Statement: the content of this blog is sorted out from Datawhale's punch in learning, and sorted into notes according to the punch in content. For reprint, please contact Datawhale and my authorization, and the reprint source must be indicated.
Chapter 3 more complex queries
The first two punch in notes introduced the basic query usage of SQL. Let's review the content first.
Content review:
MySQL: setting up the environment, getting to know the database for the first time -- Datawhale's first punch in notes
MySQL: basic query and sorting - Datawhale's second punch in note
3.1 view
On the surface, this statement is exactly the same as the normal query of data from the data table, but in fact, we operate a view. Therefore, from the perspective of SQL, the operation view and the operation table look exactly the same, so why is there a view? What is a view? How are views different from tables?
3.1.1 what is a view
A view is a virtual table, which is different from a direct operation data table. A view is created based on a SELECT statement (which will be described in detail below). Therefore, when operating a view, a virtual table will be generated according to the SELECT statement that created the view, and then SQL operations will be performed on this virtual table.
The second edition of SQL basic tutorial succinctly summarizes the difference between view and table - "whether the actual data is saved". Therefore, the view is not the data table actually stored in the database. It can be regarded as a window through which we can see the real data in the database table. Therefore, we should distinguish the essence of view and data table, that is, view is a virtual table based on real table, and its data sources are based on real table.
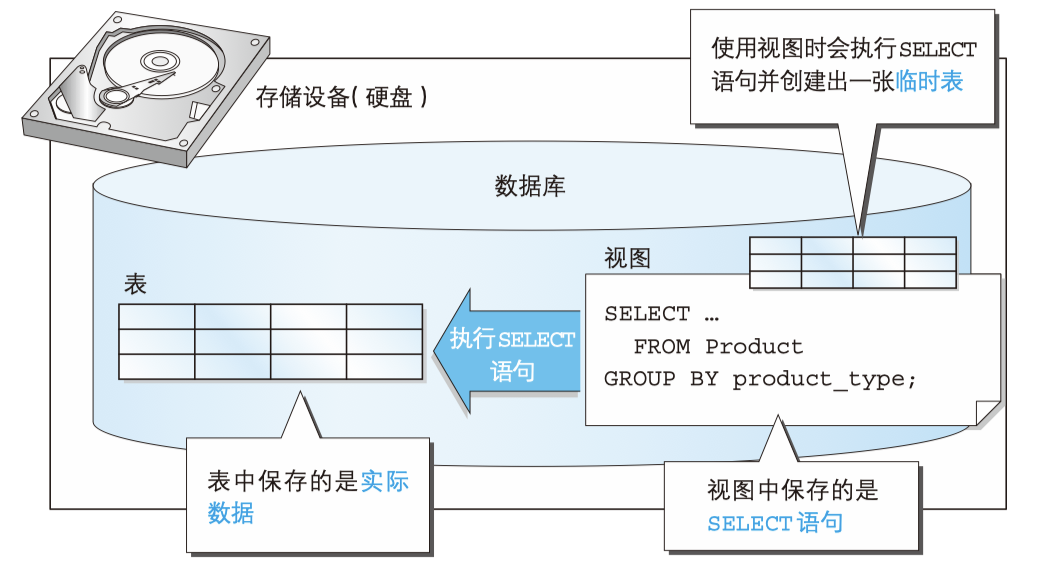
Image source: sql foundation tutorial version 2
The following doggerel is also convenient for you to remember the relationship between view and table: "view is not a table, view is a virtual table, and view depends on table".
3.1.3 why are there views
Now that you have a data table, why do you need a view? The main reasons are as follows:
- By defining views, you can save frequently used SELECT statements to improve efficiency.
- By defining views, users can see data more clearly.
- By defining the view, you can not disclose all the fields of the data table, so as to enhance the confidentiality of the data.
- Data redundancy can be reduced by defining views.
3.1.4 how to create a view
After talking about the differences between views and tables, let's take a look at how to create views.
The basic syntax for creating a view is as follows:
CREATE VIEW <View name>(<Column name 1>,<Column name 2>,...) AS <SELECT sentence>
The SELECT statement needs to be written after the AS keyword. The columns in the SELECT statement are arranged in the same order AS the columns in the view. The first column in the SELECT statement is the first column in the view, the second column in the SELECT statement is the second column in the view, and so on. Moreover, the column name of the view is defined in the list after the view name. It should be noted that the view name must be unique in the database and cannot be the same AS other views and tables.
Views can not only be based on real tables, but we can also continue to create views based on views.
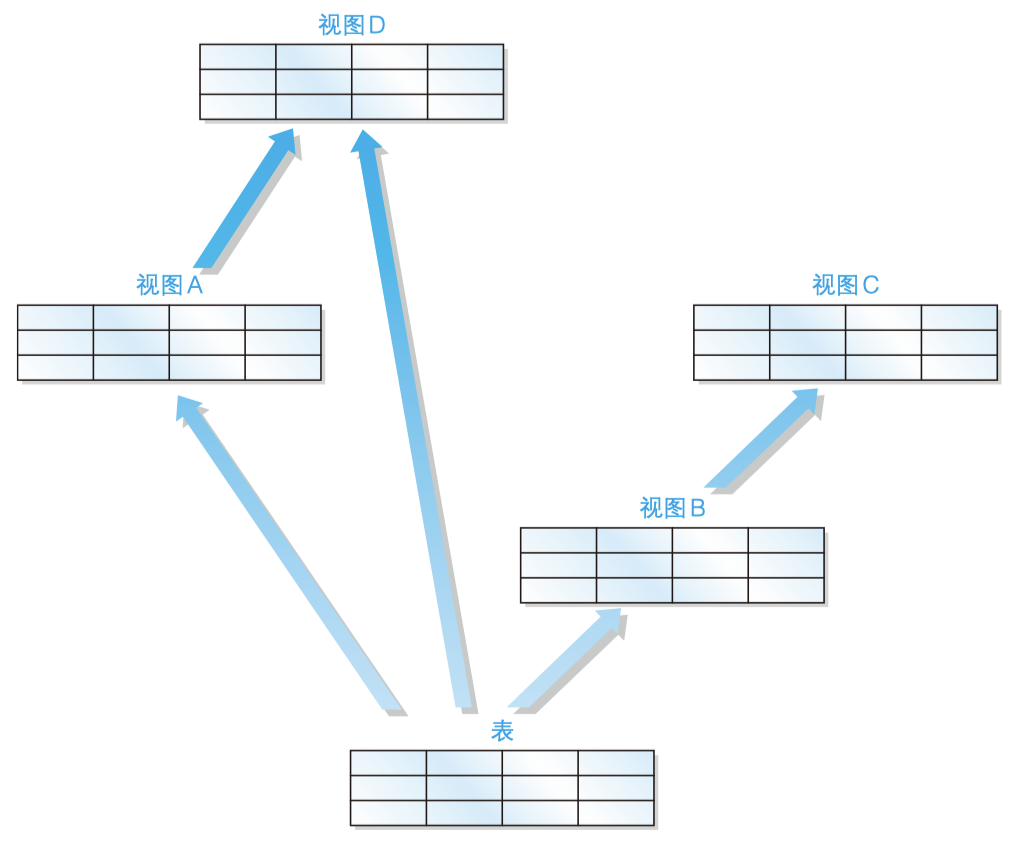
Image source: sql foundation tutorial version 2
Although there is no syntax error in continuing to create views on views, we should try to avoid this operation. This is because for most DBMS, multiple views degrade SQL performance.
- matters needing attention
It should be noted that the ORDER BY statement cannot be used when defining views in a general DBMS. It is wrong to define a view like this.
CREATE VIEW productsum (product_type, cnt_product) AS SELECT product_type, COUNT(*) FROM product GROUP BY product_type ORDER BY product_type;
Why can't you use the ORDER BY clause? This is because, like a view and a table, data rows are out of order.
In MySQL, the definition of a view allows the use of ORDER BY statements. However, if you select from a specific view and the view uses its own ORDER BY statement, the ORDER BY in the view definition will be ignored.
- Single table based view
We create a view based on the product table, as follows:
CREATE VIEW productsum (product_type, cnt_product) AS SELECT product_type, COUNT(*) FROM product GROUP BY product_type ;
The created view is shown in the following figure:
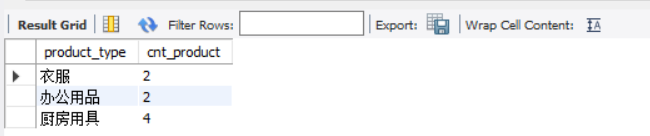
- Multi table based view
In order to learn the multi table view, we will create another table shop_product, the relevant codes are as follows:
CREATE TABLE shop_product
(shop_id CHAR(4) NOT NULL,
shop_name VARCHAR(200) NOT NULL,
product_id CHAR(4) NOT NULL,
quantity INTEGER NOT NULL,
PRIMARY KEY (shop_id, product_id));
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000A', 'Tokyo', '0001', 30);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000A', 'Tokyo', '0002', 50);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000A', 'Tokyo', '0003', 15);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0002', 30);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0003', 120);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0004', 20);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0006', 10);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0007', 40);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0003', 20);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0004', 50);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0006', 90);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0007', 70);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000D', 'Fukuoka', '0001', 100);
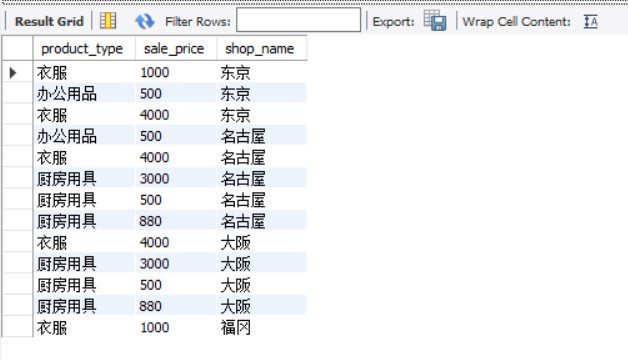
We are in the product table and shop_ Create a view based on the product table.
CREATE VIEW view_shop_product(product_type, sale_price, shop_name)
AS
SELECT product_type, sale_price, shop_name
FROM product,
shop_product
WHERE product.product_id = shop_product.product_id;
The created view is shown in the following figure
We can query based on this view
SELECT sale_price, shop_name FROM view_shop_product WHERE product_type = 'clothes';
The query result is:
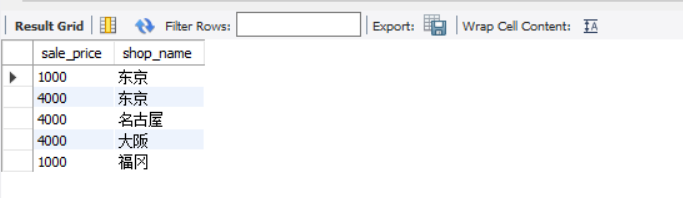
3.1.5 how to modify view structure
The basic syntax for modifying the view structure is as follows:
ALTER VIEW <View name> AS <SELECT sentence>
The view name must be unique in the database and cannot be the same as other views and tables. Of course, you can also delete and recreate the current view to achieve the effect of modification. (is this the same for the underlying database? You can explore it yourself.)
- Modify view
We modify the product sum view above to
ALTER VIEW productSum
AS
SELECT product_type, sale_price
FROM Product
WHERE regist_date > '2009-09-11';
The contents of the productSum view are shown in the following figure
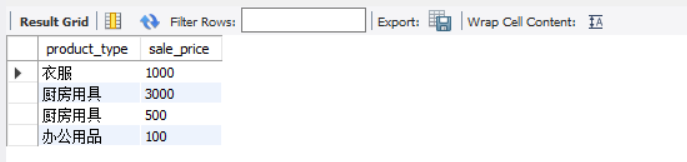
3.1.6 how to update view content
Because the view is a virtual table, the operation on the view is the operation on the underlying basic table. Therefore, the modification can be successful only if the definition of the underlying basic table is met.
For a view, any of the following structures cannot be updated:
- Aggregate functions SUM(), MIN(), MAX(), COUNT(), etc.
- DISTINCT keyword.
- GROUP BY clause.
- HAVING clause.
- UNION or UNION ALL operator.
- The FROM clause contains more than one table.
In the final analysis, the view is derived from the table. Therefore, if the original table can be updated, the data in the view can also be updated. Vice versa. If the view changes and the original table is not updated accordingly, the data consistency cannot be guaranteed.]
- update the view
Because the product sum view we just modified does not include the above restrictions, let's try to update the view
UPDATE productsum SET sale_price = '5000' WHERE product_type = 'Office Supplies';
At this point, we can check the product sum view and find that the data has been updated
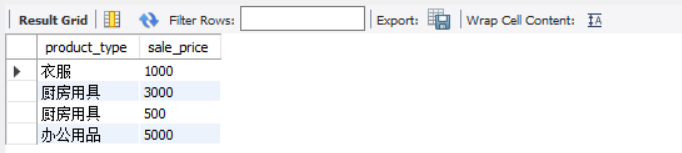
At this time, you can also find that the data has been updated by observing the original table
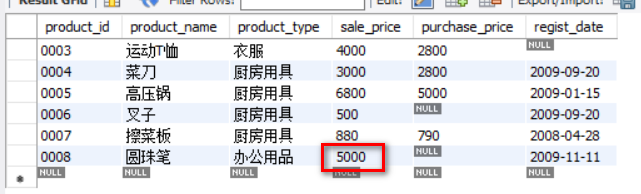
I wonder if you will have any questions when you see this result. When you just modified the view, you set product_ Sales of goods with type = 'office supplies'_ Price = 5000, why is only one piece of data in the original table modified?
Or because of the definition of view, the view is only a window of the original table, so it can only modify the contents that can be seen through the window.
Note: Although the modification here is successful, it is not recommended. In addition, we also try to use restrictions when creating views. It is not allowed to modify tables through views
3.1.7 how to delete a view
There are both creation attempts and deletion attempts. The basic syntax for deleting a view is as follows:
DROP VIEW <View name 1> [ , <View name 2> ...]
Note: you need corresponding permissions to successfully delete.
- Delete view
We delete the productSum view we just created
DROP VIEW productSum;
If we continue to operate this view, we will prompt that the content of the current operation does not exist.
3.2 sub query
Let's first look at a statement:
USE shop;
SELECT product_type, product_sum
FROM (
SELECT product_type, COUNT(*) AS product_sum
FROM product
GROUP BY sale_price) AS saleprice_sum;
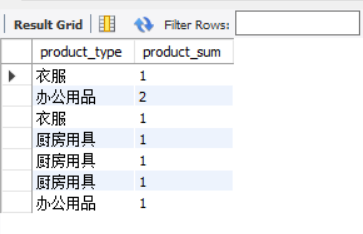
This statement looks easy to understand. The sql statement enclosed in parentheses is executed first, and then the external sql statement is executed after successful execution. However, the view mentioned in the previous section is also created according to the SELECT statement, and then queried on this basis. So what is a subquery? What is the relationship between subquery and view?
3.2.1 what is a subquery
Subquery refers to a query in which one query statement is nested inside another query statement. This feature was introduced from MySQL 4.1. The subquery is calculated first in the SELECT clause. The subquery result is used as the filter condition of another query in the outer layer. The query can be based on one table or multiple tables.
3.2.2 relationship between sub query and view
A subquery is to use the SELECT statement used to define the view directly in the FROM clause. Including AS saleprice_sum can be regarded as the name of the sub query, and because the sub query is one-time, the sub query will not be saved in the storage medium like the view, but will disappear after the SELECT statement is executed.
3.2.3 nested sub query
Similar to redefining views on views, sub queries have no specific restrictions. For example, we can do this
SELECT product_type, cnt_product
FROM (SELECT *
FROM (SELECT product_type,
COUNT(*) AS cnt_product
FROM product
GROUP BY product_type) AS productsum
WHERE cnt_product = 4) AS productsum2;
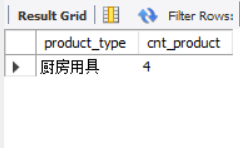
The innermost sub query is named productSum. This statement is based on product_type group and query the number. In the second level query, the number of products with 4 will be found, and the outermost layer will query product_type and cnt_product has two columns. Although nested subqueries can produce results, with the superposition of nested layers of subqueries, SQL statements will not only be difficult to understand, but also have poor execution efficiency. Therefore, such use should be avoided as far as possible.
3.2.4 quantum query
Scalar means single, so scalar subquery is also a single subquery. What is a single subquery?
The so-called single SQL statement requires us to return only one value, that is, to return a column of a specific row in the table. For example, we have the following table
product_id | product_name | sale_price
---------------±-------------------±------------
0003 sports T-shirt | four thousand
0004 Kitchen knife | 3000
0005 Pressure cooker | six thousand and eight hundred
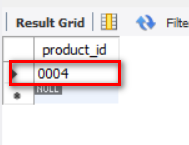
Then, after executing a scalar subquery, we want to return results like "0004" and "kitchen knife".
SELECT product_id FROM product WHERE sale_price = 3000;
3.2.5 what is the use of scalar quantum query
We now know that scalar quantum queries can return a value, so what is its role?
It may be difficult to think so directly. Let's look at several specific requirements:
- 1. Find the goods whose sales unit price is higher than the average sales unit price
- 2. Find the product with the latest registration date
Do you have any ideas?
Let's see how to query the goods whose sales unit price is higher than the average sales unit price through scalar subquery statements.
SELECT product_id, product_name, sale_price FROM product WHERE sale_price > (SELECT AVG(sale_price) FROM product);
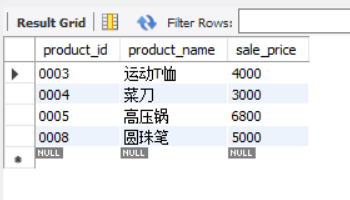
The above statement first queries the average selling price in the product table in the second half. The previous sql statement selects the appropriate goods according to the WHERE condition. Due to the characteristics of scalar subquery, scalar subquery is not limited to WHERE clause. Generally, any location WHERE a single value can be used can be used. In other words, constants or column names can be used almost everywhere, whether in the SELECT clause, GROUP BY clause, HAVING clause, or ORDER BY clause.
We can also use scalar subqueries like this:
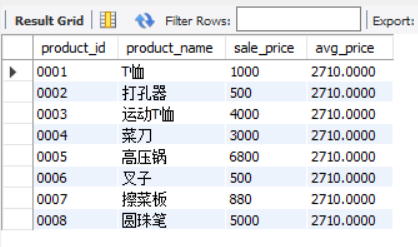
SELECT product_id,
product_name,
sale_price,
(SELECT AVG(sale_price)
FROM product) AS avg_price
FROM product;
Can you guess what the result of this code is? Run it to see if the result is consistent with your imagination.
3.2.6 associated sub query
- What is an associated subquery
Since the associated sub query contains the word association, it must mean that there is a relationship between the query and the sub query. How was this connection established?
Let's start with an example:
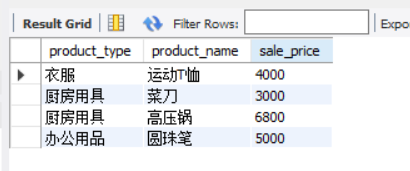
SELECT product_type, product_name, sale_price
FROM product AS p1
WHERE sale_price > (SELECT AVG(sale_price)
FROM product AS p2
WHERE p1.product_type = p2.product_type
GROUP BY product_type);
Can you understand what this example is doing? Let's take a look at the execution results of this example
From the above example, we can guess that the associated sub query is to connect the internal and external queries through some flags to filter data. Next, let's take a look at the specific content of the associated sub query.
- Relationship between associated subquery and subquery
Remember our previous example, query the goods whose sales unit price is higher than the average sales unit price. The SQL statement of this example is as follows:
SELECT product_type, product_name, sale_price
FROM product AS p1
WHERE sale_price > (SELECT AVG(sale_price)
FROM product AS p2
WHERE p1.product_type =p2.product_type
GROUP BY product_type);
Can you see the difference between the above two statements?
In the second SQL statement, that is, the associated sub query, we mark the external product table as p1, set the internal product table as p2, and connect the two queries through the WHERE statement.
However, if you are just contacted, you will be confused about the execution process of association query. Here is a blog that makes it clear. Here we briefly summarize as follows:
- 1. First execute the main query without WHERE
- 2. Match product according to the main query result_ Type to get sub query results
- 3. Combine the sub query results with the main query to execute a complete SQL statement
In subquery, like scalar subquery, nested subquery or associated subquery can be regarded as an operation mode of subquery.
Summary
View and subquery are the basic contents of database operation. For some complex queries, you need to use the combination of subquery and some conditional statements to get the correct results. However, in any case, for an SQL statement, it should not be designed with a very deep and complex number of layers, which is not only poor readability, but also difficult to ensure the execution efficiency, so try to have concise statements to complete the required functions.
Exercise - Part 1
3.1
Create a view that meets the following three conditions (the view name is ViewPractice5_1). Using the product table as the reference table, it is assumed that the table contains 8 rows of data in the initial state.
- Condition 1: the sales unit price is greater than or equal to 1000 yen.
- Condition 2: the registration date is September 20, 2009.
- Condition 3: it includes three columns: commodity name, sales unit price and registration date.
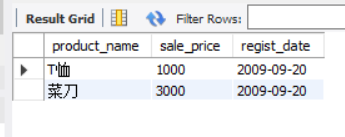
The result of the SELECT statement on the view is as follows.
SELECT * FROM ViewPractice5_1;
results of enforcement
product_name | sale_price | regist_date
--------------------±-------------±-----------
T-shirt | 1000 | 2009-09-20
Kitchen knife | 3000 | 2009-09-20
Answer
CREATE VIEW ViewPractice5_1(product_name, sale_price, regist_date)
AS
SELECT product_name, sale_price, regist_date
FROM product
WHERE sale_price >= 1000 and regist_date = '2009-09-20'
3.2
Add viewpractice5 to the view created in exercise 1_ What results will be obtained by inserting the following data into 1? Why?
INSERT INTO ViewPractice5_1 VALUES (' knife ', 300, '2009-11-02');
Answer
Error Code: 1423. Field of view 'shop.viewpractice5_1' underlying table doesn't have a default value
Because inserting data into the view will also insert data into the corresponding table, but some columns in a record of the original table cannot be empty, so it cannot be inserted.
Reference source: Author: wiki_ Zhan https://www.bilibili.com/read/cv8915888/ Source: BiliBili
3.3
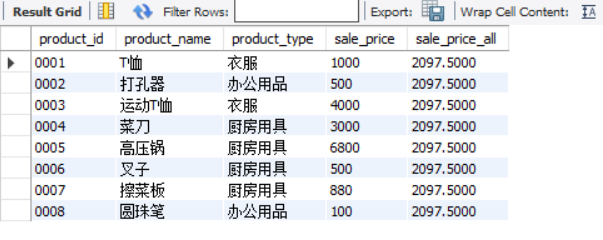
Write a SELECT statement based on the following results, where sale_price_all is the average selling unit price of all goods.
product_id | product_name| product_type | sale_price | sale_price_all
--------------±-------------------±-------------------±-------------±--------------------
0001 | T-shirt clothes | 1000 | two hundred and fifty-two point eight two five five nine two six two nine zero four four eight three eight four
0002 | punch Office supplies | five hundred | 2097.5000000000000000
0003 | sports T-shirt | Clothes | 4000 | 2097.5 billion
0004 kitchen knife kitchen utensils | three thousand | two hundred and fifty-two point eight two five five nine two six two nine zero four four eight three eight four
0005 | pressure cooker | kitchen utensils | six thousand and eight hundred | two hundred and fifty-two point eight two five five nine two six two nine zero four four eight three eight four
0006 | fork | kitchen utensils | five hundred | 2097.5000000000000000
0007 | kitchen board | kitchen utensils | eight hundred and eighty | 2097.5000000000000000
0008 | ballpoint pen | office supplies | one hundred | 2097.5000000000000000
Answer:
--My previous operations have changed the data, so it involves data modification. It is added here for the reference of small partners who modify the data.
--UPDATE product
--SET sale_price=100
--WHERE product_id=8;
SELECT product_id,
product_name,
product_type,
sale_price,
(SELECT AVG(sale_price)
FROM product) AS sale_price_all
FROM product;
3.4
Please write an SQL statement according to the conditions in exercise 1 and create a view (named AvgPriceByType) containing the following data.
product_id | product_name| product_type | sale_price | sale_price_all
--------------±-------------------±-------------------±-------------±--------------------
0001 | T-shirt clothes | 1000 | six hundred and fifty-five point three two five five nine two six two nine zero four four eight three eight four
0002 | punch Office supplies | five hundred | 300.0000000000000000
0003 | sports T-shirt | Clothes | 4000 | 2500 million million
0004 kitchen knife kitchen utensils | three thousand |
0005 | pressure cooker | kitchen utensils | six thousand and eight hundred |
0006 | fork | kitchen utensils | five hundred | 2795.0000000000000000
0007 | kitchen board | kitchen utensils | eight hundred and eighty | 2795.0000000000000000
0008 | ballpoint pen | office supplies | one hundred | 300.0000000000000000
Tip: the key is AVG_ sale_ The price column. Different from exercise 3, what needs to be calculated here is the average sales unit price of each commodity type. This is the same as using the associated subquery. That is, the column can be created using an associated subquery. The question is where the associated subquery should be used.
Problem solving ideas: easy to know by observing table data, AVG_ sale_ The price column is used to find the mean value of different product types. According to the knowledge learned before, the mean value needs to be classified and solved. The normally obtained classified mean value according to product type is only three rows. Therefore, the associated sub query needs to be used here. Through logic, it can be seen that the condition of the associated sub query should be the matching selection of corresponding values when the product types are the same, Group according to product type, so the focus of this question is: find the average value, and the matching condition is product type.
Reference from blog: https://blog.csdn.net/weixin_42647162/article/details/108417665
Answer:
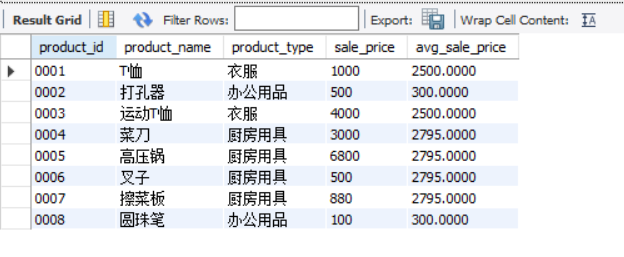
SELECT product_id,
product_name,
sale_price,
(SELECT AVG(sale_price)
FROM Product AS P2
WHERE P1.product_type = P2.product_type
GROUP BY P1.product_type) AS avg_sale_price
FROM Product AS P1;
3.3 various functions
sql comes with various functions, which greatly improves the convenience of sql language.
The so-called function is similar to a black box. If you give it an input value, it will give the return value according to the preset program definition. The input value is called a parameter.
Functions can be roughly divided into the following categories:
- Arithmetic function (function used for numerical calculation)
- String function (function used for string operation)
- Date function (function used for date operation)
- Conversion function (function used to convert data types and values)
- Aggregate function (function used for data aggregation)
The total number of functions exceeds 200. You don't need to remember it completely. There are 30 ~ 50 commonly used functions. You can consult the document when using other infrequent functions.
3.3.1 arithmetic function
- +- * / four operations have been introduced in previous chapters and will not be repeated here.
To demonstrate several other arithmetic functions, the samplemath table is constructed here
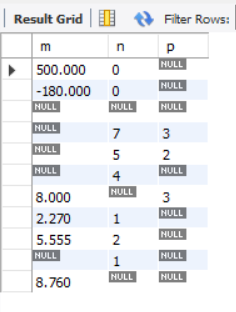
-- DDL : Create table USE shop; DROP TABLE IF EXISTS samplemath; CREATE TABLE samplemath (m float(10,3), n INT, p INT); -- DML : insert data START TRANSACTION; -- Start transaction INSERT INTO samplemath(m, n, p) VALUES (500, 0, NULL); INSERT INTO samplemath(m, n, p) VALUES (-180, 0, NULL); INSERT INTO samplemath(m, n, p) VALUES (NULL, NULL, NULL); INSERT INTO samplemath(m, n, p) VALUES (NULL, 7, 3); INSERT INTO samplemath(m, n, p) VALUES (NULL, 5, 2); INSERT INTO samplemath(m, n, p) VALUES (NULL, 4, NULL); INSERT INTO samplemath(m, n, p) VALUES (8, NULL, 3); INSERT INTO samplemath(m, n, p) VALUES (2.27, 1, NULL); INSERT INTO samplemath(m, n, p) VALUES (5.555,2, NULL); INSERT INTO samplemath(m, n, p) VALUES (NULL, 1, NULL); INSERT INTO samplemath(m, n, p) VALUES (8.76, NULL, NULL); COMMIT; -- Commit transaction -- Query table content SELECT * FROM samplemath;
- ABS – absolute value
Syntax: ABS (numeric)
ABS function is used to calculate the absolute value of a number, which represents the distance from a number to the origin.
When the parameter of the ABS function is NULL, the return value is also NULL.
- MOD – remainder
Syntax: mod (dividend, divisor)
MOD is a function for calculating the division remainder (remainder), which is the abbreviation of modulo. Decimal has no concept of remainder. It can only find the remainder of integer column.
Note: the mainstream DBMS supports MOD function. Only SQL Server does not support this function. It uses the% symbol to calculate the remainder.
- ROUND – ROUND
Syntax: round (object value, number of decimal places reserved)
The ROUND function is used for rounding.
Note: errors may be encountered when the number of decimal places of the parameter is a variable. Please use the variable with caution.
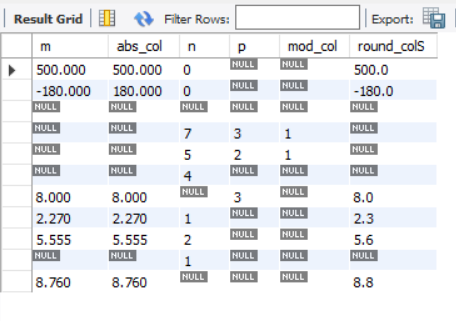
SELECT m, ABS(m)ASabs_col , n, p, MOD(n, p) AS mod_col, ROUND(m,1)ASround_colS FROM samplemath;
3.3.2 string function
String functions are also often used. In order to learn string functions, we construct the samplestr table here.
-- DDL : Create table
USE shop;
DROP TABLE IF EXISTS samplestr;
CREATE TABLE samplestr
(str1 VARCHAR (40),
str2 VARCHAR (40),
str3 VARCHAR (40)
);
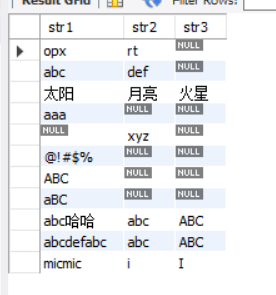
-- DML: insert data
START TRANSACTION;
INSERT INTO samplestr (str1, str2, str3) VALUES ('opx', 'rt', NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('abc', 'def', NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('sun', 'moon', 'Mars');
INSERT INTO samplestr (str1, str2, str3) VALUES ('aaa', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES (NULL, 'xyz', NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('@!#$%', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('ABC', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('aBC', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('abc ha-ha', 'abc', 'ABC');
INSERT INTO samplestr (str1, str2, str3) VALUES ('abcdefabc', 'abc', 'ABC');
INSERT INTO samplestr (str1, str2, str3) VALUES ('micmic', 'i', 'I');
COMMIT;
-- Confirm the contents in the table
SELECT * FROM samplestr;
- CONCAT – splice
Syntax: CONCAT(str1, str2, str3)
CONCAT function is used for splicing in MySQL.
- LENGTH – string LENGTH
Syntax: length (string)
- LOWER – LOWER case conversion
The LOWER function can only be used for English letters. It converts all strings in the parameter to lowercase. This function is not applicable to situations other than English letters and does not affect characters that are originally lowercase.
Similarly, the UPPER function is used for uppercase conversion.
- REPLACE – REPLACE string
Syntax: replace (object string, string before replacement, string after replacement)
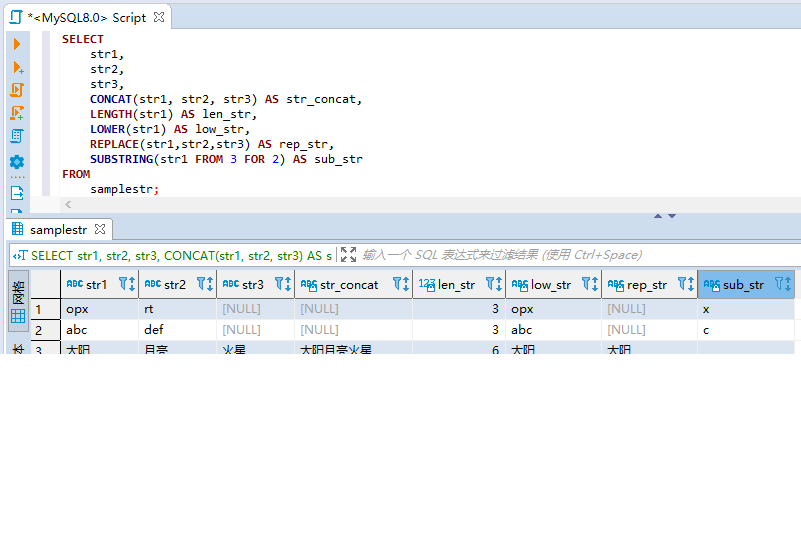
- SUBSTRING – interception of string
Syntax: SUBSTRING (the starting position of the object string intercepted FROM and the number of characters intercepted FOR)
You can use the SUBSTRING function to truncate a part of the string. The starting position of the interception is calculated from the leftmost side of the string, and the starting index value is 1.
- (extended content) SUBSTRING_INDEX – the string is truncated by index
Syntax: SUBSTRING_INDEX (original string, separator, n)
This function is used to obtain the substring before (or after) the nth separator after the original string is divided according to the separator. It supports forward and reverse indexing, and the starting values of the index are 1 and - 1 respectively.
SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);
SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);
It is easy to get the first element, and the second element / nth element can be written in the way of secondary splitting.
SELECT SUBSTRING_INDEX('www.mysql.com', '.', 1);
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('www.mysql.com', '.', 2), '.', -1);
- (extended content) REPEAT – the string repeats as many times as needed
Syntax: REPEAT(string, number)
This function is used to repeat specific characters on demand.
Example:
SELECT REPEAT('come on.',3);
3.3.3 date function
Different DBMS have different date function syntax. This course introduces some functions recognized by standard SQL that can be applied to most DBMS. You can refer to the document for the date function of a specific DBMS.
- CURRENT_DATE – gets the current date
SELECT CURRENT_DATE;
- CURRENT_TIME – current time
SELECT CURRENT_TIME;
- CURRENT_TIMESTAMP – current date and time
SELECT CURRENT_TIMESTAMP;
- EXTRACT – intercept date element
Syntax: extract (date element FROM date)
Use the EXTRACT function to EXTRACT a part of the date data, such as "year"
"Month", or "hour", "second", etc. the return value of this function is not a date type, but a numeric type
SELECT CURRENT_TIMESTAMP as now, EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year, EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month, EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day, EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour, EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS MINute, EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second;

3.3.4 conversion function
The word "conversion" has a very broad meaning. In SQL, it mainly has two meanings: one is data type conversion, which is referred to as type conversion, which is called cast in English; the other means value conversion.
- CAST - type conversion
Syntax: CAST (value before conversion AS data type to be converted)
-- Converts a string type to a numeric type
SELECT CAST('0001' AS SIGNED INTEGER) AS int_col;
-- Convert string type to date type
SELECT CAST('2009-12-14' AS DATE) AS date_col;
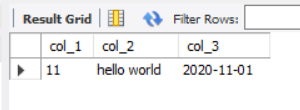
- COALESCE – converts NULL to another value
Syntax: coalesce (data 1, data 2, data 3...)
COALESCE is A SQL specific function. This function will return the first non NULL value from the left in the variable parameter A. the number of parameters is variable, so it can be increased infinitely as needed.
The conversion function is used when converting NULL to other values in SQL statements.
SELECT COALESCE(NULL, 11) AS col_1, COALESCE(NULL, 'hello world', NULL) AS col_2, COALESCE(NULL, NULL, '2020-11-01') AS col_3;
3.4 predicate
3.4.1 what are predicates
A predicate is a function that returns a true value, including TRUE / FALSE / UNKNOWN.
Predicates mainly include the following:
- LIKE
- BETWEEN
- IS NULL,IS NOT NULL
- IN
- EXISTS
3.4.2 LIKE predicate – used for partial consistent query of strings
This predicate is used when a partially consistent query of a string is required
Partial consistency can be divided into three types: front consistency, middle consistency and rear consistency.
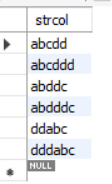
First, let's create a table
-- DDL : Create table
CREATE TABLE samplelike
( strcol VARCHAR(6) NOT NULL,
PRIMARY KEY (strcol)
samplelike);
-- DML : insert data
START TRANSACTION; -- Start transaction
INSERT INTO samplelike (strcol) VALUES ('abcddd');
INSERT INTO samplelike (strcol) VALUES ('dddabc');
INSERT INTO samplelike (strcol) VALUES ('abdddc');
INSERT INTO samplelike (strcol) VALUES ('abcdd');
INSERT INTO samplelike (strcol) VALUES ('ddabc');
INSERT INTO samplelike (strcol) VALUES ('abddc');
COMMIT; -- Commit transaction
SELECT * FROM samplelike;
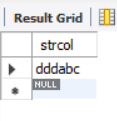
- Consistent in front: select "dddabc"
Consistent in front, that is, the string as the query condition (here "ddd") is the same as the starting part of the query object string.
SELECT * FROM samplelike WHERE strcol LIKE 'ddd%';
Where% is a special symbol representing "zero or more arbitrary strings", and in this example represents "all strings starting with ddd".
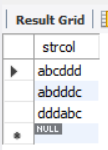
- Consistent in the middle: select "abcddd", "dddabc" and "abddddc"
Consistent in the middle, that is, the query object string contains a string as the query condition, regardless of whether the string appears in the object word
It doesn't matter whether the last or the middle of the string.
SELECT * FROM samplelike WHERE strcol LIKE '%ddd%';
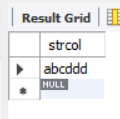
- Consistent in the rear: select "abcddd"“
The last part is consistent, that is, the string as the query condition (here "ddd") is the same as the end of the query object string.
SELECT * FROM samplelike WHERE strcol LIKE '%ddd';
Based on the above three types of queries, we can see that the query conditions are the most relaxed, that is, the middle consistency can get the most records, because it contains both front consistent and rear consistent query results.
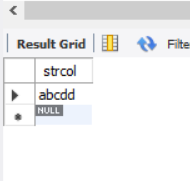
- _Underscore matches any 1 character
Use (underscore) instead of%. Unlike%, it represents "any 1 character".
SELECT * FROM samplelike WHERE strcol LIKE 'abc__';
3.4.3 BETWEEN predicate – used for range query
Use BETWEEN to query the range. This predicate is different from other predicates or functions in that it uses three parameters.
-- Select the sales unit price as 100~ 1000 Yuan commodity SELECT product_name, sale_price FROM product WHERE sale_price BETWEEN 100 AND 1000;
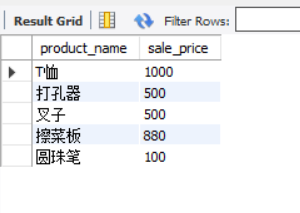
The characteristic of BETWEEN is that the result will contain two critical values of 100 and 1000, that is, closed interval. If you don't want the result to contain critical values, you must use < and >.
SELECT product_name, sale_price FROM product WHERE sale_price > 100 AND sale_price < 1000;
3.4.4 IS NULL, IS NOT NULL – used to determine whether it is NULL
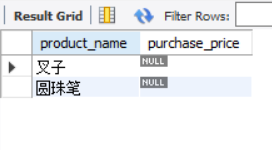
In order to select the data of some columns with NULL value, you cannot use =, but only the specific predicate IS NULL.
SELECT product_name, purchase_price FROM product WHERE purchase_price IS NULL;
In contrast, when you want to select data other than NULL, you need to use IS NOT NULL.
SELECT product_name, purchase_price FROM product WHERE purchase_price IS NOT NULL;
3.4.5 IN predicate – simple usage of OR
When multiple query criteria are merged, you can choose to use the or statement.
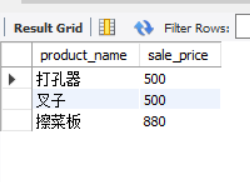
-- adopt OR Specify multiple purchase unit prices for query SELECT product_name, purchase_price FROM product WHERE purchase_price = 320 OR purchase_price = 500 OR purchase_price = 5000;
Although there is no problem with the above method, there is still a disadvantage, that is, with more and more objects to be selected, the SQL statement will be longer and more difficult to read. At this time, we can use the IN predicate ` IN (value 1, value 2, value 3,...) to replace the above SQL statement.
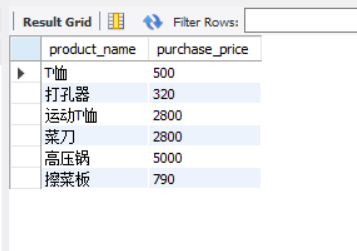
SELECT product_name, purchase_price FROM product WHERE purchase_price IN (320, 500, 5000);
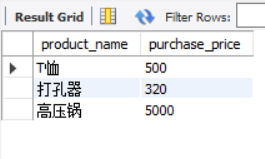
The above statements are much more concise and the readability is greatly improved. On the contrary, when you want to select goods whose purchase unit price is not 320 yuan, 500 yuan or 5000 yuan, you can use the negative form NOT IN.
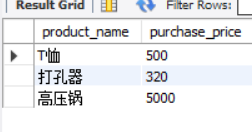
SELECT product_name, purchase_price FROM product WHERE purchase_price NOT IN (320, 500, 5000);
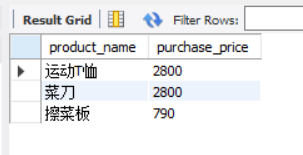
It should be noted that NULL data cannot be selected when IN and NOT IN are used. The same is true for the actual results. Neither of the above two groups of results includes forks and ballpoint pens with NULL purchase unit price. NULL can only be judged by IS NULL and IS NOT NULL.
3.4.6 using subquery as parameter of IN predicate
- IN and subquery
IN predicates (NOT IN predicates) have a usage that other predicates do not have, that is, they can use subqueries as their parameters. We have learned IN Section 3.2 that subqueries are tables generated within SQL, so we can also say "tables can be used as parameters of IN". Similarly, we can also say "views can be used as parameters of IN".
Here, we create a new table shopproduct to show which stores sell which goods.
-- DDL : Create table
DROP TABLE IF EXISTS shopproduct;
CREATE TABLE shopproduct
( shop_id CHAR(4) NOT NULL,
shop_name VARCHAR(200) NOT NULL,
product_id CHAR(4) NOT NULL,
quantity INTEGER NOT NULL,
PRIMARY KEY (shop_id, product_id) -- Specify primary key
);
-- DML : insert data
START TRANSACTION; -- Start transaction
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', 'Tokyo', '0001', 30);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', 'Tokyo', '0002', 50);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', 'Tokyo', '0003', 15);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0002', 30);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0003', 120);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0004', 20);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0006', 10);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', 'Nagoya', '0007', 40);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0003', 20);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0004', 50);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0006', 90);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', 'Osaka', '0007', 70);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000D', 'Fukuoka', '0001', 100);
COMMIT; -- Commit transaction
SELECT * FROM shopproduct;
+---------+-----------+------------+----------+
| shop_id | shop_name | product_id | quantity |
+---------+-----------+------------+----------+
| 000A | Tokyo | 0001 | 30 |
| 000A | Tokyo | 0002 | 50 |
| 000A | Tokyo | 0003 | 15 |
| 000B | Nagoya | 0002 | 30 |
| 000B | Nagoya | 0003 | 120 |
| 000B | Nagoya | 0004 | 20 |
| 000B | Nagoya | 0006 | 10 |
| 000B | Nagoya | 0007 | 40 |
| 000C | Osaka | 0003 | 20 |
| 000C | Osaka | 0004 | 50 |
| 000C | Osaka | 0006 | 90 |
| 000C | Osaka | 0007 | 70 |
| 000D | Fukuoka | 0001 | 100 |
+---------+-----------+------------+----------+
13 rows in set (0.00 sec)
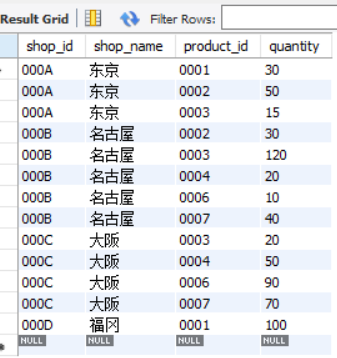
Since each row of data in the table cannot be distinguished by using store_id or product_id alone, two columns are specified as the primary key to combine stores and goods to uniquely determine each row of data.
Suppose we need to take out the sales unit price of goods on sale in Osaka, how can we achieve it?
The first step is to take out the product_id of the goods on sale in the Osaka store;
The second step is to take out the sales unit price of goods on sale in Osaka stores
-- step1: Take out the goods on sale in Osaka store `product_id` SELECT product_id FROM shopproduct WHERE shop_id = '000C';
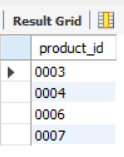
The above statement takes out the commodity number on sale in Osaka store. Next, we can use the above statement as the query criteria in the second step.
-- step2: Take out the sales unit price of goods on sale in Osaka stores `sale_price` SELECT product_name, sale_price FROM product WHERE product_id IN (SELECT product_id FROM shopproduct WHERE shop_id = '000C');
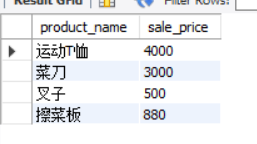
According to the knowledge learned in Section 3.2, the sub query is executed from the innermost layer (from inside to outside). Therefore, after the sub query of the above statement is executed, the sql is expanded into the following statement
-- Results after sub query expansion
SELECT product_name, sale_price
FROM product
WHERE product_id IN ('0003', '0004', '0006', '0007');
You can see that the subquery is converted into the in predicate usage. Do you understand? Or, you wonder why subqueries should be used since the in predicate can also be implemented? Here are two reasons:
① : in real life, the goods on sale in a store are constantly changing, and the sql statement needs to be updated frequently when using the in predicate, which reduces the efficiency and improves the maintenance cost;
② : in fact, there may be hundreds or thousands of goods on sale in a store. Manually maintaining the number of goods on sale is really a big project.
Using sub query can keep the sql statement unchanged, which greatly improves the maintainability of the program, which is the key consideration in system development.
- NOT IN and subqueries
NOT IN also supports sub queries as parameters, and the usage is exactly the same as in.
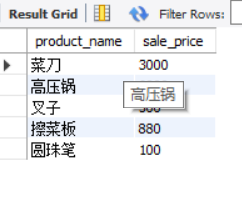
-- NOT IN Use the subquery as a parameter to retrieve the sales unit price of goods not sold in Osaka stores
SELECT product_name, sale_price
FROM product
WHERE product_id NOT IN (SELECT product_id
FROM shopproduct
WHERE shop_id = '000A');
3.4.7 EXIST predicate
The use of the EXIST predicate is difficult to understand.
① The use of EXIST is different from that before
② Grammar is difficult to understand
③ IN fact, even if EXIST is not used, it can basically be replaced by IN (or NOT IN)
So, is it necessary to learn the EXIST predicate? The answer is yes, because once you can skillfully use the EXIST predicate, you can realize its great convenience.
However, you don't have to worry too much. This course introduces some basic usage. You can pay more attention to the usage of EXIST predicate in future study, so as to master this usage when you reach the intermediate level of SQL.
- Use of EXIST predicate
The function of predicate is to "judge whether there are records that meet certain conditions".
If such a record exists, it returns TRUE (TRUE), and if it does not exist, it returns FALSE (FALSE).
The subject of the EXIST predicate is "record".
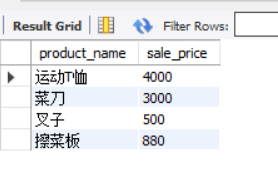
We continue to use the examples IN in and sub query to select the sales unit price of goods on sale IN Osaka stores using EXIST.
SELECT product_name, sale_price
FROM product AS p
WHERE EXISTS (SELECT *
FROM shopproduct AS sp
WHERE sp.shop_id = '000C'
AND sp.product_id = p.product_id);
- Parameters of EXIST
The predicates we learned before basically need to specify more than two parameters, such as "column LIKE string" or "column BETWEEN value 1 AND value 2", but there are no parameters on the left side of EXIST. Because EXIST is a predicate with only 1 parameter. Therefore, EXIST only needs to write one parameter on the right, which is usually a sub query.
(SELECT *
FROM shopproduct AS sp
WHERE sp.shop_id = '000C'
AND sp.product_id = p.product_id)
The subquery above is the only parameter. Specifically, because the product table and the shopproduct table are joined by the condition "SP.product_id = P.product_id", the associated subquery is used as a parameter. EXIST usually uses an associated subquery as a parameter.
- SELECT in subquery*
Since EXIST only cares about whether records EXIST, it doesn't matter which columns are returned. EXIST will only judge whether there are records that meet the criteria specified in the WHERE clause in the subquery: "the store number (shop_id) is' 000C ', and the product number (product ID) in the product table and the store product table are the same". TRUE will be returned only when such records EXIST.
Therefore, using the following query statement, the query results will not change.
SELECT product_name, sale_price
FROM product AS p
WHERE EXISTS (SELECT 1 -- The appropriate constants can be written here
FROM shopproduct AS sp
WHERE sp.shop_id = '000C'
AND sp.product_id = p.product_id);
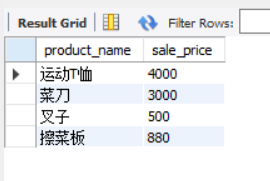
You can take writing SELECT * in the sub query of EXIST as a habit of SQL.
- Replace NOT IN with NOT EXIST
Just as EXIST can be used to replace IN, NOT IN can also be replaced with NOT EXIST.
The following code example takes out the sales unit price of goods not sold in Osaka stores.
SELECT product_name, sale_price
FROM product AS p
WHERE NOT EXISTS (SELECT *
FROM shopproduct AS sp
WHERE sp.shop_id = '000A'
AND sp.product_id = p.product_id);
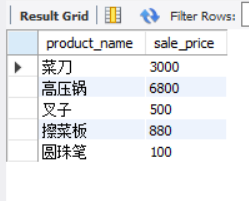
NOT EXIST, in contrast to EXIST, returns TRUE when "no record exists" that meets the criteria specified in the subquery.
3.5 CASE expression
3.5.1 what is a CASE expression?
CASE expression is a kind of function. It is one of the top two important functions in SQL. It is necessary to learn it well.
CASE expressions are used to distinguish situations, which are often called (conditional) branches in programming.
The syntax of CASE expression is divided into simple CASE expression and search CASE expression. Because the search CASE expression contains all the functions of a simple CASE expression. This lesson focuses on searching CASE expressions.
Syntax:
Case when < evaluation expression > then < expression >
When < evaluation expression > then < expression >
When < evaluation expression > then < expression >
.
.
.
Else < expression >
END
When executing the above statements, judge whether the when expression is true. If yes, execute the statement after THEN. If all the when expressions are false, execute the statement after ELSE. No matter how large a CASE expression is, it will only return one value in the end.
3.5.2 use of case expression
Suppose you want to achieve the following results now:
A: Clothes
B: Office supplies
C: Kitchen utensils
Because the records in the table do not contain strings such as "A:" or "B:", they need to be added in SQL. And combine "A:" "B:" "C:" with the record.
- Application scenario 1: get different column values according to different branches
SELECT product_name,
CASE WHEN product_type = 'clothes' THEN CONCAT('A : ',product_type)
WHEN product_type = 'Office Supplies' THEN CONCAT('B : ',product_type)
WHEN product_type = 'kitchenware' THEN CONCAT('C : ',product_type)
ELSE NULL
END AS abc_product_type
FROM product;
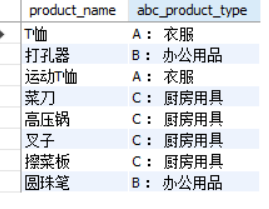
The ELSE clause can also be omitted without writing. At this time, it will be defaulted to ELSE NULL. However, in order to prevent people from missing reading, I hope you can write the ELSE clause explicitly. In addition, the "END" at the END of the CASE expression cannot be omitted. Please pay special attention not to omit it. Forgetting to write END will lead to grammatical errors, which is also the easiest mistake to make at the beginning of learning.
- Application scenario 2: aggregation in column direction
Generally, we use the following code to implement different kinds of aggregation (sum in this case) in the direction of lines
SELECT product_type,
SUM(sale_price) AS sum_price
FROM product
GROUP BY product_type;
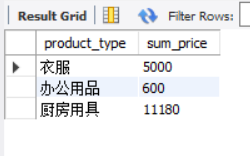
If you want to display different kinds of aggregate values in the direction of the column, how should you write them?
sum_price_clothes | sum_price_kitchen | sum_price_office
-------------------------±--------------------------±----------------------
5000 | 11180 | 600
Aggregate function + CASE WHEN expression can achieve this effect
-- Perform line to line conversion on the total sales unit price calculated by commodity type
SELECT SUM(CASE WHEN product_type = 'clothes' THEN sale_price ELSE 0 END) AS sum_price_clothes,
SUM(CASE WHEN product_type = 'kitchenware' THEN sale_price ELSE 0 END) AS sum_price_kitchen,
SUM(CASE WHEN product_type = 'Office Supplies' THEN sale_price ELSE 0 END) AS sum_price_office
FROM product;

- (extended content) application scenario 3: realize row to column conversion
Suppose there is the structure of the following chart
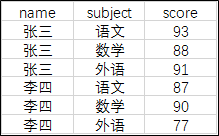
The following chart structure is planned
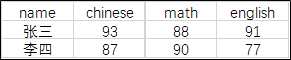
Aggregate function + CASE WHEN expression can realize this conversion
-- Create table
-- DDL : Create table
DROP TABLE IF EXISTS score;
CREATE TABLE score
(name VARCHAR(4) NOT NULL,
subject VARCHAR(4) NOT NULL,
score INT(4) NOT NULL);
START TRANSACTION;
INSERT INTO score VALUES('Zhang San', 'chinese', 93);
INSERT INTO score VALUES('Zhang San', 'mathematics', 88);
INSERT INTO score VALUES('Zhang San', 'Foreign Languages', 91);
INSERT INTO score VALUES('Li Si', 'chinese', 87);
INSERT INTO score VALUES('Li Si', 'mathematics', 90);
INSERT INTO score VALUES('Li Si', 'Foreign Languages', 77);
-- CASE WHEN Implement numeric columns score Row to column
SELECT name,
SUM(CASE WHEN subject = 'chinese' THEN score ELSE null END) as chinese,
SUM(CASE WHEN subject = 'mathematics' THEN score ELSE null END) as math,
SUM(CASE WHEN subject = 'Foreign Languages' THEN score ELSE null END) as english
FROM score
GROUP BY name;
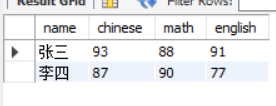
The above code realizes the row to column conversion of the digital column score, and can also realize the row to column conversion of the text column subject
-- CASE WHEN Implement text columns subject Row to column
SELECT name,
MAX(CASE WHEN subject = 'chinese' THEN subject ELSE null END) as chinese,
MAX(CASE WHEN subject = 'mathematics' THEN subject ELSE null END) as math,
MIN(CASE WHEN subject = 'Foreign Languages' THEN subject ELSE null END) as english
FROM score
GROUP BY name;
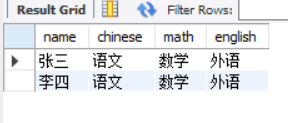
Summary:
* When the column to be converted is a number, you can use SUM AVG MAX MIN Equal aggregation function; * When the column to be converted is text, you can use MAX MIN Equal aggregate function
Exercise - Part 2
3.5 judgment questions
When NULL is included in the operation, does the operation result necessarily become NULL?
Answer:
Answer: correct
3.6
What results can be obtained by executing the following two SELECT statements on the product table used in this chapter?
①
SELECT product_name, purchase_price FROM product WHERE purchase_price NOT IN (500, 2800, 5000);
Answer:
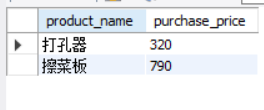
②
SELECT product_name, purchase_price FROM product WHERE purchase_price NOT IN (500, 2800, 5000, NULL);
Answer:
It should be noted that NULL data cannot be selected when IN and NOT IN are used.
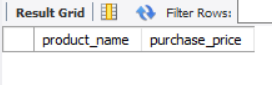
3.7
Classify the items in the product table in exercise 3.6 according to the sales_price as follows.
- Low grade goods: the sales unit price is less than 1000 yen (T-shirts, office supplies, forks, kitchen cleaning boards, ball point pens)
- Middle grade goods: the sales unit price is more than 1001 yen and less than 3000 yen (kitchen knife)
- High grade goods: the sales unit price is more than 3001 yen (Sports T-shirt, pressure cooker)
Please write a SELECT statement to count the quantity of goods contained in the above commodity categories. The results are as follows.
Execution results:
low_price | mid_price | high_price
-------------±--------------±---------------
5 | 1 | 2
Solution: by observing the commodity classification of this question, we can see that it is necessary to classify commodities, so it will involve CASE function and BETWEEN function (or use < = and = >). Because it is necessary to count quantities, we use COUNT() function. COUNT() is an aggregate function. Judge the returned result set line by line. If the parameter of COUNT() function is not NULL, the cumulative value will be added by 1, Otherwise, No. Finally, the cumulative value is returned.
Answer:
SELECT COUNT(CASE WHEN sale_price <= 1000 THEN sale_price ELSE NULL END) AS low_price,
COUNT(CASE WHEN sale_price BETWEEN 1001 AND 3000 THEN sale_price ELSE NULL END) AS mid_price,
COUNT(CASE WHEN sale_price > 3001 THEN sale_price ELSE NULL END) AS high_price
FROM product;
[summary]
From the summary of task 2 and the contents of this punch in, when some data are known, the overall idea of extracting data is to analyze the data law, and then select the corresponding function for data acquisition or writing. For specific examples, please refer to the solution idea of question 3.7 in part II of my exercise on this task. This punch in task is more difficult than I expected, The contents of this punch in need of repeated review and understanding, and the related sub query of Exercise 3.4 needs to be repeated and understood.