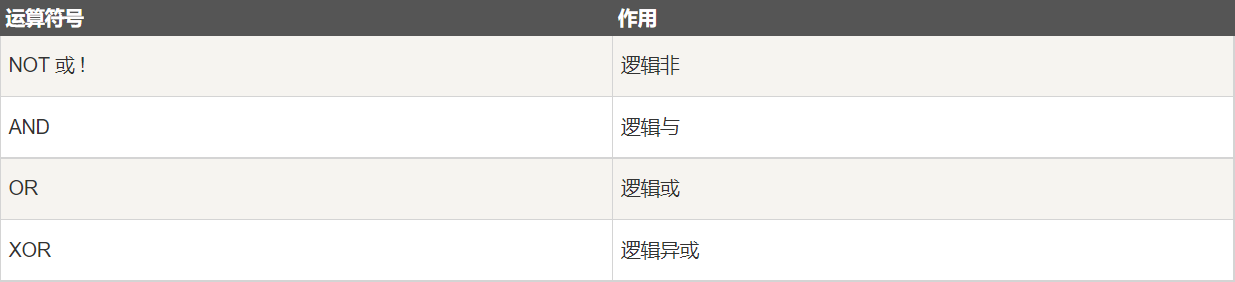
The priority of AND is higher than OR. The priority is high OR low (), AND, OR. Pay attention to the influence of each priority in the process of use.
mysql> SELECT name, age
-> FROM user
-> WHERE(name = 'Sauron' OR name = 'Monkey D Luffy')
-> AND age >= 18;
7.6. IN operator
IN stands for inclusion, NOT IN stands for exclusion.
mysql> SELECT name, age
-> FROM user
-> WHERE name IN ('Sauron', 'Monkey D Luffy')
mysql> SELECT name
-> FROM user
-> WHERE name NOT IN ('Sauron', 'Monkey D Luffy')
7.7. EXISTS operator
He can perform the same function as in.
#The B query involves id and index, so the B table is efficient. Large tables can be used -- > small outside and large inside select * from A where exists (select * from B where A.id=B.id); #The query of A involves id and index, so the efficiency of table A is high. Large tables can be used -- > large outside and small inside select * from A where A.id in (select id from B);
1. Exists is to loop the external table and query the internal table (sub query) each time. Because the index used for the query of the internal table (the internal table is efficient, so it can be used as a large table), the appearance needs to be traversed, which is inevitable (try to use a small table). Therefore, the use of exists in the large internal table can speed up the efficiency;
2. In is a hash connection between the external table and the internal table. First query the internal table, and then match the results of the internal table with the external table. The external table uses an index (the external table has high efficiency, and large tables can be used). Most of the internal tables need to be queried, which is inevitable. Therefore, the use of in with large appearance can speed up the efficiency.
3. If not in is used, the internal and external tables will be scanned completely without index and low efficiency. You can consider using not exists or A left join B on A.id=B.id where B.id is null for optimization.
8. Association
You can use Mysql JOIN in SELECT, UPDATE and DELETE statements to JOIN multi table queries.
JOIN can be roughly divided into the following four categories according to its functions:
INNER JOIN (INNER JOIN or equivalent join): obtain the records of the field matching relationship in two tables.
LEFT JOIN: obtain all records in the left table, even if there is no corresponding matching record in the right table.
RIGHT JOIN: Contrary to LEFT JOIN, it is used to obtain all records in the right table, even if there is no corresponding matching record in the left table
CROSS JOIN cross join (finally get the Cartesian product).
Test data:
CREATE TABLE t1 (
id INT PRIMARY KEY,
pattern VARCHAR(50) NOT NULL
);
CREATE TABLE t2 (
id VARCHAR(50) PRIMARY KEY,
pattern VARCHAR(50) NOT NULL
);
INSERT INTO t1(id, pattern)
VALUES(1,'Divot'),
(2,'Brick'),
(3,'Grid');
INSERT INTO t2(id, pattern)
VALUES('A','Brick'),
('B','Grid'),
('C','Diamond');
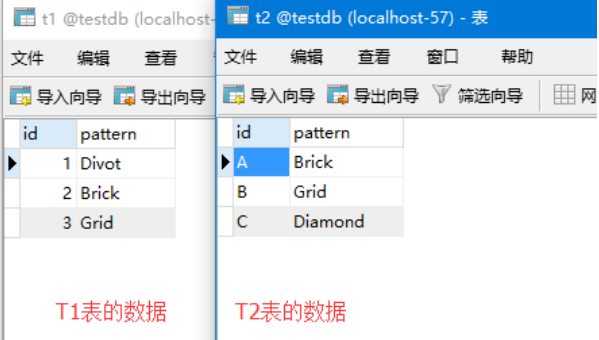
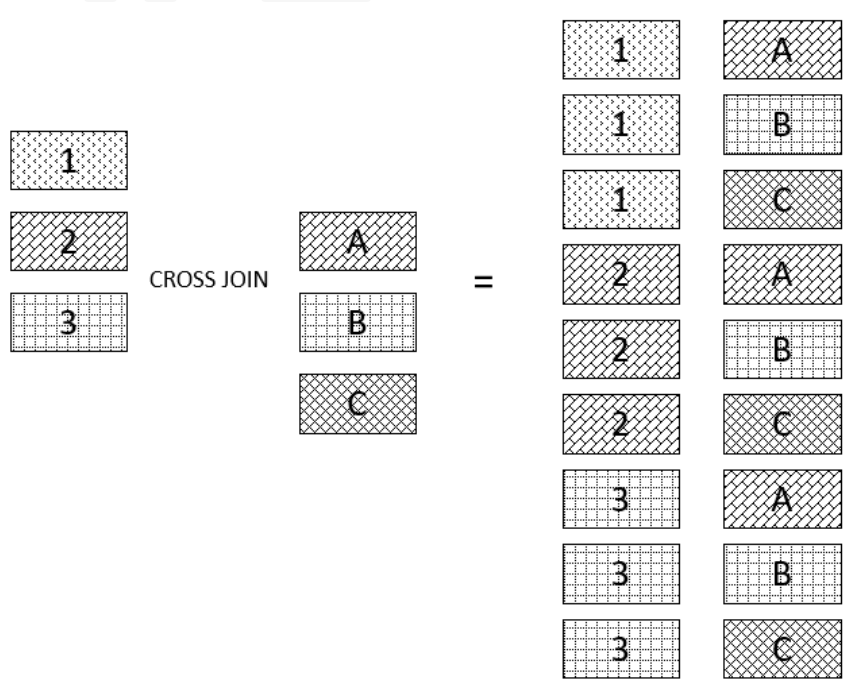
8.1 cross join
SELECT
t1.id, t2.id
FROM
t1
CROSS JOIN t2;
The results of these two writing methods are the same.
SELECT t1.id, t2.id FROM t1, t2
Operation results:
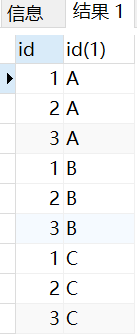
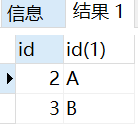
8.2 inner join
Sometimes we can see that a single join is used, and its default is actually equivalent to an INNER JOIN.
SELECT
t1.id, t2.id
FROM
t1
INNER JOIN
t2 ON t1.pattern = t2.pattern;
The results of these two writing methods are the same.
SELECT t1.id, t2.id FROM t1, t2 WHERE t1.pattern = t2.pattern;
Operation results:
8.3 left join
SELECT
t1.id, t2.id
FROM
t1
LEFT JOIN
t2 ON t1.pattern = t2.pattern;
Operation results:

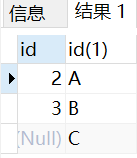
8.4 right join
SELECT
t1.id, t2.id
FROM
t1
right JOIN
t2 ON t1.pattern = t2.pattern
Operation results:
9. UNION operator
Union and union all are to merge two or more SQL query results through rows;
The merged union results will be de duplicated.
The merged results of union all will not be de duplicated.
Syntax:
select column,......from table1 union [all] select column,...... from table2
Test data:
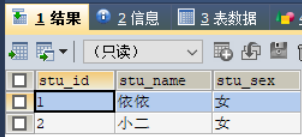
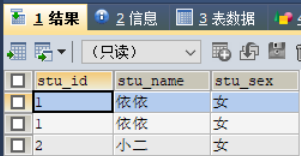
-- Create student table CREATE TABLE `tab_student` ( `stu_id` VARCHAR (16) NOT NULL COMMENT 'Student number', `stu_name` VARCHAR (20) NOT NULL COMMENT 'Student name', `stu_sex` VARCHAR(1) NOT NULL COMMENT 'Student gender', PRIMARY KEY (`stu_id`) ) COMMENT = 'Student list' ENGINE = INNODB; -- Insert data to practice INSERT INTO tab_student VALUES (1,'Yiyi','female'), (2,'waiter','female'), (3,'Zhang San','male'), (4,'Li Si','male');
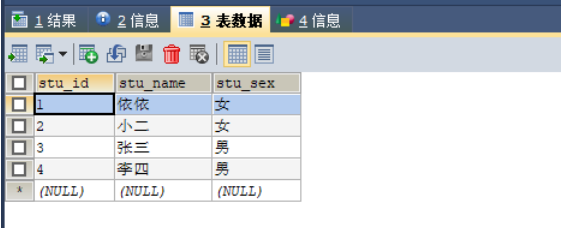
9.1,union
SELECT * FROM tab_student WHERE stu_id = 1 UNION SELECT * FROM tab_student WHERE stu_sex = 'female';
9.2,union all
SELECT * FROM tab_student WHERE stu_id = 1 UNION ALL SELECT * FROM tab_student WHERE stu_sex = 'female';
10. Data grouping
If the grouping column contains a row with a NULL value, NULL is returned as a grouping. If there are multiple rows of NULL values in a column, they are grouped.
Except for the aggregate calculation statement, each column in the SELECT statement must be given in the GROUP BY clause.
Test data:
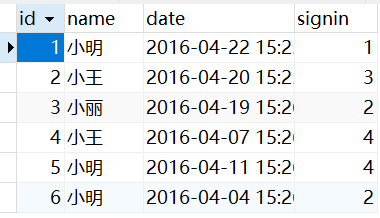
CREATE TABLE `employee_tbl` ( `id` int(11) NOT NULL, `name` char(10) NOT NULL DEFAULT '', `date` datetime NOT NULL, `signin` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'Login times', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `employee_tbl` VALUES ( '1', 'Xiao Ming', '2016-04-22 15:25:33', '1' ), ( '2', 'Xiao Wang', '2016-04-20 15:25:47', '3' ), ( '3', 'Xiao Li', '2016-04-19 15:26:02', '2' ), ( '4', 'Xiao Wang', '2016-04-07 15:26:14', '4' ), ( '5', 'Xiao Ming', '2016-04-11 15:26:40', '4' ), ( '6', 'Xiao Ming', '2016-04-04 15:26:54', '2' );
10.1,group by
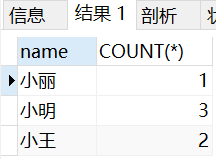
We can use this table as an order table. One piece of data is one order. Now I want to count how many orders each person has placed. At this time, we need to query in groups.
SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
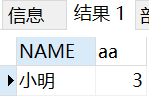
I'm not satisfied with that data. I also want to find the people who place the most orders.
SELECT * FROM ( SELECT NAME, COUNT(*) aa FROM employee_tbl GROUP BY NAME ) T1 ORDER BY T1.aa DESC LIMIT 1
Query results:
10.2,having
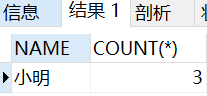
Then I also want to count the people who place more than two orders.
SELECT NAME, COUNT(*) FROM employee_tbl GROUP BY NAME HAVING count(*) > 2;
Execution results:
Main differences between WHERE and HAVING:
WHERE filters before data grouping and HAVING filters after data grouping.
In real development, the scene of deleting duplicate data often appears. You can query the duplicate data through this sql.
SELECT Column 1, count( 1) AS count FROM Table name GROUP BY Column name 1 HAVING count >1
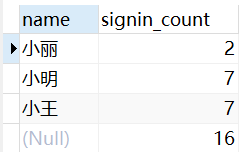
10.3. Use WITH ROLLUP
WITH ROLLUP can perform the same statistics (SUM,AVG,COUNT...) on the basis of grouped statistics.
It will add one more row to make the same statistics based on the grouped statistics. The sum used here is equivalent to adding the data to one piece after grouping, and then opening another row of data for display.
SELECT name, SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
Query results:
11. MySQL regular expression
REGEXP operator is used in MySQL for regular expression matching.
Find all data starting with 'st' in the name field:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^st';
Find all data ending with 'ok' in the name field:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'ok$';
Find all data containing the 'mar' string in the name field:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'mar';
Find all data in the name field that starts with a vowel character or ends with a 'ok' string:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
12. Common functions
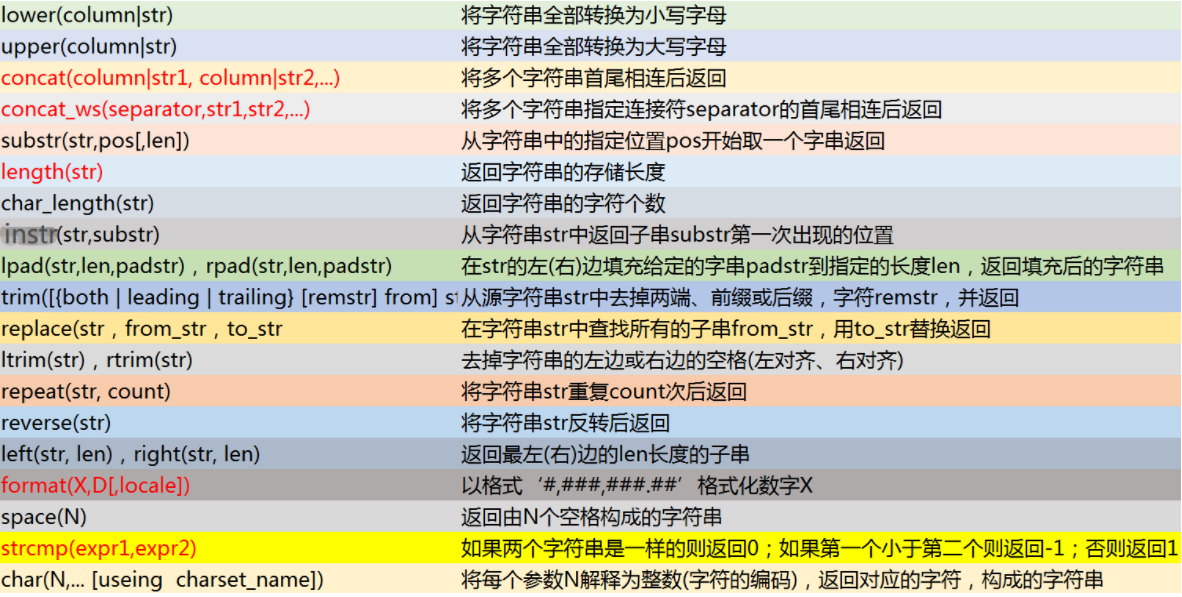
12.1 MySQL string function
12.2. MySQL digital function
ABS(x): returns the absolute value of X
BIN(x): returns the binary of X (OCT returns octal, HEX returns hexadecimal)
CEILING(x): returns the smallest integer value greater than x
EXP(x): returns the x power of the value e (the base of the natural logarithm)
FLOOR(x): returns the maximum integer value less than x
GREATEST(x1,x2,...,xn): returns the largest value in the set
LEAST(x1,x2,...,xn): returns the smallest value in the set
LN(x): returns the natural logarithm of X
LOG(x,y): returns the base y logarithm of X
MOD(x,y): returns the modulus (remainder) of x/y
PI(): returns the value of pi (pi)
RAND(): returns a random value from 0 to 1. The RAND() random number generator can generate a specified value by providing a parameter (seed).
ROUND(x,y): returns the value of parameter x rounded to y decimal places
SIGN(x): returns the value of the symbol representing the number X
SQRT(x): returns the square root of a number
TRUNCATE(x,y): returns the result of truncating the number x to y decimal places
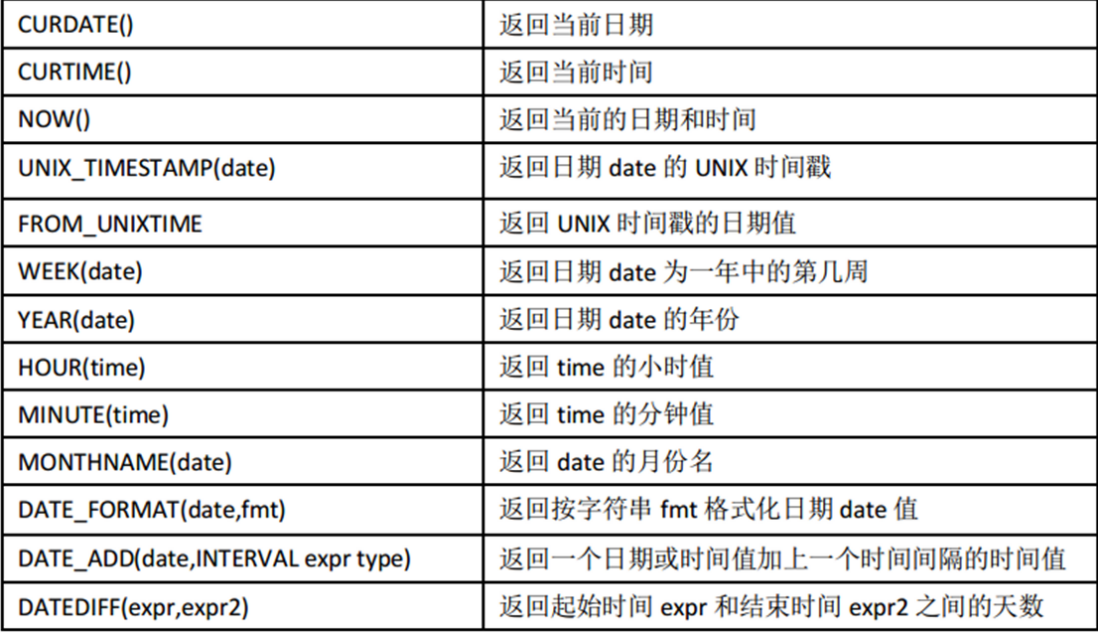
12.3. MySQL date function
12.4 MySQL aggregate function
AVG(col): returns the average value of the specified column
COUNT(col): returns the number of non NULL values in the specified column
MIN(col): returns the minimum value of the specified column
MAX(col): returns the maximum value of the specified column
SUM(col): returns the sum of all values of the specified column
GROUP_CONCAT(col): returns the result of a combination of column values belonging to a group
In this example, I the name of group by. Through this function, we can get other column values after grouping.
Example: select GROUP_CONCAT(id) from goods GROUP BY name
12.5. MySQL control flow function
MySQL has four functions for conditional operations. These functions can realize the conditional logic of SQL and allow developers to convert some application business logic to the database background.
CASE [test] WHEN[val1] THEN [result]... ELSE [default]END if test and valN are equal, resultN is returned; otherwise, default is returned
Example: when id=2, it returns 2; otherwise, it returns 3
SELECT CASE id WHEN 2 THEN 2 ELSE 3 END FROM goods;
IF(test,t,f): if test is true, return T; Otherwise, return F
IFNULL(arg1,arg2): if arg1 is not empty, arg1 is returned; otherwise, arg2 is returned
NULLIF(arg1,arg2): returns NULL if arg1=arg2; Otherwise, arg1 is returned
12.6 MySQL type conversion function
For data type conversion, MySQL provides the CAST() function, which can convert a value to a specified data type.
Syntax: CAST (expression AS data_type)
Expression: any valid SQServer expression.
AS: used to separate two parameters. Before AS is the data to be processed, and after AS is the data type to be converted.
data_type: the data type provided by the target system, including bigint and sql_variant, user-defined data types cannot be used.
The types that can be converted are limited. This type can be one of the following values:
BINARY, with BINARY prefix effect: BINARY
Character type, with parameters: CHAR()
DATE: DATE
TIME: TIME
Date time type: DATETIME
Floating point numbers: DECIMAL
Integer: SIGNED
UNSIGNED integer: UNSIGNED
Example 1: date to number
SELECT CAST(NOW() AS SIGNED);
Example 2: keep 2 decimal places
SELECT CAST('9.5' AS decimal(10,2));
Result: 9.50 (10 is the total number of digits, including the sum of digits to the left and right of the decimal point, and 2 is the number of digits to the right of the decimal point)
12.7 MySQL system information function
DATABASE(): returns the current database name
BENCHMARK(count,expr): run the expression expr repeatedly for count times
CONNECTION_ID(): returns the connection ID of the current customer
FOUND_ROWS(): returns the total number of rows retrieved by the last SELECT query
User () or SYSTEM_USER(): returns the current login user name
VERSION(): returns the version of the MySQL server
13. mysql storage engine
Database storage engine is the underlying software organization of database. Database management system (DBMS) uses data engine to create, query, update and delete data. Different storage engines provide different storage mechanisms, indexing skills, locking levels and other functions. Using different storage engines, you can also obtain specific functions. Nowadays, many different database management systems support a variety of different data engines.
Because the storage of data in a relational database is in the form of a table, the storage engine can also be called a Table Type (Table Type, that is, the type that stores and operates this table). When creating a table, you can specify the storage engine type.
To create a table of InnoDB type:
CREATE TABLE IF NOT EXISTS `runoob_tbl`( `runoob_id` INT UNSIGNED AUTO_INCREMENT COMMENT 'notes', PRIMARY KEY ( `runoob_id` ) )ENGINE=InnoDB DEFAULT CHARSET=utf8;
13.1. View the default storage engine
This command can view the default storage engine of the database.
SHOW ENGINES;
View results:
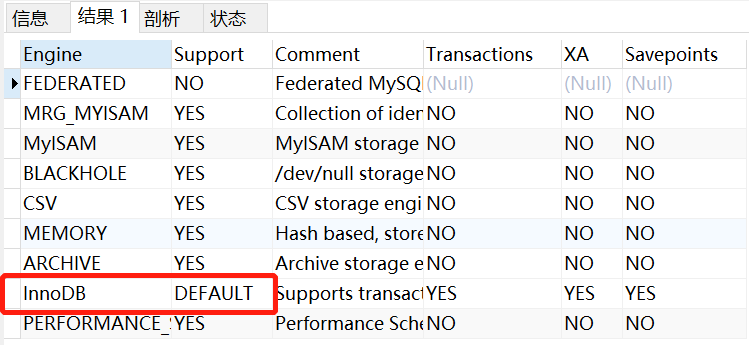
13.2 storage engine
MyISAM: MyISAM is based on and extends the ISAM storage engine. It is one of the most commonly used storage engines in Web, data warehousing and other application environments. MyISAM has high insertion and query speed, but it does not support things and foreign keys.
InnoDB: the default database of Mysql after version 5.5. It supports transaction processing, foreign keys, crash repair capability and concurrency control. If you need high requirements for transaction integrity (such as banks) and concurrency control (such as ticket sales), InnoDB has great advantages. If you need to update and delete databases frequently, you can also choose InnoDB because it supports transaction commit and rollback.
MEMORY: a storage engine that stores all data in MEMORY, with high insertion, update and query efficiency. However, it will occupy MEMORY space proportional to the amount of data. And its contents will be lost when Mysql is restarted. The MEMORY storage engine uses HASH index by default.
Archive: it is very suitable for storing a large number of independent data as historical records. Because they are not often read. Archive has efficient insertion speed, but its support for queries is relatively poor
Federated: combine different Mysql servers to logically form a complete database. Ideal for distributed applications
CSV: a storage engine that logically separates data by commas. It creates a. CSV file for each data table in the database subdirectory. This is an ordinary text file. Each data line occupies one text line. The CSV storage engine does not support indexing I remember this is used to store indexes?
BlackHole: black hole engine. The storage engine supports transactions and mvcc row level locks. Any data written to the engine table will disappear. It is mainly used for relay storage for logging or synchronous archiving. Unless there is a special purpose, this storage engine is not suitable for use.
PERFORMANCE_SCHEMA storage engine: mainly used to collect database server performance parameters. This engine provides the following functions: providing process waiting details, including locks, mutually exclusive variables and file information;
14. MySQL index
Take the table of contents page (index) of a Chinese dictionary for example. We can quickly find the required words according to the table of contents (index) sorted by pinyin, strokes, partial radicals, etc.
The index is divided into single column index and combined index. Single column index, that is, an index contains only a single column. A table can have multiple single column indexes, but this is not a composite index. Composite index, that is, an index contains multiple columns.
When creating an index, you need to ensure that the index is a condition applied to the SQL query statement (generally as a condition of the WHERE clause).
In fact, the index is also a table that holds the primary key and index fields and points to the records of the entity table.
Index also has its disadvantages: establishing an index will occupy disk space. Although the index greatly improves the query speed, it will reduce the speed of updating the table, such as INSERT, UPDATE and DELETE. Because when updating tables, MySQL should not only save data, but also save index files.
14.1 index type
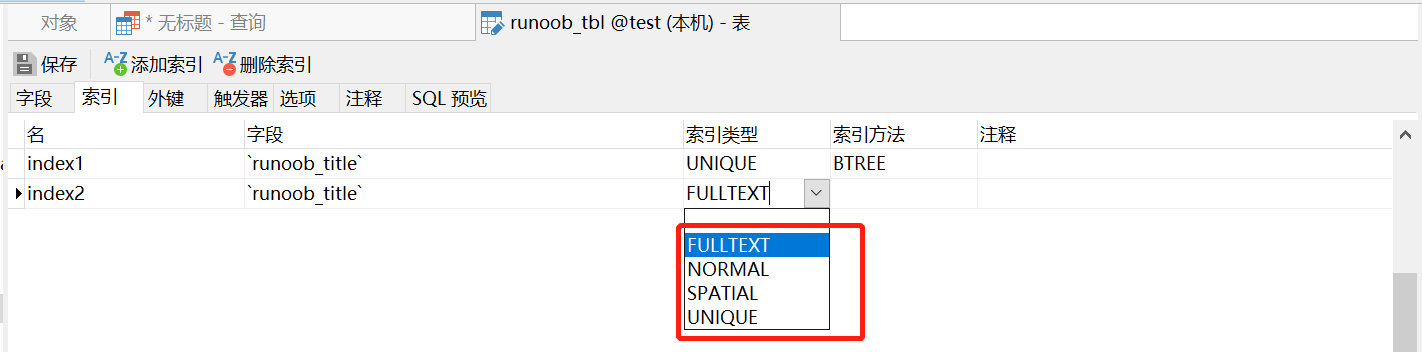
14.1.1 NORMAL general index
Represents a common index, which can be used in most cases. The so-called composite index is also one of the common index types. It is nothing more than an index composed of multiple columns.
14.1.2 UNIQUE index
The unique index column value must be unique, but null values are allowed (note that it is different from the primary key). If it is a composite index, the combination of column values must be unique. In fact, in many cases, the purpose of creating a unique index is often not to improve access speed, but to avoid data duplication.
14.1.3 FULLTEXT full text index
It indicates full-text retrieval. The effect is the best when retrieving long text. It is recommended to use Index for short text. However, when the amount of data is large, first put the data into a table without global Index, and then create the Full Text Index with Create Index, which is much faster than first creating Full Text for a table and then writing data
Full TEXT index can only be used on fields of type CHAR, VARCHAR, TEXT and. Full TEXT indexes can only be created in tables whose storage engine is MYISAM.
14.1.4 SPATIAL spatial index
SPATIAL index is an index established for fields of SPATIAL data types. There are four SPATIAL data types in MYSQL: GEOMETRY, POINT, LINESTRING and POLYGON. MYSQL uses the SPATIAL keyword to expand, enabling the syntax used to create regular index types to create SPATIAL indexes. Columns that create SPATIAL indexes must be declared NOT NULL. SPATIAL indexes can only be created in tables whose storage engine is MYISAM
14.2 index creation
Note: creating a normal index does not write the index type.
Creation method 1:
CREATE Index type INDEX Index name ON Table name (Listing);
Example: create a unique index. Here I set two columns as indexes, which is often referred to as composite index.
CREATE UNIQUE INDEX index1 ON runoob_tbl (runoob_title,runoob_author);
Creation method 2: add an index by modifying the table structure
ALTER table Table name ADD Index type INDEX Index name(Listing);
Example:
ALTER table runoob_tbl ADD SPATIAL INDEX index4(cc);
14.3. Delete index
DROP INDEX indexName ON table_name;
14.4 index method
In my navcat client, click a table, then click design table and open the index. You can see that we can specify the index method when creating the index. There are two kinds here.
Different engines have different support for indexes: Innodb and MyISAM default index is Btree index; The default index of Mermory is Hash index.
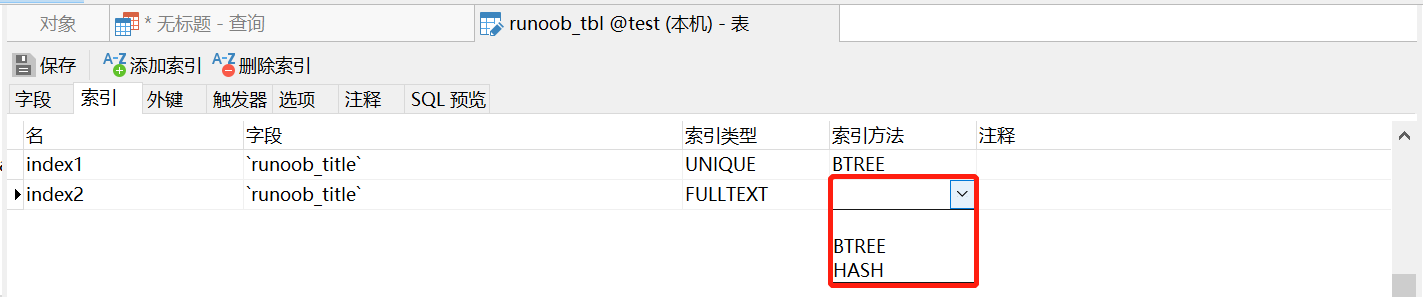
14.4.1 btree index
BTree index is the most commonly used mysql database index algorithm, because it can be used not only for the comparison operators =, >, > =, <, < = and between, but also for the like operator, as long as its query condition is a constant that does not start with a wildcard, such as:
select * from user where name like 'jack%'; select * from user where name like 'jac%k%';
If you start with a wildcard or do not use a constant, the index will not be used, for example:
select * from user where name like '%jack'; select * from user where name like simply_name;
14.4.2 hash index
The so-called Hash index is that when we want to add an index to a column of a table, we calculate the column of the table by Hash algorithm, get the Hash value, and sort it on the Hash array. Therefore, the Hash index can be located at one time with high efficiency, while the Btree index needs multiple disk IO, but innodb and myisam do not adopt it because it has many disadvantages:
1. The Hash index compares the Hash calculated values, so it can only be used for equality comparison and cannot be used for range query
2. Scan the whole table every time
3. Because the Hash values are arranged in order, but the real data mapped by the Hash values are not necessarily arranged in order in the Hash table, the Hash index cannot be used to speed up any sorting operation.
4. You cannot search with partial index keys because the combined index is calculated together when calculating the hash value.
5. When the hash value is repeated and the amount of data is very large, its retrieval efficiency is not as high as that of Btree index.
Hash indexes can only be used for peer-to-peer comparisons, such as =, < = > (equivalent to =) operators. Because it is one-time positioning data, unlike BTree index, which needs multiple IO accesses from root node to branch node and finally to page node, the retrieval efficiency is much higher than that of BTree index.
15. mysql variable classification
15.1 variable classification and relationship
Variables in MySQL are divided into global variables, session variables, user variables and local variables.
MySQL server maintains many system variables to control its running behavior. Some of these variables are compiled into the software by default, and some can be configured and overwritten through external configuration files. If you want to query self compiled built-in variables and read overwritten variables from files, you can execute the query in the cmd window through the following commands:
mysqld --verbose --help
If you want to see only self compiled built-in variables, you can use the command:
mysqld --no-defaults --verbose --help
Global variables: first, the MySQL server will use the built-in variables in its software (commonly known as those written in the code) and the variables in the configuration file (if allowed, they can override the default values in the source code) to initialize the running environment of the whole MySQL server. These variables are usually what we call global variables, Some of these global variables in memory can be modified.
Session variables: when a client is connected to the MySQL server, the MySQL server will copy most of these global variables as the session variables of the connected client. These session variables are bound to the client connection. The connected client can modify the variables that are allowed to be modified, but when the connection is disconnected, all these session variables disappear, When reconnecting, a new copy is copied from the global variable.
User variables: user variables are actually user-defined variables. After the client connects to the MySQL server, you can define some variables. These variables are valid throughout the connection process. When the connection is disconnected, these user variables disappear.
Local variable: it is usually defined by the DECLARE keyword and often appears in stored procedures.
15.2 modification of variables
First, many global variables can be adjusted dynamically, that is, you can modify global variables through the SET command during the operation of MySQL server without restarting MySQL service. However, this method requires super permissions when modifying most variables, such as the root account.
In contrast, the requirements for modifying session variables are much lower, because modifying session variables usually only affects the current connection, but there are some exceptions. Modifying them also requires higher permissions, such as binlog_format and sql_log_bin, because setting the values of these variables will affect the binary logging of the current session, and may also have a broader impact on the integrity of server replication and backup.
As for user variables and local variables, you can know from the name that the life and death of these variables are completely in your own hands. You can change them if you want. You don't need to pay attention to any permissions. Its definition and use are all in your own hands.
15.3. Global variable query and setting
Global variables: these variables come from the variables specified in the software self compilation, configuration file and startup parameters. Most of them can be modified by the root user directly at runtime through the SET command. Once the MySQL server is restarted, all modifications will be restored. If you modify the configuration file and want to restore the original settings, you only need to restore the configuration file and restart the MySQL server. Everything can be restored to its original appearance.
Query:
show global variables;
Generally, it is not used in this way. There are almost too many checks. There are about 500. Usually, a like is added to control the filtering conditions:
show global variables like 'sql%';
Another query method is through the select statement:
select @@global.sql_mode;
This can also be done when a global variable does not have a copy of the session variable
select @@sql_auto_is_null;
- select @ @ variable name takes the session variable by default. If the queried session variable does not exist, it will get the global variable, such as @ @ max_connections
- However, during set operation, set @@ variable name = xxx is always the session variable of the operation. If the session variable does not exist, an error will be reported
set up:
set global sql_mode=''; set @@global.sql_mode='';
15.4. Session variable query and setting
These variables basically come from the replication of global variables and are related to the client connection. No matter how they are modified, everything will be restored when the connection is disconnected. The next connection is a new start.
Query:
show session variables;
Generally, it is not used in this way. There are almost too many checks. There are about 500. Usually, a like is added to control the filtering conditions:
show session variables like 'sql%';
Query specific session variables, including the following three types:
select @@session.sql_mode; select @@local.sql_mode; select @@sql_mode;
set up:
set session sql_mode = ''; set local sql_mode = ''; set @@session.sql_mode = ''; set @@local.sql_mode = ''; set @@sql_mode = ''; set sql_mode = '';
15.5 user variable query and setting
User variables are user-defined variables, which also expire when the connection is disconnected. The definition and use of user variables are much simpler than session variables.
Query:
select @count;
set up:
set @count=1; set @sum:=0;
You can also use the select into statement to set values, such as:
select count(id) into @count from items where price < 99;
15.6 local variable query and setting
Local variables usually appear in stored procedures for intermediate calculation results, data exchange, etc. when the stored procedures are executed, the life cycle of variables will end.
Query:
declare count int(4); select count;
set up:
declare count int(4); declare sum int(4); set count=1; set sum:=0;
You can also use the select into statement to set values, such as:
declare count int(4); select count(id) into count from items where price < 99;
16. Management transactions
Transaction processing is a mechanism used to manage SQL operations that must be executed in batches to ensure that the database does not contain incomplete operation results. With transaction processing, you can ensure that a set of operations will not stop halfway. They will either execute completely or not execute at all (unless explicitly instructed). If no error occurs, the whole set of statements is submitted (written) to the database table; If an error occurs, fallback (undo) is performed to restore the database to a known and safe state, so as to maintain the integrity of the database.
16.1 transaction terms
transaction: refers to a group of SQL statements;
rollback: refers to the process of revoking a specified SQL statement;
commit: refers to writing the results of SQL statements that are not stored into the database table;
savepoint: refers to the temporary placeholder set in the transaction, which can be used to publish fallback (different from fallback the whole transaction).
Transactions are used to manage INSERT, UPDATE, and DELETE statements. You cannot fallback a SELECT statement (it is not necessary to fallback a SELECT statement), nor can you fallback CREATE or DROP operations. These statements can be used in transactions, but they are not undone when fallback is performed.
16.2 four characteristics of transaction
Atomicity: all operations in a transaction are either completed or not completed, and will not end in an intermediate link. If an error occurs during the execution of a transaction, it will be rolled back to the state before the start of the transaction, as if the transaction had never been executed.
Consistency: the integrity of the database is not destroyed before and after the transaction. This means that the written data must fully comply with all preset rules, including the accuracy and serialization of the data, and the subsequent database can spontaneously complete the predetermined work.
Isolation: the ability of a database to allow multiple concurrent transactions to read, write and modify their data at the same time. Isolation can prevent data inconsistency caused by cross execution when multiple transactions are executed concurrently. Transaction isolation is divided into different levels, including Read uncommitted, read committed, repeatable read, and Serializable.
Persistence: after the transaction is completed, the modification of data is permanent and will not be lost even if the system fails.
16.3. Control transaction processing
Under the default setting of MySQL command line, transactions are automatically committed, that is, the COMMIT operation will be executed immediately after the SQL statement is executed. Therefore, to explicitly start a transaction, you must use the command BEGIN or START TRANSACTION, or execute the command SET AUTOCOMMIT=0 to prohibit the automatic submission of the current session.
#There are two ways to explicitly open a transaction: BEGIN; START TRANSACTION; #There are two ways to commit transactions to make all modifications to the database permanent: COMMIT; COMMIT WORK; #Rollback will end the user's transaction and undo all ongoing uncommitted modifications; ROLLBACK; ROLLBACK WORK; #It is allowed to create a SAVEPOINT in a transaction, and there can be multiple savepoints in a transaction; SAVEPOINT Save point name; #Delete the savepoint of a transaction. When there is no specified savepoint, an exception will be thrown when the statement is executed; RELEASE SAVEPOINT Save point name; #Roll back the transaction to the marked point; ROLLBACK TO Save point name; #Used to set the isolation level of transactions. The InnoDB storage engine provides transaction isolation levels such as READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ and SERIALIZABLE. SET TRANSACTION;
Simple example:
mysql> use test; mysql> CREATE TABLE transaction_test(id int(5)) ENGINE = INNODB; # Create data table mysql> SELECT * FROM transaction_test; Empty set (0.01 sec) mysql> BEGIN; # Start transaction mysql> INSERT INTO runoob_transaction_test VALUE(1); mysql> INSERT INTO runoob_transaction_test VALUE(2); mysql> COMMIT; # Commit transaction mysql> SELECT * FROM transaction_test; +------+ | id | +------+ | 1 | | 2 | +------+ mysql> BEGIN; # Start transaction mysql> INSERT INTO transaction_test VALUES(3); mysql> SAVEPOINT first_insert; # Declare a savepoint mysql> INSERT INTO transaction_test VALUES(4); mysql> SAVEPOINT second_insert; # Declare a savepoint mysql> INSERT INTO transaction_test VALUES(5); mysql> ROLLBACK TO second_insert; # Rollback to second_insert savepoint mysql> SELECT * FROM transaction_test; # Data was not inserted because of rollback +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | +------+ mysql> ROLLBACK TO first_insert; mysql> SELECT * FROM transaction_test; +------+ | id | +------+ | 1 | | 2 | | 3 | +------+ mysql> COMMIT; # Savepoints are automatically released after COMMIT or ROLLBACK
16.4. Transaction isolation level
There is a variable in mysql that can set the transaction isolation level.
The variable name used in earlier versions of mysql was tx_isolation, after version 5.7.20, uses transaction_isolation.
# You can use this command to see what the isolation level name is show variables like 't%_isolation'; # View the default transaction isolation level (session) select @@transaction_isolation; # View the isolation level of the current session select @@session.transaction_isolation; # View global transaction isolation levels select @@global.transaction_isolation;
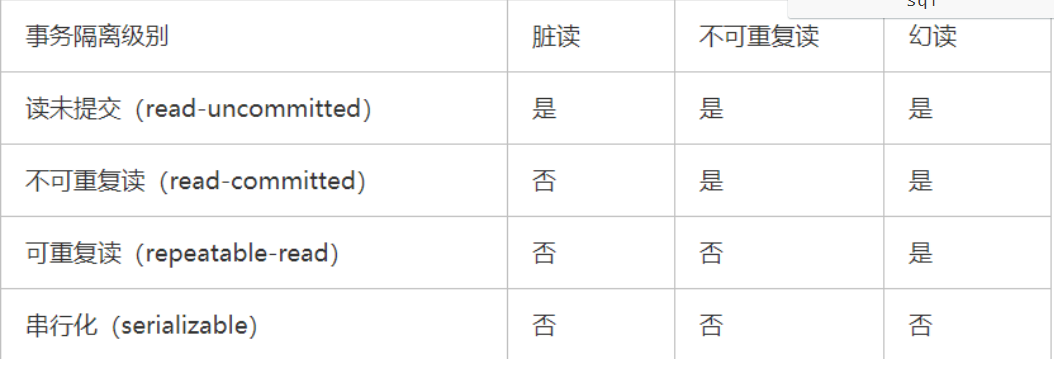
16.4.1 read uncommitted
For two transactions T1 and T2, after T1 reads the fields that have been updated by T2 but have not been committed, if T2 rolls back at this time, the contents read by T1 are temporary and invalid.
Open two Mysql clients and perform the following operations respectively to query the isolation level of the current session (REPEATABLE READ by default). Modify the current session isolation level to READ UNCOMMITTED. The global transaction isolation level remains REPEATABLE READ.
mysql> SELECT @@session.transaction_isolation; +-------------------------+ | @@transaction_isolation | +-------------------------+ | REPEATABLE-READ | +-------------------------+ mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; # Modify session isolation level mysql> SELECT @@session.transaction_isolation; # The current session isolation level has been modified +---------------------------------+ | @@session.transaction_isolation | +---------------------------------+ | READ-UNCOMMITTED | +---------------------------------+ mysql> SELECT @@global.transaction_isolation; # The global transaction isolation level was not modified +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | REPEATABLE-READ | +--------------------------------+
After that, the black box is used for updating and the white box is used for querying.
Due to the rollback of the black box ④, the data read by ③ in the white background client is temporary and invalid. Dirty reading.
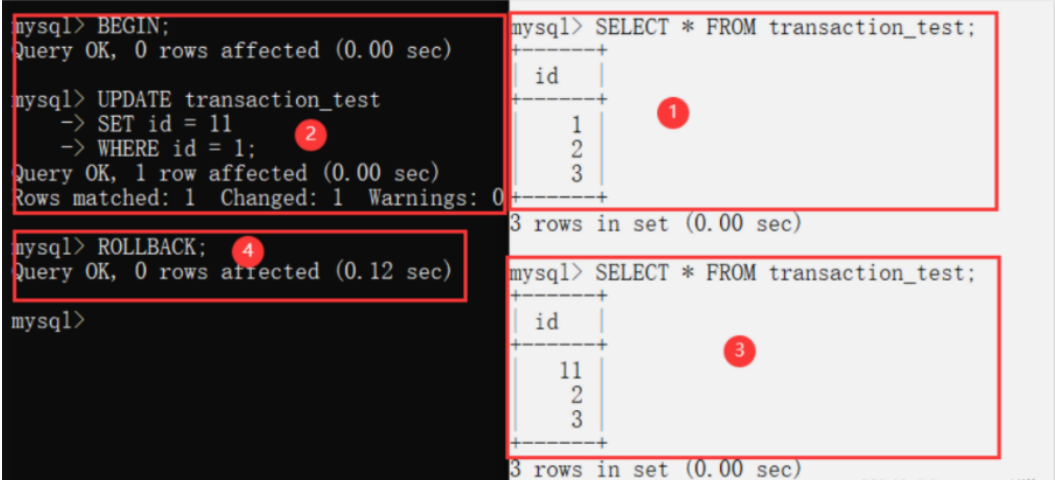
16.4.2 non repeatable reading
For two transactions T1 and T2, T1 reads a field, and then T2 updates the field and commits it. When T1 reads it again, inconsistent results occur.
Due to the update operation of the black box, the results of two reads of the white box in the same transaction are inconsistent.
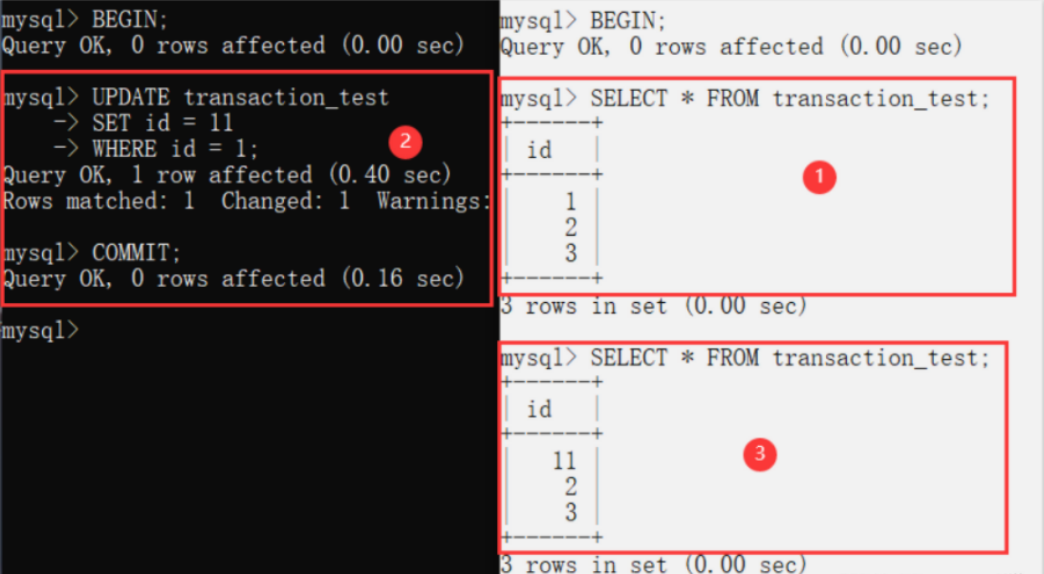
16.4.3 unreal reading
For two transactions T1 and T2, T1 reads data from the table, and then T2 performs an INSERT operation and commits. When T1 reads again, inconsistent results occur.
Due to the insertion of the black box, the results of two reads of the white box in the same transaction are inconsistent.
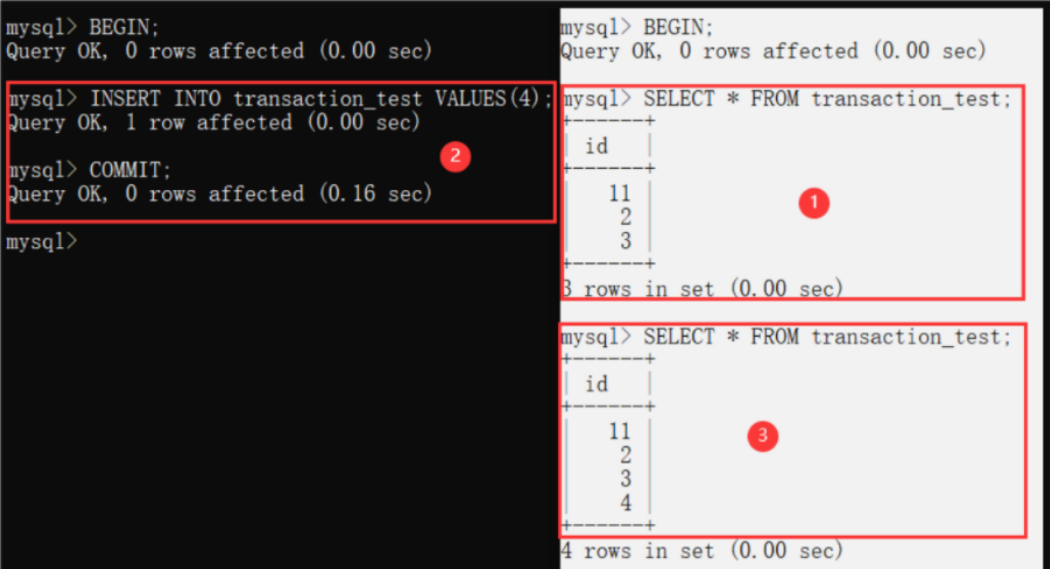
16.4.4 serialization
For two transactions T1 and T2, T1 reads data from the table, but does not end the transaction. When other transactions are added, they will fail. Queries can be queried.
(1) Open A client A, set the current transaction mode to serializable, and query the initial value of the table account:
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from account; +------+--------+---------+ | id | name | balance | +------+--------+---------+ | 1 | lilei | 10000 | | 2 | hanmei | 10000 | | 3 | lucy | 10000 | | 4 | lily | 10000 | +------+--------+---------+ 4 rows in set (0.00 sec)
(2) Open a client B and set the current transaction mode to serializable. An error is reported when inserting a record. The table is locked and the insertion fails. When the transaction isolation level in mysql is serializable, the table will be locked. Therefore, unreal reading will not occur. This isolation level has very low concurrency and is rarely used in development.
mysql> set session transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into account values(5,'tom',0); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
17. MySQL and SQL injection
If there is an sql to verify the user when logging in, let me enter the user name.
SELECT * FROM users WHERE name= #{name}
name = "Qadir'; DELETE FROM users;";
If the program does not filter the variables of name, an SQL statement that we do not need is inserted into $name, which will delete all data in the users table. Don't underestimate this problem. It may be very serious.
During like query, if the value entered by the user has "and"% ", this situation will occur: the user just wants to query" ABCD ", but there are" abcd_ "," abcde "," abcdf "and so on in the query result; there will also be problems when the user wants to query" 30% "(Note: 30%).
To prevent SQL injection, we need to pay attention to the following points:
- Never trust user input. To verify the user's input, you can use regular expressions or limit the length; Convert single quotation marks and double "-", etc.
- Never use dynamic assembly sql. You can use parameterized sql or directly use stored procedures for data query and access.
- Never use a database connection with administrator privileges. Use a separate database connection with limited privileges for each application.
- Do not store confidential information directly, encrypt or hash passwords and sensitive information.
- The application exception information should give as few prompts as possible. It is best to wrap the original error information with custom error information
- The detection method of SQL injection generally adopts auxiliary software or website platform. The software generally adopts SQL injection detection tool jsky. The website platform has Yisi website security platform detection tool. MDCSOFT SCAN et al. MDCSOFT-IPS can effectively defend against SQL injection and XSS attacks.
18. Stored procedure
Stored procedure is a set of SQL statements to complete specific functions. It is compiled, created and saved in the database. Users can call and execute it by specifying the name of the stored procedure and giving parameters (when necessary).
18.1 querying stored procedures
# View all stored procedure information SHOW PROCEDURE STATUS; # Specify stored procedure view SHOW CREATE PROCEDURE Stored procedure name;
18.2 authority issues
Sometimes it is clear that the database has this stored procedure, but it is said that it cannot be found when call ing. This is because the user does not have the permission of the stored procedure.
// Query authority mysql> SHOW GRANTS FOR root@localhost; // Refresh mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.00 sec) // Assignment authority mysql> GRANT ALL PRIVILEGES ON test.* TO 'root'@localhost; Query OK, 0 rows affected (0.00 sec)
18.3. Create stored procedure
In MySQL, the basic form of creating stored procedures is as follows:
DELIMITER $$
CREATE
PROCEDURE Stored procedure name (parameter list)
BEGIN
SQL Statement code block
END$$
DELIMITER ; # DELIMITER must be followed by a space
DELIMITER $$; The function of the statement is to set the END character of MYSQL to $$, because the default END character of MYSQL statement is semicolon, The SQL statement in the stored procedure needs a semicolon to END. In order to avoid conflict with the SQL statement terminator in the stored procedure, you need to use delimiter to change the terminator of the stored procedure and END the stored procedure with "END $$". Delete is used after the stored procedure is defined; Restore the default terminator. Delimiter can also specify other symbols as terminators.
Note: when using the DELIMITER command, you should avoid using the backslash (\) character, because the backslash is the escape character of MYSQL!!!
DELIMITER means a DELIMITER, which actually defines the terminator of a statement execution;
By default, delimiter is a semicolon ";". In the command-line client, if a command ends with a semicolon, mysql will execute the command after entering. If you enter the following statement
mysql> select * from stu;
Then press enter, and MySQL will execute the statement immediately. But sometimes, I don't want Mysql to do that. Because you may enter more statements and the statements contain semicolons. By default, it is impossible to wait until the user has entered all these statements before executing the whole statement. As soon as MySQL encounters a semicolon, it will execute automatically. That is, when the statement is followed by ";, the MySQL interpreter will execute. In this case, you need to replace the delimiter with other symbols, such as / / or $$. In this way, the MySQL interpreter will execute this statement only after $$. Remember to modify the terminator back to".
18.4 stored procedure parameters
The form of parameter list is as follows:
[IN|OUT|INOUT] param_name type
param_name indicates the parameter name; Type indicates the type of the parameter, which can be any type in the MYSQL database.
- IN (input parameter): indicates that the caller passes IN a value to the procedure (the passed IN value can be literal or variable)
- OUT (output parameter): indicates that the procedure sends OUT a value to the caller (multiple values can be returned) (the outgoing value can only be a variable)
- INOUT (input / output parameter): it indicates that the caller passes in a value to the procedure and the procedure passes out a value to the caller (the value can only be a variable)
18.4.1 IN input parameters
Parameter columns surrounded by parentheses must always exist. If there are no parameters, an empty parameter column () should also be used.
Each parameter is an IN parameter by default. To specify as another parameter, use the keyword OUT or INOUT before the parameter name.
@p_in is a user variable, although p_in is modified in the stored procedure, but does not affect @p_ The value of in because in_test only accepts input parameters and does not output parameters, so it is equivalent to changing in the function, but does not output this value to @ p_in .
mysql> DELIMITER $$
mysql> DROP PROCEDURE IF EXISTS `in_test`$$
mysql> CREATE PROCEDURE in_test(IN p_in INT)
-> BEGIN
-> SELECT p_in; -- First query
-> SET p_in = 2; -- modify p_in Value of
-> SELECT p_in; -- Second query
-> END$$
mysql> DELIMITER ;
mysql> SET @p_in = 1;
mysql> CALL in_test(@p_in);
+------+
| p_in |
+------+
| 1 |
+------+
+------+
| p_in |
+------+
| 2 |
+------+
mysql> SELECT @p_in;
+-------+
| @p_in |
+-------+
| 1 |
+-------+
18.4.2 OUT input parameters
mysql> DELIMITER $$
mysql> DROP PROCEDURE IF EXISTS `out_test`$$
mysql> CREATE PROCEDURE out_test(OUT p_out INT)
-> BEGIN
-> SELECT p_out; -- First query
-> SET p_out = 2; -- modify p_out Value of
-> SELECT p_out; -- Second query
-> END$$
mysql> DELIMITER ;
mysql> SET @p_out = 1;
mysql> CALL out_test(@p_out);
+-------+
| p_out |
+-------+
| NULL |
+-------+
+-------+
| p_out |
+-------+
| 2 |
+-------+
mysql> SELECT @p_out;
+--------+
| @p_out |
+--------+
| 2 |
+--------+
The first return result is NULL because OUT outputs parameters to the caller and does not receive input parameters. Therefore, p_out has not been assigned, so it is NULL. Last @ p_ The value of the OUT variable changes to 2 because OUT is called_ Test stored procedure, output parameters, changed P_ The value of the OUT variable.
18.4.3 INOUT input and output parameters
mysql> DELIMITER $$
mysql> DROP PROCEDURE IF EXISTS `inout_test`$$
mysql> CREATE PROCEDURE inout_test(INOUT p_inout INT)
-> BEGIN
-> SELECT p_inout; -- First query
-> SET p_inout = 2; -- modify p_inout Value of
-> SELECT p_inout; -- First query
-> END$$
mysql> DELIMITER ;
mysql> SET @p_inout = 1;
mysql> CALL inout_test(@p_inout);
+---------+
| p_inout |
+---------+
| 1 |
+---------+
+---------+
| p_inout |
+---------+
| 2 |
+---------+
mysql> SELECT @p_inout;
+----------+
| @p_inout |
+----------+
| 2 |
+----------+
Call inout_ The test stored procedure accepts both input and output parameters, @p_ The value of inout is changed.
18.5 deleting stored procedures
DROP PROCEDURE IF EXISTS Stored procedure name;
This statement is used to remove a stored program. You cannot delete a stored procedure within another stored procedure.
18.6. Calling stored procedure
CALL Stored procedure name(parameter list);
18.7 stored procedure body
The stored procedure body contains the statements that must be executed during procedure call, such as dml, ddl statements, if then else and while do statements, declare statements that declare variables, etc.
Procedure body format: start with begin and end with end (can be nested)
18.8 defining variables
Define variable my_sql, the data type is INT, and the default value is 10. The code is as follows:
DECLARE my_sql INT DEFAULT 10 ;
The DECLARE keyword is used to DECLARE variables;
my_ The SQL parameter is the name of the variable. Multiple variables can be defined here at the same time;
When the DEFAULT clause is not used, the DEFAULT value is NULL.
instructions:
Local variables can only be declared in the begin... end statement block of the stored procedure body.
Local variables must be declared at the beginning of the stored procedure body.
The scope of a local variable is limited to the begin... end statement block that declares it. Statements in other statement blocks cannot use it.
Local variables are different from user variables. The difference between them is: when declaring a local variable, the @ symbol is not used in front of it, and it can only be used in the begin... end statement block; When a user variable is declared, the @ symbol will be used in front of its name, and the declared user variable exists in the whole session.
18.9 assignment variables
SELECT col_name[,...] INTO var_name[,...] table_expr;
col_name: the column field name to query from the database;
var_name: variable name. The column field name corresponds to the position in the column list and variable list, and the queried value is assigned to the variable in the corresponding position;
table_expr: the rest of the SELECT statement, including the optional FROM clause and WHERE clause.
It should be noted that when using the SELECT... INTO statement, the variable name cannot be the same as the field name in the data table, otherwise an error will occur.
Example:
CREATE DEFINER=`root`@`localhost` PROCEDURE `test6`()
BEGIN
// Define a variable
DECLARE NAME VARCHAR(30);
// Assign the queried data to the variable
select uname INTO `name` from user where uid = 1;
// Perform other business queries through variables.
SELECT uid from user where uname = name;
END
19. Cursor
The SQL retrieval operation returns the result set. Simply use the SELECT statement. There is no way to get the first row, the next row or the first 10 rows. Sometimes, you need to move forward or backward one or more rows in the retrieved rows, which is the purpose of the cursor. A cursor is a database query stored on the DBMS server. It is not a SELECT statement, but a result set retrieved by the statement. After storing the cursor, the application can scroll or browse the data as needed.
19.1. Use cursor
To use a cursor:
A cursor must be declared (defined) before it can be used. This process does not actually retrieve data, it just defines the SELECT statement and cursor options to be used.
Once declared, the cursor must be opened for use. This process uses the previously defined SELECT statement to actually retrieve the data.
For cursors filled with data, fetch (retrieve) rows as needed.
At the end of cursor use, the cursor must be closed and, if possible, released.
After declaring a cursor, you can open or close the cursor as often as needed. When the cursor is open, fetch operations can be performed frequently as needed.
Note: unlike most DBMS, MySQL cursors can only be used for stored procedures (and functions).
19.2. Create cursor
Use DECLARE to create cursors. DECLARE names cursors and defines corresponding SELECT statements with WHERE and other clauses as needed.
The following statement defines a cursor named ordernumbers and uses a SELECT statement that can retrieve all orders.
DROP PROCEDURE IF EXISTS processorder; CREATE PROCEDURE processorder() BEGIN -- Define cursor DECLARE ordernumbers CURSOR FOR SELECT order_num FROM orders; END;
In this stored procedure, the DECLARE statement is used to define and name cursors. After the stored procedure is processed, the cursor disappears (because it is limited to the stored procedure).
19.3. Using cursor data
Case 1: this uses a loop loop.
DELIMITER $$
USE `test`$$
DROP PROCEDURE IF EXISTS `test2`$$
CREATE DEFINER = `root` @`localhost` PROCEDURE `test2` ()
BEGIN
-- Define local variables
DECLARE uid INT ;
DECLARE count2 INT ;
DECLARE done INT ;
-- Define cursor
DECLARE cur_test CURSOR FOR
SELECT
id,
COUNT
FROM
test2 ;
-- If no data is returned,The program continues,And put the variable done Set to 1
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=true;
-- Open cursor
OPEN cur_test ;
-- definition loop
posLoop :LOOP
IF done = 1
-- LEAVE Statement is mainly used to jump out of loop control
THEN LEAVE posLoop ;
END IF ;
-- The value in the cursor is assigned to the variable
FETCH cur_test INTO UID,count2 ;
-- At this time, you can get the variables for business processing.
UPDATE
test2
SET
COUNT= 2
WHERE id = UID ;
-- end loop
END LOOP posLoop ;
-- Close cursor
CLOSE cur_test ;
END $$
DELIMITER ;
Case 2: this uses the REPEAT function loop.
DELIMITER $$
USE `test`$$
DROP PROCEDURE IF EXISTS `test3`$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `test3`()
BEGIN
DECLARE uid INT ;
DECLARE count2 INT ;
DECLARE done INT ;
DECLARE cur_test CURSOR FOR
SELECT
id,
COUNT
FROM
test2 ;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = TRUE ;
OPEN cur_test ;
REPEAT
FETCH cur_test INTO UID,
count2 ;
UPDATE
test2
SET
COUNT= 4
WHERE id = UID ;
-- judge REPEAT End of cycle
UNTIL done
END REPEAT ;
CLOSE cur_test ;
END $$
DELIMITER ;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=true;
This statement defines a CONTINUE HANDLER, which is the code to be executed when the condition occurs. Here, it indicates that SET done=true when SQLSTATE '02000' appears. SQLSTATE '02000' is a condition not found. This condition occurs when REPEAT cannot continue because there are no more rows for circulation.
You can also write this to end the cycle. This is usually a special case. Judge whether to end the cycle according to the parameters. The above case is bound to be completed.
REPEAT SET num := num + 1; SET total := total + num; UNTIL num >= 100 END REPEAT;
20. Storage function
Like stored procedures, stored functions are a collection of SQL statements defined in the database. The storage function can return the function value through the return statement, which is mainly used to calculate and return a value. The stored procedure has no direct return value and is mainly used to perform operations.
20.1. Query storage function
# View all stored function information SHOW FUNCTION STATUS; # Specify storage function view SHOW CREATE FUNCTION Store function name;
20.2. Create storage function
In MySQL, the basic form of creating a storage function is as follows:
DELIMITER $$
CREATE
FUNCTION Store function name (parameter list) RETURNS return type
BEGIN
SQL Statement code block, processing business, etc..;
RETURN Return value;
END$$
DELIMITER ;
Use CREATE FUNCTION to create a query TB_ The SQL statement and execution process of a student name function in the student table are as follows:
mysql> USE test;
Database changed
mysql> DELIMITER //
mysql> CREATE FUNCTION func_student(id INT(11))
-> RETURNS VARCHAR(20)
-> COMMENT 'Query the name of a student'
-> BEGIN
-> RETURN(SELECT name FROM tb_student WHERE tb_student.id = id);
-> END //
Query OK, 0 rows affected (0.10 sec)
mysql> DELIMITER ;
Note: when the initial return value of the storage function is, variable assignment is not required. Variable assignment is required for other queries, otherwise an error is reported.
For example, if there is a query before returning, but the query result has no assigned variable, the compilation will report an error.
CREATE DEFINER=`root`@`localhost` FUNCTION `func_user`(id INT(11)) RETURNS varchar(20) CHARSET utf8 BEGIN SELECT uname FROM USER; RETURN ( SELECT uname FROM USER u WHERE u.uID = id ); END
solve:
CREATE DEFINER=`root`@`localhost` FUNCTION `func_user`(id INT(11)) RETURNS varchar(20) CHARSET utf8 BEGIN DECLARE NAME VARCHAR(30); SELECT uname INTO `name` FROM USER; RETURN ( SELECT uname FROM USER u WHERE u.uID = id ); END
20.3. Call storage function
select Store function name(parameter);
Example:
select func_user(1);
20.4. Storing function parameters
Same as the stored procedure above.
20.5. Delete storage function
DROP FUNCTION IF EXISTS Store function name;
21. mysql scheduled tasks
Since MySQL 5.1.6, a very distinctive function Event Scheduler has been added, which can be used to regularly perform some specific tasks (such as deleting records, summarizing data, data backup, etc.) to replace the work that can only be performed by the scheduled tasks of the operating system. It is worth mentioning that the Event Scheduler of MySQL can execute a task every second, while the scheduled tasks of the operating system (such as cron of Linux or task planning under Windows) can only be executed every minute. It is very suitable for some applications that require high real-time data (such as stocks, odds, scores, etc.).
Event schedulers can sometimes be called temporary Triggers, because event schedulers execute certain tasks based on specific time periods, and Triggers are triggered based on events generated by a table. That's the difference.
21.1 preparation
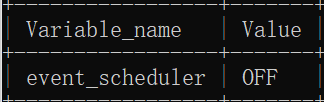
Before using this function, you must ensure that event_ The scheduler is turned on.
You can use this command to query whether it is enabled:
show global variables like 'event_scheduler%';
OFF means OFF, ON means ON.
There are three ways to turn it ON: after it is turned ON, it will become ON.
SET GLOBAL event_scheduler = 1;
In configuration my.cnf Add in the document event_scheduler = 1
SET GLOBAL event_scheduler = ON;
Note: close the event plan: SET GLOBAL event_scheduler = 0;
21.2. Create event
In MySQL version 5.1 and above, you can create events through the CREATE EVENT statement.
CREATE
[DEFINER={user | CURRENT_USER}]
EVENT [IF NOT EXISTS] event_name
ON SCHEDULE schedule
[ON COMPLETION [NOT] PRESERVE]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
DO event_body;
Clause of CREATE EVENT statement:

In the ON SCHEDULE clause, the value of the parameter schedule is an AS clause, which is used to specify that the event occurs at a certain time. Its syntax format is AS follows:
AT timestamp [+ INTERVAL interval] ...
| EVERY interval
[STARTS timestamp [+ INTERVAL interval] ...]
[ENDS timestamp [+ INTERVAL interval] ...]
Parameter Description:
(1) timestamp: indicates a specific time point, followed by a time interval, indicating that the event occurs after this time interval.
(2) EVERY clause: used to indicate how often an event occurs in a specified time interval. The STARTS clause is used to specify the start time; The ENDS clause specifies the end time.
Both starts and ends have interval parameters: it represents a time from now on, and its value consists of a value and unit. For example, use "4 WEEK" to represent 4 weeks; Use '1:10' HOUR_MINUTE to represent 1 hour and 10 minutes. The distance of the interval is in date_ The add() function.
The syntax format of the interval parameter value is as follows:
quantity {YEAR | QUARTER | MONTH | DAY | HOUR | MINUTE |
WEEK | SECOND | YEAR_MONTH | DAY_HOUR | DAY_MINUTE |
DAY_SECOND | HOUR_MINUTE | HOUR_SECOND | MINUTE_SECOND}
Some common time interval settings:
(1) Execute after 5 days
ON SCHEDULE AT CURRENT_TIMESTAMP+INTERVAL 5 DAY
(2) Specify a time period for execution
ON SCHEDULE AT TIMESTAMP '2018-09-17 18:16:00'
(3) Every 5 seconds
ON SCHEDULE EVERY 5 SECOND
(4) Every 1 minute
ON SCHEDULE EVERY 1 MINUTE
(5) Every day at 1 a.m
ON SCHEDULE EVERY 1 DAY STARTS DATE_ADD(DATE_ADD(CURDATE(), INTERVAL 1 DAY), INTERVAL 1 HOUR)
(6) At 1 a.m. on the first day of each month
ON SCHEDULE EVERY 1 MONTH STARTS DATE_ADD(DATE_ADD(DATE_SUB(CURDATE(),INTERVAL DAY(CURDATE())-1 DAY),INTERVAL 1 MONTH),INTERVAL 1 HOUR)
(7) Every three months, a week from now
ON SCHEDULE EVERY 3 MONTH STARTS CURRENT_TIMESTAMP + 1 WEEK
(8) Every twelve hours, starting 30 minutes from now and ending four weeks from now
ON SCHEDULE EVERY 12 HOUR STARTS CURRENT_TIMESTAMP + INTERVAL 30 MINUTE ENDS CURRENT_TIMESTAMP + INTERVAL 4 WEEK
Example 1: create an event_user's event, which is used to send TB to the data table every 5 seconds_ Insert a piece of data into the user information table.
(1) First create tb_user (user information table).
-- Create user information table CREATE TABLE IF NOT EXISTS tb_user ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT 'User number', name VARCHAR(30) NOT NULL COMMENT 'User name', create_time TIMESTAMP COMMENT 'Creation time' ) COMMENT = 'User information table';
(2) Create an event.
-- Create event
CREATE EVENT IF NOT EXISTS event_user
ON SCHEDULE EVERY 5 SECOND
ON COMPLETION PRESERVE
COMMENT 'Add user information scheduled task'
DO INSERT INTO tb_user(name,create_time) VALUES('pan_junbiao Blog',NOW());
Example 2: create an event to count the number of registered members at 1 a.m. on the first day of each month and insert it into the statistics table.
(1) The creation name is p_ The stored procedure of total is used to count the number of registered members and insert it into the statistics table tb_ In total.
CREATE PROCEDURE p_total() BEGIN DECLARE n_total INT default 0; SELECT COUNT(*) INTO n_total FROM db_database11.tb_user; INSERT INTO tb_total (userNumber,createtime) VALUES(n_total,NOW()); END;
(2) The creation name is e_ The event of autototal, which is used to call the stored procedure at 1 a.m. on the first day of each month.
CREATE EVENT IF NOT EXISTS e_autoTotal ON SCHEDULE EVERY 1 MONTH STARTS DATE_ADD(DATE_ADD(DATE_SUB(CURDATE(),INTERVAL DAY(CURDATE())-1 DAY),INTERVAL 1 MONTH),INTERVAL 1 HOUR) ON COMPLETION PRESERVE ENABLE DO CALL p_total();
21.3. Query events
You can query information in MySQL_ Schema.events table to view the created events. The statement is as follows:
SELECT * FROM information_schema.events;
21.4. Modification event
In MySQL 5.1 and later versions, after an event is created, you can also use the ALTER EVENT statement to modify its definition and related properties. The syntax is as follows:
ALTER
[DEFINER={user | CURRENT_USER}]
EVENT [IF NOT EXISTS] event_name
ON SCHEDULE schedule
[ON COMPLETION [NOT] PRESERVE]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
DO event_body;
The ALTER EVENT statement is basically the same as the CREATE EVENT statement. Another use of the ALTER EVENT statement is to close or reactivate an event.
21.5 startup and shutdown events
Another use of the ALTER EVENT statement is to close or reactivate an event.
Example: the startup name is event_user event.
ALTER EVENT event_user ENABLE;
Example: close event_user event.
ALTER EVENT event_user DISABLE;
21.6. Delete event
In MySQL 5.1 and later versions, the DROP EVENT statement can be used to delete the created event.
Example: delete event_user event.
DROP EVENT IF EXISTS event_user;
22. mysql trigger
Trigger is a special type of stored procedure, which is different from stored procedure. It is mainly executed by event triggering, that is, it is not called actively; The stored procedure needs to actively call its name to execute
Trigger: trigger refers to binding a piece of code for a table in advance. When some contents in the table are changed (added, deleted or modified), the system will automatically trigger the code and execute it.
22.1 function
Data can be forcibly verified or converted before writing data (to ensure data security)
When an error occurs in the trigger, the previous successful operations performed by the user will be revoked, similar to the rollback of transactions
22.2. Create trigger
Basic grammar
delimiter Custom end symbol
create trigger Trigger name trigger time trigger event on surface for each row
begin
-- Trigger content body, each line ending with a semicolon
end
Custom end match
delimiter ;
on table for each: trigger object. The essence of trigger binding is all rows in the table. Therefore, when the specified change occurs in each row, the trigger will occur
Trigger time
When an SQL instruction occurs, the data in the row will change, and the corresponding row in each table has two states: before and after data operation
Before: the status before the data in the table changes
After: the status after the data in the table changes
PS: if the before trigger fails or the statement itself fails, the after trigger (if any) will not be executed
Trigger event
Triggers are triggered only when data transmission changes, and the corresponding operations only
INSERT
DELETE
UPDATE
matters needing attention
In MySQL 5, the trigger name must be unique in each table, but not in each database, that is, two tables in the same database may have triggers with the same name
Only one trigger is allowed for each event of each table at a time. Therefore, each table supports up to 6 triggers, before/after insert, before/after delete, and before/after update
example
1. First create two tables, commodity table and order table
CREATE TABLE `goods` ( `id` int(11) NOT NULL COMMENT 'commodity id', `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT 'Trade name', `goods_num` int(11) NULL DEFAULT NULL COMMENT 'stock', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; CREATE TABLE `orders` ( `id` int(11) NOT NULL COMMENT 'order id', `goods_id` int(255) NULL DEFAULT NULL COMMENT 'commodity id', `goods_num` int(255) NULL DEFAULT NULL COMMENT 'Quantity of goods purchased', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT;utf8_general_ci ROW_FORMAT = COMPACT; INSERT INTO `goods` VALUES (1, 'mobile phone', 100); INSERT INTO `goods` VALUES (2, 'computer', 100);
2. If data insertion occurs in the order table, the corresponding commodity inventory should be reduced. Therefore, a trigger is created for the order table
grammar
delimiter ##
-- Create trigger
create trigger after_insert_order after insert on orders for each row
begin
-- Update the inventory of the commodity table. Only the inventory of the first commodity is specified here
update goods set goods_num = goods_num - 1 where id = 1;
end
##
delimiter ;
22.3. View trigger
1. View all triggers
Syntax: show triggers;
If you use a black box connection, you can add \ G for formatting.
show triggers \G;
2. View the creation statement of the trigger
Syntax: show create trigger trigger name;
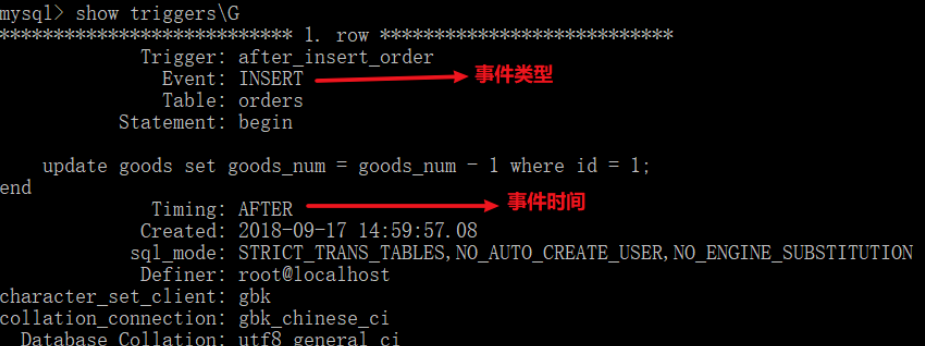
22.4 trigger
The trigger is not triggered automatically or manually, but only after the corresponding event occurs. For example, the trigger we created will execute only when we perform data operations on the order table
We insert data into the orders table to see if a trigger is triggered
First of all, I have black box Chinese garbled code here, which is implemented
set character_set_results=gb2312;
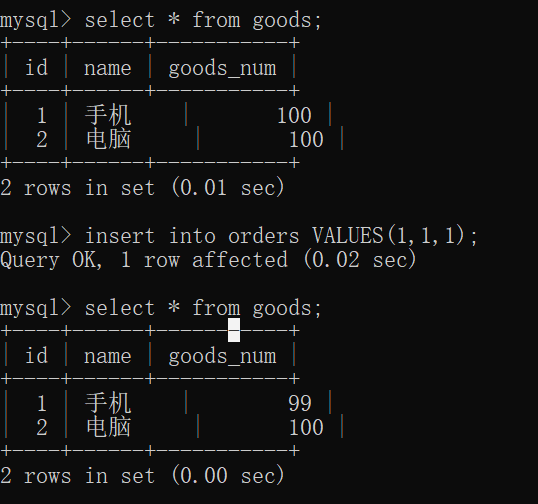
It can be seen that when we insert data into the orders table, the inventory of goods with id 1 in the goods table does change. But there is a problem. Even if we buy five goods with id 1, the corresponding goods table is only reduced by 1
If we buy five goods with id 2, it is also incorrect that only the goods with id 1 in the goods table are changed.
22.5 delete trigger
Triggers cannot be modified, they can only be deleted
Syntax: drop trigger + trigger name
22.6 trigger application
The trigger is for each row of records in the database. Each row of data will have a corresponding state before and after the operation. The trigger saves the state before the operation to the old keyword and the state after the operation to new
Syntax: old/new. Field name
It should be noted that not all triggers of old and new have

Based on this, the trigger for automatically modifying inventory according to the change of order data is re created
delimiter ##
-- Create trigger
create trigger after_insert_order after insert on orders for each row
begin
-- new representative orders New data in table
update goods set goods_num = goods_num - new.goods_num where id = new.goods_id;
end
##
delimiter ;
If you buy five items with id 1, the inventory of the item with id 1 is modified correctly. Of course, if you buy other kinds of goods, the final result is also correct. We won't demonstrate them one by one here
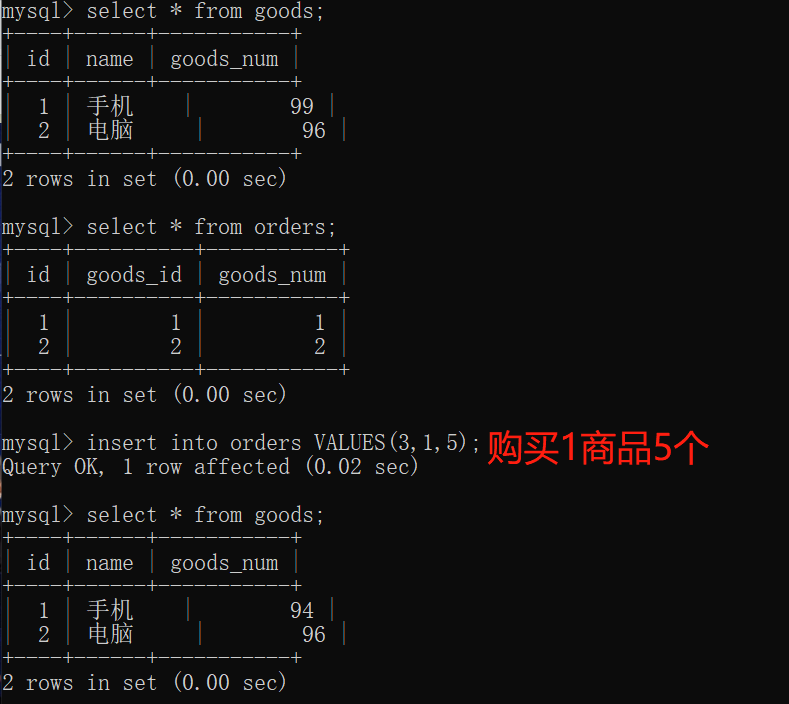
PS
Of course, we also need to consider a situation: if the inventory of goods is insufficient at this time, what should we do?
Here, a trigger is created again and executed before adding a new statement, that is, to verify the inventory. Only after the verification is passed.
delimiter ##
-- Create trigger
create trigger before_insert_order before insert on orders for each row
begin
-- take out goods Corresponding in the table id Inventory of
-- new representative orders New data in table
select goods_num from goods where id = new.goods_id into @num;
-- Use the to be inserted orders Inventory and in table goods Compare the inventory in the table
-- If the inventory is insufficient, the operation is interrupted
if @num < new.goods_num then
-- Interrupt operation: violent resolution, active error
insert into xxx values(xxx);
end if;
end
##
delimiter ;
After creating the trigger, add it again. At this time, you can find that when I add data exceeding the inventory, I directly report an error. If the data cannot be inserted into the orders table, the trigger insert after will not be executed.
At the same time, if an error occurs in the trigger, all the previous operations will be cleared
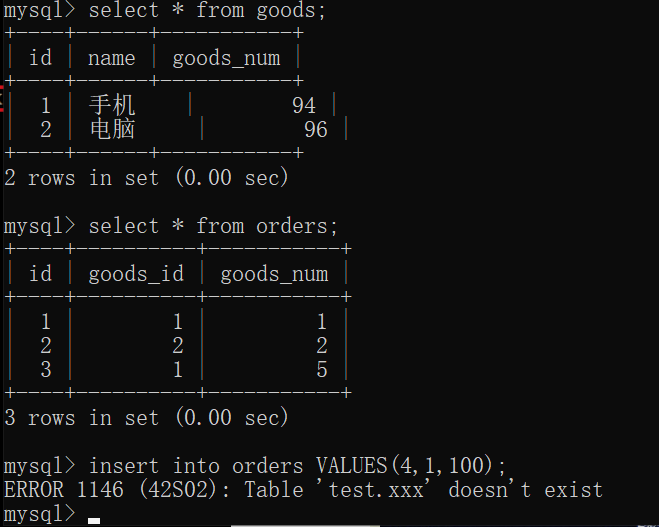
22.7 others
① mysql trigger cannot modify the same table
If I make an update statement during before update, I can update any field in it
delimiter //
create trigger up before update on orders for each row
begin
update orders set goods_id = 10 where id = new.id;
end;
//
delimiter ;
Next, I use the update statement to update the orders table
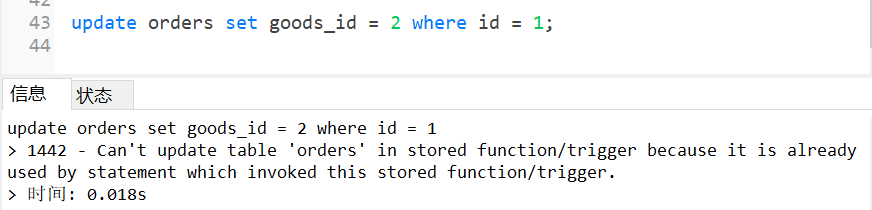
At this time, an error is reported, indicating that the update cannot be performed. After that, I tried to insert and delete in the trigger, and then the same error was reported when updating
Therefore, note: the MySQL trigger cannot perform insert, update and delete operations on this table (this table refers to the table name declared during creation), otherwise an error will be reported.
22.8 advantages and disadvantages
Advantages: triggers can achieve cascading changes through associated tables in the database, that is, changes in the data of one table will affect the data of other tables
It can ensure data security and conduct security verification
Disadvantages: over reliance on triggers will affect the structure of the database and increase the maintenance cost of the database
23. sql optimization
A blog will be specially sorted out in the follow-up meeting. Due to the long length, this article will not be sorted out.