review
In the previous article, we analyzed the type conversion, log adapter, class loading module and resolverutil (used to find qualified classes under the specified package), and also saw some design patterns used, such as adapter pattern and singleton pattern
Next, go to a core of the basic support layer, DataSource
DataSource
In the data persistence layer, the data source is a very important component, and the performance will directly affect the performance of the whole persistence layer.
Most of the time, we use third-party data sources, such as Apache Common DBCP, C3P0, Proxool, etc. MyBatis not only supports custom integration of third-party data source components, but also provides its own data source implementation
First, we need to know the DataSource interface, which is under javax.sql.DataSource
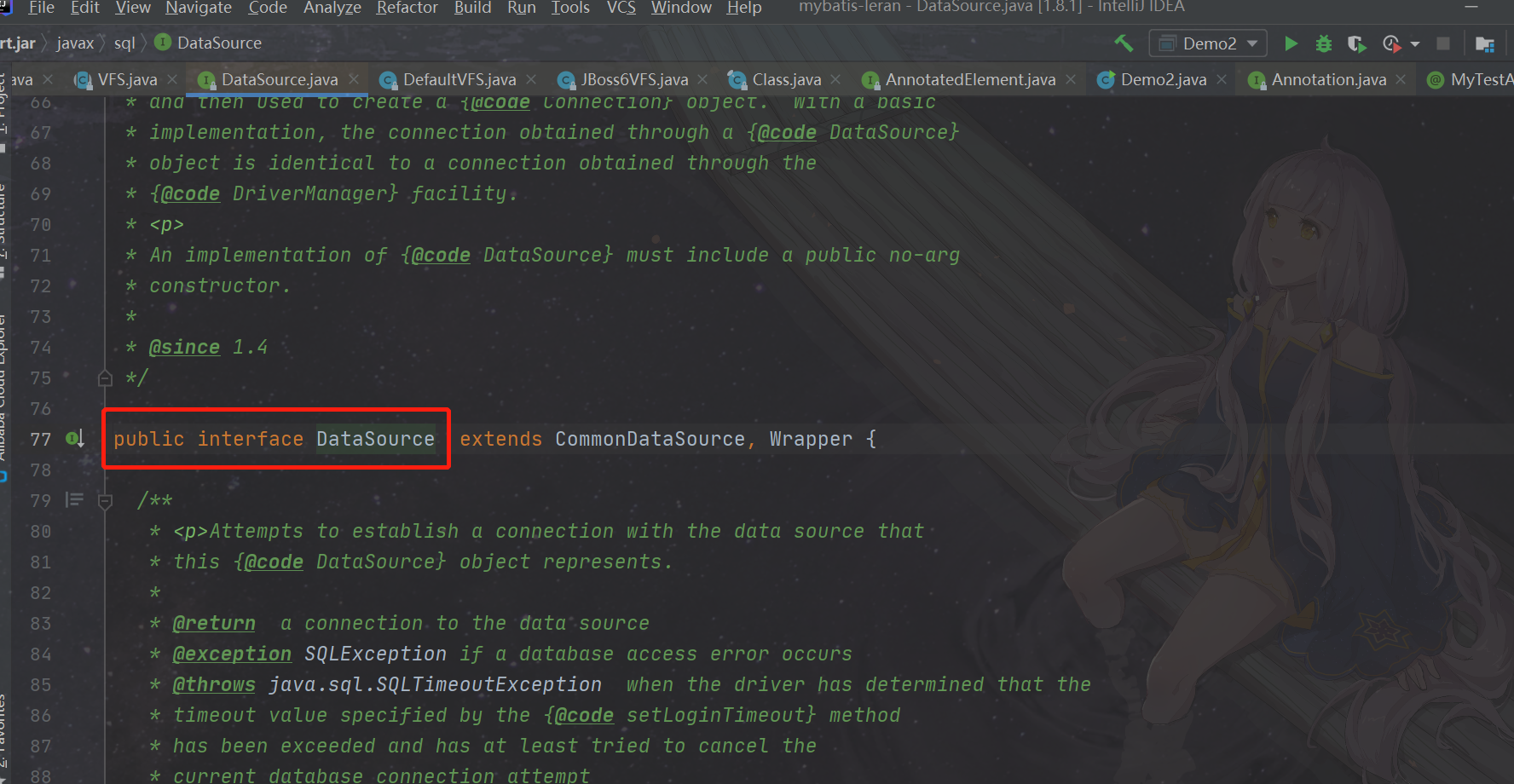
Common data source components implement this DataSource interface, so the data source defined by MyBatis will also implement this interface. We can know how many data sources MyBatis implements, and in the factory mode, the product produced is a DataSource
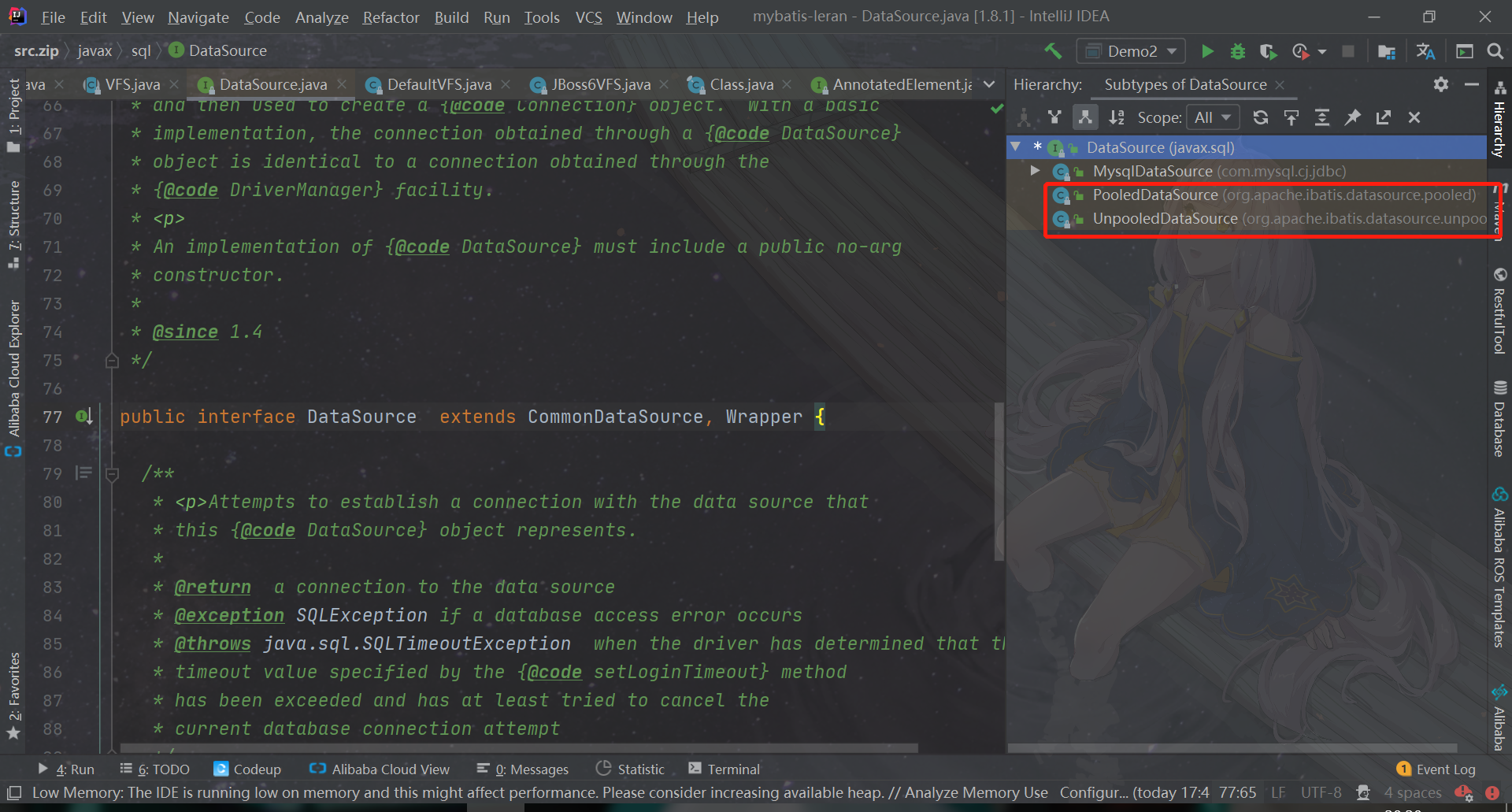
As you can see, there are two implementations for MyBatis
- PooledDataSource
- UnpooledDataSource
MyBati has multiple data sources, so how does MyBatis manage it?
DataSourceFactory
For multiple data sources, MyBatis uses DataSourceFactory for management. From here, you can probably estimate that the factory mode is used
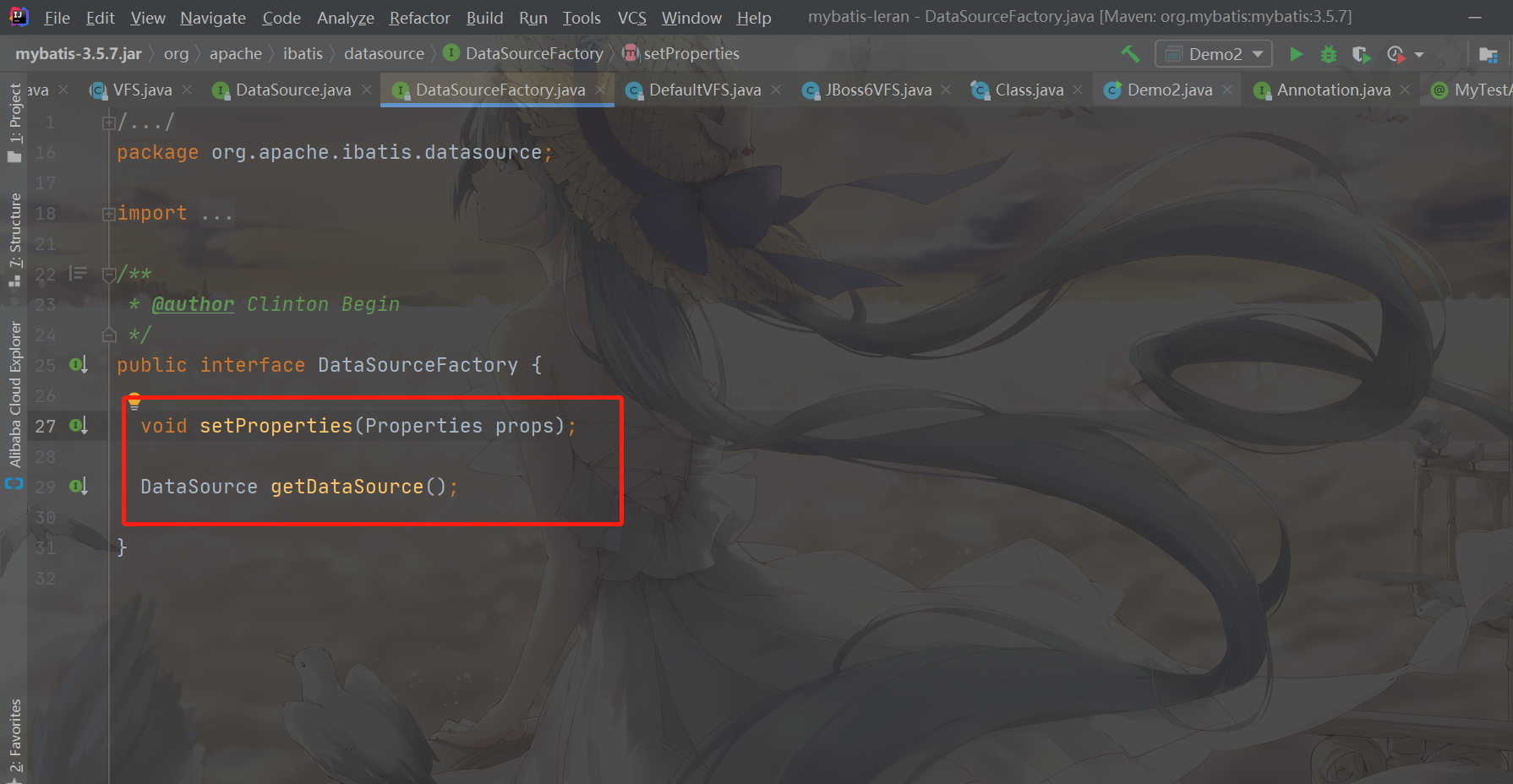
As you can see from the above, the DataSourceFactory interface only provides two methods
- setProperties: sets properties related to the data source
- getDataSource: get data source
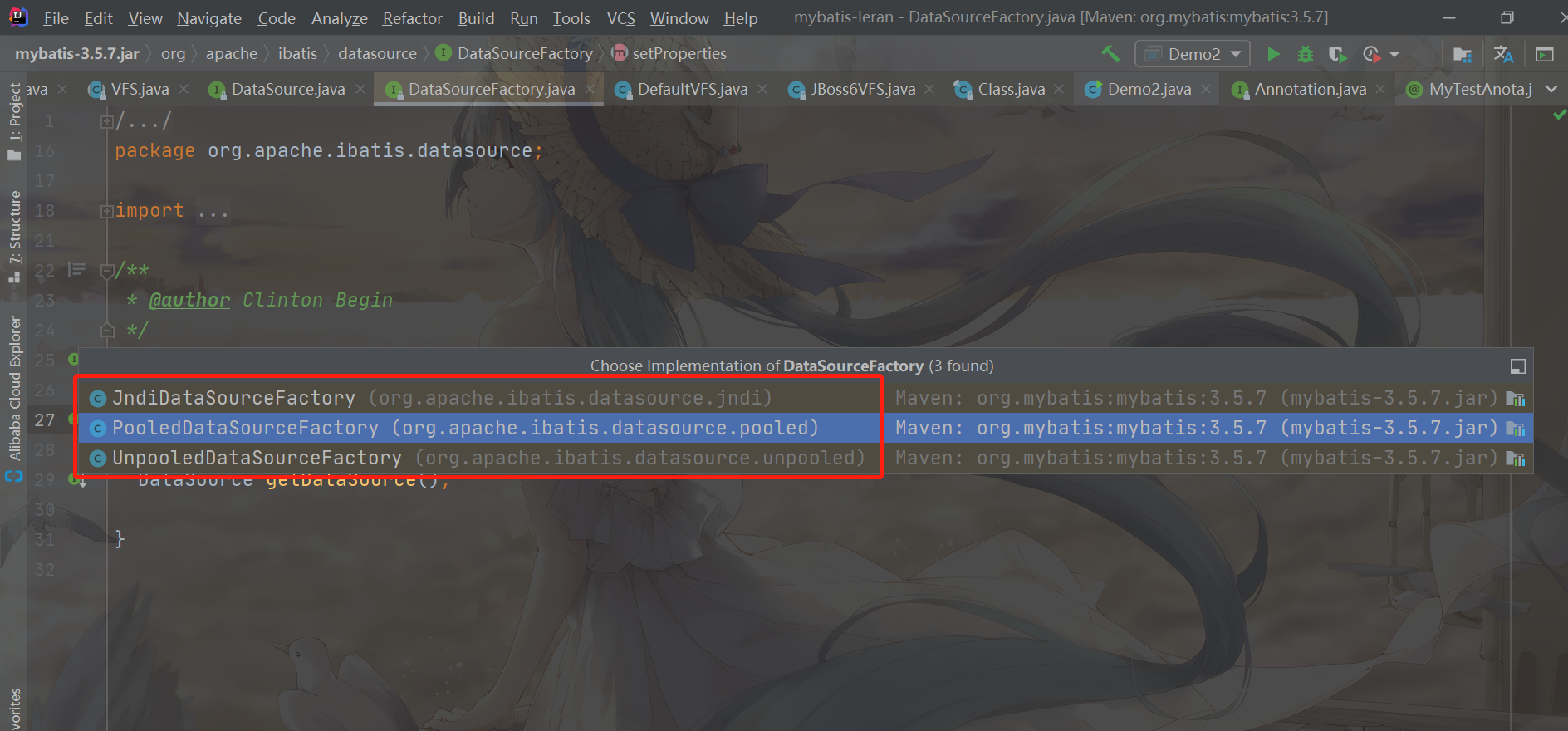
As you can see, MyBatis has three implementation classes for the DataSourceFactory interface
- JndiDataSourceFactory:
- PooledDataSourceFactory: creates a PooledDataSource data source
- UnpooledDataSourceFactory: creates an UnpooledDataSource data source
UnpooledDataSourceFactory
Let's first look at the creation factory of UnpooledDataSource data source
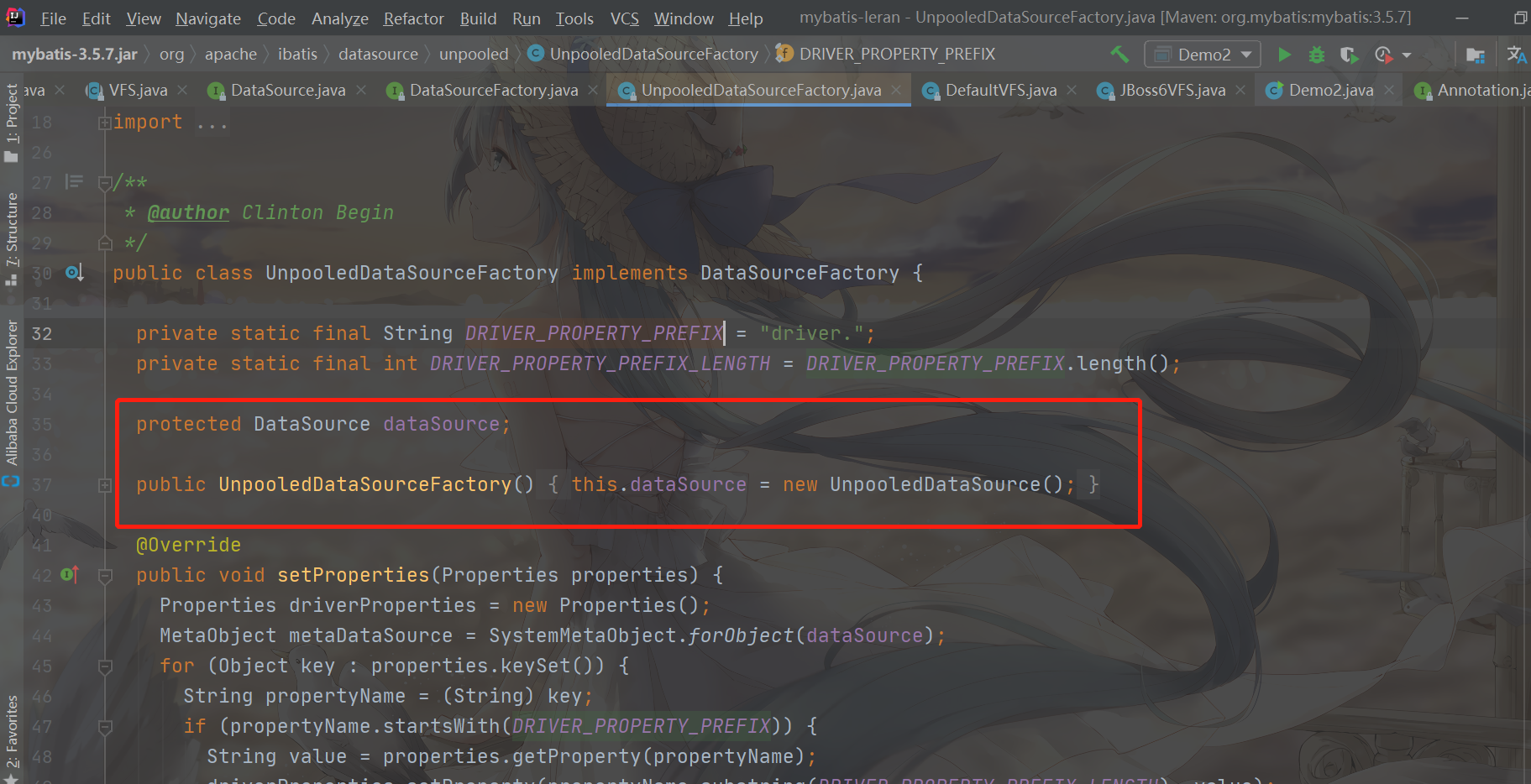
From the construction method, we can see that when the UnPooledDataSourceFactory is instantiated, the UnpooledDataSource will be created and injected into its own DataSource member property
Let's take a look at how the getDataSource method in DataSourceFactory is implemented
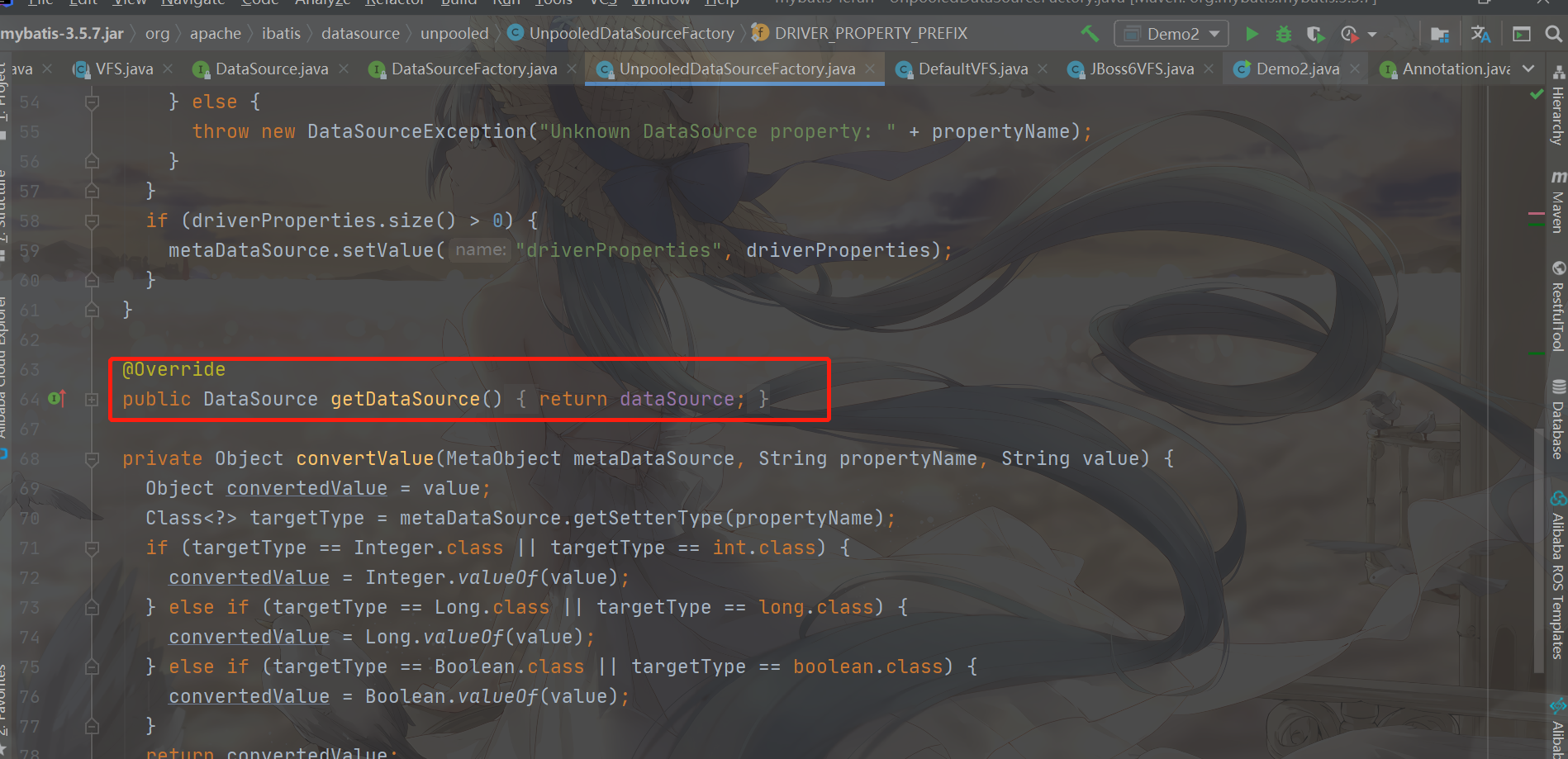
As you can see, it is very simple and returns the constructed UnpooledDataSource directly
Next, let's see how to rewrite the setProperty method. The source code is as follows
public void setProperties(Properties properties) {
//Store configuration for DataSource
Properties driverProperties = new Properties();
//Use SystemMetaObject to create a MetaObject object of DataSource
//We have already mentioned this MetaObject object, which is used by MyBatis to manage the information of instance objects!!!!
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
//Traverse the properties to set
for (Object key : properties.keySet()) {
//Gets the name of the property currently to be set
String propertyName = (String) key;
//If it's a driver
//Represents the configuration of the DataSource
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
//Add to the driverProperties collection
String value = properties.getProperty(propertyName);
driverProperties.setProperty(propertyName.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
}
//The following is how to set other related properties. You must have a setter method to set them
else if (metaDataSource.hasSetter(propertyName)) {
//Call the set method to set properties
String value = (String) properties.get(propertyName);
Object convertedValue = convertValue(metaDataSource, propertyName, value);
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
//Finally, set the configuration of DataSource
if (driverProperties.size() > 0) {
metaDataSource.setValue("driverProperties", driverProperties);
}
}
It can be seen that UnpooledDataSourceFactory first converts DataSource to MetaObject for setProperty method, and then continues to inject set. Therefore, we can see MyBatis's application of MetaObject, which converts the current instance DataSource to MetaObject (MetaObject can be used to manage instance information), and then modifies or injects the corresponding properties
PooledDataSourceFactory
PooledDataSourceFactory is simpler. It is used to create PooledDataSource
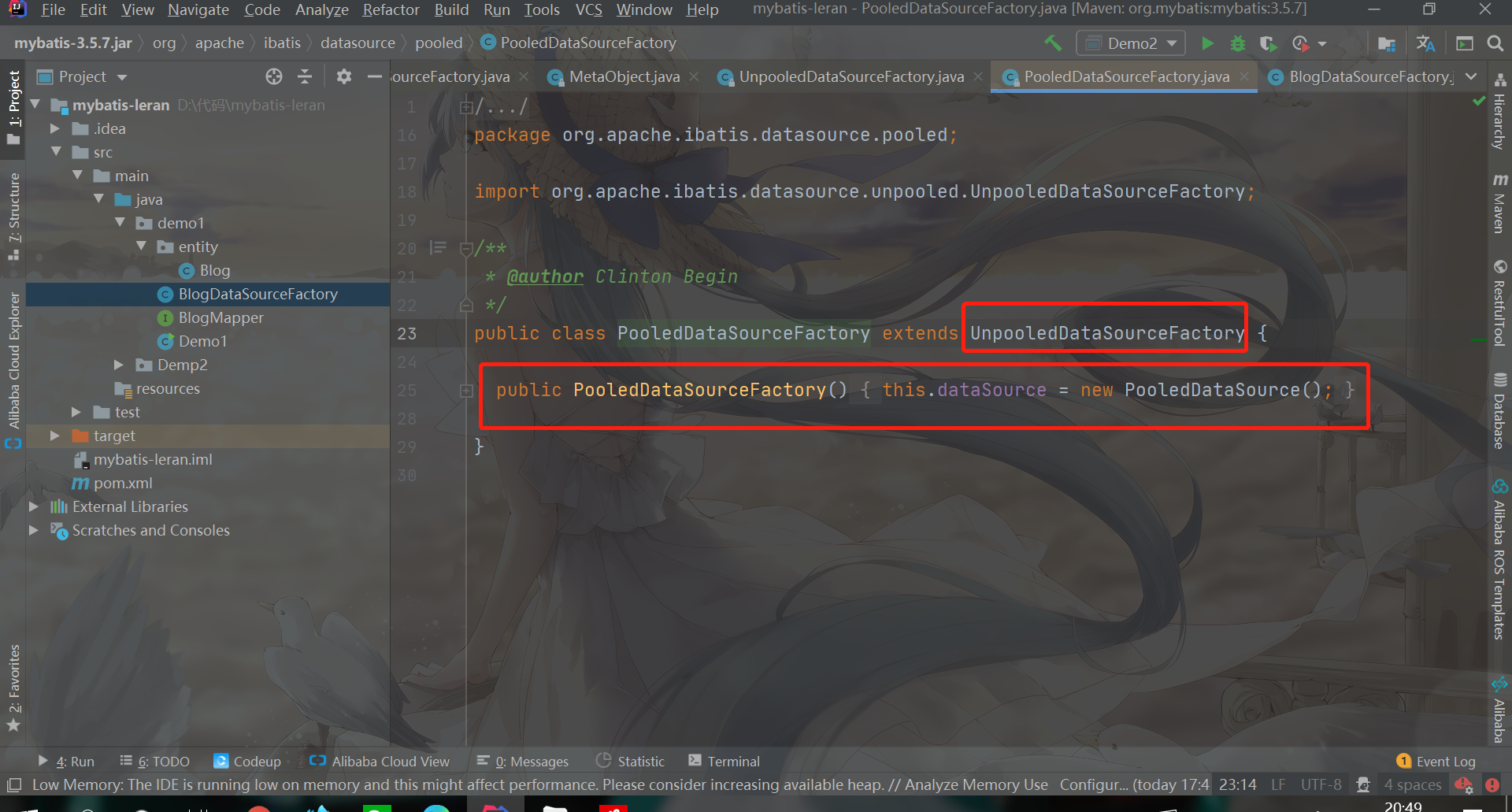
It can be seen that PooledDataSourceFactory inherits UnpooledDataSourceFactory, but the construction method is different. PooledDataSourceFactory creates PooledDataSource, while UnpooledDataSourceFactory creates UnPooledDataSource
Other methods, such as obtaining data sources and setting data source properties, are the same as UnpooledDataSourceFactory
JndiDataSourceFactory
JNDI datasourcefactory uses JNDI services to set up third-party data sources. When the previous JVM learned the parental delegation model, the JNDI service can destroy the sequential parental delegation model
JNDI
JNDI, whose full name is Java Naming and Directory Interface, is a set of API specifications provided by Sum company. Its function is to imitate the registry of Window
It is equivalent to storing the user's configuration in the registry, and then JNDI can get the information from the registry
The Jndi datasourcefactory i is used to obtain the user configured DataSource from the container
After reading DataSourceFactory, let's take a look at DataSource
UnpooledDataSource
UnpooledDataSource is characterized by the same name. There is no pool, that is, there is no connection pool. A new connection will be created every time a database connection is obtained
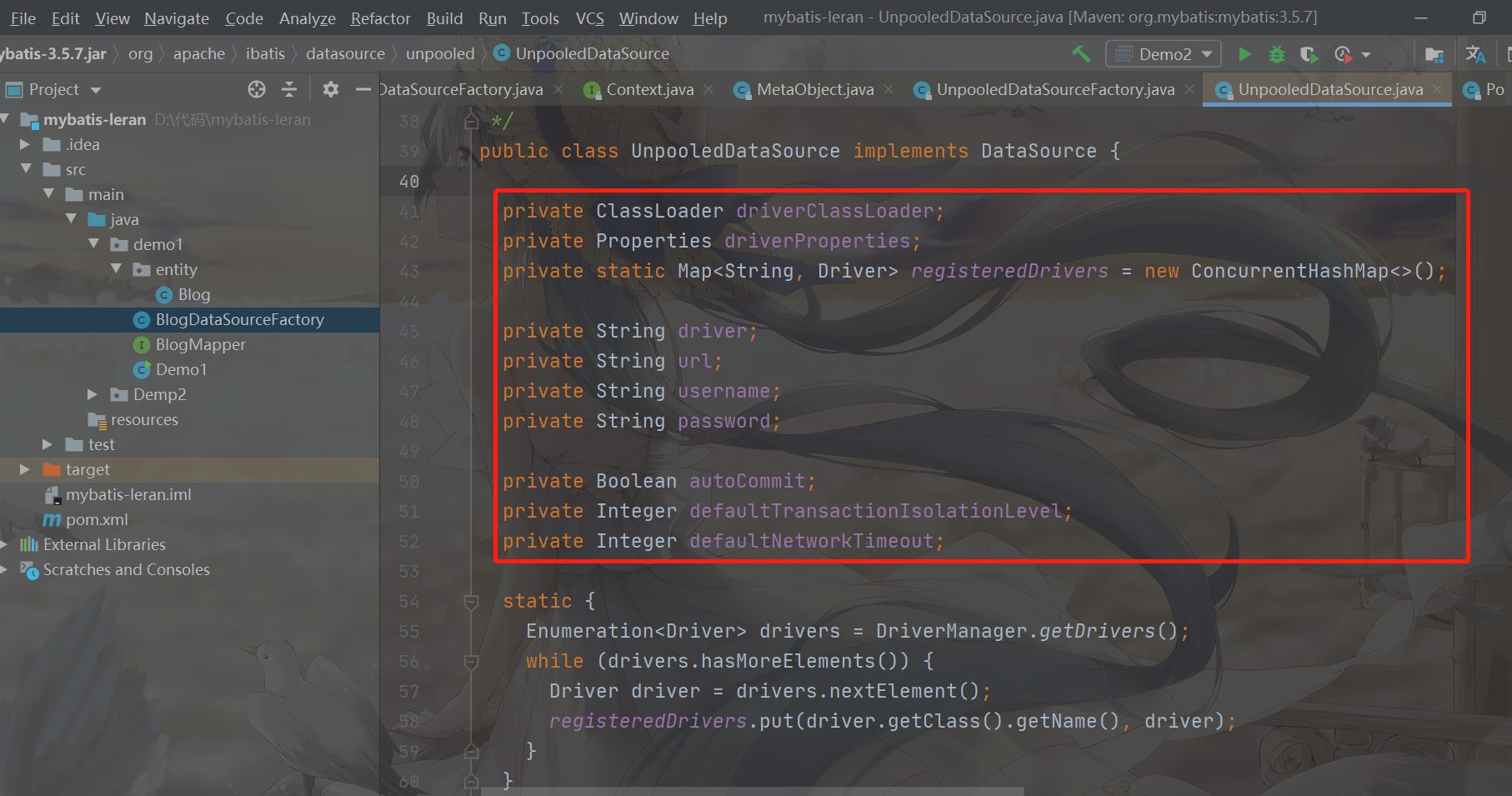
Let's take a look at the member properties of UnpooledDataSourced
-
driverClassLoader: the class loader that loads the Driver class
-
Driver porperties: database connection driver related configurations
-
Registered drivers: cache all registered database connection drivers
-
Driver: the name of the driver for the database connection
-
URL: database URL
-
username: user name
-
Password: password
-
autoCommit: Auto commit
-
defaultTransactionIslationLevel: the default transaction isolation level
-
defaultNetworkTimeout: the default network connection timeout
Recall using native JDBC
Step 1: register driver, DriverManager.registerDriver
After registering the driver, it is also saved in a container of DriverManger, as shown below
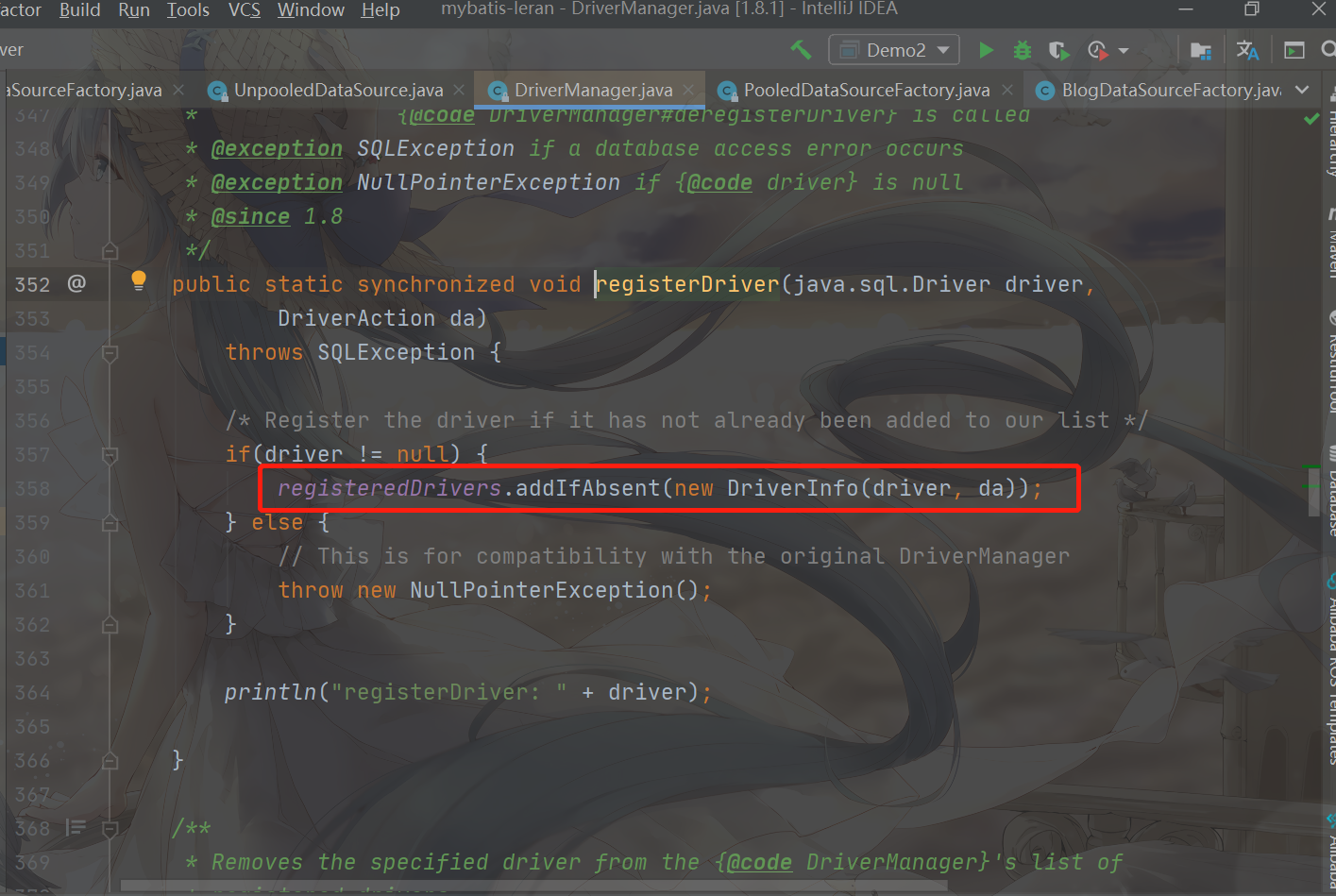
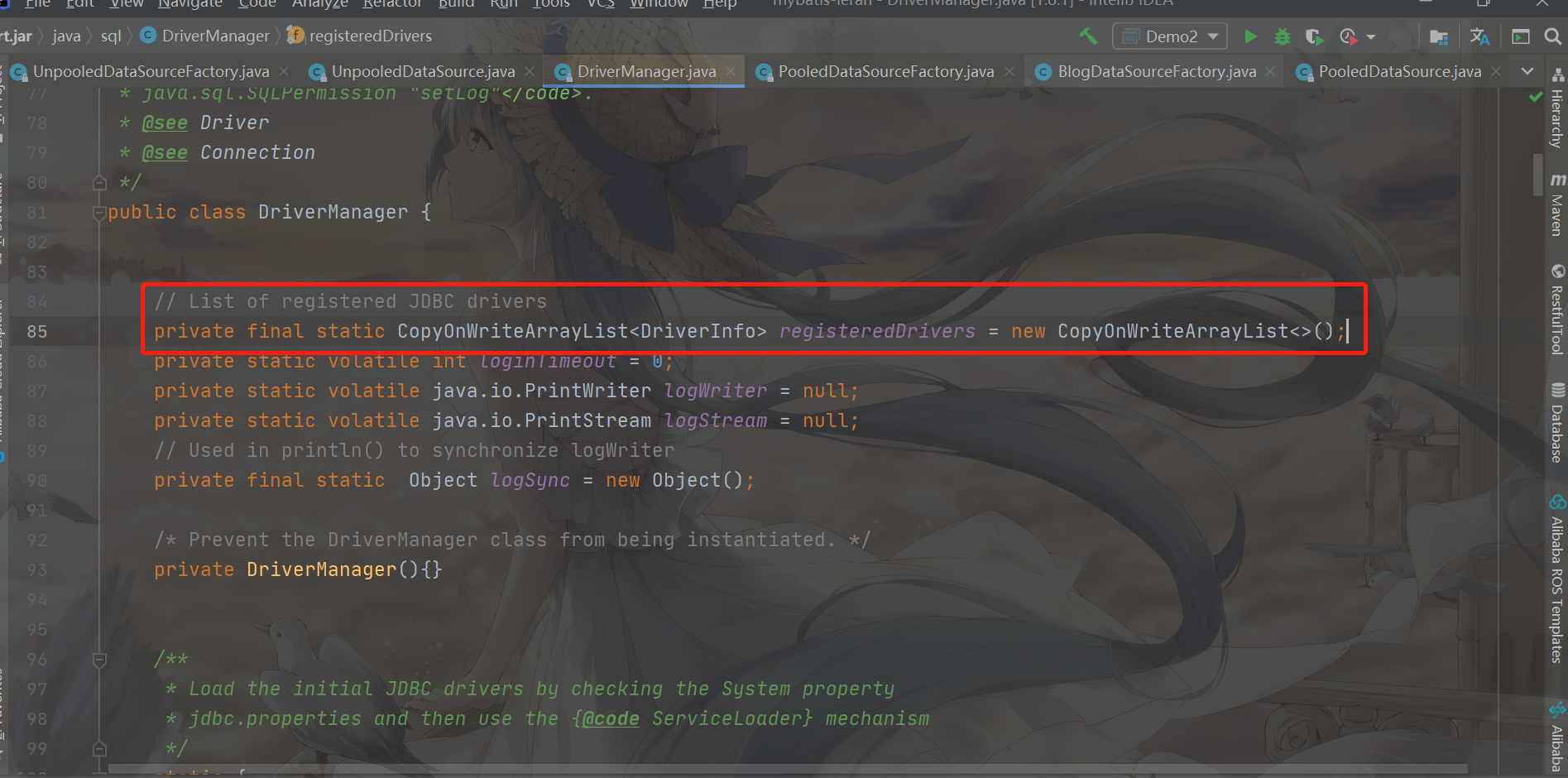
Let's look at the static code block again, because the static code block will be executed when the UnpooledDataSource is accessed for the first time
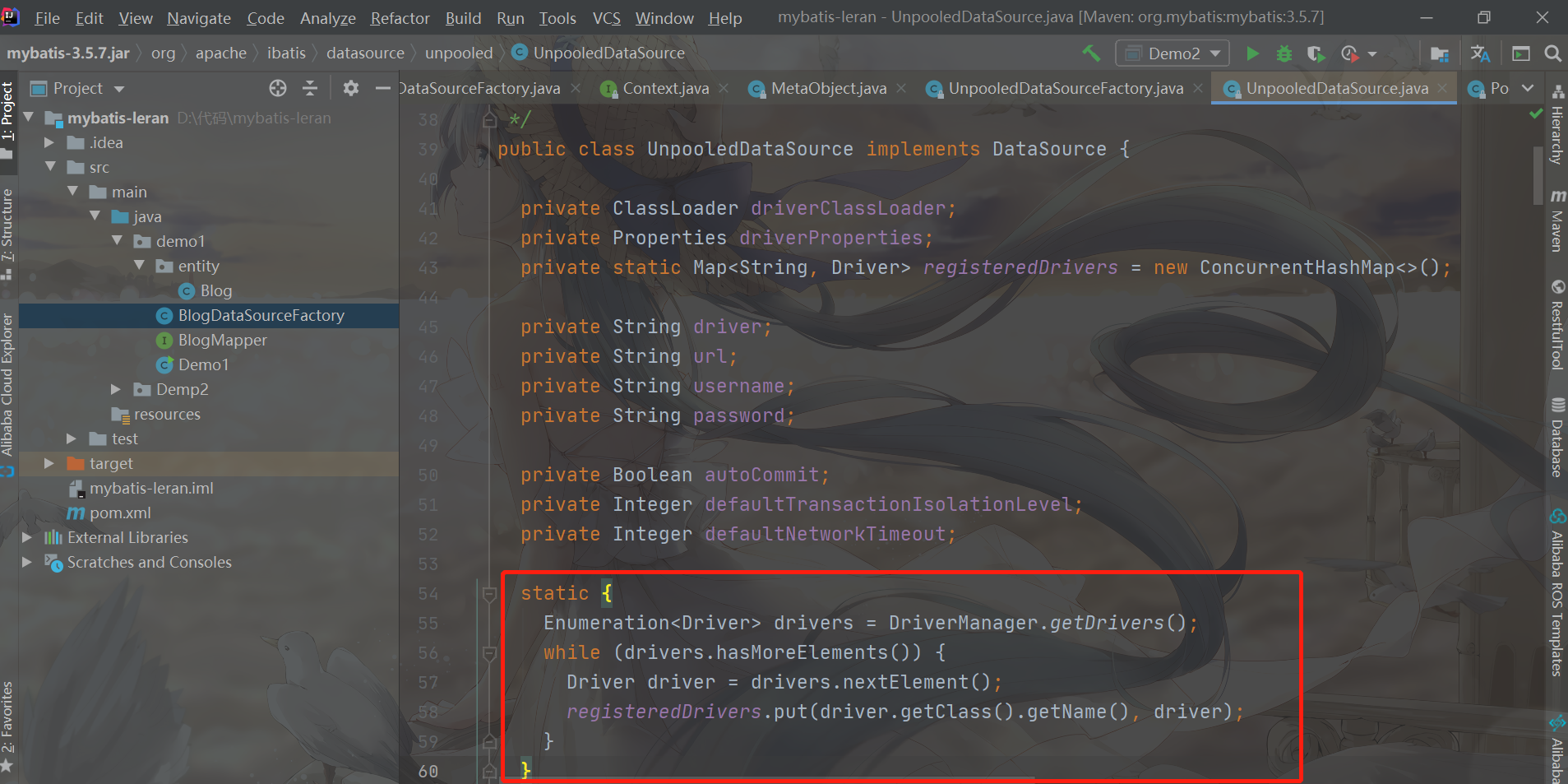
The source code is as follows
static {
//Get the driver registered in DriverManager
Enumeration<Driver> drivers = DriverManager.getDrivers();
//Traversal adds all registered drivers to the cache
while (drivers.hasMoreElements()) {
Driver driver = drivers.nextElement();
registeredDrivers.put(driver.getClass().getName(), driver);
}
}
You can see that registering drivers is not done in the DataSource, and the DataSource also supports a variety of drivers!!!!!! To put it bluntly, it supports multiple databases
Let's take a look at how to get the connection
getConnection
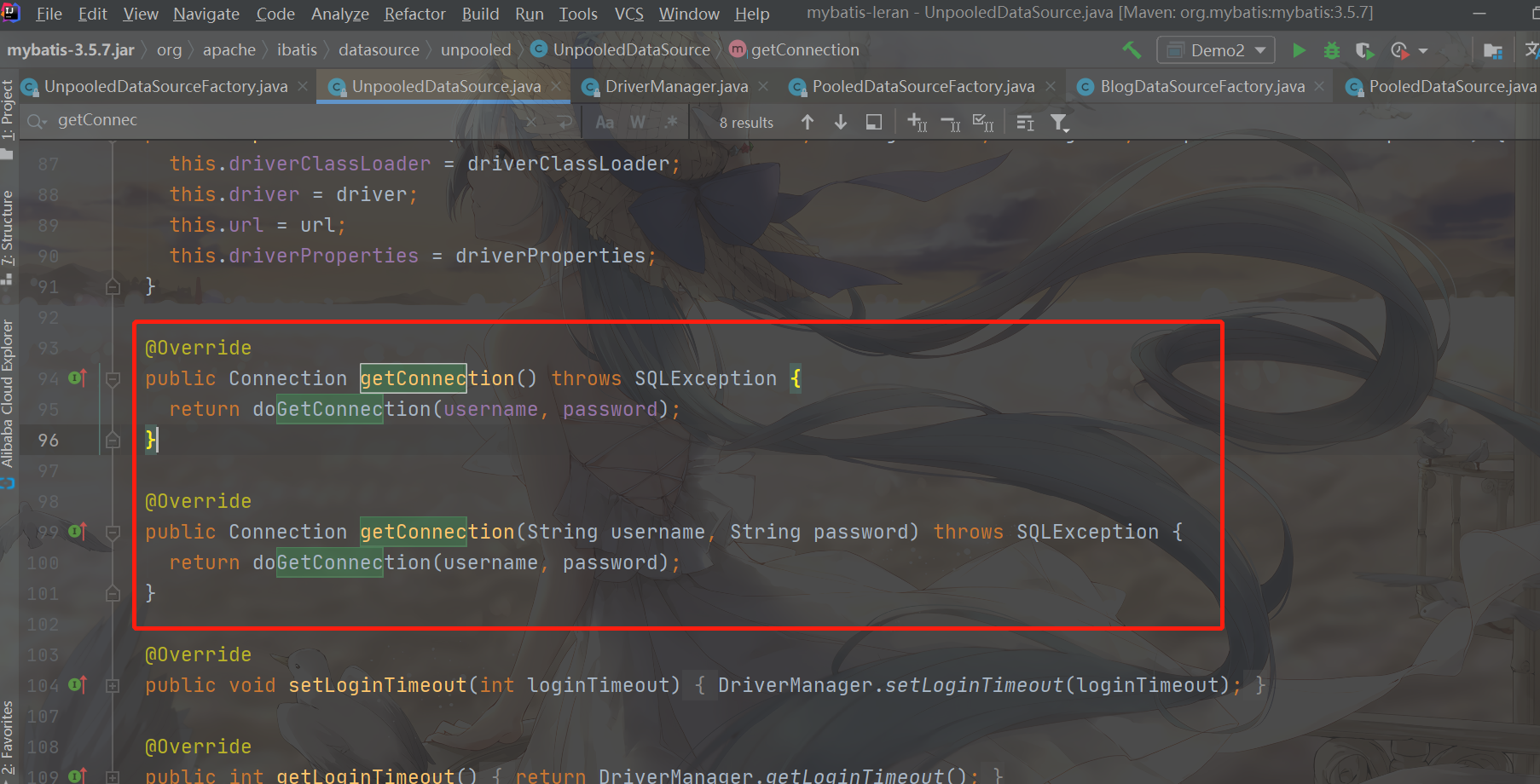
getConnection corresponds to obtaining a Connection connection. You can see that it calls the doGetConnection method. However, the framework likes to give the actual operation to the doxxx method. The same is true in the Spring framework. It is already a createBean and needs to be pushed to doCreateBean for implementation
Let's take a look at what doGetConnection does
The source code is as follows
private Connection doGetConnection(String username, String password) throws SQLException {
//Get the configuration parameters of the encapsulation connection
//Properties is essentially a HashTable
//Properties is also a class under java.util. It is Java Native and suitable for storing some key value pair configuration information
Properties props = new Properties();
//Load all data source configurations
if (driverProperties != null) {
props.putAll(driverProperties);
}
//Load user name
if (username != null) {
props.setProperty("user", username);
}
//Load password
if (password != null) {
props.setProperty("password", password);
}
//Call the overloaded method of doGetConnection
return doGetConnection(props);
}
It can be seen that only encapsulation parameters are made in this layer, which encapsulates the configuration of the data source, the account and password connecting the data source, and then delegate to the doGetConnection method
The overloaded doGetConnection source code is as follows
private Connection doGetConnection(Properties properties) throws SQLException {
//Initialize the driver for no driver
initializeDriver();
//Use DriverManager to get connections......
Connection connection = DriverManager.getConnection(url, properties);
//Configure some information for the obtained connection
configureConnection(connection);
return connection;
}
The steps are as follows
- Initialization drive
- Use DriverManager to obtain Connection based on database URL and configuration information
- Configure the Connection
- Return to Connection
The following steps are analyzed one by one
initializeDriver
The source code is as follows
private synchronized void initializeDriver() throws SQLException {
//Determine whether the driver has been registered
if (!registeredDrivers.containsKey(driver)) {
Class<?> driverType;
try {
//If the driver is not registered
//Use ClassLoader to create driver classes
//It is created according to the name of the driver, so the name of the driver here should be a fully qualified class name
if (driverClassLoader != null) {
driverType = Class.forName(driver, true, driverClassLoader);
} else {
driverType = Resources.classForName(driver);
}
//Use reflection to create an instance of the driver
Driver driverInstance = (Driver) driverType.getDeclaredConstructor().newInstance();
//DriverManager to register drivers
DriverManager.registerDriver(new DriverProxy(driverInstance));
//And add the registered driver to the cache
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}
You can see that initializing the driver is actually to judge whether the driver of UnpooledDataSource has been registered (although there is a cache, only one driver can be used!!!). If it is not registered, it means that there is no name of the current driver in the cache. If there is, it means it has been registered, and if there is no, it means it has not been registered, If there is no registered driver, you need to use ClassLoader + reflection to create a driver instance, and then hand it over to the DriverManager to register the driver. After registering the driver, add the registered driver to the cache
DriverManager.getConnection
There's nothing to say about using DriverManager.getConnection to get a connection
configureConnection
The next step is to configure the Connection, whether to automatically commit, the timeout setting, and the default transaction isolation level. The source code is as follows
private void configureConnection(Connection conn) throws SQLException {
//Judge whether the defined default timeout is not empty
if (defaultNetworkTimeout != null) {
//If the timeout time is defined, redefine the timeout time of the Connection
conn.setNetworkTimeout(Executors.newSingleThreadExecutor(), defaultNetworkTimeout);
}
//Determine whether there is a custom auto submit attribute
//If the automatic submission property is set and the custom submission property is different from the original default of Connection
if (autoCommit != null && autoCommit != conn.getAutoCommit()) {
//Make settings
//The reason why the judgment here is complex is that I think it should be automatic submission, which is a sensitive attribute
conn.setAutoCommit(autoCommit);
}
//If the customized default transaction isolation mechanism is not empty
if (defaultTransactionIsolationLevel != null) {
//Set a custom transaction isolation mechanism for Connection
conn.setTransactionIsolation(defaultTransactionIsolationLevel);
}
}
As you can see from the code, the configuration of the created Connection is actually aimed at the following three aspects
- Network timeout
- Auto submit
- Transaction isolation mechanism
It can be seen from the whole process of obtaining the Connection that getConnection will call DriverManager to create a Connection and create a new Connection every time, which is also the reason for unPooled
PooledDataSource
Creating a database Connection is a very time-consuming operation, and the number of connections that can be established by the database is also limited. Therefore, in most systems, database Connection is a very precious resource, and database Connection pool is very necessary. Using database Connection pool will bring a series of benefits, for example, It can realize the reuse of database Connection, improve the response speed, prevent too many database connections from causing database fake death, and avoid database Connection leakage at the same time
What is the workflow of database connection pool?
-
When the database connection pool is initialized, a certain number of database connections will be created and added to the connection pool for standby
-
When the program needs to use a connection, get the connection from the pool
-
When the program finishes using the connection, it will return the connection to the pool and wait for the next use instead of closing it directly
-
The database connection pool will guarantee a certain number of connections and control the upper limit of the total number of online and idle connections. If the total number of connections created by the connection pool reaches the online level and are all occupied, the subsequent threads that want to obtain connections from the connection pool will enter the blocking queue and wait until the threads release available connections; If there are a large number of free connections in the connection pool and the free connections are online, the subsequent used connections will be closed directly when they return (generally become free connections), because maintaining free connections also requires overhead
Let's analyze the problems that the online settings of total connections and idle connections are too large or too small
- Total connections: represents the number of Connection instances in the Connection pool. If it is set too large, it will easily lead to database deadlock (too many connections); If the setting is too small, the performance of the database cannot be played, and the user thread is affected (blocked)
- Free connections: represents the number of free connections in the Connection pool. If it is set too large, too many system resources will be wasted to maintain these free connections; When the number of idle connections is set too small, the response ability of the system will be very weak when peak requests occur
Let's take a look at how PooledDataSource is implemented
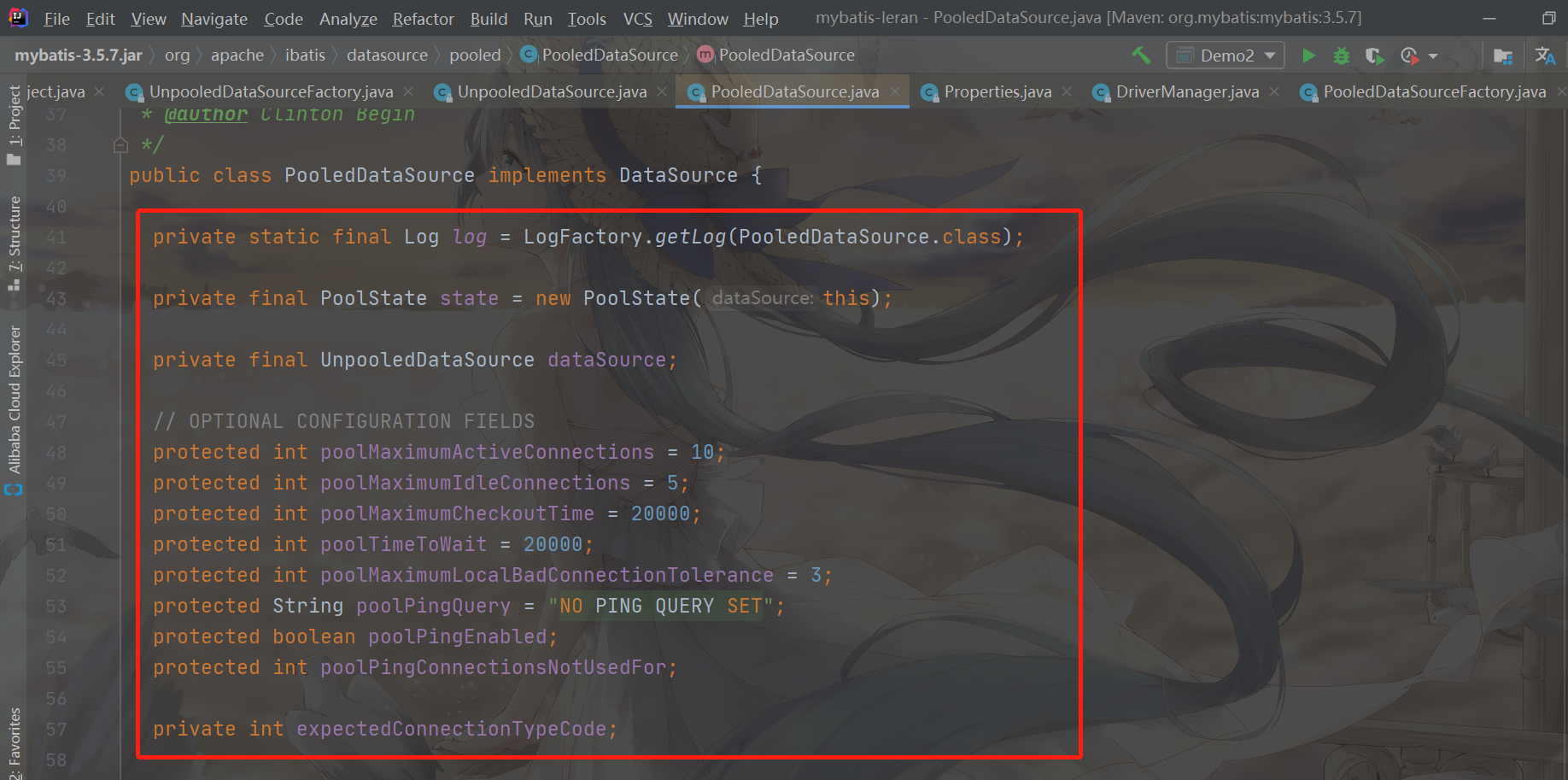
You can see that PooledDataSource also implements the DataSource interface, and it also assembles UnpooledDataSource and PoolState
PooledConnection
PooledDataSource does not directly manage the Connection object, but manages the PooledConnection object encapsulated in one layer. PooledConnection encapsulates the real database Connection object, that is, Connection, and its proxy object, which is generated by JDK dynamic agent
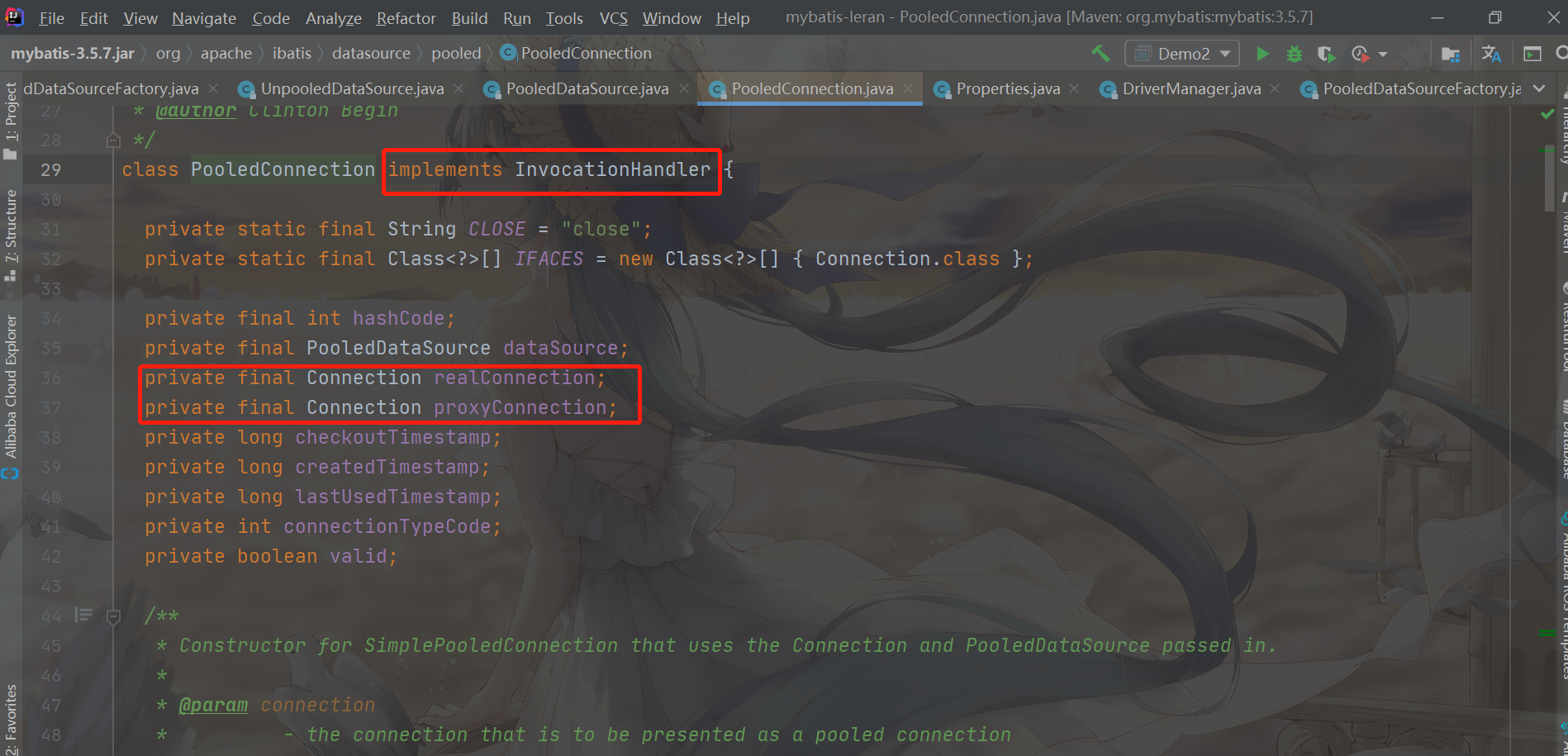
You can see that PooledConnection implements the InvocationHandler interface, which shows that PooledConnection itself is a proxy object......
Let's look at the core fields of PooledConnection
- dataSource: connection pool of PooledConnection
- realConnection: real database Connection (note that this is the Connection type)
- proxyConnection: proxy object for database Connection (this is also a Connection type)
- checkoutTimestamp: timestamp taken from the connection pool
- createdTimestamp: the timestamp when the connection was created
- lastUsedTimestamp: the timestamp of the last time the connection was used
- connectionTypeCode: a hash value calculated from the database URL, user name and password, which can be used to identify the connection pool to which the connection belongs
- Valid: indicates whether the current PooledConnection is valid. This field is used to prevent the program from closing the connection through the close method, but the subsequent connection will continue to be used
As mentioned earlier, PooledConnection implements the InvocationHandler interface, which indicates that it is a proxy object. Why is there a proxy object on the member attribute?
Let's look at the construction method
The source code is as follows
public PooledConnection(Connection connection, PooledDataSource dataSource) {
this.hashCode = connection.hashCode();
this.realConnection = connection;
this.dataSource = dataSource;
this.createdTimestamp = System.currentTimeMillis();
this.lastUsedTimestamp = System.currentTimeMillis();
this.valid = true;
//As you can see, the real proxy object is proxyConnection in the property
//The proxy object in the property is created through the current PooledConnection. How does it feel like it has become a static proxy
//It is equivalent to that as long as the proxy object is new, the internal instance of the proxy object will be generated, and a Connection represented by the current proxy object will be generated
//Coding ability is really awesome.......
this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
}
From the code, we can see that MyBatis does have something.......
Personally, I feel that this method is similar to the static proxy. The proxy is completed by creating the proxy object
For JDK dynamic proxy objects, the key point is the invoke method. Let's see what logic the invoke method does
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//Gets the name of the executed method
String methodName = method.getName();
//If the method name is close
if (CLOSE.equals(methodName)) {
//Let the dataSource recycle the cache instead of closing it!!!
dataSource.pushConnection(this);
//Do not execute the real close logic
return null;
}
try {
//Determine whether to execute the methods in the Object
if (!Object.class.equals(method.getDeclaringClass())) {
//If the execution is not the method in Object
//To check whether the current connection has failed
//The logic inside is just to judge the valid field. If it is false, it will throw an error
checkConnection();
}
//This is very important. You can see that this is executed by realConnection
//Instead of proxyConnection, that is, the proxy Connection executes logic
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
As you can see, the logic of the invoke method is as follows
- Intercept the close method first. If the close method is executed, it is not really to execute the connected close method, but to let PooledDataSource recycle it into the connection pool
- Then, the interception is not the method in the Object. If it is not the method in the Object, it must be verified before it can be executed, that is, the verification of the valid field, so as to avoid putting the Connection back into the Connection pool, and continue to manipulate the Connection. Only after passing the verification can the reflection be used for execution, and the reflection executes the method of the realConnection Object, Instead of the method of the proxy Connection
PoolState
After playing PooledConnection, let's know PoolState, which is the connection pool in PooledDataSource
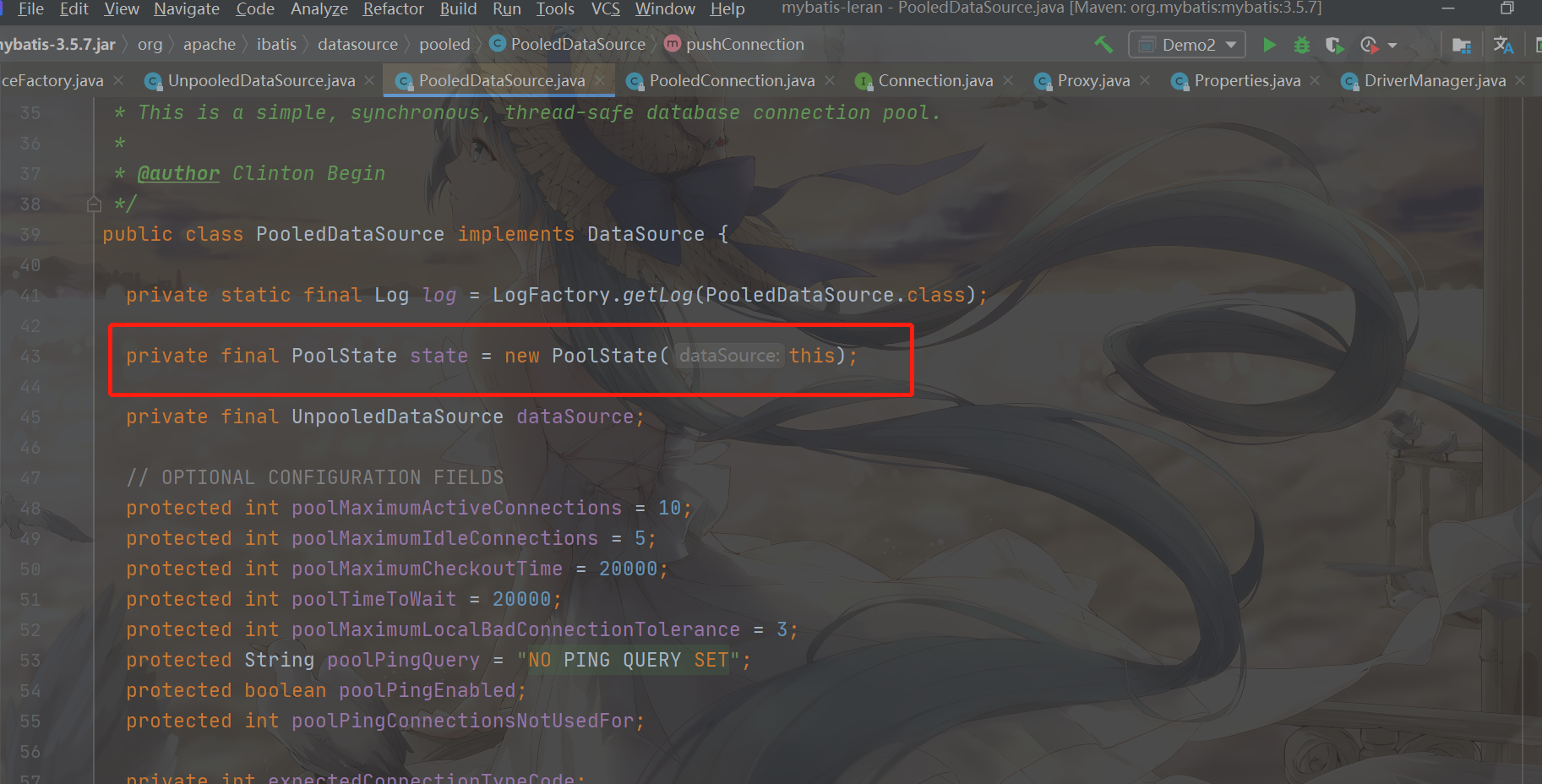
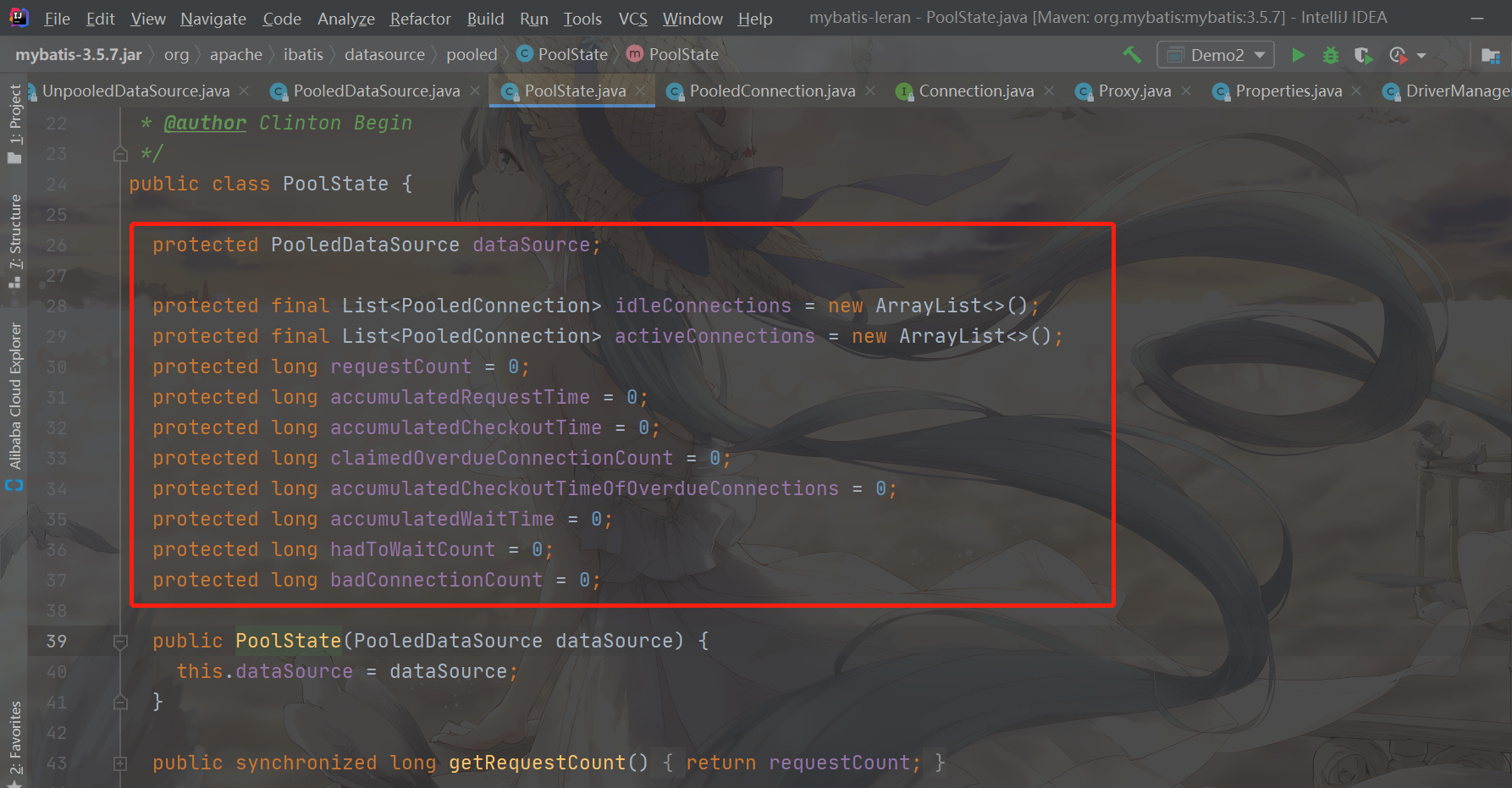
Let's analyze the member properties of PoolState. In addition to the connection pool, there are also many statistics
- PooledDataSource: the data source to which the connection pool belongs
- idleConnection: idle PooledConnection connection collection, which can be seen as an ArrayList collection
- activeConnection: PooledConnection connection collection in use, which can be seen as an ArrayList collection
- requestCount: number of database connections requested
- Accumulaterequestime: gets the cumulative time of all connections
- accumulateCheckoutTime: gets the CheckoutTime for all connections
- claimedOverdueConnection: records the number of connections that have timed out
- accumulatedCheckoutTimeofOverdueConnections: the cumulative timeout of all connections
- accumulatedWaitTime: the cumulative waiting time for all connections
- hadToWaitCount: the number of times the thread failed to get a connection and waited
- badConnectionCount: invalid number of connections
It can be seen that PoolState maintains a series of statistics, and PoolState is only an encapsulation of these resources, and the remaining methods are get methods
This connection pool is used by all user threads, which will cause a series of concurrency problems. In PoolState, synchronized is mainly used to ensure concurrency safety
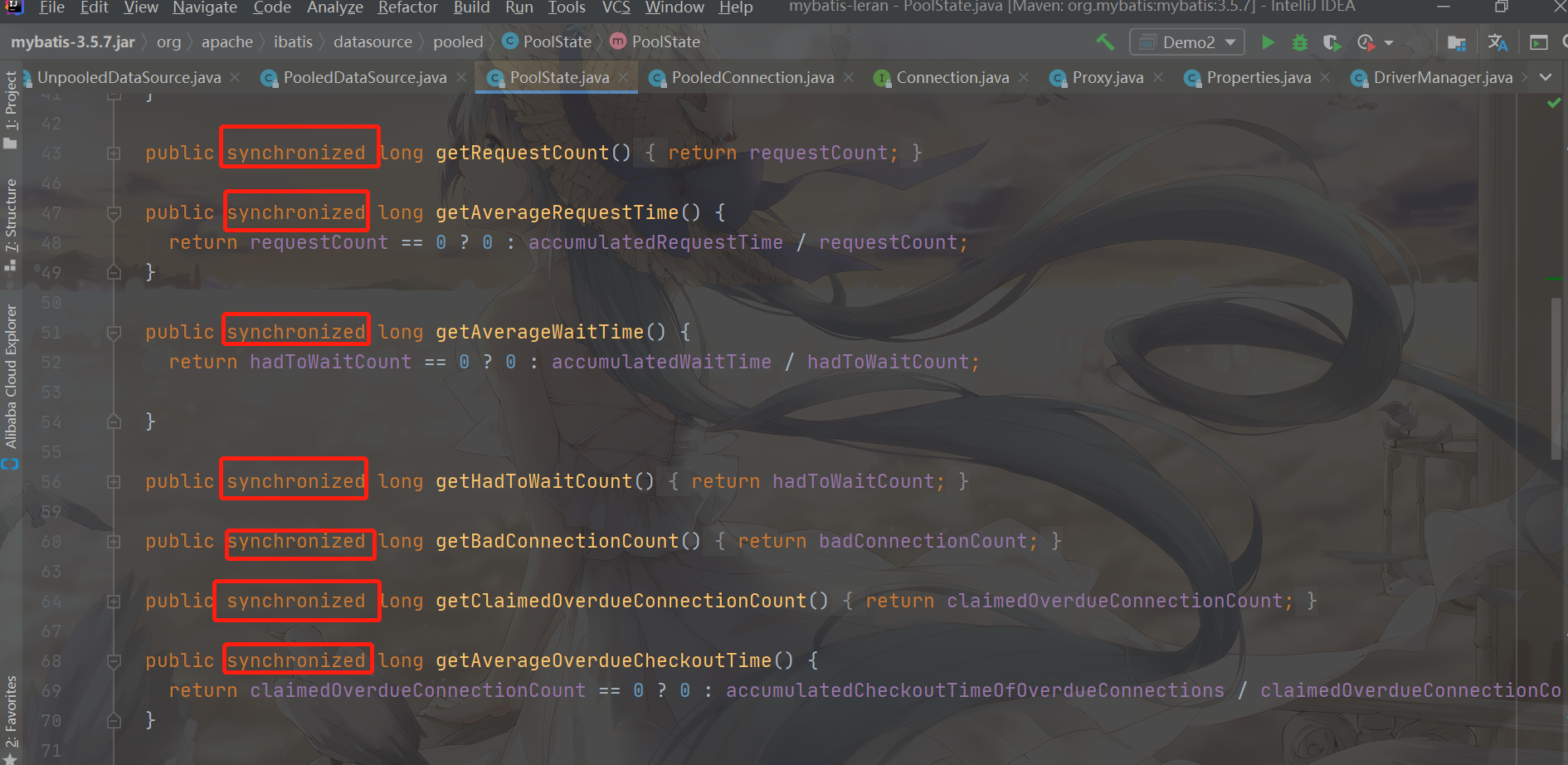
Additional optional information for PooledDataSource
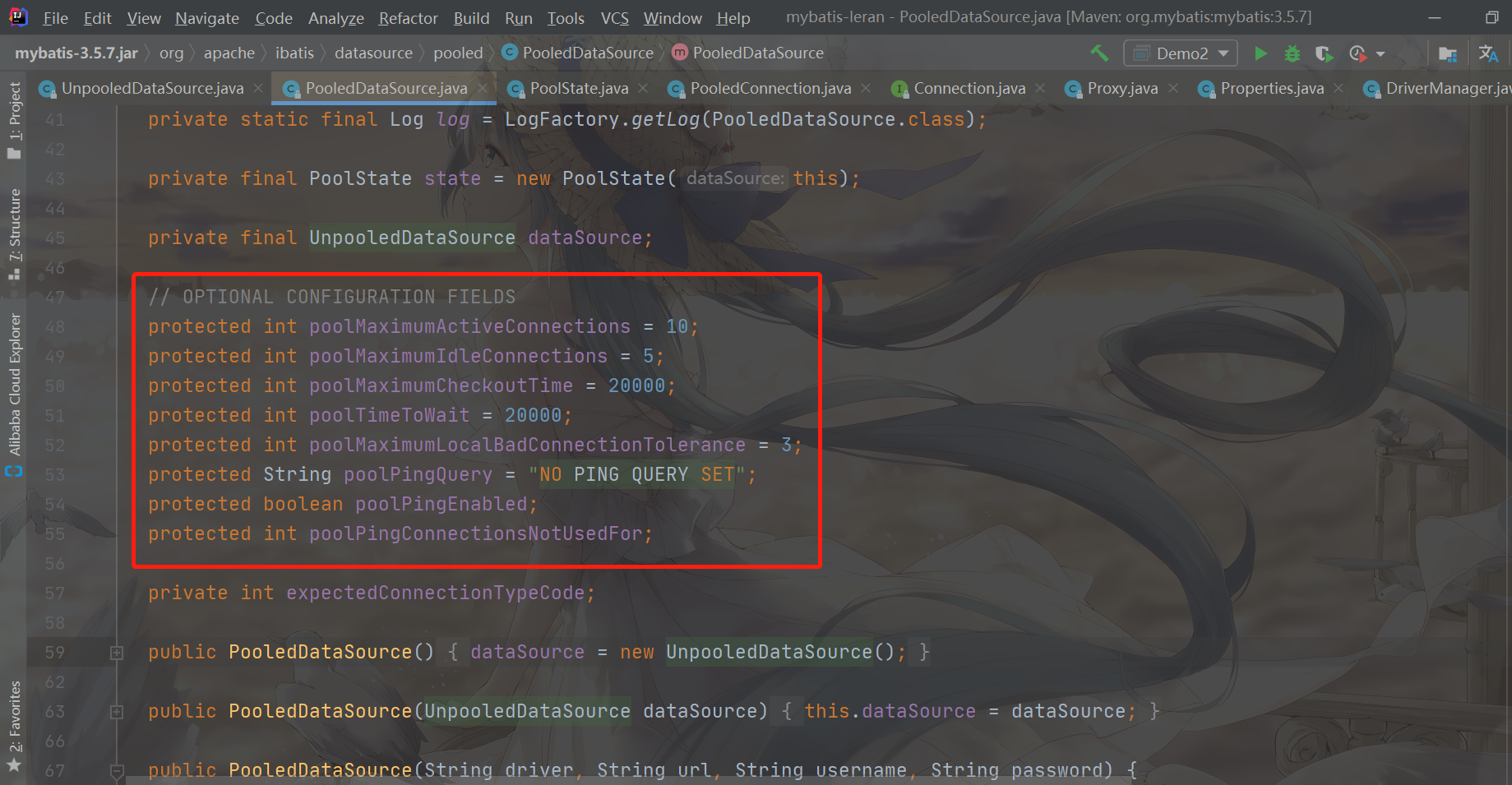
You can see that PooledDataSource also has a series of optional information, such as the total number of connections in the connection pool, the maximum number of free connections, etc.....
- poolMaximumActiveConnections: the maximum number of active connections
- poolMaximumIdleConnections: maximum number of idle connections
- Poolmaximumcheckout time: the maximum Checkout time
- poolTimeToWait: the maximum waiting time for obtaining a connection, that is, the maximum equal time when the thread cannot obtain a connection
- poolMaximumLocalBadConnectionToLerance: the maximum number of tolerable failed connections, that is, Ping test SQL fails
- PoolPingQuery: Test SQL statement sent to test whether the database connection is available
- PoolPingEnable: whether to enable the function of testing whether the database connection is available
- poolPingConnecionsNotUsedFor: when the number of milliseconds is exceeded, a test SQL occurs to check whether the connection is still available
- exceptedConnectionTypeCode: a hash value generated according to the URL, user name and password of the database. The hash value is used to mark the current connection pool
UnpooledDataSource
From the member property of PooledDataSource, we can see that it also assembles an UnpooledDataSource. I personally understand that the decorator mode is adopted here to add the function of connection pool to the UnpooledDataSource, thus forming a new UnpooledDataSource
Let's take a look at a key point of PooledDataSource, how to get connections from the connection pool
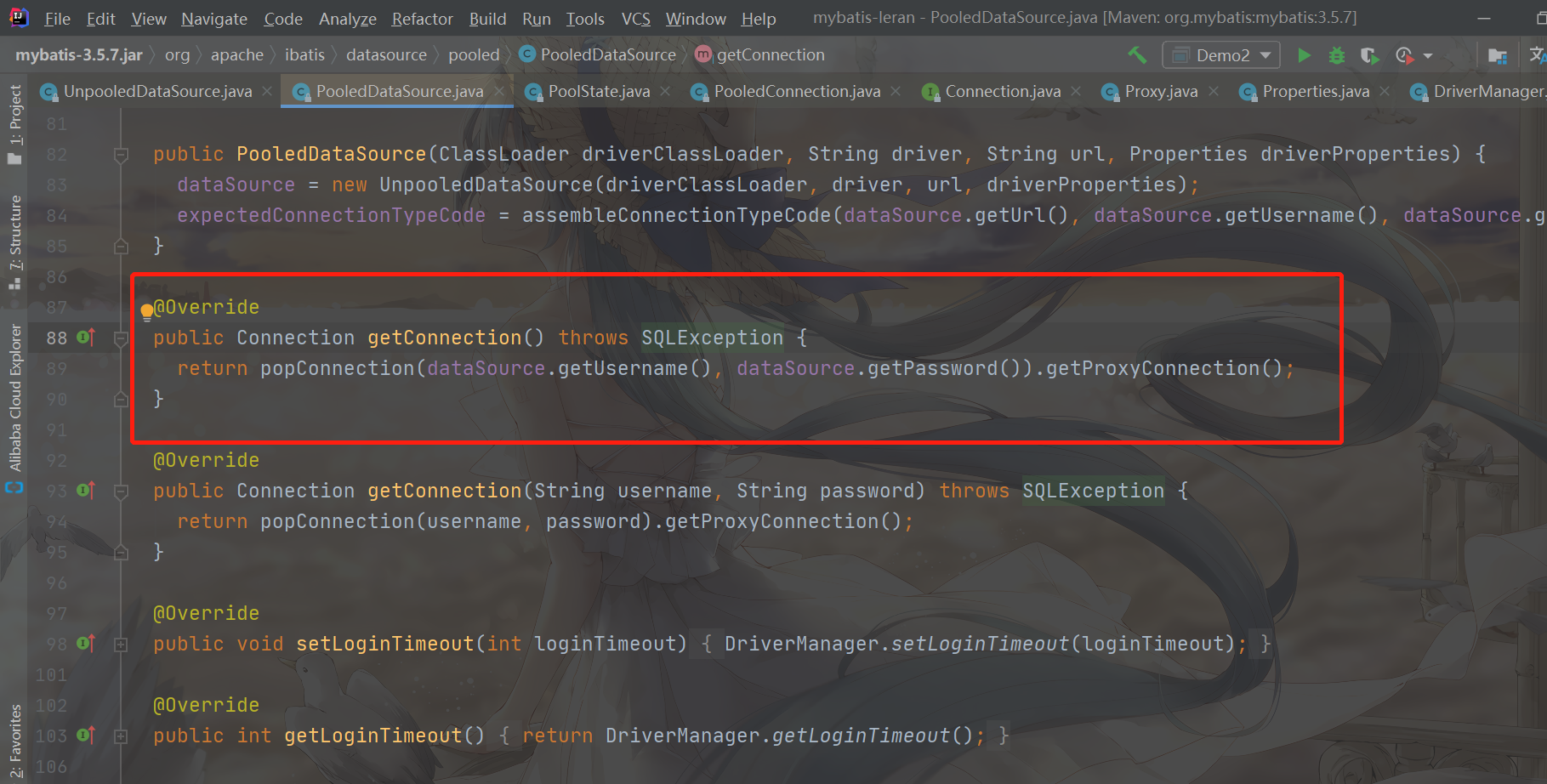
Get Connection
The corresponding method is the getConnection method. The getConnection method obtains the PooledConnection in the Connection pool through the popConnection method, and then obtains the proxy object (ProxtConnection) of the proxy Connection for operation. Therefore, the key point is how the popConnection is obtained from the Connection pool
The source code is as follows
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
//conn is used to carry the obtained PooledConnection
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
//Loop to get PooledConnection
//Loop to obtain PooledConnection until it succeeds, and throw an error if the acquisition fails for more than a certain number of times
while (conn == null) {
//Lock the state
//It ensures that only one thread can get a connection from state
synchronized (state) {
//Judge whether there are free connections in the pool
if (!state.idleConnections.isEmpty()) {
//If there is an idle connection, the first idle connection pops up
//Pay attention here!
//The remove method is used, and maintenance is required after the pop-up
//That is, the idle connections in the back are connected to the mobile
//So does too much idle connection cost performance
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// If there is no free connection
//Judge whether the number of connections currently being activated exceeds the maximum allowed number of activated connections
//To put it bluntly, it is to judge whether the current connection exceeds the set maximum number of connections threshold
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// If not, use UnPooledDataSource to create a new Connection
//Then create a proxy object for the new Connection
//Encapsulated in PooledConnection
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// If the maximum connection threshold is exceeded, you cannot create a new connection
//Get the oldest connection in use
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
//Determine whether the oldest connection has timed out
//The timeout here refers to exceeding the defined CheckoutTime
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
//If it has timed out, remove it
// Maintain poolState statistics
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
//Timeout, remove from connection pool
state.activeConnections.remove(oldestActiveConnection);
//Judge whether automatic submission is enabled for this Connection
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
//If Auto commit is not turned on, rollback is performed
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
log.debug("Bad connection. Could not roll back");
}
}
//Recreate PooledConnection
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
//Set some time properties of PooledConnection
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
//Change the oldest connection to fail
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
}
//If the oldest connections do not exceed the defined Checkout time
//Then we have to wait
else {
// Wait
try {
//Wait once
if (!countedWait) {
//Maintain some properties of PoolState
state.hadToWaitCount++;
//Wait
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
//
long wt = System.currentTimeMillis();
//PoolState executes the wait method to wait, and the waiting time is the set waiting time
//The key point here is that entering the wait method will release the lock!
//The default value is 20000 MS, waiting for 20 s?????
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
//If you go through the above steps, you can get the connection
if (conn != null) {
// Verify the connection, and ping will be performed in the isValid method
if (conn.isValid()) {
//Before using the connection, roll back the transaction inside!
//Rolling back will be more robust....
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
//Make some property settings for PooledConnection
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
//Add to the connection pool being acquired
state.activeConnections.add(conn);
//Maintenance information
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
}
//If the verification fails, that is, the ping is different, the execution of the test SQL fails
else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
//Maintenance information
state.badConnectionCount++;
localBadConnectionCount++;
//Let con = null and let the external loop get it again!
conn = null;
//Judge the number of ping test failures. If the specified number of failures is exceeded, throw an error
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
//Throw wrong
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
//If the connection is not obtained, it cannot be obtained after waiting
//Error throwing treatment
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
//Return the Connection
return conn;
}
The general process is as follows
- Loop to obtain the Connection until it succeeds, and the number of acquisition failures reaches the maximum. Throw error processing (acquisition failure is not to obtain Null, but to obtain the Connection, but Ping fails, that is, the execution of test SQL fails)
- Lock the PoolState
- Judge whether the free connection pool is empty. If it is empty, directly take the first connection pool in the free connection pool and maintain the free connection pool (move the previous free connections)
- If the free connection pool is not empty, consider whether to create a new connection or release an already active connection
- If the number of active connections does not exceed the set threshold, a new connection is created, and the obtained connection is the new connection
- If the number of active connections exceeds the set threshold, consider whether you need to release the active connections
- Judge whether the oldest active connection has timed out, that is, whether it has exceeded the set maximum CheckoutTime. If it has exceeded the set maximum CheckoutTime, release the oldest active connection. First release the oldest connection from the active connection pool. If automatic commit is not set for the connection, roll back the transactions in it, and finally create a new connection
- If there is no timeout, wait and wait only once!!!!!! The wait operation is executed by the state.wait operation. The default wait time is 20000 milliseconds. The wait operation is actually a method in the Object. Executing the wait method will release the lock resources. At this time, when the connection is exhausted, the thread that is ready to release the connection can continue the operation
- After the above steps, judge whether the connection has been obtained. If the connection has been obtained, verify the connection and execute the test SQL, that is, Ping operation
- If the verification fails, False is returned to make the obtained connection Null, and the number of failures is counted. If the upper limit value (number of free connections + maximum number of tolerated failures) is exceeded, an error will be thrown. If there is no failure, the next cycle will be started
- If the verification is successful, if it is not automatically committed, roll back the transaction and add the connection to the active connection pool
- Finally, return to the connection
I understand the general process of obtaining the connection. Now let's look at the details
Verify connection
The corresponding method is isValid
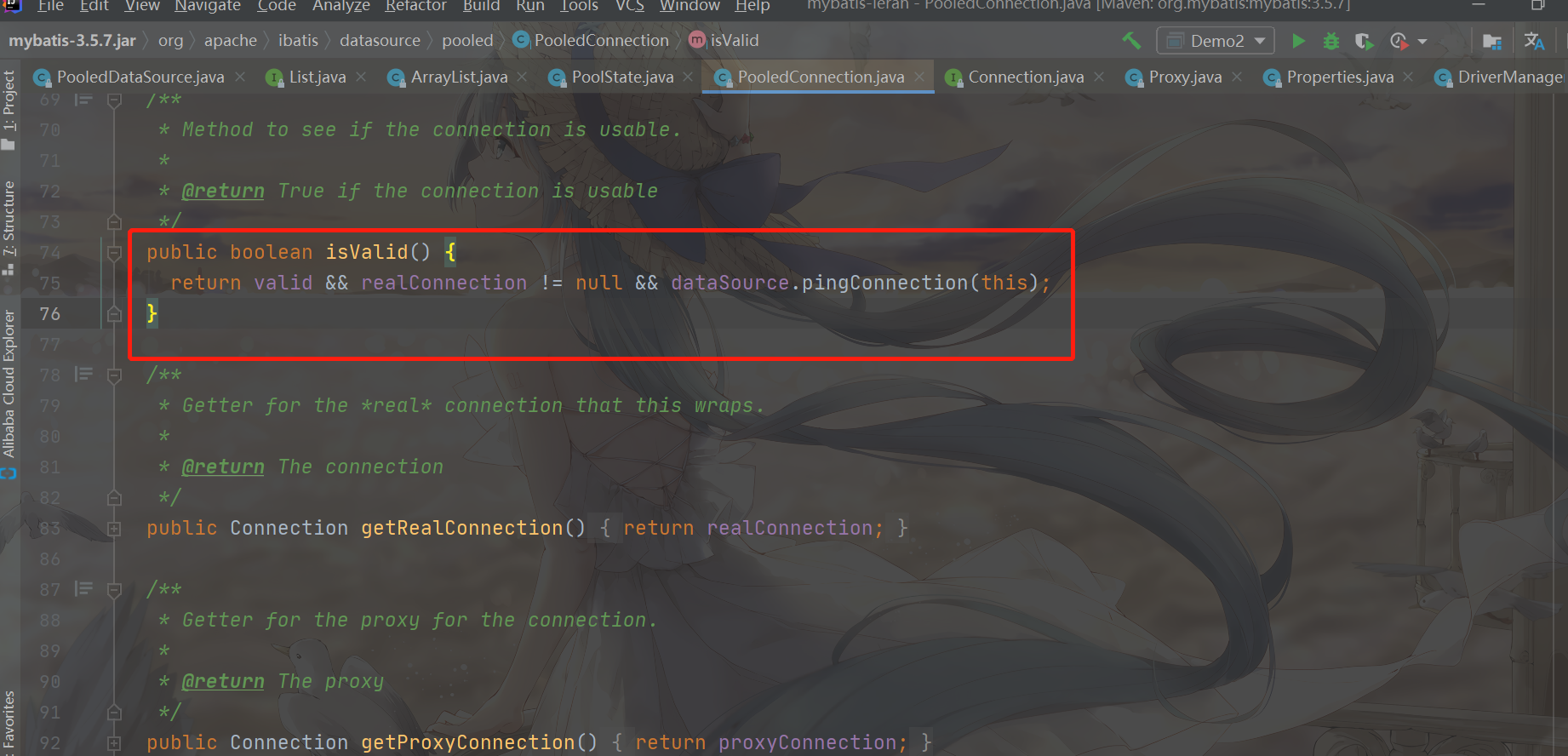
It can be seen that only when the valid is true, the realConnection is not null, and the dataSource.pingConnection succeeds can the verification be successful. The key lies in the pingConnection operation
The source code is as follows
protected boolean pingConnection(PooledConnection conn) {
boolean result = true;
try {
//Judge whether the real connection is closed
//Proxy objects use realConnection to perform operations
//If it is closed, the result will be false
//It will be true as long as it is not closed
result = !conn.getRealConnection().isClosed();
} catch (SQLException e) {
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is BAD: " + e.getMessage());
}
result = false;
}
//If the connection is not closed and the test verification is turned on, and the set interval for verification is exceeded
//SQL test verification is required
if (result && poolPingEnabled && poolPingConnectionsNotUsedFor >= 0
&& conn.getTimeElapsedSinceLastUse() > poolPingConnectionsNotUsedFor) {
try {
if (log.isDebugEnabled()) {
log.debug("Testing connection " + conn.getRealHashCode() + " ...");
}
//Use the current connection to execute poolPingQuery, that is, test SQL
Connection realConn = conn.getRealConnection();
try (Statement statement = realConn.createStatement()) {
statement.executeQuery(poolPingQuery).close();
}
//If it is submitted automatically, roll back
//It ensures that the test SQL will not affect the data
if (!realConn.getAutoCommit()) {
realConn.rollback();
}
//The test SQL passes and the result is true
result = true;
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is GOOD!");
}
} catch (Exception e) {
log.warn("Execution of ping query '" + poolPingQuery + "' failed: " + e.getMessage());
try {
conn.getRealConnection().close();
} catch (Exception e2) {
// ignore
}
result = false;
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is BAD: " + e.getMessage());
}
}
}
return result;
}
It can be seen that Ping verification is not necessarily enabled. The connection must not be closed (if it is closed, it is necessary to test the ghost BAA), the test SQL function must be enabled, and the time conditions must be met (that is, the test cannot be executed until a certain time interval is reached)
Waiting for connection
Another key point is how PoolState performs wait operations
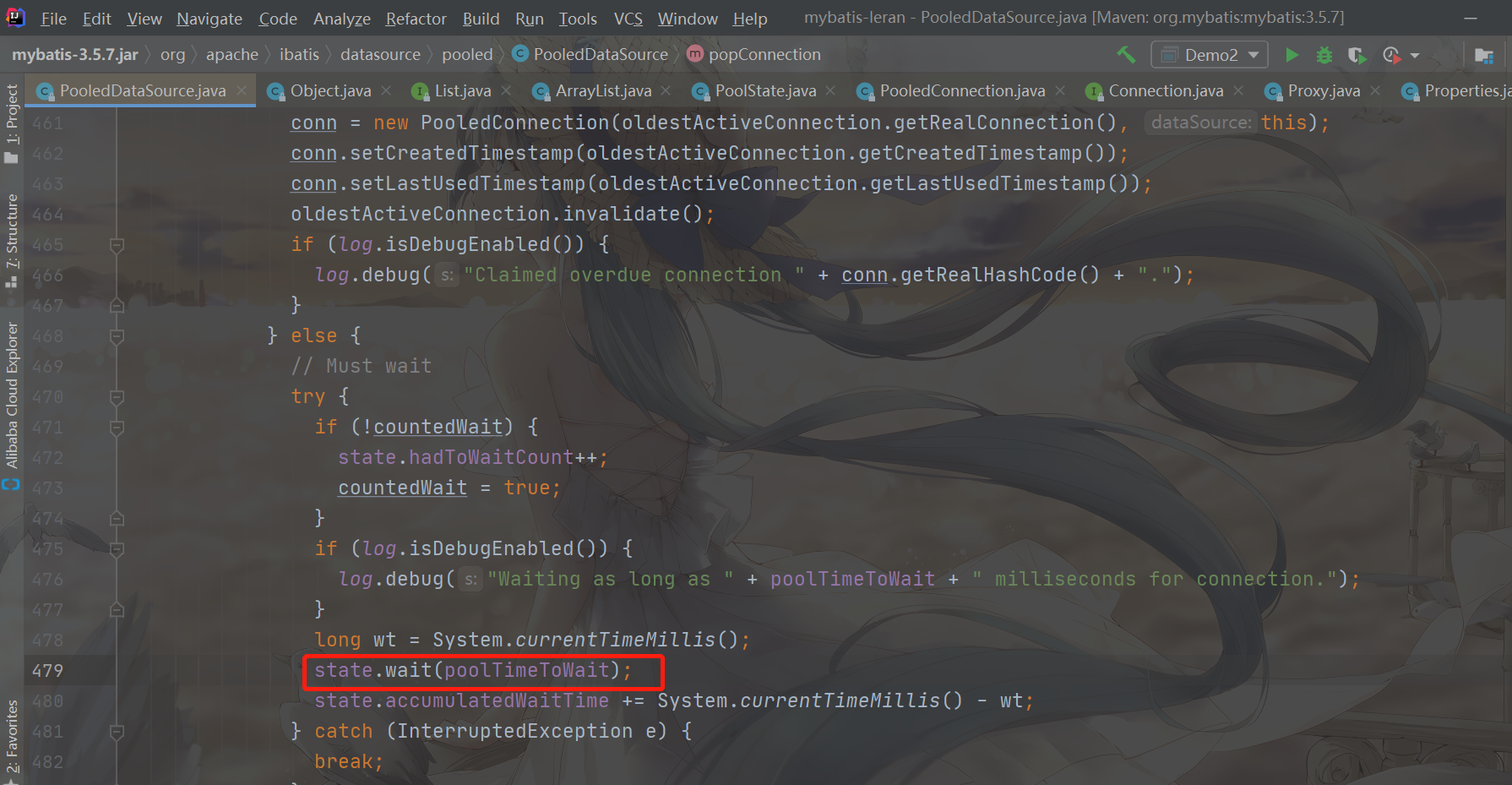
As you can see, PoolState directly calls the wait method of Object to make the current thread enter the waiting state......
dataSource.pushConnection
That's the problem. Does the thread have to wait until the specified time? At this time, if there are free connections in the free connection pool, can't you take them directly?
Remember the PooledConnection of the proxy Connection object? In its invoke method, it will intercept the Close method and execute the dataSouece.pushConnection method, as shown below
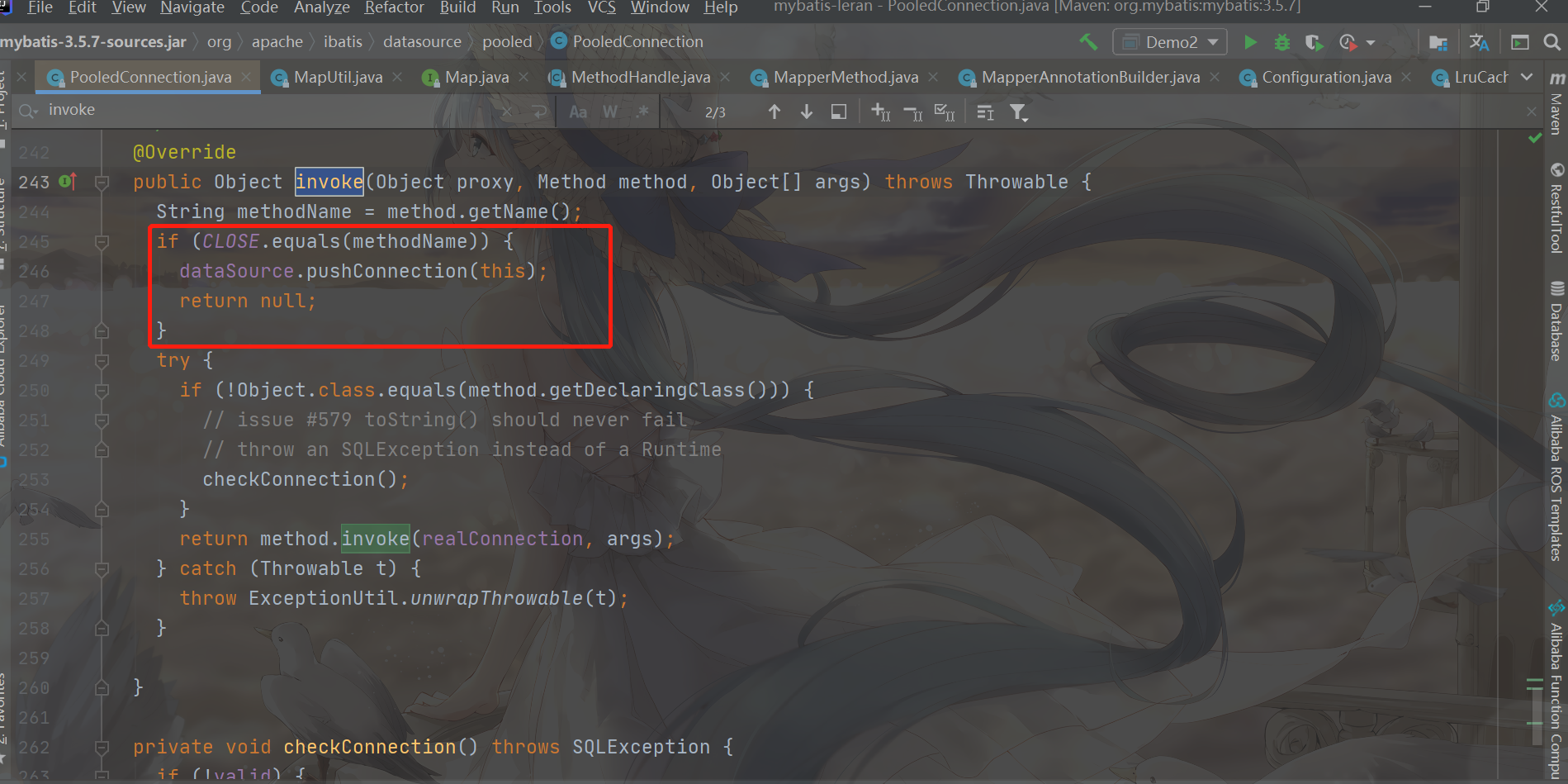
Let's take a look at the logic of this pushConnection. Because idle connections are generated here, it is possible to wake up threads here to compete. The source code is as follows
protected void pushConnection(PooledConnection conn) throws SQLException {
//Lock the connection pool, so you can only release connections one thread at a time
synchronized (state) {
//First release the connection from the active connection pool
state.activeConnections.remove(conn);
//Determine whether it can still pass the verification
//We have seen the isValid method before. It is possible to Ping
//Therefore, it is also determined whether the connection is available before release
if (conn.isValid()) {
//If the number of free connections at this time is less than the defined maximum number of free connections
//And expectedConnectionTypeCode can correspond to
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
//Consent to release
//Update CheckoutTime
state.accumulatedCheckoutTime += conn.getCheckoutTime();
//If it is not automatically committed, the transaction in it will be rolled back
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
//You can see that the original PooledConnection proxy object is discarded and a new proxy object is created instead
//But! The represented RealConnection is still the same
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
//Store in free connection pool
state.idleConnections.add(newConn);
//Update the information of the newly created proxy object
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
//Invalidate the old proxy object
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
//Wake up all waiting threads, and the method has ended and the lock has been released
//The waking waiting thread can obtain the State lock and then operate
state.notifyAll();
} else {
//If the maximum number of free connections allowed is exceeded, the connection needs to be discarded
//Update connection pool information
state.accumulatedCheckoutTime += conn.getCheckoutTime();
//Rollback without automatic commit
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
//Close old RealConnection
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
//Set to fail
conn.invalidate();
}
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
//If ping fails, the returned connection cannot be used
//And do nothing??? Simply move out of the active connection pool?
state.badConnectionCount++;
}
}
}
Here is a summary of the whole return steps
- Get lock on connection pool
- Release the connection from the active connection pool
- Check whether the connection can still be used
- If it can continue to be used, judge whether the current free connection pool has reached the defined maximum number of free connections
- If not, create a new proxy object (but the proxy Connection is the same), add the new proxy object to the idle Connection pool, roll back the transactions that are not automatically committed, invalidate the original old proxy object, and finally notify all threads (wake up those threads that have entered the waiting state in obtaining the Connection)
- If it is reached, the transaction that is not automatically committed will be rolled back, and then the proxy Connection in the proxy object at this time will be really closed, and then the proxy object will be set as invalid. It will not be added to the idle Connection pool, and it will not notify the thread. Because it is not returned, it is equivalent to directly losing it
- If it is not available, update the badConnectionCount property and do nothing......
- If it can continue to be used, judge whether the current free connection pool has reached the defined maximum number of free connections
Force all connections to close
Another important operation in PooledDataSource is to forcibly close all connections. When will you forcibly close all connections?
When the PooledDatSource field is modified, such as database URL, user name, password, autoCommit and other configurations (execute its Set method), the forceCloseAll method will be called to close all database connections. At the same time, all corresponding PooledConnection objects will be Set to invalid, and the connection pool will be cleared, including active connection pool and idle connection pool
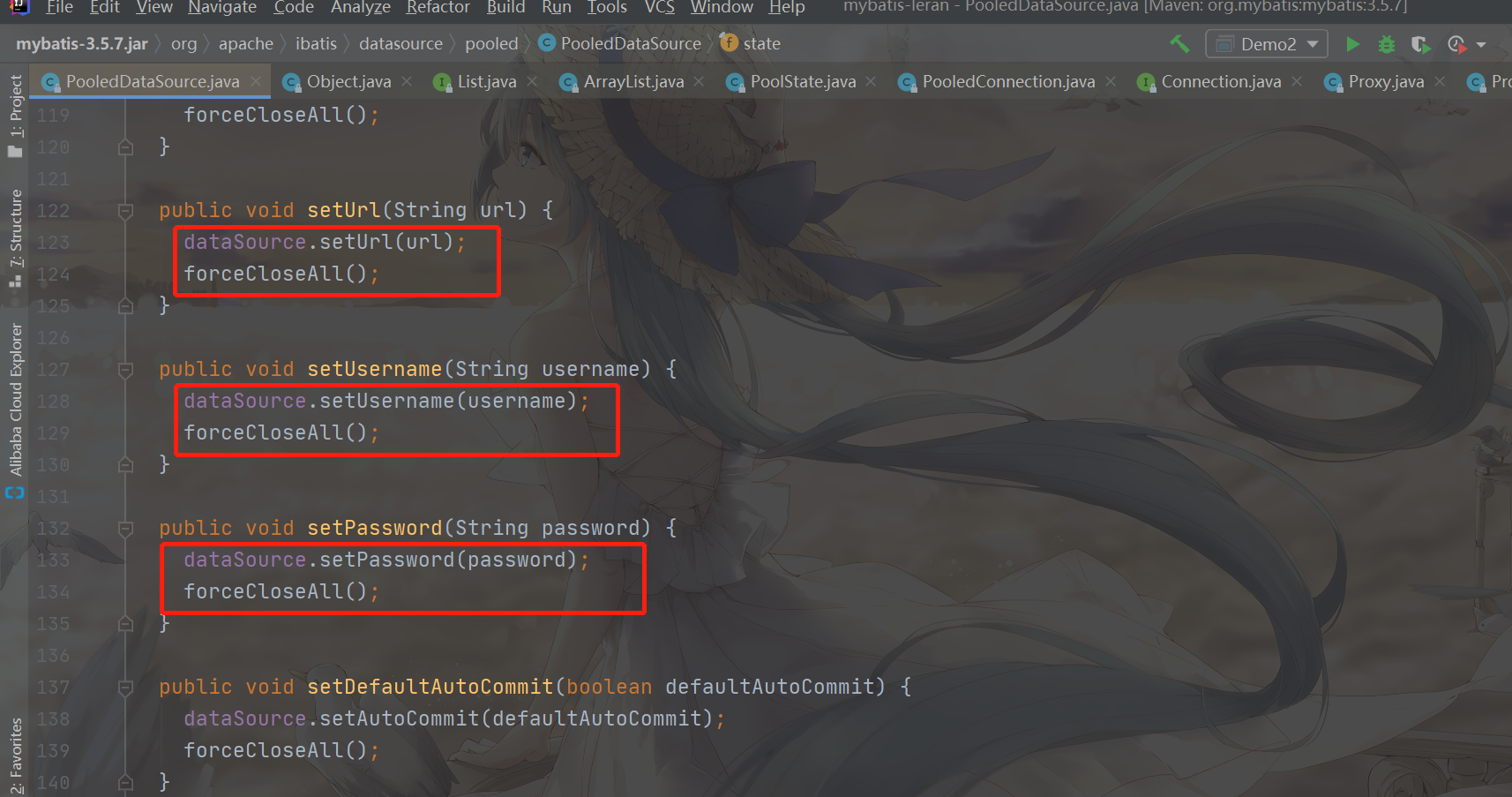
As you can see, the forceCloseAll method will be executed after the set method
forceCloseAll
The source code of the method is as follows
public void forceCloseAll() {
//Lock PooledState
synchronized (state) {
//Generate a new expectedConnectionTypeCode
expectedConnectionTypeCode = assembleConnectionTypeCode(dataSource.getUrl(), dataSource.getUsername(), dataSource.getPassword());
//Traverse active connection pool
for (int i = state.activeConnections.size(); i > 0; i--) {
try {
//Move the current connection out of the active connection pool
PooledConnection conn = state.activeConnections.remove(i - 1);
//Change to invalid
conn.invalidate();
//Roll back
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
realConn.rollback();
}
//close
realConn.close();
} catch (Exception e) {
// ignore
}
}
//Traverse free connection pool
for (int i = state.idleConnections.size(); i > 0; i--) {
try {
//Move the current connection out of the free connection pool
PooledConnection conn = state.idleConnections.remove(i - 1);
//Change to invalid
conn.invalidate();
//Roll back
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
realConn.rollback();
}
realConn.close();
} catch (Exception e) {
// ignore
}
}
}
if (log.isDebugEnabled()) {
log.debug("PooledDataSource forcefully closed/removed all connections.");
}
}
As you can see, the forced closing of all connections is to process the active connection pool and the idle connection pool
- Traverse connection pool
- Move connections out of the current connection pool
- Invalidate the connection (modify the valid field)
- Judge whether to submit automatically. If not, roll back
- Let realConnection execute close
At this point, PooledDataSource is also known
To sum up
-
MyBatis uses the factory mode to manage the establishment of data sources, and adopts the abstract factory mode. The establishment of a data source corresponds to a factory. The factory is abstracted as DataSourceFactory, and the created data source is abstracted as DataSource
-
MyBatis supports two data sources by default
- UnpooledDataSource: there is no connection pool. The thread will create a new connection when it gets the connection
- PooledDataSource: a connection pool is added on the basis of UnpooledDataSource, and a PoolState connection pool is added by means of assembly (modifying UnpooledDataSource)
- Managing connections does not directly manage connections, but its proxy object PooledConnection
- The connection pool is divided into two parts. One is the active connection pool and the other is the free connection pool. Both are an ArrayList collection
- The connection is not loaded in advance. It is more like a form of lazy loading!
- Only when the connection is used can we judge whether it needs to be created. When the connection is used up, when the close method is executed, it will be intercepted by the proxy object PooledConnection. Instead of actually closing, it will be stored in the idle connection
- When there is no idle connection, you will consider creating an active connection. When the active connection exceeds the specified threshold, you will try to release the oldest active connection. If the release fails, the thread will enter the waiting state (the default waiting time is 20000 milliseconds, 20S), wait for 20S, or until a thread returns the connection, and notify all threads to contact the waiting state
- In principle, if you can't get it all the time, it will always be in the loop. 20S just avoids idling. There are corresponding mechanisms to limit the test SQL failure. If the Ping failure exceeds the specified number of times, an error will be thrown
-
For PooledDataSource: the maximum number of connections actually supported is the user-defined maximum number of active connections, because the connections in the idle connection pool are released from the active connection pool