
Tip: the following is the main content of this article. The following cases can be used for reference
1, Introduction
1.1 what are the existing data storage methods?
① Java programs store data (variables, objects, arrays, collections), which are stored in memory and belong to transient state storage.
② File stores data, which is saved on the hard disk and belongs to persistent state
1.2 what are the disadvantages of the above storage methods?
1. There is no distinction between data types.
2. The storage order is small
3. No access security restrictions
4. There is no backup and recovery mechanism
2, Database
2.1 concept
Database is "a warehouse that organizes, stores and manages data according to data structure. It is an organized, shared and uniformly managed data set stored in computers for a long time."
2.2 classification of database
Mesh structure database: IDS(Integrated Data Store) of American General Electric Company, which is stored and accessed in the form of nodes.
Hierarchical database: the IMS (Information Management System) of IBM company has a directional and orderly tree structure to realize storage and access
Relational databases: Oracle, DB2, MySQL and SQL Server, which are stored in tables. Association relationships are established between multiple tables. Access is realized through operations such as classification, merging, connection and selection
Non relational databases: MongDB and Radius use hash tables, which implement specific keys and a pointer to specific data in the form of key value.
ElastercSearch
3, Database management system
3.1 concept
Database management system (DataBase Management System, DBMS): refers to a large-scale software for operating and managing the database, which is used to establish, use and maintain the database, and uniformly manage and control the database to ensure the security and integrity of the database. Users access the data in the database through the DataBase Management System.
3.2 common database management systems
- Oracle: it is considered to be a relatively successful relational database management system in the industry. Oracle database can run on UNIX, Windows and other mainstream operating system platforms, fully support all industrial standards, and obtain the highest level of ISO standard security certification.
- DB2: the product of IBM company. DB2 database system adopts multi process and multi thread architecture. Its function is enough to meet the needs of large and medium-sized companies, and can flexibly serve small and medium-sized e-commerce solutions.
- SQL Server: a relational database management system launched by Microsoft. The utility model has the advantages of convenient use, good scalability and high degree of integration with relevant software.
- SQLLite: a database applied to mobile phones.
4, MySQL
4.1 introduction
MySQL is a relational database management system developed by MySQL ab of Sweden, which is a product of Oracle. MySQL is one of the most popular relational database management systems. In terms of WEB application, MySQL is one of the best RDBMS (Rational Database Management System) application software.
4.2 access and download
Official website: https://www.mysql.com/
Download address: https://dev.mysql.com/downloads/mysql/
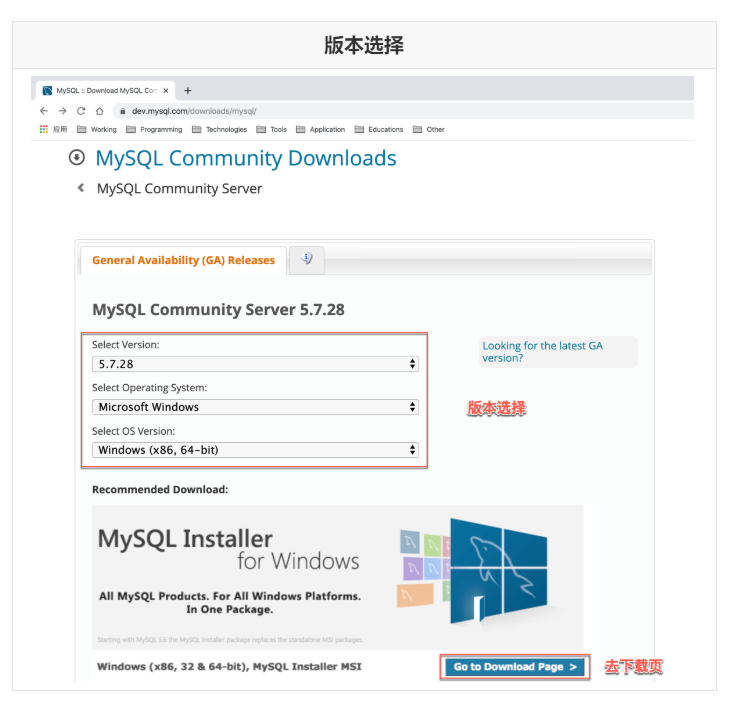
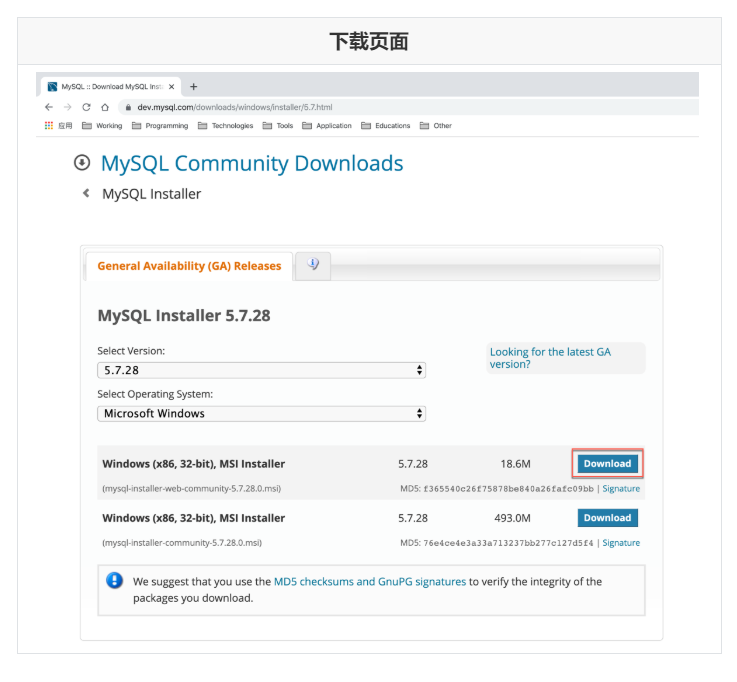
4.3 installation
Run mysql-installer-community-5.7.28.0.msi to enter the installation step
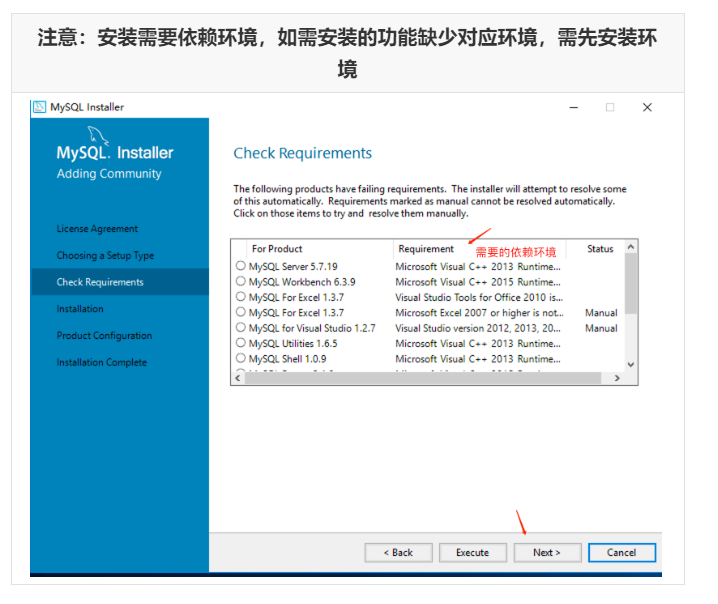
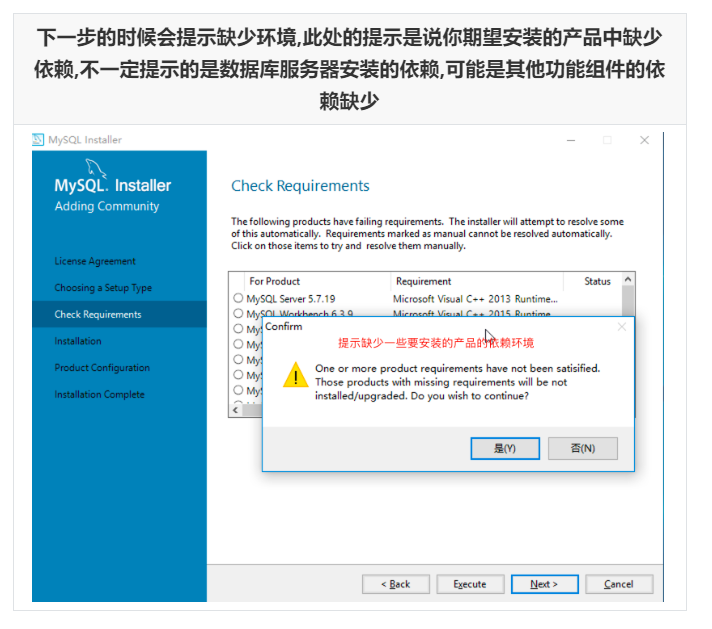
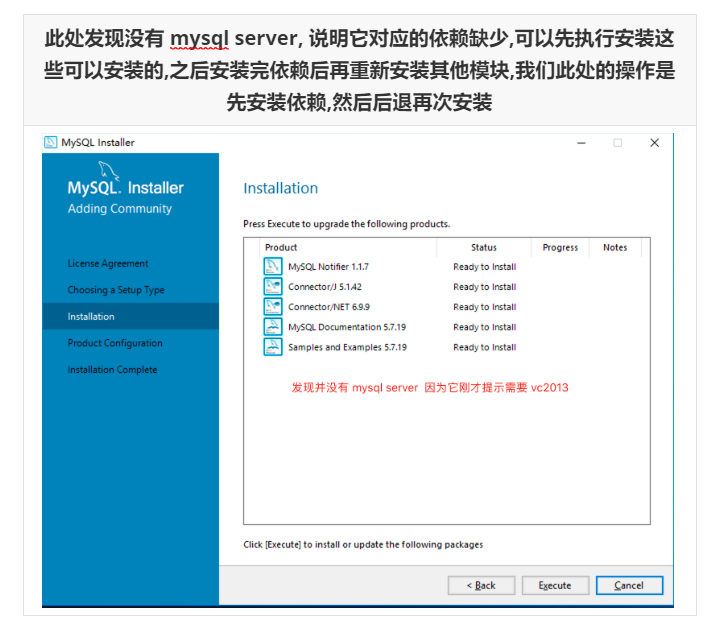
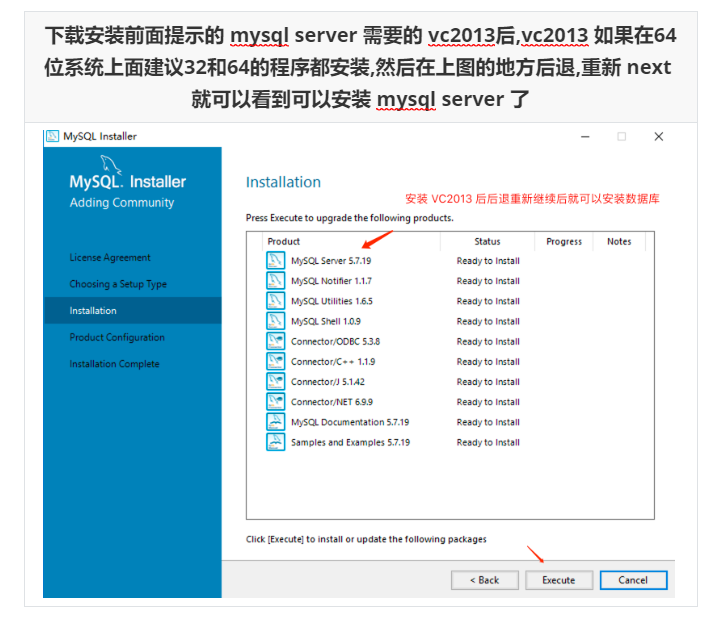
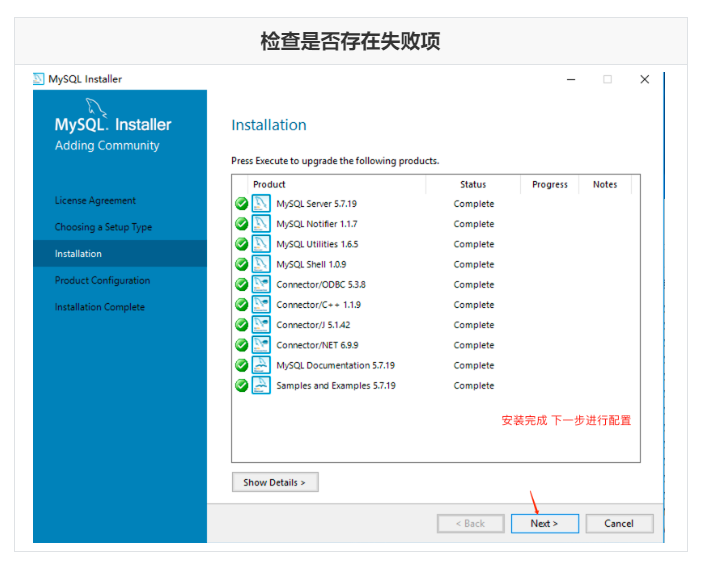
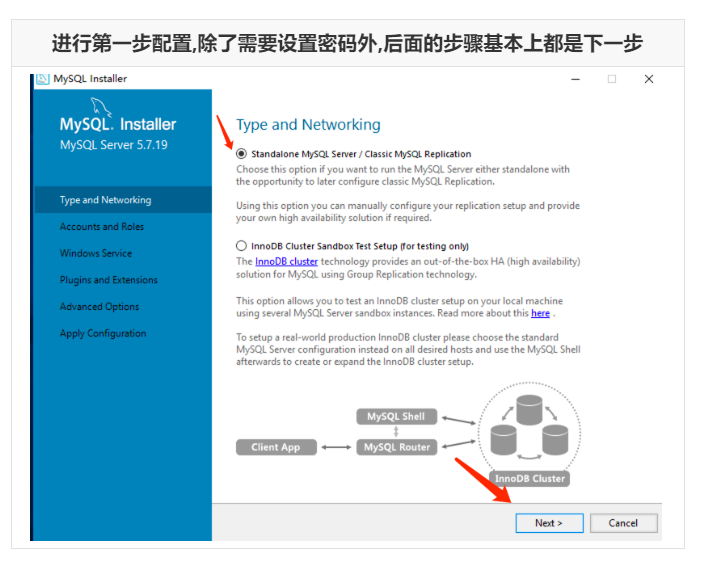
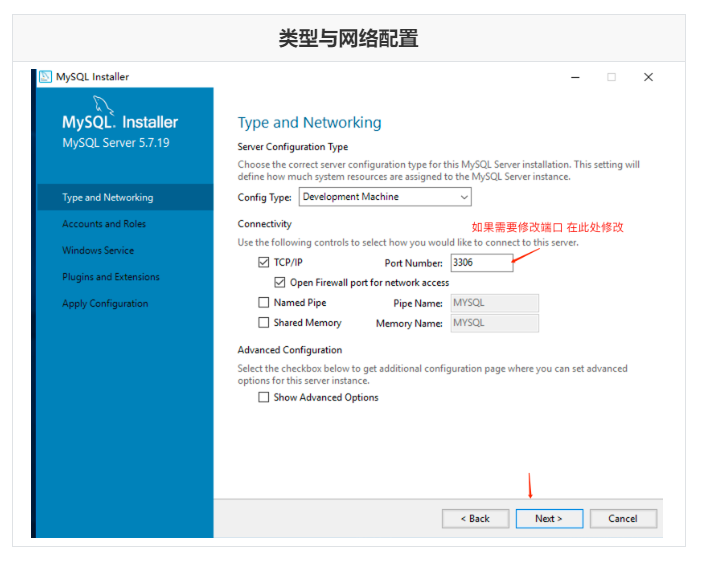
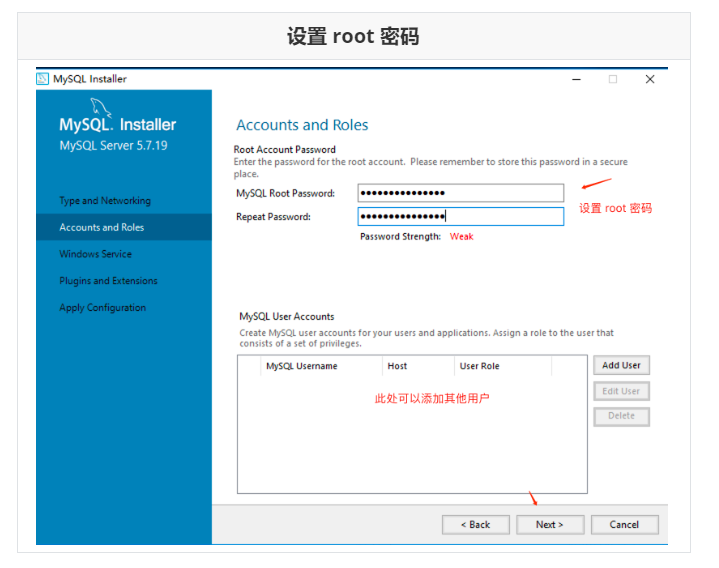
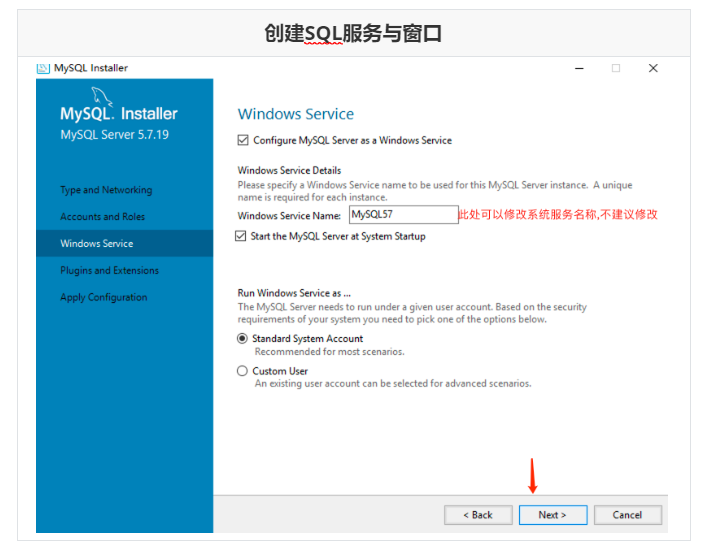
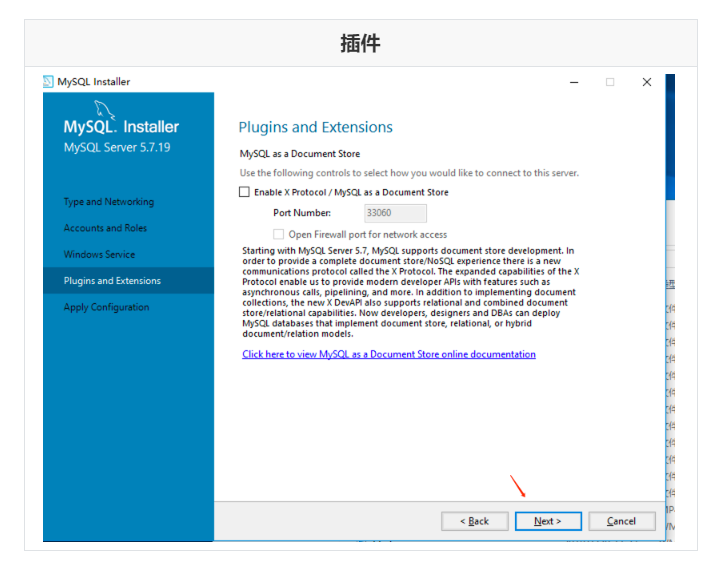
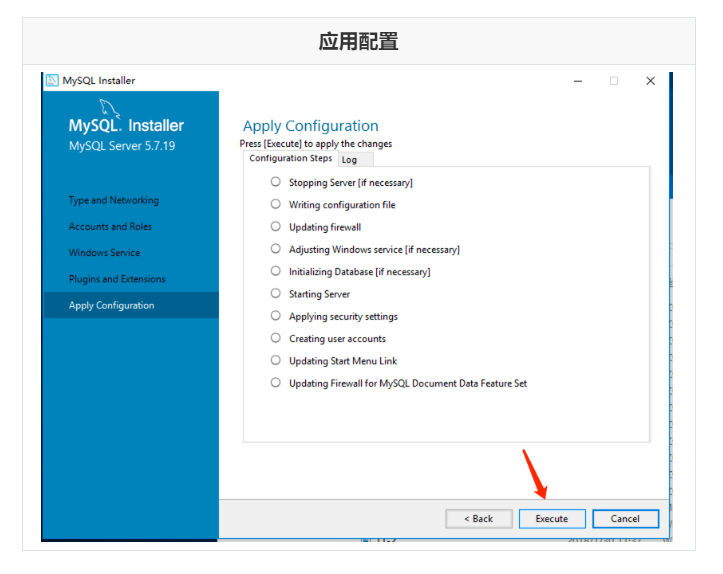
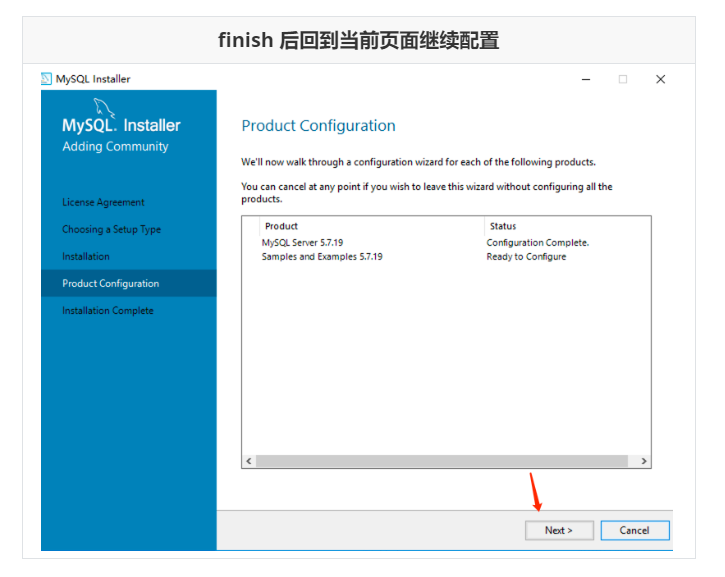
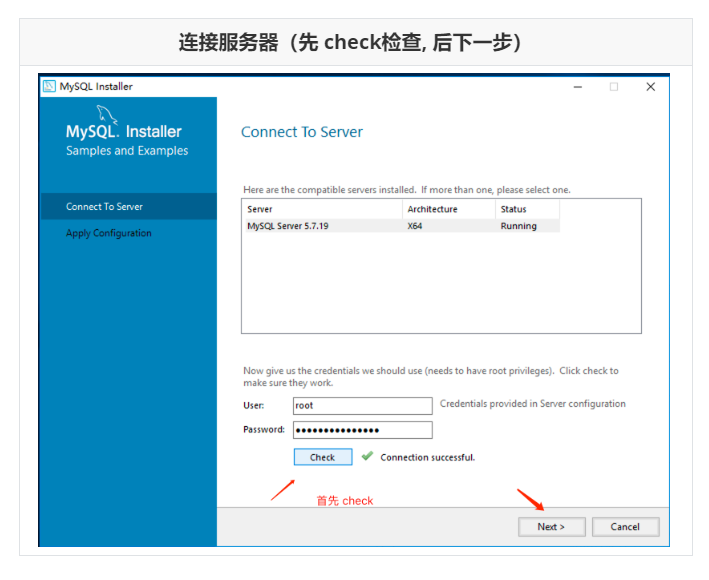
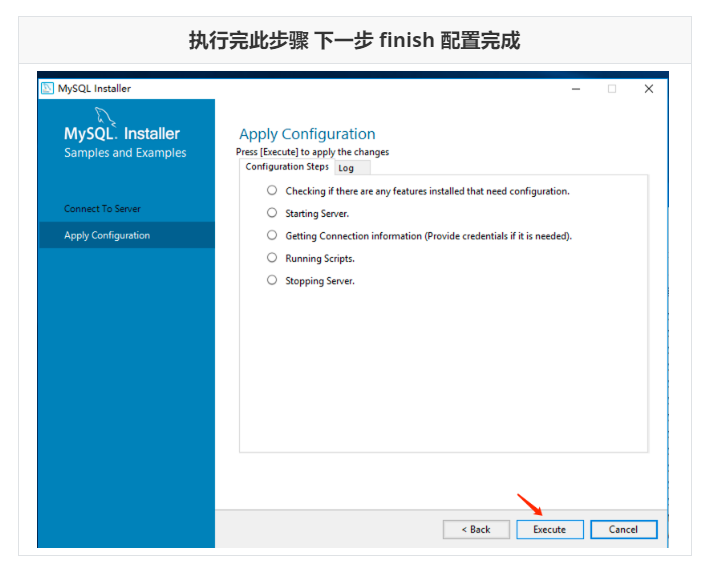
4.4 unloading
- Console uninstall.
- Find the mysql installation directory and delete it.
- programdata delete mysql
- Note: if there is any undeleted MySQL service after uninstallation, you can delete it manually.
- Open the command line as an administrator and enter sc delete MySQL.
4.5 configuring environment variables
- Windows
- Create MYSQL_HOME: C:\Program Files\MySQL\MySQL Server 5.7
- Append PATH:% MYSQL_HOME%\bin;
- MacOS / Linux
- Enter cd ~ in the terminal to enter the directory and check. Bash_ Whether the profile exists, append if any, and create if none
- Create the file touch. Bash_ profile
- Open the file open. Bash_ profile
- Enter export PATH=${PATH}:/usr/local/mysql/bin to save and exit the terminal
4.6 MySQL directory structure
Core document introduction
| Folder name | content |
|---|---|
| bin | Command file |
| lib | Header file |
| include | Library file |
| Share | Character set, language and other information |
4.7 MySQL configuration file
Find the my.ini file in the MySQL installation directory, and open the my.ini file to view several common configuration parameters
| parameter | describe |
|---|---|
| default-character-set | Client default character set |
| character-set-server | Server side default character set |
| port | Client and server port numbers |
| default-storage-engine | MySQL default storage engine INNODB |
5, SQL
5.1 concept
SQL (Structured Query Language) is a programming language for accessing data, updating, querying and managing relational database systems.
5.2 MySQL application
For database operation, you need to enter instructions in the MySQL environment and use them at the end of a sentence; end
5.3 basic commands
View all databases in MySQL
MySQL> SHOW DATABASES; # Displays all databases contained in the current MySQL
| Database name | describe |
|---|---|
| information_schema | Information database, which holds information (metadata) about all databases. Metadata is data about data, such as database name or table name, column data type, or access rights. |
| mysql | The core database is mainly responsible for storing database users, permission settings, keywords, etc, And the control and management information to be used, which cannot be deleted. |
| performance_schema | Performance optimized database, a performance optimized engine added in MySQL version 5.5. |
| sys | System database, a new system database in MySQL 5.7 that can quickly understand metadata information It is convenient to discover the diverse information of the database and solve the performance bottleneck problem. |
Create custom database
mysql> CREATE DATABASE mydb1; #Create mydb database mysql> CREATE DATABASE mydb2 CHARACTER SET gbk; #Create the database and set the encoding format to gbk mysql> CREATE DATABASE mydb3 CHARACTER SET gbk COLLATE gbk_chinese_ci; #Support simplified Chinese and traditional Chinese mysql> CREATE DATABASE IF NOT EXISTS mydb4; #If mydb4 database does not exist, create it; If it exists, it is not created.
View database creation information
mysql> SHOW CREATE DATABASE mydb2; #View basic information when creating a database
modify the database
mysql> ALTER DATABASE mydb2 CHARACTER SET gbk; #View basic information when creating a database
Delete database
mysql> DROP DATABASE mydb1; #Delete database mydb1
View the database currently in use
mysql> select database(); #View the database currently in use
Use database
mysql> USE mydb1; #Using mydb1 database
6, Client tools
6.1Navicate
Navicat is a fast, reliable and affordable database management tool designed to simplify database management and reduce system management costs. Its design meets the needs of database administrators, developers and small and medium-sized enterprises. Navicat is built with an intuitive graphical user interface that allows you to create, organize, access and share information in a safe and easy way.
6.2 SQLyog
MySQL may be the most popular open source database engine in the world, but it may be difficult to manage using text-based tools and configuration files. SQLyog provides a complete graphical interface, and even beginners can easily use the powerful functions of MySQL. It has a wide range of predefined tools and queries, friendly visual interface, query result editing interface similar to Excel and so on.
install
Regular use
Branch execution. sql file
7, Data query [ key ]
7.1 basic structure of database table
Relational structure database is stored in tables, which are composed of "rows" and "columns"
7.2 basic query
Syntax: SELECT column name FROM table name
| keyword | describe |
|---|---|
| SELECT | Specify the columns to query |
| FROM | Specify the table to query |
7.2.1 query part columns
#Query the number, name and email address of all employees in the employee table SELECT employee_id,first_name,email FROM t_employees;
7.2.2 query all columns
#Query all information of all employees in the employee table (all columns) SELECT Column names for all columns FROM t_employees; SELECT * FROM t_employees;
7.2.3 calculate the data in the column
#Query the number, name and annual salary of all employees in the employee table SELECT employee_id , first_name , salary*12 FROM t_employees;
| Arithmetic operator | describe |
|---|---|
| + | Add two columns |
| - | Subtract two columns |
| * | Multiply two columns |
| / | Divide two columns |
Note:% is a placeholder, not a modulo operator.
7.2.4 alias of column
Column as' column name '
#Query the number, name and annual salary of all employees in the employee table (the column names are in Chinese) SELECT employee_id as "number" , first_name as "name" , salary*12 as "Annual salary" FROM t_employees;
7.2.5 de duplication of query results
distinct column name
#Query the ID of all managers in the employee table. SELECT distinct manager_id FROM t_employees;
7.3 Sorting Query
Syntax: SELECT column name FROM table name ORDER BY [sort rule]
| Sorting rules | describe |
|---|---|
| ASC | Sort the front row in ascending order |
| desc | Sort the front row in descending order |
7.3.1 sorting by single column
#Query employee's number, name and salary. Sort by salary in ascending order. SELECT employee_id , first_name , salary FROM t_employees ORDER BY salary DESC;
7.3.2 sorting by multiple columns
#Query employee's number, name and salary. Sort by salary level in ascending order (if the salary is the same, sort by number in ascending order). SELECT employee_id , first_name , salary FROM t_employees ORDER BY salary DESC , employee_id ASC;
7.4 query criteria
Syntax: SELECT column name FROM table name WHERE conditions
| keyword | describe |
|---|---|
| WHERE conditions | In the query results, filter the query results that meet the criteria. The criteria are Boolean expressions |
7.4.1 equivalence judgment (=)
#Query employee information (number, name, salary) with salary of 11000 SELECT employee_id , first_name , salary FROM t_employees WHERE salary = 11000;
Note: unlike java (= =), equivalence judgment is used in mysql=
7.4.2 logical judgment (and, or, not)
#Query employee information (number, name, salary) with salary of 11000 and commission of 0.30 SELECT employee_id , first_name , salary FROM t_employees WHERE salary = 11000 AND commission_pct = 0.30;
7.4.3 unequal judgment (>, <, > =, < =,! =, < >)
#Query the employee information (number, name, salary) whose salary is between 6000 and 10000 SELECT employee_id , first_name , salary FROM t_employees WHERE salary >= 6000 AND salary <= 10000;
7.4.4 between and
#Query the employee information (number, name, salary) whose salary is between 6000 and 10000 SELECT employee_id , first_name , salary FROM t_employees WHERE salary BETWEEN 6000 AND 10000; #Closed interval, including two values of interval boundary
7.4.5 NULL value judgment (IS NULL, IS NOT NULL)
-
IS NULL
Column name IS NULL
-
IS NOT NULL
Column name IS NOT NULL
#Query employee information without commission (No., name, salary, commission) SELECT employee_id , first_name , salary , commission_pct FROM t_employees WHERE commission_pct IS NULL;
7.4.6 enumeration query (IN (value 1, value 2, value 3))
#Query employee information (number, name, salary, department number) with department numbers of 70, 80 and 90 SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE department_id IN(70,80,90); Note: in The query efficiency is low and can be spliced through multiple conditions.
7.4.7 fuzzy query
-
LIKE _ (single arbitrary character)
Column name LIKE 'Zhang'
-
%(any character of any length)
Column LIKE 'Zhang%'
Note: fuzzy query can only be used in combination with LIKE keyword
#Query employee information (number, name, salary, department number) whose name starts with "L" SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE first_name LIKE 'L%'; #Query the employee information (number, name, salary, department number) whose name starts with "L" and length is 4 SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE first_name LIKE 'L___';
7.4.8 branch structure query
CASE WHEN Condition 1 THEN Result 1 WHEN Condition 2 THEN Result 2 WHEN Condition 3 THEN Result 3 END
- Note: by using CASE END for condition judgment, a value is generated for each data.
- Experience: similar to switch in Java.
#Query employee information (No., name, salary, salary level < corresponding condition expression generation >)
SELECT employee_id , first_name , salary , department_id ,
CASE
WHEN salary>=10000 THEN 'A'
WHEN salary>=8000 AND salary<10000 THEN 'B'
WHEN salary>=6000 AND salary<8000 THEN 'C'
WHEN salary>=4000 AND salary<6000 THEN 'D'
ELSE 'E'
END as "LEVEL"
FROM t_employees;
7.5 time query
Syntax: SELECT Time function ([parameter list])
| Time function | describe |
|---|---|
| SYSDATE() | Current system time (day, month, year, hour, minute, second) |
| SYSTIMESTAMP() | Current system time (day, month, year, hour, minute, second) |
| CURDATE() | Get current date |
| CURTIME() | Get current time |
| SELECT WEEK('2012-05-24'); | Gets the week ordinal of the year with the specified date |
| YEAR(DATE) | Gets the year of the specified date |
| HOUR(TIME) | Gets the hour value for the specified time |
| MINUTE(TIME) | Gets the minute value of the time |
| DATEDIFF(DATE1,DATE2) | Gets the number of days between DATE1 and DATE2 |
| ADDDATE(DATE,N) | Calculate DATE plus N days later |
7.5.1 obtaining the current system time
#Query current time SELECT SYSDATE();
#Query current time SELECT NOW();
#Get current date SELECT CURDATE();
#Get current time SELECT CURTIME();
7.6 string query
Syntax: SELECT String function ([parameter list])
| String function | explain |
|---|---|
| CONCAT(str1,str2,str...) | Concatenate multiple strings |
| INSERT(str,pos,len,newStr) | Replace the contents of len length from the specified pos position in str with newStr |
| LOWER(str) | Converts the specified string to lowercase |
| UPPER(str) | Converts the specified string to uppercase |
| SUBSTRING(str,num,len) | Specify the str string to the num position and start intercepting len contents |
7.6.1 string application
#Splicing content
SELECT CONCAT('My','S','QL');
#String substitution
SELECT INSERT('This is a database',3,2,'MySql');#The result is that this is a MySql database
#Convert specified content to lowercase
SELECT LOWER('MYSQL');#mysql
#Convert specified content to uppercase
SELECT UPPER('mysql');#MYSQL
#Specified content interception
SELECT SUBSTRING('JavaMySQLOracle',5,5);#MySQL
7.7 aggregate function
Syntax: SELECT Aggregate function (column name) FROM table name;
| Aggregate function | explain |
|---|---|
| SUM() | Find the sum of single column results in all rows |
| AVG() | average value |
| MAX() | Maximum |
| MIN() | minimum value |
| COUNT() | Find the total number of rows |
7.7.1 single column sum
#Count the total monthly salary of all employees SELECT sum(salary) FROM t_employees;
7.7.2 single column average
#Calculate the average monthly salary of all employees SELECT AVG(salary) FROM t_employees;
7.7.3 maximum value of single column
#Splicing content
SELECT CONCAT('My','S','QL');
7.7.4 minimum value of single column
#Count the lowest monthly salary of all employees SELECT MIN(salary) FROM t_employees;
7.7.5 total number of head offices
#Count the total number of employees SELECT COUNT(*) FROM t_employees;
#Count the number of employees with commission SELECT COUNT(commission_pct) FROM t_employees;
Note: the aggregate function automatically ignores null values and does not perform statistics.
7.8 group query
Syntax: SELECT column name FROM table name WHERE condition GROUP BY (column);
| keyword | explain |
|---|---|
| GROUP BY | Grouping basis must take effect after WHERE |
7.8.1 query the total number of people in each department
#Idea: #1. Grouping by department number (grouping by department_id) #2. count the number of people in each department SELECT department_id,COUNT(employee_id) FROM t_employees GROUP BY department_id;
7.8.2 query the average salary of each department
#Idea: #1. Group by department number (grouping by department_id). #2. Average wage statistics (avg) for each department. SELECT department_id , AVG(salary) FROM t_employees GROUP BY department_id
7.8.3 query the number of people in each department and position
#Idea: #1. Group by department number (grouping by department_id). #2. Group by position name (by job_id). #3. count the number of people for each position in each department. SELECT department_id , job_id , COUNT(employee_id) FROM t_employees GROUP BY department_id , job_id;
7.8.4 common problems
#Query each department id, total number of people and first_name SELECT department_id , COUNT(*) , first_name FROM t_employees GROUP BY department_id; #error
7.9 group filtering query
Syntax: SELECT column name FROM table name WHERE condition GROUP BY group column HAVING filter rules
| keyword | explain |
|---|---|
| HAVING filter rules | Filter rule definitions filter grouped data |
7.9.1 maximum wage of statistical department
#Statistics on the maximum wages of departments 60, 70 and 90 #Idea: #1). Determine grouping basis (department_id) #2). For the grouped data, filter out the information with department numbers of 60, 70 and 90 #3). max() function processing SELECT department_id , MAX(salary) FROM t_employees GROUP BY department_id HAVING department_id in (60,70,90) # group determines the grouping basis department_id #having filtered out 60 70 90 departments #select to view the department number and max function.
7.10 restricted query
SELECT column name FROM table name LIMIT start line, number of query lines
| keyword | explain |
|---|---|
| LIMIT offset_start,row_count | Limit the number of starting rows and total rows of query results |
7.10.1 query the first 5 lines of records
#Query all the information of the top five employees in the table SELECT * FROM t_employees LIMIT 0,5;
7.10.2 query range record
#The query table starts from the third item and queries 10 rows SELECT * FROM t_employees LIMIT 3,10;
7.10.3 typical application of limit
Pagination query: 10 items are displayed on one page, and a total of three pages are queried
#Idea: the first page starts from 0 and displays 10 items SELECT * FROM LIMIT 0,10; #The second page starts with Article 10 and displays 10 articles SELECT * FROM LIMIT 10,10; #The third page starts with 20 items and displays 10 items SELECT * FROM LIMIT 10,10;
7.11 query summary
7.11.1 SQL statement writing sequence
7.11.1 SQL statement writing sequence
1.FROM: Specifies the data source table
2.WHERE: filter the query data for the first time
3.GROUP BY: Group
4.HAVING: filter the grouped data for the second time
5.SELECT: query the value of each field
6.ORDER BY: sort
7.LIMIT: limit query results
7.12 sub query (judged as condition)
SELECT column name FROM table name Where condition (subquery result)
7.12.1 query employee information whose salary is greater than Bruce
#1. First query Bruce's salary (one row and one column) SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce';#The salary is 6000 #2. Query employee information whose salary is greater than Bruce's SELECT * FROM t_employees WHERE SALARY > 6000; #3. Integrate 1 and 2 statements SELECT * FROM t_employees WHERE SALARY > (SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce' );
- Note: take the results of sub query "one row, one column" as the criteria of external query for the second query
- Only the results of a row and a column obtained by a sub query can be used as the equivalence judgment condition of an external query
7.13 sub query (as enumeration query criteria)
SELECT column name FROM table name Where column name In (sub query result);
7.13.1 query employee information of the same department as' King '
#Idea: #one First query the department number of 'King' (multiple lines and single column) SELECT department_id FROM t_employees WHERE last_name = 'King'; //Department No.: 80, 90 #two Then query the employee information of departments 80 and 90 SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE department_id in (80,90); #3.SQL: Consolidation SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE department_id in (SELECT department_id cfrom t_employees WHERE last_name = 'King'); #N rows and one column
7.13.2 information about the owner of the Department whose salary is higher than 60
#1. Query 60 Department owner's salary (multiple rows and columns) SELECT SALARY from t_employees WHERE DEPARTMENT_ID=60; #2. Query the information of employees whose wages are higher than 60 Department owners (higher than all) select * from t_employees where SALARY > ALL(select SALARY from t_employees WHERE DEPARTMENT_ID=60); #. query the information of employees whose wages are higher than 60 departments (higher part) select * from t_employees where SALARY > ANY(select SALARY from t_employees WHERE DEPARTMENT_ID=60);
7.14 sub query (as a table)
SELECT column name FROM (result set of subquery) WHERE conditions;
7.14.1 query the information of the top 5 employees in the employee table
#Idea: #one Sort the salaries of all employees first (temporary table after sorting) select employee_id , first_name , salary from t_employees order by salary desc #two Then query the first 5 rows of employee information in the temporary table select employee_id , first_name , salary from (cursor) where rownum <= 5; #SQL: merging select employee_id , first_name , salary from (select employee_id , first_name , salary from t_employees order by salary desc) //N rows n columns where rownum <= 5;
7.15 consolidated query (understand)
-
SELECT * FROM table name 1 UNION SELECT * FROM table Name2
-
SELECT * FROM table name 1 UNION ALL SELECT * FROM table Name2
7.15.1 results of merging two tables (removing duplicate records)
#Merge the results of two tables to remove duplicate records SELECT * FROM t1 UNION SELECT * FROM t2;
7.15.2 results of merging two tables (keep duplicate records)
#Merge the results of two tables without removing duplicate records (show all) SELECT * FROM t1 UNION ALL SELECT * FROM t2;
Experience: using UNION to merge the result set will remove the duplicate data in the two tables
7.16 table connection query
SELECT column name FROM table 1 Connection mode Table 2 ON connection condition
7.16.1 INNER JOIN ON
#1. Query the information of all employees with departments (excluding employees without departments) MYSQL SELECT * FROM t_employees,t_jobs WHERE t_employees.JOB_ID = t_jobs.JOB_ID #2. Query the SQL standard of all employees with departments (excluding employees without departments) SELECT * FROM t_employees INNER JOIN t_jobs ON t_employees.JOB_ID = t_jobs.JOB_ID
- Experience: in MySql, the first method can also be used as internal connection query, which does not meet the SQL standard
- The second belongs to SQL standard, which is common with other relational databases
7.16.2 three table connection query
#Query the job number, name, department name and country ID of all employees SELECT * FROM t_employees e INNER JOIN t_departments d on e.department_id = d.department_id INNER JOIN t_locations l ON d.location_id = l.location_id
7.16.3 LEFT JOIN ON
#Query all employee information and the corresponding department name (employees without departments are also in the query results, and the Department name is filled with NULL) SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e LEFT JOIN t_departments d ON e.department_id = d.department_id;
- Note: the left outer connection takes the left table as the main table, matches to the right in turn, matches to, and returns the result
- If no match is found, NULL value filling is returned
7.16.4 RIGHT JOIN ON
#Query all department information and all employee information in this department (departments without employees are also in the query results, and the employee information is filled in with NULL) SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e RIGHT JOIN t_departments d ON e.department_id = d.department_id;
- Note: the right outer connection takes the right table as the main table, matches to the left in turn, matches to, and returns the result
- If no match is found, NULL value filling is returned
8, DML operation [ key ]
8.1 add (INSERT)
INSERT INTO Table name (column 1, column 2, column 3...) values (value 1, value 2, value 3...);
8.1.1 add a message
#Add a job information
INSERT INTO t_jobs(JOB_ID,JOB_TITLE,MIN_SALARY,MAX_SALARY) VALUES('JAVA_Le','JAVA_Lecturer',2500,9000);
#Add an employee information
INSERT INTO `t_employees`
(EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID)
VALUES
('194','Samuel','McCain','SMCCAIN', '650.501.3876', '1998-07-01', 'SH_CLERK', '3200', NULL, '123', '50');
8.2 modification (UPDATE)
UPDATE table name SET column 1 = new value 1, column 2 = new value 2,... WHERE condition;
8.2.1 modify a message
#The salary of the employee with modification number 100 is 25000 UPDATE t_employees SET SALARY = 25000 WHERE EMPLOYEE_ID = '100';
#Modify the employee information No. 135 and the position No. is ST_MAN, salary 3500 UPDATE t_employees SET JOB_ID=ST_MAN,SALARY = 3500 WHERE EMPLOYEE_ID = '135';
8.3 DELETE
DELETE FROM table name WHERE condition;
8.3.1 delete a message
#Delete employee number 135 DELETE FROM t_employees WHERE EMPLOYEE_ID='135';
#Delete the employee whose last name is Peter and whose first name is Hall DELETE FROM t_employees WHERE FIRST_NAME = 'Peter' AND LAST_NAME='Hall';
8.4 clear whole table data (TRUNCATE)
TRUNCATE TABLE table name;
8.4.1 empty the whole table
#Empty t_countries entire table TRUNCATE TABLE t_countries;
9, Library table operation
9.1 database creation
CREATE DATABASE Library name;
9.1.1 create database
#Create a database mydb1 CREATE TABLE mydb1;
#Create database specified character encoding set CREATE TABLE mydb1 CHARACTER SET UTF8;
9.2 modify database (ALTER)
ALTER DATABASE Library name operation
9.2.1 modify the character set of the database
#Modify the character set of mydb1 to GBK ALTER DATABASE mydb1 CHRARCTER SET GBK;
9.3 delete database (DROP)
9.3.1 delete database
#Delete mydb1 database DROP DATABASE mydb1;
9.4 data type
MySQL supports many types, which can be roughly divided into three types: numeric, date / time and string (character) types. It is very helpful for us to constrain the type of data
9.4.1 value type
| type | size | Range (signed) | Range (unsigned) | purpose |
|---|---|---|---|---|
| INT or INTEGER | 4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | Large integer value |
| DOUBLE | 8 bytes | (-1.797E+308,-2.22E-308) | (0,2.22E-308,1.797E+308) | Double precision floating point value |
| DOUBLE(M,D) | 8 bytes, M represents length and D represents decimal places | Ibid., subject to M and D, DUBLE(5,2) -999.99-999.99 | Ibid., subject to M and D | Double precision floating point value |
| DECIMAL(M,D) | For DECIMAL(M,D), if M > D, it is M+2, otherwise it is D+2 | Depending on the values of M and D, the maximum value of M is 65 | Depending on the values of M and D, the maximum value of M is 65 | Small value |
9.4.2 date type
| type | size | Range | format | purpose |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | Date value |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | Time value or duration |
| YEAR | 1 | 1901/2155 | YYYY | Year value |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | Mixed date and time values |
| TIMESTAMP | 4 | The ending time of 1970-01-01 00:00:00 / 2038 is 2147483647 seconds, 11:14:07 Beijing time 2038-1-19, 03:14:07 AM GMT on January 19, 2038 | YYYYMMDD HHMMSS | Mixed date and time values, timestamp |
9.4.3 string type
| type | size | purpose |
|---|---|---|
| CHAR | 0-255 characters | Fixed length string char(10) 10 characters |
| VARCHAR | 0-65535 bytes | Variable length string varchar(10) 10 characters |
| BLOB(binary large object) | 0-65 535 bytes | Long text data in binary form |
| TEXT | 0-65 535 bytes | Long text data |
- CHAR and VARCHAR types are similar, but they are saved and retrieved differently. Their maximum length and whether trailing spaces are retained are also different. Case conversion is not performed during storage or retrieval.
- BINARY and VARBINARY classes are similar to CHAR and VARCHAR, except that they contain BINARY strings instead of non BINARY strings. That is, they contain byte strings instead of character strings. This means that they have no character set, and they sort and compare numeric values based on column value bytes.
- BLOB is a large binary object that can hold a variable amount of data. There are four types of blobs: TINYBLOB, BLOB, mediablob and LONGBLOB. They differ only in the maximum length of the value that can be accommodated.
- There are four TEXT types: TINYTEXT, TEXT, mediamtext and LONGTEXT.
9.5 data table creation
Column name data type [constraint],
Column name data type [constraint],
...
Column name data type [constraint] //No comma at the end of the last column
)[charset=utf8] //You can specify the character encoding set of the table as needed
9.5.1 create table
| Listing | data type | explain |
|---|---|---|
| subjectId | INT | Course number |
| subjectName | VARCHAR(20) | Course name |
| subjectHours | INT | Course duration |
#Create a data table according to the above table and insert 3 test statements into the table CREATE TABLE subject( subjectId INT, subjectName VARCHAR(20), subjectHours INT )charset=utf8; INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40); INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(2,'MYSQL',20); INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(3,'JavaScript',30);
- Question: when adding data to the created table, can you add two rows of data with the same column value?
- If feasible, what disadvantages will there be?
10, Restraint
10.1 entity integrity constraints
A row of data in the table represents an entity. The role of entity integrity is to identify that each row of data is not duplicate and the entity is unique.
10.1.1 primary key constraint
PRIMARY KEY It uniquely identifies a row of data in the table. The value of this column cannot be repeated and cannot be NULL
#Add a primary key constraint to the columns in the table that apply the primary key CREATE TABLE subject( subjectId INT PRIMARY KEY,#The course number identifies the unique number of each course and cannot be NULL subjectName VARCHAR(20), subjectHours INT )charset=utf8; INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40); INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40);#error primary key 1 already exists
10.1.2 unique constraints
UNIQUE It is unique and identifies a row of data in the table. It cannot be repeated and can be NULL
#Add unique constraints to columns in the table whose column values do not allow duplicates CREATE TABLE subject( subjectId INT PRIMARY KEY, subjectName VARCHAR(20) UNIQUE,#Course name is unique! subjectHours INT )charset=utf8; INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(1,'Java',40); INSERT INTO subject(subjectId,subjectName,subjectHours) VALUES(2,'Java',40);#error the course name already exists
10.1.3 automatic growth column
AUTO_INCREMENT Automatic growth: add automatic growth to the numeric column of the primary key. Start from 1 and add 1 each time. It cannot be used alone and in combination with the primary key
#Add automatic growth for the primary key column in the table to avoid forgetting the primary key ID sequence number
CREATE TABLE subject(
subjectId INT PRIMARY KEY AUTO_INCREMENT,#The course number is a primary key and grows automatically. It will start from 1 and add 1 according to the order of adding data
subjectName VARCHAR(20) UNIQUE,
subjectHours INT
)charset=utf8;
INSERT INTO subject(subjectName,subjectHours) VALUES('Java',40);#Course number automatically increases from 1
INSERT INTO subject(subjectName,subjectHours) VALUES('JavaScript',30);#Article 2 is numbered 2
10.2 domain integrity constraints
Limits the data correctness of the cells in the column.
10.2.1 non null constraints
NOT NULL Non empty, this column must have a value.
#Although a unique constraint is added to the course name, it is possible that a NULL value exists. Avoid making the course name NULL CREATE TABLE subject( subjectId INT PRIMARY KEY AUTO_INCREMENT, subjectName VARCHAR(20) UNIQUE NOT NULL, subjectHours INT )charset=utf8; INSERT INTO subject(subjectName,subjectHours) VALUES(NULL,40);#error, the course name constraint is not empty
10.2.2 default value constraints
default value Give a DEFAULT value to the column. When no value is specified for the new data, write DEFAULT and fill it with the specified DEFAULT value
#When storing course information, if the course duration has no specified value, it will be filled in with the default class hour 20
CREATE TABLE subject(
subjectId INT PRIMARY KEY AUTO_INCREMENT,
subjectName VARCHAR(20) UNIQUE NOT NULL,
subjectHours INT DEFAULT 20
)charset=utf8;
INSERT INTO subject(subjectName,subjectHours) VALUES('Java',DEFAULT);#The course duration is populated with the default value of 20
10.2.3 referential integrity constraints
-
Detailed explanation: FOREIGN KEY refers to the value of a column in the external table. When adding data, the value constraining this column must be the value existing in the reference table.
#Create specialty table
CREATE TABLE Speciality(
id INT PRIMARY KEY AUTO_INCREMENT,
SpecialName VARCHAR(20) UNIQUE NOT NULL
)CHARSET=utf8;
#Create a curriculum (the SpecialId of the curriculum refers to the ID of the specialty table)
CREATE TABLE subject(
subjectId INT PRIMARY KEY AUTO_INCREMENT,
subjectName VARCHAR(20) UNIQUE NOT NULL,
subjectHours INT DEFAULT 20,
specialId INT NOT NULL,
CONSTRAINT fk_subject_specialId REFERENCES Speciality(id) #Reference the id in the specialty table as the foreign key. When adding course information, the specialty of the course will be constrained.
)charset=utf8;
#New data in specialty table
INSERT INTO Speciality(SpecialName) VALUES('Java');
INSERT INTO Speciality(SpecialName) VALUES('C#');
#Add data to course information table
INSERT INTO subject(subjectName,subjectHours) VALUES('Java',30,1);#The specialty id is 1, which refers to the Java of the specialty table
INSERT INTO subject(subjectName,subjectHours) VALUES('C#MVC',10,2);#major id Is 2, which refers to the professional table C#
10.3 constraint creation and integration
Create a table with constraints.
10.3.1 create table
| Listing | data type | constraint | explain |
|---|---|---|---|
| GradeId | INT | Primary key, auto growth | Class number |
| GradeName | VARCHAR(20) | Unique, non empty | Class name |
CREATE TABLE Grade( GradeId INT PRIMARY KEY AUTO_INCREMENT, GradeName VARCHAR(20) NOT NULL )CHARSET=UTF8;
| Listing | data type | constraint | explain |
|---|---|---|---|
| student_id | VARCHAR(50) | Primary key | Student number |
| Student_name | VARCHAR(50) | Non empty | full name |
| sex | CHAR(2) | Default fill 'male' | Gender |
| borndate | DATE | Non empty | birthday |
| phone | VARCHAR(11) | nothing | Telephone |
| GradeId | INT | Non empty, foreign key constraint: refers to the gradeid of the class table. | Class number |
CREATE TABLE student( student_id varchar(50) PRIMARY KEY, student_name varchar(50) NOT NULL, sex CHAR(2) DEFAULT 'male' borndate date NOT NULL, phone varchar(11), gradeId int not null, CONSTRAINT fk_student_gradeId REFERENCES Grade(GradeId) #Reference the value of the GradeId column of the Grade table as the foreign key. The class number of the constrained students must exist when inserting. );
- Note: when creating a relational table, you must first create a master table and then create a slave table
- When deleting a relational table, first delete the secondary table, and then delete the primary table.
10.4 modification of data sheet (ALTER)
ALTER TABLE table name operation;
10.4.1 adding columns to an existing table
#Add image column to student table ALTER TABLE student ADD image blob;
10.4.2 modify the columns in the table
#Modify the mobile phone number in the student table. It is not allowed to be empty ALTER TABLE student MODIFY Phone VARCHAR(11) NOT NULL;
10.4.3 delete columns in the table
#Delete image column in student table ALTER TABLE student DROP image;
Note: when deleting columns, only one column can be deleted at a time
10.4.4 modifying column names
#Modify the border column in the student table as birthday ALTER TABLE student CHANGE borndate birthday date NOT NULL;
10.4.5 modify table name
#Change the student of the student table to stu ALTER TABLE student TO stu;
10.5 deletion of data sheet (DROP)
DROP TABLE table name
10.5.1 delete student table
#Delete student table DROP TABLE stu;
11, Affairs [ key ]
11.1 simulated transfer
In life, transfer is to deduct money from the transferor's account and add money to the receiver's account. We use database operations to simulate real transfers
11.1.1 database simulation transfer
#Account A transfers 1000 yuan to account B. #Account A minus 1000 yuan UPDATE account SET MONEY = MONEY-1000 WHERE id=1; #Account B plus 1000 yuan UPDATE account SET MONEY = MONEY+1000 WHERE id=2;
The above code completes the transfer operation between two accounts.
11.1.2 analog transfer error
#Account A transfers 1000 yuan to account B. #Account A minus 1000 yuan UPDATE account SET MONEY = MONEY-1000 WHERE id=1; #Power failure, exception, error #Account B plus 1000 yuan UPDATE account SET MONEY = MONEY+1000 WHERE id=2;
- If there is an exception in the above code after the subtraction operation or an error in the money addition statement, it will be found that the money reduction is still successful and the money addition fails!
- Note: each SQL statement is an independent operation, and the execution of an operation has a permanent impact on the database.
11.2 concept of transaction
A transaction is an atomic operation. Is a minimum execution unit. It can be composed of one or more SQL statements. In the same transaction, when all SQL statements are successfully executed, the whole transaction succeeds. If one SQL statement fails, the whole transaction fails.
11.3 boundaries of transactions
-
Start: the first addition, deletion and modification statement after the end of the previous transaction, that is, the start of the transaction.
-
end:
1). Submission:
a. show submission: commit;
b. implicit submission: a statement created or deleted, and normal exit (the client exits the connection);
2). Rollback:
a. show rollback: rollback;
b. implicit rollback: abnormal exit (power failure, Down machine), execute the create and delete statements, but fail, and rollback will be executed for this invalid statement.
11.4 principle of transaction
The database will maintain a spatially independent cache (rollback segment) for each client. The execution results of all add, delete and modify statements in a transaction will be cached in the rollback segment. Only when all SQL statements in the transaction are commit ted, the data in the rollback segment will be synchronized to the database. Otherwise, the whole transaction will be rolled back no matter what reason it fails.
11.5 characteristics of transactions
Indicates that all operations within a transaction are a whole, either all successful or all failed
Indicates that when an operation fails in a transaction, all changed data must be rolled back to the state before modification
A transaction views the state of data during data operation, either before another concurrent transaction modifies it or after another transaction modifies it. A transaction will not view the data in the intermediate state.
After a persistent transaction is completed, its impact on the system is permanent.
11.6 transaction application
Application environment: Based on the operation results of addition, deletion and modification statements (all return the number of rows affected after the operation), transaction submission or rollback can be manually controlled through program logic
11.6.1 transaction completion and transfer
#Transfer from account A to account B. #1. Start transaction START TRANSACTION;|setAutoCommit=0;#Disable automatic submission setAutoCommit=1;#Turn on auto submit #2. Intra transaction data operation statement UPDATE ACCOUNT SET MONEY = MONEY-1000 WHERE ID = 1; UPDATE ACCOUNT SET MONEY = MONEY+1000 WHERE ID = 2; #3. If all statements in the transaction are successful, execute COMMIT; COMMIT; #4. If an error occurs in the transaction, execute ROLLBACK; ROLLBACK;
12, Authority management
12.1 creating users
CREATE USER user name IDENTIFIED BY password
12.1.1 create a user
#Create a zhangsan user CREATE USER `zhangsan` IDENTIFIED BY '123';
12.2 authorization
GRANT ALL ON Database. Tables TO user name;
12.2.1 user authorization
#Grant permissions to all tables under companyDB to zhangsan GRANT ALL ON companyDB.* TO `zhangsan`;
12.3 revocation of authority
REVOKE ALL ON Database. Table name TO user name
12.3.1 revoke user permission
#Revoke the permission of zhangsan's companyDB REVOKE ALL ON companyDB.* FROM `zhangsan`;
12.4 delete user
DROP USER user name
12.4.1 delete user
#Delete user zhangsan DROP USER `zhangsan`;
13, View
13.1 concept
A view, a virtual table, is a table queried from one or more tables. Its function is the same as that of a real table. It contains a series of data with rows and columns. In the view, the user can use the SELECT statement to query data, or use INSERT, UPDATE and DELETE to modify records. The view can facilitate the user's operation and ensure the security of the database system.
13.2 view features
-
advantage
- Simplification, data WYSIWYG.
- Security, users can only query or modify the data they can see.
- Logical independence can shield the impact of real table structure changes.
-
shortcoming
- The performance is relatively poor, and simple queries will become slightly more complex.
- It's inconvenient to modify. The special change is a complex aggregate view, which can't be modified basically.
13.3 view creation
Syntax: CREATE VIEW view name AS Query data source table statement;
13.3.1 creating views
#Create t_ View of empinfo, whose view is from t_ Employee number, employee name, employee email and salary can be queried in the employees table CREATE VIEW t_empInfo AS SELECT EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,SALARY from t_employees;
13.3.2 use view
#Query t_ Employee information numbered 101 in empinfo view SELECT * FROM t_empInfo where employee_id = '101';
13.4 modification of view
-
Mode 1: CREATE OR REPLACE VIEW View name AS query statement
-
Mode 2: ALTER VIEW View name AS query statement
13.4.1 modify view
#Method 1: if the view exists, modify it; otherwise, create it CREATE OR REPLACE VIEW t_empInfo AS SELECT EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,SALARY,DEPARTMENT_ID from t_employees; #Method 2: modify the existing view directly ALTER VIEW t_empInfo AS SELECT EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,SALARY from t_employees;
13.5 deletion of view
DROP VIEW View name
13.5.1 delete view
#Delete t_empInfo view DROP VIEW t_empInfo;
13.6 precautions for view
be careful:
- The view does not store data independently. The original table changes and the view also changes. No query performance was optimized.
- If the view contains one of the following structures, the view is not updatable
- Result of aggregate function
- DISTINCT results after de duplication
- GROUP BY results after grouping
- HAVING filtered results
- UNION, UNION ALL combined results
14, SQL language classification
Data Query Language (DQL): select, where, order by, group by, having.
. Data Definition Language (DDL): create, alter, drop.
. Data Manipulation Language (DML): insert, update, delete
. Transaction Process Language (TPL): commit and rollback
. Data Control Language (DCL): grant, revoke.
15, Comprehensive exercise
The database table structure of an online mall is as follows:
# Create user table
create table user(
userId int primary key auto_increment,
username varchar(20) not null,
password varchar(18) not null,
address varchar(100),
phone varchar(11)
);
#Create classification table
create table category(
cid varchar(32) PRIMARY KEY ,
cname varchar(100) not null #Classification name
);
# Commodity list
CREATE TABLE `products` (
`pid` varchar(32) PRIMARY KEY,
`name` VARCHAR(40) ,
`price` DOUBLE(7,2),
category_id varchar(32),
constraint foreign key(category_id) references category(cid)
);
#Order form
create table `orders`(
`oid` varchar(32) PRIMARY KEY ,
`totalprice` double(12,2), #total
`userId` int,
constraint foreign key(userId) references user(userId) #Foreign key
);
# Order item table
create table orderitem(
oid varchar(32), #Order id
pid varchar(32), #Commodity id
num int , #Quantity of goods purchased
primary key(oid,pid), #Primary key
foreign key(oid) references orders(oid),
foreign key(pid) references products(pid)
);
#-----------------------------------------------
#Initialization data
#Add data to user table
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('Zhang San','123','Shahe, Changping, Beijing','13812345678');
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('Wang Wu','5678','Haidian, Beijing','13812345141');
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('Zhao Liu','123','Chaoyang, Beijing','13812340987');
INSERT INTO USER(username,PASSWORD,address,phone) VALUES('pseudo-ginseng','123','Beijing Daxing','13812345687');
#Initialize data for item table
insert into products(pid,name,price,category_id) values('p001','association',5000,'c001');
insert into products(pid,name,price,category_id) values('p002','Haier',3000,'c001');
insert into products(pid,name,price,category_id) values('p003','Thor',5000,'c001');
insert into products(pid,name,price,category_id) values('p004','JACK JONES',800,'c002');
insert into products(pid,name,price,category_id) values('p005','jeanswest ',200,'c002');
insert into products(pid,name,price,category_id) values('p006','dandy',440,'c002');
insert into products(pid,name,price,category_id) values('p007','Jin Ba',2000,'c002');
insert into products(pid,name,price,category_id) values('p008','Chanel',800,'c003');
insert into products(pid,name,price,category_id) values('p009','Affordable materia medica',200,'c003');
insert into products(pid,name,price,category_id) values('p010','Mei Mingzi',200,null);
#Initialize data for classification table
insert into category values('c001','an electric appliance');
insert into category values('c002','Clothes & Accessories');
insert into category values('c003','Cosmetics');
insert into category values('c004','book');
#Add order
insert into orders values('o6100',18000.50,1);
insert into orders values('o6101',7200.35,1);
insert into orders values('o6102',600.00,2);
insert into orders values('o6103',1300.26,4);
#Order details sheet
insert into orderitem values('o6100','p001',1),('o6100','p002',1),('o6101','p003',1);
15.1 comprehensive exercise 1 - [ multi table query ]
1> Query orders of all users
SELECT o.oid,o.totalprice, u.userId,u.username,u.phone FROM orders o INNER JOIN USER u ON o.userId=u.userId;
2> Query all order details with user id 1
SELECT o.oid,o.totalprice, u.userId,u.username,u.phone ,oi.pid FROM orders o INNER JOIN USER u ON o.userId=u.userId INNER JOIN orderitem oi ON o.oid=oi.oid where u.userid=1;
15.2 comprehensive exercise 2 - [ sub query ]
1> View orders for Zhang San
SELECT * FROM orders WHERE userId=(SELECT userid FROM USER WHERE username='Zhang San');
2> Query all user information whose order price is greater than 800.
SELECT * FROM USER WHERE userId IN (SELECT DISTINCT userId FROM orders WHERE totalprice>800);
summary
Tip: here is a summary of the article:
For example, the above is what we want to talk about today. This paper only briefly introduces the use of pandas, which provides a large number of functions and methods that enable us to process data quickly and conveniently.