Original author: Li Haiqiang, from the retail big data team of Ping An Bank
Preface
As a data engineer, you may encounter many ways to start PySpark. You may not understand what they have in common, what differences they have, and what impact different methods have on program development and deployment. Today, let's analyze these ways to start PySpark.
The following code analysis is based on spark-2.4.4. In order to avoid ambiguity, it is necessary to have a deep understanding of Spark in this version.
How to start PySpark

Start PySpark code analysis
Let's analyze the code implementation process of the three methods.
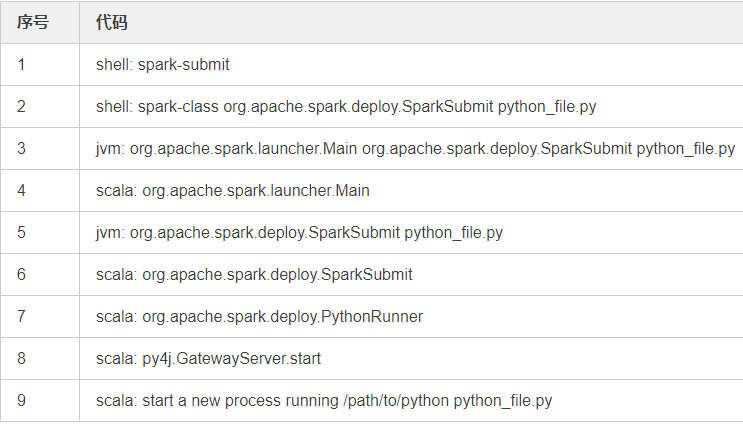
/path/to/spark-submit python_file.py
-
Spark submit is a shell script
-
Spark submit calls the shell command spark class org.apache.spark.deploy.sparksubmit python_file.py
-
Spark class, line 71, execute jvm org.apache.spark.launcher.Main org.apache.spark.deploy.SparkSubmit python_file.py and rewrite the SparkSubmit parameter
# The launcher library will print arguments separated by a NULL character, to allow arguments with # characters that would be otherwise interpreted by the shell. Read that in a while loop, populating # an array that will be used to exec the final command. # # The exit code of the launcher is appended to the output, so the parent shell removes it from the # command array and checks the value to see if the launcher succeeded. build_command() { "$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@" printf "%d\0" $? } # Turn off posix mode since it does not allow process substitution set +o posix CMD=() while IFS= read -d '' -r ARG; do CMD+=("$ARG") done < <(build_command "$@")
4. Analyze how org.apache.spark.launcher.Main rewrites the Spark submit parameter. You can see that buildCommand can be divided into three situations, corresponding to three different scenarios: PySpark shell, Spark R shell and Spark submit. Different class es are used for scenarios
/** * This constructor is used when invoking spark-submit; it parses and validates arguments * provided by the user on the command line. */ SparkSubmitCommandBuilder(List<String> args) { this.allowsMixedArguments = false; this.parsedArgs = new ArrayList<>(); boolean isExample = false; List<String> submitArgs = args; this.userArgs = Collections.emptyList(); if (args.size() > 0) { switch (args.get(0)) { case PYSPARK_SHELL: this.allowsMixedArguments = true; appResource = PYSPARK_SHELL; submitArgs = args.subList(1, args.size()); break; case SPARKR_SHELL: this.allowsMixedArguments = true; appResource = SPARKR_SHELL; submitArgs = args.subList(1, args.size()); break; case RUN_EXAMPLE: isExample = true; appResource = SparkLauncher.NO_RESOURCE; submitArgs = args.subList(1, args.size()); } this.isExample = isExample; OptionParser parser = new OptionParser(true); parser.parse(submitArgs); this.isSpecialCommand = parser.isSpecialCommand; } else { this.isExample = isExample; this.isSpecialCommand = true; } } @Override public List<String> buildCommand(Map<String, String> env) throws IOException, IllegalArgumentException { if (PYSPARK_SHELL.equals(appResource) && !isSpecialCommand) { return buildPySparkShellCommand(env); } else if (SPARKR_SHELL.equals(appResource) && !isSpecialCommand) { return buildSparkRCommand(env); } else { return buildSparkSubmitCommand(env); } }
-
Here, the class returned by buildCommand is org.apache.spark.deploy.SparkSubmit, and the parameter is python_file.py
-
Because the parameter of SparkSubmit is a. py file, select class org.apache.spark.deploy.python runner
Finally, let's look at the implementation of Python runner. First, create a thread of py4j.GatewayServer to receive requests initiated by python, and then start a sub process to execute the user's Python code python_file.py. Python_file.py will initiate various Spark operations through py4j, as in the previous article[ How PySpark works ]Mentioned.
/** * A main class used to launch Python applications. It executes python as a * subprocess and then has it connect back to the JVM to access system properties, etc. */ object PythonRunner { def main(args: Array[String]) { val pythonFile = args(0) val pyFiles = args(1) val otherArgs = args.slice(2, args.length) val sparkConf = new SparkConf() val secret = Utils.createSecret(sparkConf) val pythonExec = sparkConf.get(PYSPARK_DRIVER_PYTHON) .orElse(sparkConf.get(PYSPARK_PYTHON)) .orElse(sys.env.get("PYSPARK_DRIVER_PYTHON")) .orElse(sys.env.get("PYSPARK_PYTHON")) .getOrElse("python") // Format python file paths before adding them to the PYTHONPATH val formattedPythonFile = formatPath(pythonFile) val formattedPyFiles = resolvePyFiles(formatPaths(pyFiles)) // Launch a Py4J gateway server for the process to connect to; this will let it see our // Java system properties and such val localhost = InetAddress.getLoopbackAddress() val gatewayServer = new py4j.GatewayServer.GatewayServerBuilder() .authToken(secret) .javaPort(0) .javaAddress(localhost) .callbackClient(py4j.GatewayServer.DEFAULT_PYTHON_PORT, localhost, secret) .build() val thread = new Thread(new Runnable() { override def run(): Unit = Utils.logUncaughtExceptions { gatewayServer.start() } }) thread.setName("py4j-gateway-init") thread.setDaemon(true) thread.start() // Wait until the gateway server has started, so that we know which port is it bound to. // `gatewayServer.start()` will start a new thread and run the server code there, after // initializing the socket, so the thread started above will end as soon as the server is // ready to serve connections. thread.join() // Build up a PYTHONPATH that includes the Spark assembly (where this class is), the // python directories in SPARK_HOME (if set), and any files in the pyFiles argument val pathElements = new ArrayBuffer[String] pathElements ++= formattedPyFiles pathElements += PythonUtils.sparkPythonPath pathElements += sys.env.getOrElse("PYTHONPATH", "") val pythonPath = PythonUtils.mergePythonPaths(pathElements: _*) // Launch Python process val builder = new ProcessBuilder((Seq(pythonExec, formattedPythonFile) ++ otherArgs).asJava) val env = builder.environment() env.put("PYTHONPATH", pythonPath) // This is equivalent to setting the -u flag; we use it because ipython doesn't support -u: env.put("PYTHONUNBUFFERED", "YES") // value is needed to be set to a non-empty string env.put("PYSPARK_GATEWAY_PORT", "" + gatewayServer.getListeningPort) env.put("PYSPARK_GATEWAY_SECRET", secret) // pass conf spark.pyspark.python to python process, the only way to pass info to // python process is through environment variable. sparkConf.get(PYSPARK_PYTHON).foreach(env.put("PYSPARK_PYTHON", _)) sys.env.get("PYTHONHASHSEED").foreach(env.put("PYTHONHASHSEED", _)) builder.redirectErrorStream(true) // Ugly but needed for stdout and stderr to synchronize try { val process = builder.start() new RedirectThread(process.getInputStream, System.out, "redirect output").start() val exitCode = process.waitFor() if (exitCode != 0) { throw new SparkUserAppException(exitCode) } } finally { gatewayServer.shutdown() } }
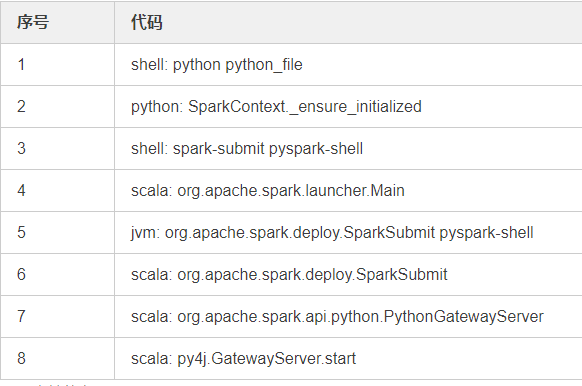
/path/to/python python_file
-
Execute Python? File.py directly
-
Call sparkcontext. ﹣ ensure ﹣ initialized to initialize Spark Context (step 2), call launch ﹣ gateway to create Spark py4j.GatewayServer instance. In fact, the final step is to start a sub process to execute spark submit pyspark shell (step 3)
@classmethod
def _ensure_initialized(cls, instance=None, gateway=None, conf=None):
"""
Checks whether a SparkContext is initialized or not.
Throws error if a SparkContext is already running.
"""
with SparkContext._lock:
if not SparkContext._gateway:
SparkContext._gateway = gateway or launch_gateway(conf)
SparkContext._jvm = SparkContext._gateway.jvm
def _launch_gateway(conf=None, insecure=False): """ launch jvm gateway :param conf: spark configuration passed to spark-submit :param insecure: True to create an insecure gateway; only for testing :return: a JVM gateway """ if insecure and os.environ.get("SPARK_TESTING", "0") != "1": raise ValueError("creating insecure gateways is only for testing") if "PYSPARK_GATEWAY_PORT" in os.environ: gateway_port = int(os.environ["PYSPARK_GATEWAY_PORT"]) gateway_secret = os.environ["PYSPARK_GATEWAY_SECRET"] else: SPARK_HOME = _find_spark_home() # Launch the Py4j gateway using Spark's run command so that we pick up the # proper classpath and settings from spark-env.sh on_windows = platform.system() == "Windows" script = "./bin/spark-submit.cmd" if on_windows else "./bin/spark-submit" command = [os.path.join(SPARK_HOME, script)] if conf: for k, v in conf.getAll(): command += ['--conf', '%s=%s' % (k, v)] submit_args = os.environ.get("PYSPARK_SUBMIT_ARGS", "pyspark-shell") if os.environ.get("SPARK_TESTING"): submit_args = ' '.join([ "--conf spark.ui.enabled=false", submit_args ]) command = command + shlex.split(submit_args) # Create a temporary directory where the gateway server should write the connection # information. conn_info_dir = tempfile.mkdtemp() try: fd, conn_info_file = tempfile.mkstemp(dir=conn_info_dir) os.close(fd) os.unlink(conn_info_file) env = dict(os.environ) env["_PYSPARK_DRIVER_CONN_INFO_PATH"] = conn_info_file if insecure: env["_PYSPARK_CREATE_INSECURE_GATEWAY"] = "1" # Launch the Java gateway. # We open a pipe to stdin so that the Java gateway can die when the pipe is broken if not on_windows: # Don't send ctrl-c / SIGINT to the Java gateway: def preexec_func(): signal.signal(signal.SIGINT, signal.SIG_IGN) proc = Popen(command, stdin=PIPE, preexec_fn=preexec_func, env=env) else: # preexec_fn not supported on Windows proc = Popen(command, stdin=PIPE, env=env) # Wait for the file to appear, or for the process to exit, whichever happens first. while not proc.poll() and not os.path.isfile(conn_info_file): time.sleep(0.1) if not os.path.isfile(conn_info_file): raise Exception("Java gateway process exited before sending its port number") with open(conn_info_file, "rb") as info: gateway_port = read_int(info) gateway_secret = UTF8Deserializer().loads(info) finally: shutil.rmtree(conn_info_dir) # In Windows, ensure the Java child processes do not linger after Python has exited. # In UNIX-based systems, the child process can kill itself on broken pipe (i.e. when # the parent process' stdin sends an EOF). In Windows, however, this is not possible # because java.lang.Process reads directly from the parent process' stdin, contending # with any opportunity to read an EOF from the parent. Note that this is only best # effort and will not take effect if the python process is violently terminated. if on_windows: # In Windows, the child process here is "spark-submit.cmd", not the JVM itself # (because the UNIX "exec" command is not available). This means we cannot simply # call proc.kill(), which kills only the "spark-submit.cmd" process but not the # JVMs. Instead, we use "taskkill" with the tree-kill option "/t" to terminate all # child processes in the tree (http://technet.microsoft.com/en-us/library/bb491009.aspx) def killChild(): Popen(["cmd", "/c", "taskkill", "/f", "/t", "/pid", str(proc.pid)]) atexit.register(killChild) # Connect to the gateway gateway_params = GatewayParameters(port=gateway_port, auto_convert=True) if not insecure: gateway_params.auth_token = gateway_secret gateway = JavaGateway(gateway_parameters=gateway_params) # Import the classes used by PySpark java_import(gateway.jvm, "org.apache.spark.SparkConf") java_import(gateway.jvm, "org.apache.spark.api.java.*") java_import(gateway.jvm, "org.apache.spark.api.python.*") java_import(gateway.jvm, "org.apache.spark.ml.python.*") java_import(gateway.jvm, "org.apache.spark.mllib.api.python.*") # TODO(davies): move into sql java_import(gateway.jvm, "org.apache.spark.sql.*") java_import(gateway.jvm, "org.apache.spark.sql.api.python.*") java_import(gateway.jvm, "org.apache.spark.sql.hive.*") java_import(gateway.jvm, "scala.Tuple2") return gateway
Next, the process is similar to the first method. This time, the selected class is org.apache.spark.api.python.python gateway server. Let's take a look at the code, which is to start a py4j.gateway server to handle requests from Python side
/** * Process that starts a Py4J GatewayServer on an ephemeral port. * * This process is launched (via SparkSubmit) by the PySpark driver (see java_gateway.py). */ private[spark] object PythonGatewayServer extends Logging { initializeLogIfNecessary(true) def main(args: Array[String]): Unit = { val secret = Utils.createSecret(new SparkConf()) // Start a GatewayServer on an ephemeral port. Make sure the callback client is configured // with the same secret, in case the app needs callbacks from the JVM to the underlying // python processes. val localhost = InetAddress.getLoopbackAddress() val builder = new GatewayServer.GatewayServerBuilder() .javaPort(0) .javaAddress(localhost) .callbackClient(GatewayServer.DEFAULT_PYTHON_PORT, localhost, secret) if (sys.env.getOrElse("_PYSPARK_CREATE_INSECURE_GATEWAY", "0") != "1") { builder.authToken(secret) } else { assert(sys.env.getOrElse("SPARK_TESTING", "0") == "1", "Creating insecure Java gateways only allowed for testing") } val gatewayServer: GatewayServer = builder.build() gatewayServer.start() val boundPort: Int = gatewayServer.getListeningPort if (boundPort == -1) { logError("GatewayServer failed to bind; exiting") System.exit(1) } else { logDebug(s"Started PythonGatewayServer on port $boundPort") } // Communicate the connection information back to the python process by writing the // information in the requested file. This needs to match the read side in java_gateway.py. val connectionInfoPath = new File(sys.env("_PYSPARK_DRIVER_CONN_INFO_PATH")) val tmpPath = Files.createTempFile(connectionInfoPath.getParentFile().toPath(), "connection", ".info").toFile() val dos = new DataOutputStream(new FileOutputStream(tmpPath)) dos.writeInt(boundPort) val secretBytes = secret.getBytes(UTF_8) dos.writeInt(secretBytes.length) dos.write(secretBytes, 0, secretBytes.length) dos.close() if (!tmpPath.renameTo(connectionInfoPath)) { logError(s"Unable to write connection information to $connectionInfoPath.") System.exit(1) } // Exit on EOF or broken pipe to ensure that this process dies when the Python driver dies: while (System.in.read() != -1) { // Do nothing } logDebug("Exiting due to broken pipe from Python driver") System.exit(0) } }
/path/to/pyspark

-
pyspark is a shell script
-
1 will call another shell command spark submit pyspark shell main
-
2 will call another shell command spark class
-
3. A java class, org.apache.spark.launcher.Main, will be executed to override the SparkSubmit parameter
-
3. Then a python process will be started, which is the pyspark that finally interacts with the user
-
When the python process starts, it will first execute the Python code specified by the environment variable $PYTHONSTARTUP. This code is pyspark/python/pyspark/shell.py. This environment variable is set in the shell script 1. Then let's look at the shell.py code
from pyspark import SparkConf from pyspark.context import SparkContext from pyspark.sql import SparkSession, SQLContext if os.environ.get("SPARK_EXECUTOR_URI"): SparkContext.setSystemProperty("spark.executor.uri", os.environ["SPARK_EXECUTOR_URI"]) SparkContext._ensure_initialized() try: spark = SparkSession._create_shell_session() except Exception: import sys import traceback warnings.warn("Failed to initialize Spark session.") traceback.print_exc(file=sys.stderr) sys.exit(1) sc = spark.sparkContext sql = spark.sql atexit.register(lambda: sc.stop())
- shell.py calls sparkcontext. Ensure_initialized. The next procedure is the same as the second method. The selected class is also org.apache.spark.api.python.PythonGatewayServer, that is, a py4j.GatewayServer, which processes the requests initiated by python
summary
This paper analyzes three ways to start PySpark with code, each of which has its own characteristics and the principle is the same. However, different methods can mine some skills, realize some customized functions and integrate with their own products.

