catalogue
1, Overview of master-slave replication and separation of read and write
1. What is read write separation?
2. Why separate reading and writing?
3. When should I separate reading from writing?
4. Master-slave replication and read-write separation
5. Replication types supported by mysq
6. Working process of master-slave replication
7. MySQL master-slave replication delay
8. MySQL read-write separation principle
9. At present, the common MySQL read-write separation can be divided into the following two types:
2, Set up master-slave replication and read-write separation
Master server time synchronization configuration (192.168.255.180)
Time synchronization configuration from server
Configure Amoeba read-write separation and two Slave read-write load balancing
Amoeba server configuration amoeba service
1, Overview of master-slave replication and separation of read and write
1. What is read write separation?
The basic principle of read-write separation is to let the main database handle transactional add, change and DELETE operations (INSERT, UPDATE and DELETE), while the SELECT query operation is processed from the database. Database replication is used to synchronize changes caused by transactional operations to slave databases in the cluster
2. Why separate reading and writing?
Because the "write" (writing 10000 pieces of data may take 3 minutes) operation of the database is time-consuming
But the "read" of the database (it may take only 5 seconds to read 10000 pieces of data)
Therefore, the separation of reading and writing solves the problem that the writing of the database affects the efficiency of query
3. When should I separate reading from writing?
The database does not have to be read-write separated. If the program uses more databases, less updates and more queries, it will be considered. The use of database master-slave synchronization, and then through read-write separation, can share the pressure of the database and improve the performance
4. Master-slave replication and read-write separation
In the actual production environment, the reading and writing of the database are in the same database server, which can not meet the actual needs. Whether in security, high availability or high concurrency, it can not meet the actual needs. Therefore, master-slave replication is used to synchronize data, and then read-write separation is used to improve the concurrent load capacity of the database. It is a bit similar to rsync, but the difference is that rsync backs up disk files, while mysql master-slave replication backs up data and statements in the database
5. Replication types supported by mysq
STATEMENT: STATEMENT based replication. Execute sql statements on the server and the same statements on the slave server. mysql adopts STATEMENT based replication by default, with high execution efficiency
ROW: ROW based replication. Copy the changed content instead of executing the command from the server
MIXED: MIXED type replication. By default, statement based replication is adopted. Once it is found that statement based replication cannot be accurately copied, row based replication will be adopted
6. Working process of master-slave replication
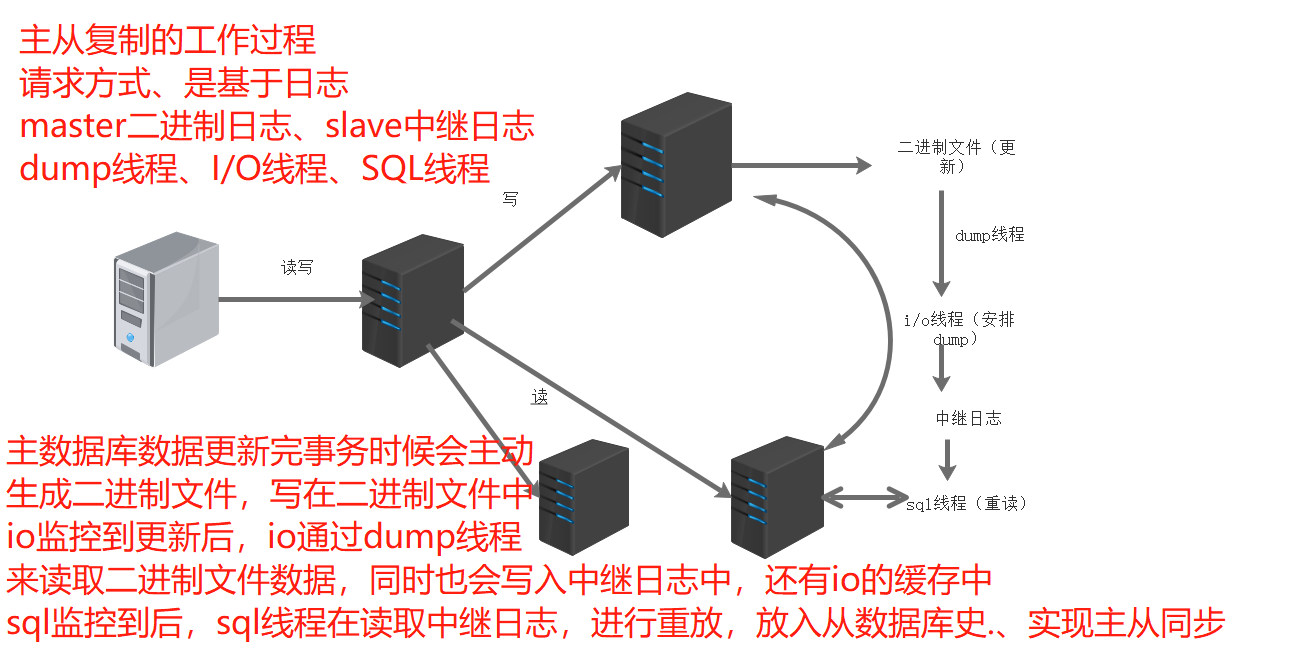 The Master node records the data changes into a bin log. When the data on the Master changes, the changes are written into the bin log
The Master node records the data changes into a bin log. When the data on the Master changes, the changes are written into the bin log
The Slave node will detect whether the binary log of the Master has changed within a certain time interval. If it has changed, it will start an I/O thread to request the binary event of the Master
At the same time, the Master node starts a dump thread for each I/O thread to send binary events to it and save them to the Slave node's local Relay log. The Slave node will start the sql thread to read the binary log from the Relay log and replay it locally, that is, parse it into sql statements and execute them one by one, so that its data is consistent with that of the Master node, Finally, the I/O thread and sql thread will go to sleep and wait for the next wake-up
Note:
Relay logs are usually located in the OS cache, so the overhead of relay logs is very small
There is a very important limitation in the replication process, that is, the replication is serialized on the Slave, that is, the parallel update operation on the Master cannot be operated in parallel on the Slave
7. MySQL master-slave replication delay
The master server is highly concurrent, forming a large number of transactions
Network delay
Caused by master-slave hardware devices
cpu main frequency, memory io, hard disk io
It is not synchronous replication, but asynchronous replication
Optimization:
Optimize Mysql parameters from the library. For example, increase innodb_buffer_pool_size to allow more operations to be completed in Mysql memory and reduce disk operations
Use high-performance hosts from the library. Including strong cpu and increased memory. Avoid using virtual virtual hosts and use physical hosts, which improves i/o
SSD disks are used from the library to optimize the network and avoid synchronization across machine rooms
8. MySQL read-write separation principle
Read write separation is to write only on the master server and read only on the slave server. The basic principle is to let the master database handle transactional operations and the select query from the database. Database replication is used to synchronize changes caused by transactional operations on the master database to the slave database in the cluster
9. At present, the common MySQL read-write separation can be divided into the following two types:
Internal implementation based on program code
In the code, routing is classified according to select and insert, which is also the most widely used method in production environment
The advantage is better performance, because it is implemented in program code, and there is no need to add additional equipment for hardware expenditure; The disadvantage is that it needs developers to implement it, and the operation and maintenance personnel have no way to start
However, not all applications are suitable for realizing read-write separation in program code. For example, some large and complex Java applications, if reading-write separation is realized in program code, the code will be greatly changed
Implementation based on intermediate agent layer
The proxy is generally located between the client and the server. After receiving the client request, the proxy server forwards it to the back-end database through judgment. There are the following representative programs
MySQL-Proxy. MySQL proxy is an open source project of MySQL. SQL judgment is performed through its own lua script
Atlas is a data middle tier project based on MySQL protocol developed and maintained by the infrastructure team of Qihoo 360's Web Platform Department. Based on MySQL proxy version 0.8.2, it optimizes it and adds some new features. The MySQL service run by atlas in 360 carries billions of read and write requests every day. Support things and stored procedures
Amoeba was developed by Chen Siru. The author once worked for Alibaba. The program is developed by the Java language and Alibaba uses it in the production environment. However, it does not support transactions and stored procedures
Because a large number of Lua scripts need to be written to use MySQL Proxy, these Luas are not ready-made, but need to be written by themselves. This is very difficult for people who are not familiar with MySQL Proxy built-in variables and MySQL Protocol
Amoeba is a very easy to use and portable software. Therefore, it is widely used in the agent layer of database in production environment
2, Set up master-slave replication and read-write separation
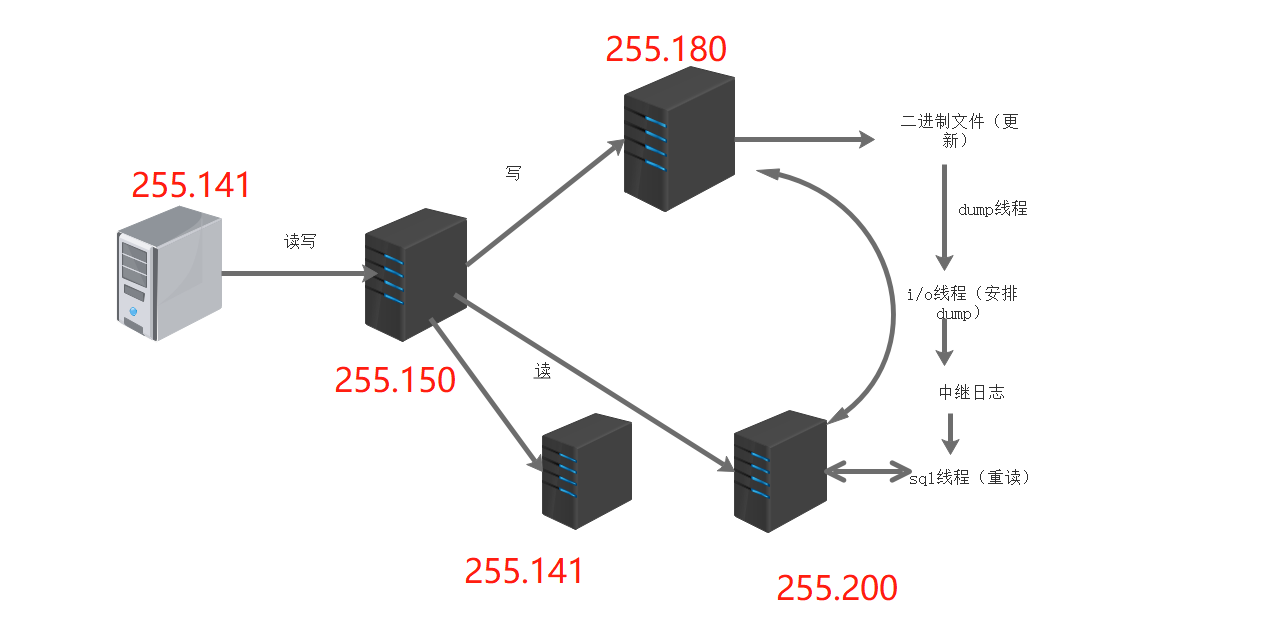
Master server time synchronization configuration (192.168.255.180)
yum -y install ntp vim /etc/ntp.conf Last line add server 127.127.255.0 #Set the local clock source. Pay attention to modifying the network segment fudge 127.127.255.0 stratum 8 #Set the time level to 8 (limited to 15) systemctl start ntpd
Time synchronization configuration from server
yum -y install ntp ntpdate systemctl start ntpd /usr/sbin/ntpdate 192.168.255.180 #Time synchronization, pointing to the Master server IP crontab -e */30 * * * * /usr/sbin/ntpdate 192.168.255.180
Master server profile
vim /etc/my.cnf server_id = 1 log_bin=master-bin #Add, and the primary server opens the binary log log_slave=updates=true #Added to allow binary logs to be updated from the server systemctl restart mysqld mysql -u root -p123456 #Authorize the slave server to copy all tables of all databases (the first account) grant replication slave on *.* to 'myslave'@'192.168.255.%' identified by '123456'; flush privileges; see master Database status show master status\G
Profile from server
vim /etc/my.cnf server-id = 2 #Modify. Note that the id is different from that of the Master, and the IDs of the two Slave should also be different relay-log=relay-log-bin #Add, enable the relay log, and synchronize the log file records from the primary server to the local server relay-log-index=slave-relay-bin.index #Add and define the location and name of the relay log file systemctl restart mysqld mysql -u root -p CHANGE master to master_host='192.168.255.180', master_user='myslave', master_password ='123456', master_log_file='master-bin.000001',master_log_pos=604; #To configure synchronization, pay attention to the master_log_file and Master_ log_ The value of POS should be consistent with that of the Master query. Here is an example. Everyone's is different start slave; #Start synchronization, and execute reset slave in case of error; show slave status\G #View Slave status ensure IO and SQL Threads are Yes,Indicates that the synchronization is normal. Slave_IO_Running: Yes #Responsible for io communication with the host Slave_SQL_Running: Yes #Be responsible for your own slave mysql process #General slave_ IO_ Possibility of running: No: 1,The network is blocked 2,my.cnf There is a problem with the configuration 3,Password file File name pos Incorrect offset 4,The firewall is not turned off
Test master-slave replication
Amoeba server configuration
take jdk-6u14-linux-x64.bin and amoeba-mysql-binary-2.2.0.tar.gz.0 Upload to/opt Directory. cd /opt/ cp jdk-6u14-linux-x64.bin /usr/local/ cd /usr/local/ chmod +x jdk-6u14-linux-x64.bin ./jdk-6u14-linux-x64.bin Press space to the last line Press yes,Press enter mv jdk1.6.0_14/ /usr/local/jdk1.6 vim /etc/profile export JAVA_HOME=/usr/local/jdk1.6 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin export AMOEBA_HOME=/usr/local/amoeba export PATH=$PATH:$AMOEBA_HOME/bin #If any environment variables need to be deleted before source /etc/profile java -version ##install Amoeba Software## mkdir /usr/local/amoeba tar zxvf /opt/amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/ chmod -R 755 /usr/local/amoeba/ /usr/local/amoeba/bin/amoeba //If amoeba start|stop is displayed, the installation is successful
Configure Amoeba read-write separation and two Slave read-write load balancing
First in Master,Slave1,Slave2 of mysql Open permissions to Amoeba visit grant all on *.* to test@'192.168.255.%' identified by '123.com';
Amoeba server configuration amoeba service
cd /usr/local/amoeba/conf/
cp amoeba.xml{,.bak}
vim amoeba.xml #Modify amoeba configuration file
30 modify
<property name="user">amoeba</property>
32 modify
<property name="password">123.com</property>
115 modify
<property name="defaultPool">master</property>
117 Remove comments–
<property name="writePool">master</property>
<property name="readPool">slaves</property>
cp dbServers.xml{,.bak}
vim dbServers.xml #Modify database configuration file
23 modify
<!--<property name="schema">mysql</property> -->
26 modify
<!-- mysql user -->
<property name="user">test</property>
28-30 Remove comments (header) mysql password Notes (don't go)
<property name="password">123.com</property>
45 Modify and set the name of the master server Master
<dbServer name="master" parent="abstractServer">
48 Modify and set the address of the master server
<property name="ipAddress">192.168.255.180</property>
52 Modify to set the name of the slave server slave1
<dbServer name="slave1" parent="abstractServer">
55 Modify and set the address of slave server 1
<property name="ipAddress">192.168.255.141</property>
58 Copy the above 6 lines and paste to set the name from server 2 slave2 And address
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.255.200</property>
65 modify
<dbServer name="slaves" virtual="true">
71 modify
<property name="poolNames">slave1,slave2</property>
/usr/local/amoeba/bin/amoeba start & #Start Amoeba software and press ctrl+c to return
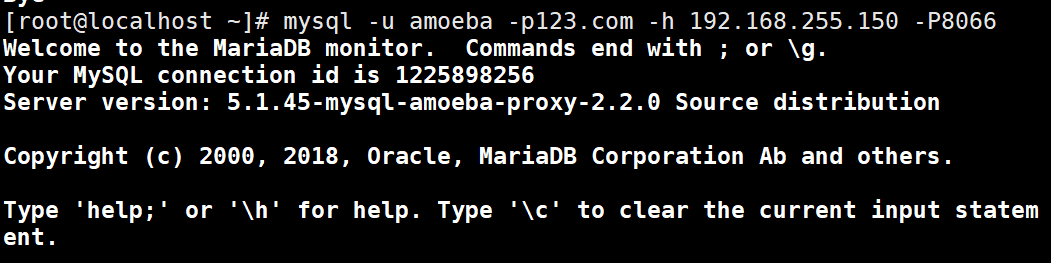
netstat -anpt | grep java #Check whether port 8066 is enabled. The default port is TCP 8066
test
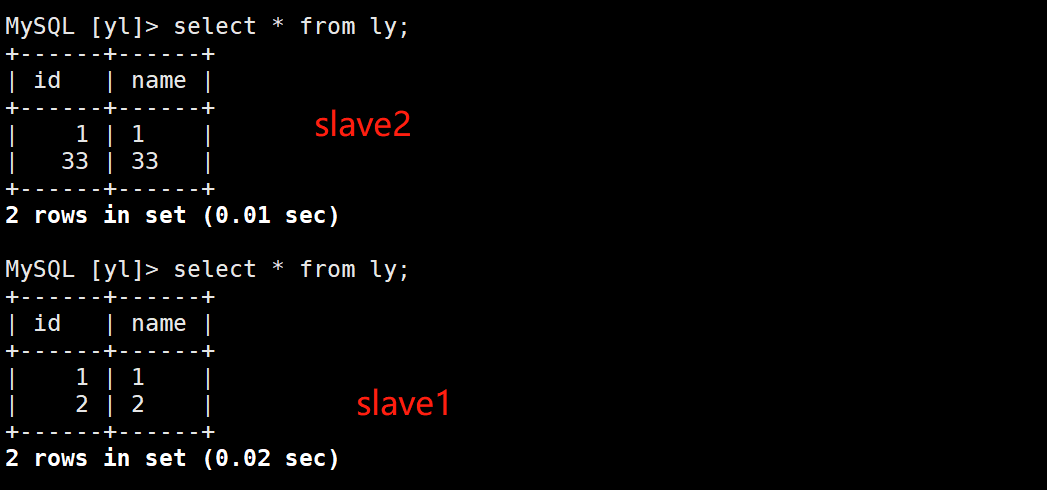
summary
The working process request mode of master-slave replication is based on log master binary log, slave relay log, dump thread, I/O thread and SQL thread
After the master database data is updated, a binary file will be generated and written in the binary file. After io monitors the update, io reads the binary file data through the dump thread and writes it to the relay log and io cache. After sql monitoring, the sql thread reads the relay log, replays it, puts it into the slave database history, and realizes master-slave synchronization