0. Project construction
As usual, let's build a new project first configuration The project is a little messy. The name of the project is what we call it mybatis-03-mapper Well, the imported dependencies are the same as before, and then simplify the previous code.
The copied project structure and documents shall be as follows:
Most of the code in it doesn't need to be changed. Just simplify the MyBatis global configuration file:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>
<typeAliases>
<package name="com.linkedbear.mybatis.entity"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/department.xml"/>
<mapper resource="mapper/user.xml"/>
</mappers>
</configuration>
also user.xml Simplify it. No extra work is needed databaseId , And typeHandler configuration:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.linkedbear.mybatis.mapper.UserMapper">
<resultMap id="userMap" type="com.linkedbear.mybatis.entity.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="birthday" column="birthday"/>
<association property="department" javaType="com.linkedbear.mybatis.entity.Department">
<id property="id" column="department_id"/>
<result property="name" column="department_name"/>
</association>
</resultMap>
<resultMap id="userlazy" type="com.linkedbear.mybatis.entity.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="birthday" column="birthday"/>
<association property="department" javaType="com.linkedbear.mybatis.entity.Department"
select="com.linkedbear.mybatis.mapper.DepartmentMapper.findById" column="department_id"/>
</resultMap>
<select id="findAll" resultMap="userMap">
select usr.*, dep.name as department_name
from tbl_user usr
left join tbl_department dep on usr.department_id = dep.id
</select>
<select id="findAllLazy" resultMap="userlazy">
select * from tbl_user
</select>
<insert id="saveUser" parameterType="com.linkedbear.mybatis.entity.User">
insert into tbl_user (id, name, department_id) VALUES (#{id}, #{name}, #{department.id})
</insert>
<select id="findAllByDepartmentId" parameterType="string"
resultType="com.linkedbear.mybatis.entity.User">
select * from tbl_user where department_id = #{departmentId}
</select>
</mapper>
That's OK. Let's start.
1. select - DQL
Select may be one of the most commonly used mapper elements (none). In addition, deletion, modification and query, query may be the most complex and we worry about more operations. In MyBatis, a lot of work has been done on the select tag.
1.1 attribute meaning of label
First, let's look at the properties of the select tag itself. Most of them are familiar to us,
| attribute | describe | remarks |
|---|---|---|
| id | Unique identification of the statement in a namespace | The same id can be defined in different namespace s |
| parameterType | The type of parameter passed in by the execution statement | This property can be left blank. MyBatis will automatically infer the type of the parameter passed in according to the TypeHandler |
| resultType | Fully qualified name or alias of the encapsulated entity type from the result set of the executed SQL query | If a collection is returned, it should be set to the type contained in the collection, not the type of the collection itself; Only one can be used between resultType and resultMap at the same time |
| resultMap | id reference of any resultMap defined in mapper.xml | If the referenced resultMap is in other mapper.xml, the referenced id is [namespace + '. + id]; Only one can be used between resultType and resultMap at the same time |
| useCache | Whether query results are saved to L2 cache | Default true |
| flushCache | After executing SQL, the L1 cache (local cache) and L2 cache will be emptied | The default is false; The L1 cache of all namespaces and L2 cache of the current namespace will be cleared [1.2] |
| timeout | Maximum wait time (in seconds) for SQL requests | There is no limit by default. It is recommended to define the global maximum waiting time (settings → defaultStatementTimeout) |
| fetchSize | The number of result rows returned by one query driven by the underlying database | There is no default value (depending on different database drivers). This configuration has nothing to do with MyBatis, but only with the underlying database driver [1.3] |
| statementType | The type of Statement used by the underlying | Optional values: state, PREPARED, callable, default PREPARED, used by the bottom layer PreparedStatement |
| resultSetType | Controls the behavior of the ResultSet object in jdbc | Optional value: FORWARD_ONLY , SCROLL_SENSITIVE , SCROLL_INSENSITIVE , DEFAULT[1.4] |
| databaseId | Used for SQL used by some different database manufacturers | All statement s without databaseId and matching the databaseId of the database vendor corresponding to the active data source will be loaded |
The commonly used attribute booklet will not be explained too much. Let's explore several attributes that may cause questions in detail.
1.2 flushCache
of flushCache What caches are to be cleared? If the small volume does not specifically specify all namespaces in front, some small partners may think that the caches under one namespace flushCache Only the L1 cache and L2 cache under the current namespace will be cleared, but this idea is wrong. Now we can test the effect.
For the convenience of testing, we are user.xml Define another select in the flushCache Declare as true (of course, any insert, update and delete can also be used, and their flushCache Itself is true):
<select id="cleanCache" resultType="int" flushCache="true">
select count(id) from tbl_user
</select>
Take this cleanCache Defined in user.xml The purpose of is to determine whether the department's L2 cache will be cleared together after clearing the user's L2 cache.
Next, let's test the effect of L1 cache:
public class SelectUseCacheApplication {
public static void main(String[] args) throws Exception {
InputStream xml = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(xml);
SqlSession sqlSession = sqlSessionFactory.openSession();
// Query the same Department twice in succession
DepartmentMapper departmentMapper = sqlSession.getMapper(DepartmentMapper.class);
Department department = departmentMapper.findById("18ec781fbefd727923b0d35740b177ab");
System.out.println(department);
Department department2 = departmentMapper.findById("18ec781fbefd727923b0d35740b177ab");
System.out.println("department == department2 : " + (department == department2));
// Close the first SqlSession to save the L2 cache
sqlSession.close();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
DepartmentMapper departmentMapper2 = sqlSession2.getMapper(DepartmentMapper.class);
// Query Department again
Department department3 = departmentMapper2.findById("18ec781fbefd727923b0d35740b177ab");
departmentMapper2.findAll();
UserMapper userMapper = sqlSession2.getMapper(UserMapper.class);
// Trigger cache cleanup
userMapper.cleanCache();
System.out.println("==================cleanCache====================");
// Then query the Department again
Department department4 = departmentMapper2.findById("18ec781fbefd727923b0d35740b177ab");
System.out.println("department3 == department4 : " + (department3 == department4));
sqlSession2.close();
}
}
The above code may be a little complicated. Let's explain it a little.
1) first, let's open one SqlSession , Query id is 18ec781fbefd727923b0d35740b177ab of Department , Then close SqlSession Persisting the first level cache to the second level cache; 2) then open a new one SqlSession , Query the same again Department , Observe whether the L2 cache is effective; 3) then trigger cache clearing, and then query the same Department , Observe whether the L2 cache is cleared.
Next, we run main Method, observe the log output of the console:
[main] DEBUG source.pooled.PooledDataSource - Created connection 1259652483. [main] DEBUG ansaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@4b14c583] [main] DEBUG pper.DepartmentMapper.findById - ==> Preparing: select * from tbl_department where id = ? [main] DEBUG pper.DepartmentMapper.findById - ==> Parameters: 18ec781fbefd727923b0d35740b177ab(String) [main] DEBUG pper.DepartmentMapper.findById - <== Total: 1 // --------------------After executing departmentMapper.findById for the first time------------------------- [main] DEBUG ybatis.mapper.DepartmentMapper - Cache Hit Ratio [com.linkedbear.mybatis.mapper.DepartmentMapper]: 0.0 [main] DEBUG ansaction.jdbc.JdbcTransaction - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@4b14c583] [main] DEBUG ansaction.jdbc.JdbcTransaction - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@4b14c583] [main] DEBUG source.pooled.PooledDataSource - Returned connection 1259652483 to pool. // --------------------After executing departmentMapper.findById for the second time------------------------- [main] DEBUG ybatis.mapper.DepartmentMapper - Cache Hit Ratio [com.linkedbear.mybatis.mapper.DepartmentMapper]: 0.3333333333333333 // --------------------Close sqlSession1------------------------- [main] DEBUG ansaction.jdbc.JdbcTransaction - Opening JDBC Connection [main] DEBUG source.pooled.PooledDataSource - Checked out connection 1259652483 from pool. [main] DEBUG ansaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@4b14c583] [main] DEBUG s.mapper.UserMapper.cleanCache - ==> Preparing: select count(id) from tbl_user [main] DEBUG s.mapper.UserMapper.cleanCache - ==> Parameters: [main] DEBUG s.mapper.UserMapper.cleanCache - <== Total: 1 [main] DEBUG apper.DepartmentMapper.findAll - ==> Preparing: select * from tbl_department [main] DEBUG apper.DepartmentMapper.findAll - ==> Parameters: [main] DEBUG apper.DepartmentMapper.findAll - <== Total: 4 ==================cleanCache==================== [main] DEBUG ybatis.mapper.DepartmentMapper - Cache Hit Ratio [com.linkedbear.mybatis.mapper.DepartmentMapper]: 0.5 [main] DEBUG apper.DepartmentMapper.findAll - ==> Preparing: select * from tbl_department [main] DEBUG apper.DepartmentMapper.findAll - ==> Parameters: [main] DEBUG apper.DepartmentMapper.findAll - <== Total: 4 [main] DEBUG ansaction.jdbc.JdbcTransaction - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@4b14c583] [main] DEBUG ansaction.jdbc.JdbcTransaction - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@4b14c583] [main] DEBUG source.pooled.PooledDataSource - Returned connection 1259652483 to pool.
- It can be seen that when the first execution is completed findById After, the data already exists in the L1 cache, so the SQL is not printed during the second execution. after SqlSession When off, the L1 cache is persisted to the L2 cache.
- Open a new one again SqlSession You can find that it is called again findById If the SQL is still not sent, it indicates that the L2 cache has taken effect; Then call findAll Method, let all Department The query is loaded into the L1 cache;
- Next execution UserMapper of cleanCache , After clearing the L2 cache, call again findById Method. SQL sending instructions are still not printed in the log UserMapper Cleared L2 cache does not affect DepartmentMapper ; But at the same time, findAll Method reprints the SQL, indicating that the L1 cache has been completely cleared!
Therefore, based on the above observations and analysis, we can draw a conclusion: flushCache The global L1 cache and L2 cache under this namespace will be cleared.
1.3 fetchSize
This configuration is not MyBatis, but jdbc. To say this, we need to understand some native operations of jdbc.
1.3.1 fetchSize itself exists in jdbc
public class JdbcFetchSizeApplication {
public static void main(String[] args) throws Exception {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis", "root", "123456");
PreparedStatement ps = connection.prepareStatement("select * from tbl_department");
// Set the number of result rows fetched at one time on the PreparedStatement
ps.setFetchSize(2);
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString("name"));
}
resultSet.close();
ps.close();
connection.close();
}
}
As shown in the above code, fetchSize It was Statement A property configuration that can be executed in executeQuery Method.
1.3.2 the beginning of fetchsize design
In jdbc Statement Interface, setFetchSize The method notes are as follows:
Gives the JDBC driver a hint as to the number of rows that should be fetched from the database when more rows are needed for ResultSet objects generated by this Statement. If the value specified is zero, then the hint is ignored. The default value is zero.
When this Statement Generated ResultSet When the object needs more rows, provide a prompt to the JDBC driver about the number of rows to get from the database. If you specify a value of zero, the prompt is ignored. The default value is zero.
It's a little obscure. Let's explain this in a slightly easy to understand way fetchSize Design of.
Because MySQL itself does not support fetchSize So we can refer to Oracle perhaps PostgreSQL . By default, when sending a DQL query, the database driver will pull the entire query result into memory at one time (i.e executeQuery ), When the amount of data in a query is too large and the memory can't hold so much data, it may cause OOM phenomenon. At this time, fetchSize The function of is reflected: after the database drives the query of data, it only pulls data from the database each time fetchSize The specified amount of data. When this batch of data is completed next, continue to pull the next batch of data to avoid the occurrence of OOM phenomenon.
It's still a little difficult to understand? For example, I only have enough memory to hold 20 pieces of data. I send it once select * from tbl_department You can query 50 pieces of data. If you put all 50 pieces of data into memory at one time, it is not enough to specify, and OOM is inevitable; but if I set fetchSize For 10, only 10 pieces of data are pulled out of the database each time. Let me encapsulate the result set. After these 10 pieces are encapsulated, continue to pull the last 10 pieces, so as not to cause the phenomenon of OOM!
1.3.3 applicable conditions and scenarios of fetchsize
Of course, fetchSize Not all scenarios can be used, and some major prerequisites need to be met:
- Database environment support (Oracle can, PostgreSQL (7.4 +) can, but MySQL can't)
- When executing DQL, Connection of autoCommit Must be false (i.e. start transaction)
- Of query results ResultSet , Type must be TYPE_FORWARD_ONLY (you can't scroll in the opposite iteration direction) (mentioned shortly below)
- It is only useful when sending one DQL at a time. It is not easy to send multiple dqls at one time if separated by semicolons (e.g select * from tbl_department; select * from tbl_user;)
Another point is that fetchSize is used to read and process data in a timely manner, rather than to read all these data and encapsulate the result set. Imagine that if it is used to encapsulate the result set, all the data read from the database would dry explode your memory. Isn't it double "dry explosion" to encapsulate the result set? So this point should be clear.
1.4 resultSetType
resultSetType , This attribute is not MyBatis, as mentioned above ResultSet In MyBatis, this attribute is used to configure the type of, but we generally don't use it at all, just learn about it.
But when it comes to it, we have to mention the jdbc specification.
1.4.1 result set read defect by default
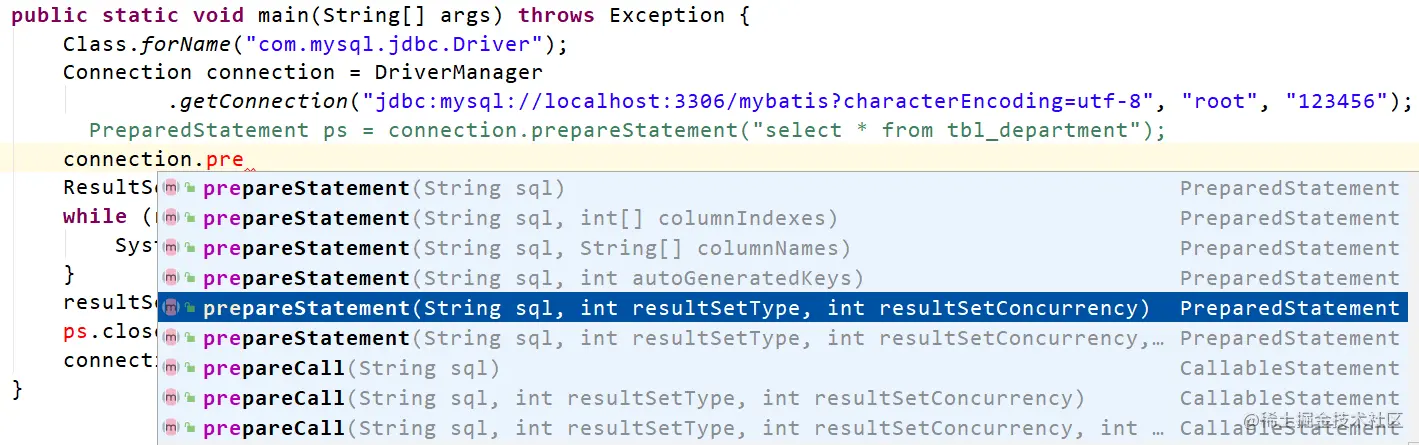
According to jdbc specification, Connection Object is being created Statement When, you can specify ResultSet To control the return of query action execution ResultSet Type. From an API perspective, prepareStatement Method has overloaded and can be passed in resultSetType How to:
Values that can be passed in, in ResultSet Defined in the interface:
// The general default type only supports downward iteration of the result set
int TYPE_FORWARD_ONLY = 1003;
// It can support rolling to obtain records in any direction and is not sensitive to the modification of other connections
int TYPE_SCROLL_INSENSITIVE = 1004;
// It can support scrolling to obtain records in any direction and is sensitive to the modification of other connections
int TYPE_SCROLL_SENSITIVE = 1005;
Oh, it's coming again ~ please say a few words???
OK, OK, OK, let's explain it in words that are easier to understand.
We are executing DQL and get ResultSet After that, whether we encapsulate the result set or directly traverse the result set to process data, we all write as follows:
ResultSet resultSet = ps.executeQuery();
// Traversal cursor down iteration
while (resultSet.next()) {
System.out.println(resultSet.getString("name"));
}
Every time a new row of data is obtained, it is executed ResultSet of next Method, iterate from top to bottom. After the iteration is completed, this ResultSet Your mission is over. If you have special needs, you need to go back again?
// Traversal cursor down iteration
while (resultSet.next()) {
System.out.println(resultSet.getString("name"));
}
// Traversal cursor up iteration
while (resultSet.previous()) {
System.out.println("Reverse order --- " + resultSet.getString("name"));
}
Sorry, it doesn't work. By default ResultSet We can only go from top to bottom. How to solve this problem? Change ResultSet Type, that is, the three constants mentioned above.
1.4.2 resultSetType in JDBC
As mentioned above, in prepareStatement When, you can specify the returned ResultSet Here we specify its type as TYPE_SCROLL_INSENSITIVE , That is, scrolling is allowed:
PreparedStatement ps = connection.prepareStatement("select * from tbl_department",
ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_READ_ONLY);
After the above code is executed normally, it can be found that the two while loops are indeed a positive order reading and a reverse order reading:
All departments Development Department Test product department Operation and maintenance department Reverse order --- Operation and maintenance department Reverse order --- Test product department Reverse order --- Development Department Reverse order --- All departments
And TYPE_SCROLL_INSENSITIVE Similarly, there are TYPE_SCROLL_SENSITIVE , The difference between them is that if the data in the database changes when reading the result set, the ResultSet Whether the data in the also changes.
1.4.3 configuring resultSetType in mybatis
In MyBatis, it is not automatically set by default resultSetType It is completely determined by the database driver. Of course, it can also be specified. There are three specified values, which correspond to one-to-one in jdbc:
- FORWARD_ONLY → TYPE_FORWARD_ONLY
- SCROLL_INSENSITIVE → TYPE_SCROLL_INSENSITIVE
- SCROLL_SENSITIVE → TYPE_SCROLL_SENSITIVE
1.5 SQL writing of select tag
For the preparation of SQL, there must be no need to talk about it in a small volume. Everyone is very familiar with it! Or it can be done directly at one go and used where parameters are needed # {} After setting, dynamic SQL is used to assemble complex scenarios. We will not expand the content of dynamic SQL in this chapter, but we will explain it separately in the next chapter.
2. insert, update and delete - DML
Since insert, update and delete belong to DML statements, and their use is similar, we discuss these three tags in one chapter.
2.1 attribute meaning of label
Let's first look at the attributes of these tags. Many of these attributes are similar or identical to the above select. Here we only show some attributes that are not or different from the select:
| attribute | describe | remarks |
|---|---|---|
| flushCache | After executing SQL, the L1 cache (local cache) and L2 cache will be emptied | The default value is true |
| useGeneratedKeys | If enabled, MyBatis will use the getGeneratedKeys method at the bottom of jdbc to get the value of the auto incremented primary key | Only applicable to insert and update. The default value is false |
| keyProperty | When used with useGeneratedKeys, you need to specify the attribute name of the incoming parameter object. MyBatis will fill the specified attribute with the return value of getGeneratedKeys or the selectKey sub element in the insert statement | Only applicable to insert and update, no default value |
| keyColumn | The effective value of useGeneratedKeys corresponds to the column name in the database table. In some databases (such as PostgreSQL), when the primary key column is not the first column of the database table, this property needs to be explicitly configured | It is only applicable to insert and update. If there is more than one primary key column, multiple attribute names can be separated by commas |
except flushCache In addition, the remaining three are only used in the insert and update tags. Let's talk about them.
2.2 useGeneratedKeys
To put it bluntly, the self increasing id of the database table is used as the primary key when inserting data. If this property is set to true, the primary key may not be passed, and MyBatis will use jdbc at the bottom getGeneratedKeys Method helps us find out the id, then put it into the id attribute and backfill it into the entity class. This property can be associated with keyProperty and keyColumn With the use, we can demonstrate the effect below.
2.2.1 cooperation between test and keyProperty
We can make a simple test table and demonstrate it useGeneratedKeys coordination keyProperty Effect of:
create table tbl_dept2 (
id int(11) not null auto_increment,
name varchar(32) not null,
tel varchar(18) default null,
primary key (id)
);
Then the corresponding mapper file test.xml :
<mapper namespace="test">
<insert id="save" useGeneratedKeys="true" keyProperty="id">
insert into tbl_dept2 (name, tel) VALUES (#{name}, #{tel})
</insert>
</mapper>
Finally, the test run class, which we call directly
public class GeneratedKeysApplication {
public static void main(String[] args) throws Exception {
InputStream xml = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(xml);
SqlSession sqlSession = sqlSessionFactory.openSession();
Department department = new Department();
department.setName("hahaha");
department.setTel("12345");
sqlSession.insert("test.save", department);
sqlSession.commit();
System.out.println(department);
}
}
implement main Method and observe the department object printed on the console:
[main] DEBUG source.pooled.PooledDataSource - Created connection 2129221032.
[main] DEBUG ansaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@7ee955a8]
[main] DEBUG test.save - ==> Preparing: insert into tbl_dept2 (name, tel) VALUES (?, ?)
[main] DEBUG test.save - ==> Parameters: hahaha(String), 12345(String)
[main] DEBUG test.save - <== Updates: 1
[main] DEBUG ansaction.jdbc.JdbcTransaction - Committing JDBC Connection [com.mysql.jdbc.JDBC4Connection@7ee955a8]
Department{id='2', name='hahaha', tel='12345'}
It can be found that the id has been successfully filled in!
If the two attributes of insert in mapper.xml are removed:
<insert id="save">
insert into tbl_dept2 (name, tel) VALUES (#{name}, #{tel})
</insert>
The department print after successful operation has no id attribute value:
Department{id='null', name='hahaha', tel='12345'}
This leads to a conclusion: use generated keys and keyProperty Property allows us to automatically backfill the id after the insert operation is completed (provided, of course, that the id increases automatically).
2.2.2 test the cooperation with keyColumn
Let's test it again useGeneratedKeys And keyColumn Mutual cooperation. But let's start with a background:
Generally, when we design the database table structure, we use the first column as the primary key column. Over time, it is established by convention. When we see the first column, we know it is the primary key column. But it's not guaranteed. Some creatures from outer space (funny) will set the primary key of the database table to other columns, resulting in the first column no longer being the primary key column! Although this will not cause any impact in MySQL, there will be a magical problem in PostgreSQL and other databases. Let's demonstrate it below.
First, let's prepare a PostgreSQL database and mybatis-config.xml Configure data sources in:
<dataSource type="POOLED">
<property name="driver" value="org.postgresql.Driver"/>
<property name="url" value="jdbc:postgresql://localhost:5432/postgres"/>
<property name="username" value="postgres"/>
<property name="password" value="123456"/>
</dataSource>
Then create a table as like as two peas in the corresponding database: (note that the column in id is not the first column).
create table tbl_dept2 (
name varchar(32) not null,
id serial primary key,
tel varchar(18)
);
At this time, the configuration in test.xml is only useGeneratedKeys and keyProperty :
<insert id="save" useGeneratedKeys="true" keyProperty="id">
insert into tbl_dept2 (name, tel) VALUES (#{name}, #{tel})
</insert>
Next, let's run the above directly GeneratedKeysApplication Class main Method, observe the department print on the console:
[main] DEBUG dbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [org.postgresql.jdbc.PgConnection@eb21112]
[main] DEBUG test.save - ==> Preparing: insert into tbl_dept2 (name, tel) VALUES (?, ?)
[main] DEBUG test.save - ==> Parameters: hahaha(String), 12345(String)
[main] DEBUG test.save - <== Updates: 1
[main] DEBUG dbc.JdbcTransaction - Committing JDBC Connection [org.postgresql.jdbc.PgConnection@eb21112]
Department{id='hahaha', name='hahaha', tel='12345'}
?????? Isn't id of type int? How did it become "hahaha"?
Maybe some little friends will doubt, won't they Department The id of the model class itself is String Type, which leads to the evil problem? Let's change the type of id to Integer:
public class Department implements Serializable {
private static final long serialVersionUID = -2062845216604443970L;
private String name;
private Integer id;
private String tel;
Then run again main Method, which is even more outrageous this time. An exception is thrown directly:
Caused by: org.postgresql.util.PSQLException: Bad type value int : hahaha
Good guy, with the database driver, you have to plug haha into the id attribute? That must be unreasonable!
But what is the reason for the problem? As mentioned above, PostgreSQL believes that the first column of each table should be the primary key column, so it takes the value of the first column as the return value of the primary key and puts it into the id attribute of the model class, resulting in data type conversion errors.
How to solve it? We need to actively tell him which attribute is the id:
<insert id="save" useGeneratedKeys="true" keyProperty="id" keyColumn="id">
insert into tbl_dept2 (name, tel) VALUES (#{name}, #{tel})
</insert>
After this declaration, run again main Method, the console prints normally this time:
Department{id=3, name='hahaha', tel='12345'}
Note that the id is 3. Check the database:
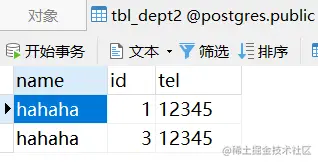
Eh? Why is there only two pieces of data in the database? Very simply, in the previous test, an exception was reported. That exception caused the transaction to roll back and the data was not added, but the self increment has been + 1, so we only saw 1 and 3, not 2.
For the insert, update and delete tags, this is the main emphasis in the booklet useGeneratedKeys Attributes and the two attributes of cooperation. The rest of you must be more proficient in using them, so the booklet is not wordy.
3. resultMap - result set mapping
<resultMap> Responsible for result set mapping, MyBatis calls it the most important and powerful label element, which shows the high degree of attention. The conventional usage booklet is not too verbose. We mainly study several relatively special or rare usage.
3.1 construction method using pojo
Generally speaking, for a pojo, it is not allowed to have any explicitly defined construction methods. In other words, it can only have its own default parameterless construction methods. Of course, in a few cases, when configuring resultMap, we will still encounter some special scenarios. We need to return some Vos instead of entity model classes. At this time, we need MyBatis to call its parametric construction method. MyBatis supports it better and better. In the current mainstream version of MyBatis 3.5, it can handle the result set mapping of parametric construction methods well. Let's give a simple demonstration.
3.1.1 simple use
Let's just take what we have Department Let's demonstrate by explicitly declaring a parameterless constructor and a parameterless constructor with id:
public class Department implements Serializable {
private String id;
private String name;
private String tel;
public Department() {
}
public Department(String id) {
this.id = id;
}
In this way, you can not only be compatible with the previous code, but also carry out the next test.
Next, we define a new resultMap and use the construction method < constructor> label:
<resultMap id="departmentWithConstructor" type="Department">
<constructor>
<idArg column="id" javaType="String"/>
</constructor>
<result property="name" column="name"/>
<result property="tel" column="tel"/>
</resultMap>
<select id="findAll" resultMap="departmentWithConstructor">
select * from tbl_department
</select>
Then we can code and test. We have written the content of the code many times:
public class ResultMapApplication {
public static void main(String[] args) throws Exception {
InputStream xml = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(xml);
SqlSession sqlSession = sqlSessionFactory.openSession();
DepartmentMapper departmentMapper = sqlSession.getMapper(DepartmentMapper.class);
List<Department> departmentList = departmentMapper.findAll();
departmentList.forEach(System.out::println);
}
}
function main Method, the console can normally print out all department information to prove < constructor> There is no problem with the label.
3.1.2 precautions in use
Pay attention to a detail in use, < constructor > There is one of the sub tags of the tag name Properties:

this name Is the member attribute name of the corresponding entity class. Generally, we don't need to write it. However, if you really need to declare name Attribute, you need to write an annotation in the entity class: @ Param :
public Department(@Param("idd") String id) {
this.id = id;
}
@Param of value You can write it at will. For example, the booklet above has specially added a d, which needs to be explicitly declared in the resultMap above name Properties:
<resultMap id="departmentWithConstructor" type="com.linkedbear.mybatis.entity.Department">
<constructor>
<!-- be careful name With the above@Param Annotated value agreement -->
<idArg column="id" javaType="String" name="idd"/>
</constructor>
<result property="name" column="name"/>
<result property="tel" column="tel"/>
</resultMap>
So we can do it again ResultMapApplication of main Method can still be executed normally. Small partners can also test by themselves. If the name s on both sides are not aligned, main The method will report as soon as it starts BuilderException (prompt Error in result map).
3.2 reference other resultmaps
Remember the most basic userMap we wrote in the basic review:
<resultMap id="userMap" type="com.linkedbear.mybatis.entity.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="birthday" column="birthday"/>
<association property="department" javaType="com.linkedbear.mybatis.entity.Department">
<id property="id" column="department_id"/>
<result property="name" column="department_name"/>
</association>
</resultMap>
fortunately Department There are not many attributes of entity classes. What if there are too many attributes... How hard it would be for us to match more than 20 of them... Therefore, there are some alternative solutions, either delayed loading, or we can implement it by referring to an external resultMap.
3.2.1 off the shelf resultMap+prefix
For example, we were department.xml The most basic department mapping relationship has been defined in:
<resultMap id="department" type="com.linkedbear.mybatis.entity.Department">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="tel" column="tel"/>
</resultMap>
Then we can use it directly. find user.xml Medium findAll , Let's change the resultMap:
<resultMap id="userWithPrefix" type="com.linkedbear.mybatis.entity.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="birthday" column="birthday"/>
<association property="department" javaType="com.linkedbear.mybatis.entity.Department"
resultMap="com.linkedbear.mybatis.mapper.DepartmentMapper.department" columnPrefix="department_"/>
</resultMap>
<select id="findAll" resultMap="userWithPrefix"> <!-- Pay attention here resultMap It is newly defined above -->
select usr.*, dep.name as department_name, dep.tel as department_tel
from tbl_user usr
left join tbl_department dep on usr.department_id = dep.id
</select>
Look at the above userWithPrefix Definition, < Association > The label directly refers to the resultMap of the above department, but there is only one more columnPrefix="department_" Configuration of. Its purpose must not need to be explained in the booklet, and small partners can guess. It can be automatically taken out when encapsulating the result set "Specify prefix + column" The columns of are encapsulated in the specified resultMap.
It feels good. Let's take the query above as an example, findAll The results of SQL statements executed in the database should be as follows:

The column about department information in this column is just the same as Department Entity classes can correspond to each other one by one, and also to the resultMap of the Department, but these columns have a common prefix of department_ , So we can take out these columns and tell MyBatis that these columns need to be spelled for me department_ Prefix, encapsulated into Department In the entity class object, MyBatis can help us do this.
After replacing in this way, let's test the effect:
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> userList = userMapper.findAll();
userList.forEach(System.out::println);
function main Method, observe the printed on the console User Object:
User{id='09ec5fcea620c168936deee53a9cdcfb', name='A bear', department=Department{id='18ec781fbefd727923b0d35740b177ab', name='Development Department', tel='123'}}
User{id='0e7e237ccac84518914244d1ad47e756', name='hahahaha', department=Department{id='18ec781fbefd727923b0d35740b177ab', name='Development Department', tel='123'}}
User{id='5d0eebc4f370f3bd959a4f7bc2456d89', name='Old dog', department=Department{id='ee0e342201004c1721e69a99ac0dc0df', name='Operation and maintenance department', tel='456'}}
As you can see, Department All properties of have been filled, indicating that this way of referencing other resultmaps is completely possible.
3.2.2 directly reference resultMap
Of course, if the column found corresponds to Department If the attributes of the entity class are not completely prefixed (such as department_id, department_name, tel), the resultMap + prefix method will not work. In this case, we can only define a new resultMap and reference it directly, like this:
<resultMap id="userWithPrefix" type="com.linkedbear.mybatis.entity.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="birthday" column="birthday"/>
<association property="department" javaType="com.linkedbear.mybatis.entity.Department"
resultMap="com.linkedbear.mybatis.mapper.DepartmentMapper.departmentWithPrefix"/>
</resultMap>
<resultMap id="departmentWithPrefix" type="com.linkedbear.mybatis.entity.Department">
<id property="id" column="department_id"/>
<result property="name" column="department_name"/>
<result property="tel" column="tel"/>
</resultMap>
In this way, you can also test and verify by yourself.
3.3 inheritance of resultmap
With the spring framework BeanDefinition Similar to inheritance, resultMap also has the concept of inheritance. The introduction of inheritance makes the resultMap hierarchical and universal. We can experience the benefits of the features inherited by resultMap through an example.
Recall that when we wrote one to many, we need to add a collection in the resultMap of the department to load all users. However, in fact, some scenarios do not need these users at all, so loading them is a waste of performance and increases power consumption! In the past, our solution was as follows:
<resultMap id="department" type="com.linkedbear.mybatis.entity.Department">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="tel" column="tel"/>
</resultMap>
<resultMap id="departmentWithUsers" type="com.linkedbear.mybatis.entity.Department">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="tel" column="tel"/>
<collection property="users" ofType="com.linkedbear.mybatis.entity.User"
select="com.linkedbear.mybatis.mapper.UserMapper.findAllByDepartmentId" column="id"/>
</resultMap>
That's right, but tbl_department The common field mapping in the table is repeated, and the maintenance cost will increase. MyBatis naturally helps us think of this, so we can optimize it as follows:
<resultMap id="department" type="com.linkedbear.mybatis.entity.Department">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="tel" column="tel"/>
</resultMap>
<resultMap id="departmentWithUsers" type="Department" extends="department">
<collection property="users" ofType="com.linkedbear.mybatis.entity.User"
select="com.linkedbear.mybatis.mapper.UserMapper.findAllByDepartmentId" column="id"/>
</resultMap>
<select id="findAll" resultMap="departmentWithUsers">
select * from tbl_department
</select>
Look, Department In this resultMap, only the mapping of single table fields is configured, and the query of associated sets is used departmentWithUsers This resultMap, let it inherit department , You can also have the field mapping relationship of a single table at the same time.
After this configuration, we can change the resultMap of findAll and actually test it. Of course, the results must be feasible, but the test results are not posted in the booklet (mainly too long). Small partners can write and try.
3.4 discriminator
Finally, we introduce a special result set mapping called discriminator Discriminator mapping. Discriminator is nothing more than deciding how to do / choose according to certain conditions. Let's explain the use of discriminator through a simple requirement.
3.4.1 requirements
Existing tbl_user There is one in the table deleted Property, representing whether to delete it logically. Our need is, when deleted When the attribute value is 0, it means that it has not been deleted. When querying user information, you need to bring out the Department information together; deleted When it is 1, it means that the user has been deleted and the Department information is no longer queried.
In order to distinguish between two different users, we first tbl_user Haha user in, deleted Change the attribute to 1:
update tbl_user set deleted = 1 where id = '0e7e237ccac84518914244d1ad47e756';
3.4.2 using discriminator
According to the requirements, we need to find out the results first and then decide how to package the result set, so we can find out all the results first and then decide how to package them. We can also find out TBL first_ User's main table, and then delay loading department information according to the deleted attribute. The second scheme is selected here. You can write it down when you practice.
First, let's declare a new statement:
<select id="findAllUseDiscriminator" resultMap="userWithDiscriminator">
select * from tbl_user
</select>
For the newly declared resultMap, we also define:
<resultMap id="userWithDiscriminator" type="com.linkedbear.mybatis.entity.User">
<discriminator column="deleted" javaType="boolean">
<case value="false" resultMap="userlazy"/>
<case value="true" resultType="com.linkedbear.mybatis.entity.User"/>
</discriminator>
</resultMap>
Let's take a look at this way of writing. There is only one in it < discriminator> It can take out a column in the query result dataset, convert it to the specified type, and perform similar operations switch-case The corresponding resultMap or resultType is used according to the same value of the comparison.
tbl_user In table deleted Property. The corresponding data type is tinyint, which is equivalent to a boolean in Java. 0 represents false and 1 represents true. Then we can declare that when deleted When it is false, the user lazy loaded with delay can be used to check User Can you drop in when you're ready Department Also found out; deleted When it is true, only the attributes of this table are queried, and it is directly specified with resultType User Type is enough.
3.4.3 test run
Everything is ready. Let's write the test code briefly:
List<User> userList2 = sqlSession.selectList("com.linkedbear.mybatis.mapper.UserMapper.findAllUseDiscriminator");
userList2.forEach(System.out::println);
Then run main Method, observe the of the console User Print:
User{id='09ec5fcea620c168936deee53a9cdcfb', name='A bear', department=Department{id='18ec781fbefd727923b0d35740b177ab', name='Development Department', tel='123'}}
User{id='0e7e237ccac84518914244d1ad47e756', name='hahahaha', department=null}
User{id='5d0eebc4f370f3bd959a4f7bc2456d89', name='Old dog', department=Department{id='ee0e342201004c1721e69a99ac0dc0df', name='Operation and maintenance department', tel='456'}}
You can find haha's department The absence of the attribute indicates that the function of the discriminator is effective.
4. cache - cache
Finally, let's briefly mention the cache in mapper.xml. By default, MyBatis will only turn on based on SqlSession The L2 cache will not be enabled by default. L2 cache can also be understood as based on SqlSessionFactory Level cache / namespace range cache. A namespace corresponds to a L2 cache. If you need to turn on the L2 cache for a specific namespace, you can declare one in the corresponding mapper.xml < cache> label:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.linkedbear.mybatis.mapper.DepartmentMapper">
<cache />
<!-- ... statement ... -->
</mapper>
Since MyBatis enables L2 cache globally by default, no additional configuration is required.
There are some partners who reflect that the understanding may be ambiguous. The booklet adds a metaphor:
MyBatis enables L2 cache globally by default, just like a powered on plug-in; Declared in each mapper.xml < cache /> After labeling, it's like inserting an electrical appliance into the plug-in row. When the plug-in bank is powered on, all plugged in appliances can be used normally, but if the main switch of the whole plug-in bank is disconnected (secondary cache is disabled), all appliances can not be used.
There's another one < cache-ref> Tag, which refers to the L2 cache of other namespace s. After the introduction, the operations in this mapper.xml will also be affected < cache-ref> Cache of references.