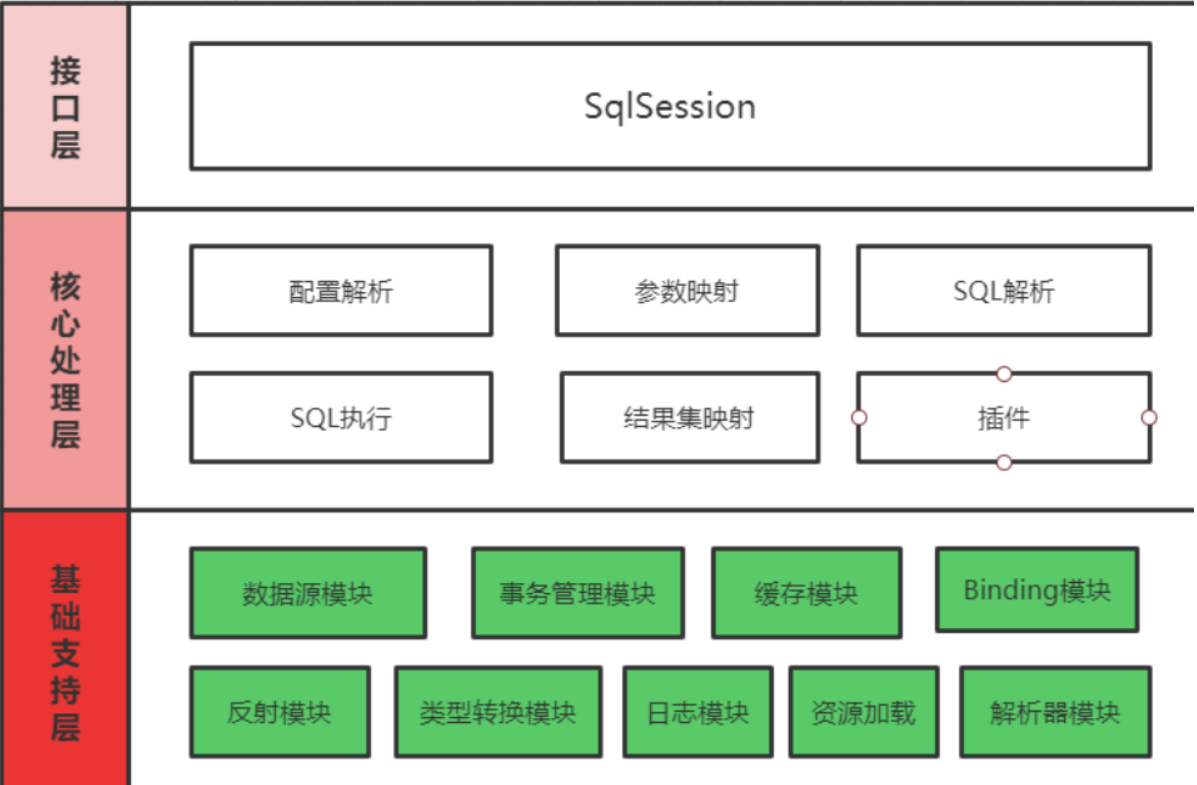
Basic support layer
The basic support layer is located at the bottom of the overall architecture of MyBatis, supports the core processing layer of MyBatis, and is the cornerstone of the whole framework. Several general and independent modules are encapsulated in the basic support layer. It not only provides basic support for MyBatis, but also can be reused directly in appropriate scenarios.
Reflection module
MyBatis uses a large number of reflection operations in parameter processing, result set mapping and other operations. Although the reflection function in Java is powerful, the code is complex and error prone. In order to simplify the code related to reflection operations, MyBatis provides a special reflection module, which is located in the org.apache.ibatis.reflection package, It further encapsulates common reflection operations and provides a more concise and convenient reflection API.
1. Reflector
Reflector is the foundation of the reflection module. Each reflector object corresponds to a class. The meta information of the class needed for reflection is cached in reflector.
1.1 properties
First, let's look at the meaning of the related attributes provided in Reflector:
// Corresponding Class type 1 private final Class<?> type; // The name collection of the readable attribute is the attribute with getter method, and the initial value is null private final String[] readablePropertyNames; // The name collection of writable properties. Writable properties are properties with setter methods, and the initial value is null private final String[] writablePropertyNames; // The corresponding setter method of the property is recorded. key is the property name and value is the Invoker method // It encapsulates the Method object corresponding to the setter Method private final Map<String, Invoker> setMethods = new HashMap<>(); // Property corresponding getter method private final Map<String, Invoker> getMethods = new HashMap<>(); // The parameter type of the corresponding setter method is recorded. key is the property name and value is the parameter type of the setter method private final Map<String, Class<?>> setTypes = new HashMap<>(); // Corresponding to the above private final Map<String, Class<?>> getTypes = new HashMap<>(); // The default construction method is recorded private Constructor<?> defaultConstructor; // A collection that records all attribute names private Map<String, String> caseInsensitivePropertyMap = new HashMap<>();
1.2 construction method
The constructor of Reflector will complete the initialization of related properties:
// Resolve the specified Class type and fill in the above collection information
public Reflector(Class<?> clazz) {
type = clazz; // Initialize type field
addDefaultConstructor(clazz);// Set default construction method
addGetMethods(clazz);// Get getter method
addSetMethods(clazz); // Get setter method
addFields(clazz); // Processing fields without getter/setter methods
// Initializes a collection of readable property names
readablePropertyNames = getMethods.keySet().toArray(new String[0]);
// Initializes the collection of writable attribute names
writablePropertyNames = setMethods.keySet().toArray(new String[0]);
// caseInsensitivePropertyMap records the names of all readable and writable properties, that is, all property names
for (String propName : readablePropertyNames) {
// Attribute name to uppercase
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
for (String propName : writablePropertyNames) {
// Attribute name to uppercase
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
}
Reflection can also be used directly in the project to define an ordinary Bean object.
public class Person {
private Integer id;
private String name;
public Person(Integer id) {
this.id = id;
}
public Person(Integer id, String name) {
this.id = id;
this.name = name;
}
}
Test:
Reflector reflector = new Reflector(Person.class);

1.3 public API methods
Then we can look at the public API methods provided in Reflector:
| Method name | effect |
|---|---|
| getType | Gets the Class represented by the Reflector |
| getDefaultConstructor | Gets the default constructor |
| hasDefaultConstructor | Determine whether there is a default constructor |
| getSetInvoker | Get the corresponding Invoker object according to the property name |
| getGetInvoker | Get the corresponding Invoker object according to the property name |
| getSetterType | Get the type corresponding to the attribute, such as: String name// getSetterType(“name”) --> java.lang.String |
| getGetterType | It corresponds to the above |
| getGetablePropertyNames | Gets a collection of all readable property names |
| getSetablePropertyNames | Gets a collection of all writable property names |
| hasSetter | Determine whether there is a writable attribute |
| hasGetter | Determine whether there is a readable attribute |
| findPropertyName | Find properties by name |
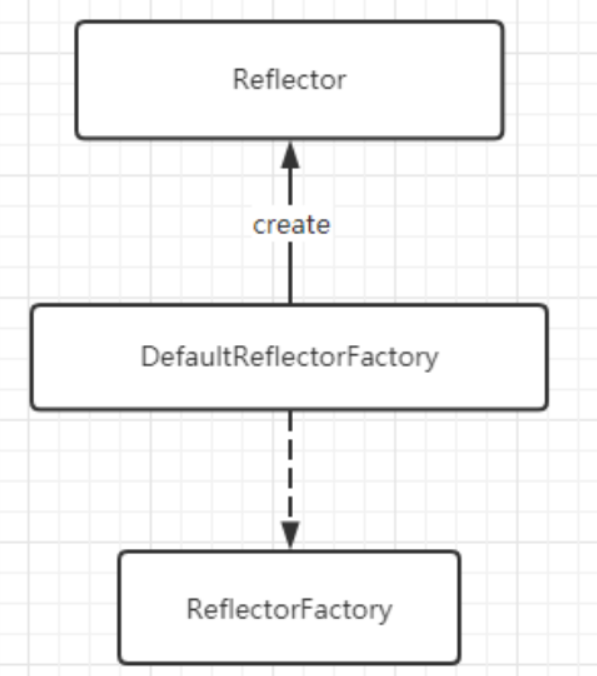
After knowing the basic information of Reflector object, how do we get Reflector object? A ReflectorFactory factory object is provided in MyBatis. So let's first briefly understand the ReflectorFactory object. Of course, you can also directly new it, just like the above case.
2. ReflectorFactory
The ReflectorFactory interface mainly implements the creation and caching of Reflector objects.
2.1 definition of interface
public interface ReflectorFactory {
// Detects whether the Reflector object is cached in the ReflectorFactory
boolean isClassCacheEnabled();
// Sets whether to cache Reflector objects
void setClassCacheEnabled(boolean classCacheEnabled);
// Create a Reflector object with a specified Class
Reflector findForClass(Class<?> type);
}
2.2 DefaultReflectorFactory
MyBatis only provides an implementation class DefaultReflectorFactory for this interface. His relationship with Reflector is as follows:
The implementation code in DefaultReflectorFactory is relatively simple. We will post it directly:
public class DefaultReflectorFactory implements ReflectorFactory {
private boolean classCacheEnabled = true;
// Implement caching of Reflector objects
private final ConcurrentMap<Class<?>, Reflector> reflectorMap = new ConcurrentHashMap<>();
public DefaultReflectorFactory() {
}
@Override
public boolean isClassCacheEnabled() {
return classCacheEnabled;
}
@Override
public void setClassCacheEnabled(boolean classCacheEnabled) {
this.classCacheEnabled = classCacheEnabled;
}
@Override
public Reflector findForClass(Class<?> type) {
if (classCacheEnabled) {// Enable cache
// synchronized (type) removed see issue #461
return reflectorMap.computeIfAbsent(type, Reflector::new);
} else {
// Create directly without opening the cache
return new Reflector(type);
}
}
}
2.3 basic use
Through the above introduction, we can use it specifically to deepen our understanding. First, prepare a JavaBean.
public class Student {
public Integer getId() {
System.out.println("reading id");
return 6;
}
public void setId(Integer id) {
System.out.println("write in id:" + id);
}
public String getName() {
return "Zhang San";
}
}
We did a simple process for this Bean.
@Test
public void test02() {
ReflectorFactory factory = new DefaultReflectorFactory();
Reflector reflector = factory.findForClass(Student.class);
System.out.println("Readable properties:"+Arrays.toString(reflector.getGetablePropertyNames()));
System.out.println("Writable attribute:"+Arrays.toString(reflector.getSetablePropertyNames()));
System.out.println("Does it have a default constructor:" + reflector.hasDefaultConstructor());
System.out.println("Reflector Corresponding Class:" + reflector.getType());
}

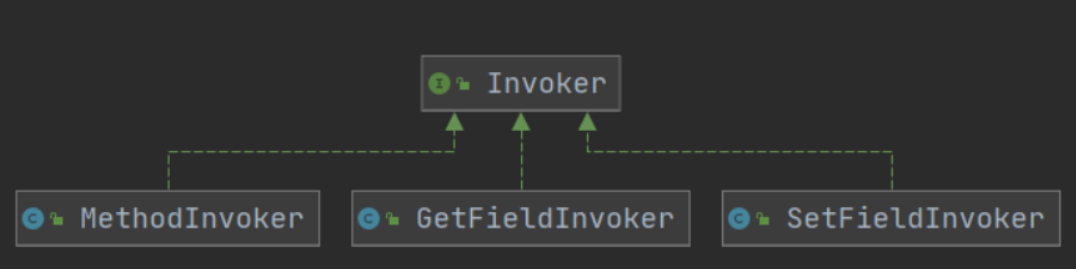
3. Invoker
For the calls of Field and Method in Class, the Invoker object is encapsulated in MyBatis for unified processing (adapter mode is used).
3.1 interface description
public interface Invoker {
// Execute Field or Method
Object invoke(Object target, Object[] args) throws IllegalAccessException, InvocationTargetException;
// Returns the corresponding type of the property
Class<?> getType();
}
The interface has three corresponding implementations:
3.2 basic use
@Test
public void test03() throws Exception {
ReflectorFactory factory = new DefaultReflectorFactory();
Reflector reflector = factory.findForClass(Student.class);
//Get the constructor and generate the corresponding object
Object o = reflector.getDefaultConstructor().newInstance();
MethodInvoker invoker = (MethodInvoker) reflector.getSetInvoker("id");
invoker.invoke(o, new Object[]{999});
//read
Invoker invoker1 = reflector.getGetInvoker("id");
invoker1.invoke(o, null);
}
4. MetaClass
You can operate on common attributes in Reflector, but if there are more complex attributes, such as private Person person; In this case, the expression we are looking for is person.userName. This expression can be processed through MetaClass. Let's take a look at the main properties and construction methods:
// Cache Reflector
private final ReflectorFactory reflectorFactory;
// When creating a MetaClass, a class will be specified, and the reflector will record the relevant information of the class
private final Reflector reflector;
private MetaClass(Class<?> type, ReflectorFactory reflectorFactory) {
this.reflectorFactory = reflectorFactory;
this.reflector = reflectorFactory.findForClass(type);
}
Effect demonstration, prepare Bean object:
public class RichType {
private RichType richType;
private String richField;
private String richProperty;
private Map richMap = new HashMap();
private List richList = new ArrayList() {
{
add("bar");
}
};
public RichType getRichType() {
return richType;
}
public void setRichType(RichType richType) {
this.richType = richType;
}
public String getRichProperty() {
return richProperty;
}
public void setRichProperty(String richProperty) {
this.richProperty = richProperty;
}
public List getRichList() {
return richList;
}
public void setRichList(List richList) {
this.richList = richList;
}
public Map getRichMap() {
return richMap;
}
public void setRichMap(Map richMap) {
this.richMap = richMap;
}
}
Test:
@Test
public void test04() throws Exception {
ReflectorFactory reflectorFactory = new DefaultReflectorFactory();
MetaClass meta = MetaClass.forClass(RichType.class, reflectorFactory);
System.out.println(meta.hasGetter("richField"));
System.out.println(meta.hasGetter("richProperty"));
System.out.println(meta.hasGetter("richList"));
System.out.println(meta.hasGetter("richMap"));
System.out.println(meta.hasGetter("richList[0]"));
System.out.println(meta.hasGetter("richType"));
System.out.println(meta.hasGetter("richType.richField"));
System.out.println(meta.hasGetter("richType.richProperty"));
System.out.println(meta.hasGetter("richType.richList"));
System.out.println(meta.hasGetter("richType.richMap"));
System.out.println(meta.hasGetter("richType.richList[0]")); // findProperty can only handle expressions of
System.out.println(meta.findProperty("richType.richProperty"));
System.out.println(meta.findProperty("richType.richProperty1"));
System.out.println(meta.findProperty("richList[0]"));
System.out.println(Arrays.toString(meta.getGetterNames()));
}
5. MetaObject
We can parse complex expressions through MetaObject objects to operate on the provided objects. The specific demonstration through cases will be more intuitive.
@Test
public void shouldGetAndSetField() {
RichType rich = new RichType();
MetaObject meta = SystemMetaObject.forObject(rich);
meta.setValue("richField", "foo");
System.out.println(meta.getValue("richField"));
}
@Test
public void shouldGetAndSetNestedField() {
RichType rich = new RichType();
MetaObject meta = SystemMetaObject.forObject(rich);
meta.setValue("richType.richField", "foo");
System.out.println(meta.getValue("richType.richField"));
}
@Test
public void shouldGetAndSetMapPairUsingArraySyntax() {
RichType rich = new RichType();
MetaObject meta = SystemMetaObject.forObject(rich);
meta.setValue("richMap[key]", "foo");
System.out.println(meta.getValue("richMap[key]"));
}
The output of the above three methods is foo
6. Application of reflection module
Then let's look at the practical application in the core processing layer of MyBatis.
6.1 SqlSessionFactory
When creating SqlSessionFactory, the Configuration object will be created, and the implementation of ReflectorFactory defined by default in Configuration is the DefaultReflectorFactory object.
Then, in the code for parsing the global configuration file, the user is provided with the extension of ReflectorFactory, that is, we can use our customized ReflectorFactory through tags in the global configuration file.
6.2 SqlSession
No related operation
6.3 Mapper
No related operation
6.4 execute SQL
After obtaining the result set in the Statement, it is used in the createResultObject method of DefaultResultSetHandler when mapping the result set.

Then, during automatic mapping in the getRowValue method of DefaultResultSetHandler:

To continue tracing, in the createAutomaticMappings method:

Of course, there are many other places where the reflection module is used to complete the relevant operations, which can be consulted by yourself.
Type conversion module
String sql = "SELECT id,user_name,real_name,password,age,d_id from t_user where id = ? and user_name = ?"; ps = conn.prepareStatement(sql); ps.setInt(1,2); ps.setString(2,"Zhang San");
MyBatis is a persistence layer framework ORM framework, which realizes the two-way mapping of data in the database and attributes in Java objects, so it is inevitable to encounter the problem of type conversion. When PreparedStatement binds parameters to SQL statements, it needs to be converted from Java type to JDBC type, and when obtaining data from the result set, it needs to be converted from JDBC type to Java type, So let's look at how to implement type conversion in MyBatis.
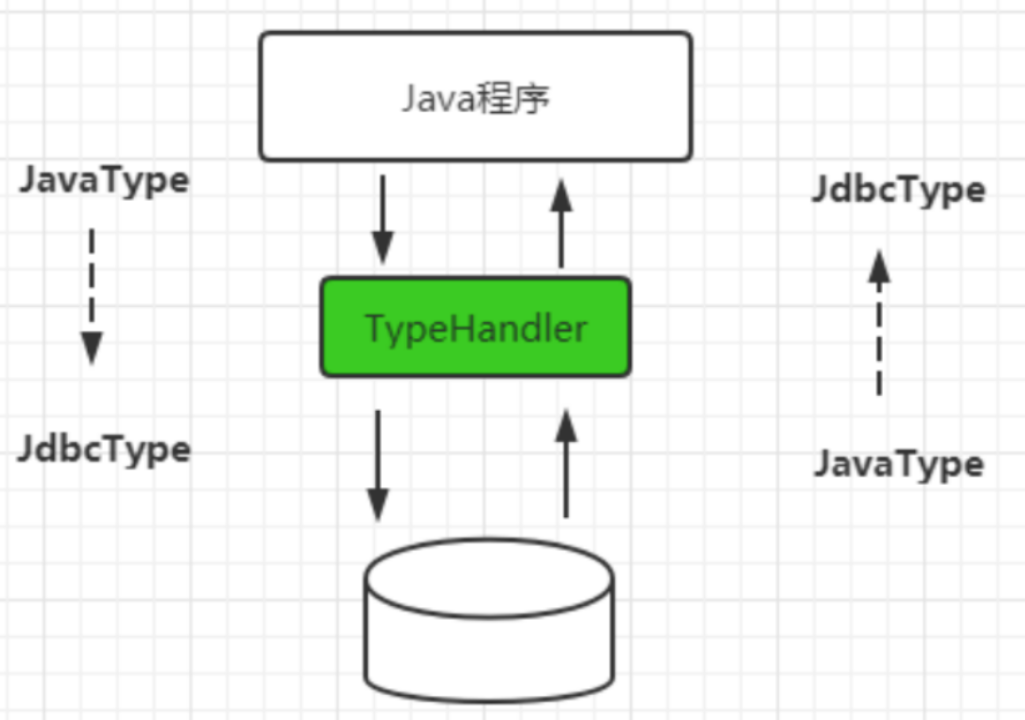
1. TypeHandler
All type converters in MyBatis inherit the TypeHandler interface, which defines the most basic functions of type converters.
public interface TypeHandler<T> {
/**
* Responsible for converting Java types to JDBC types
* @param ps
* @param i
* @param parameter
* @param jdbcType
* @throws SQLException
*/
void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
/**
* This method is called when getting data from the ResultSet, which converts the data from JdbcType to Java type
* @param columnName Colunm name, when configuration <code>useColumnLabel</code> is <code>false</code>
*/
T getResult(ResultSet rs, String columnName) throws SQLException;
T getResult(ResultSet rs, int columnIndex) throws SQLException;
T getResult(CallableStatement cs, int columnIndex) throws SQLException;
}
2. BaseTypeHandler
In order to facilitate users to customize the implementation of TypeHandler, the abstract class BaseTypeHandler is provided in MyBatis, which implements the TypeHandler interface and inherits the TypeReference class.
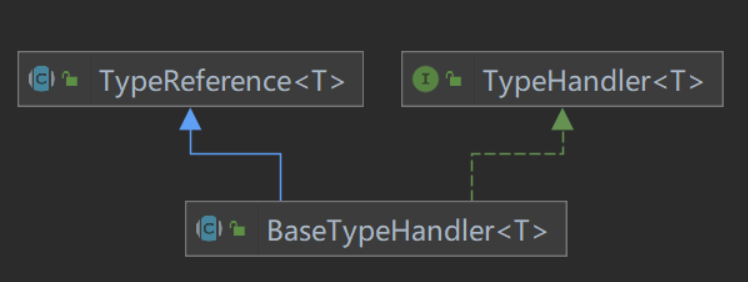
null processing is implemented in the implementation method of BaseTypeHandler, and non empty processing is handed over to each subclass. This is clearly reflected in the code.
3. TypeHandler implementation class
There are many implementation classes of TypeHandler, and the implementation is relatively simple.
Take Integer as an example:
public class IntegerTypeHandler extends BaseTypeHandler<Integer> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, Integer parameter, JdbcType jdbcType)
throws SQLException {
ps.setInt(i, parameter); // Binding of implementation parameters
}
@Override
public Integer getNullableResult(ResultSet rs, String columnName)
throws SQLException {
int result = rs.getInt(columnName); // Gets the value of the specified column
return result == 0 && rs.wasNull() ? null : result;
}
@Override
public Integer getNullableResult(ResultSet rs, int columnIndex)
throws SQLException {
int result = rs.getInt(columnIndex); // Gets the value of the specified column
return result == 0 && rs.wasNull() ? null : result;
}
@Override
public Integer getNullableResult(CallableStatement cs, int columnIndex)
throws SQLException {
int result = cs.getInt(columnIndex); // Gets the value of the specified column
return result == 0 && cs.wasNull() ? null : result;
}
}
4. TypeHandlerRegistry
Through the previous introduction, we found that there are too many specific type converters provided to us in MyBatis. How do we know which converter class to use in actual use? In fact, all typehandlers are saved and registered in TypeHandlerRegistry in MyBatis. First, pay attention to the related attributes of the Declaration: (it will be found when parsing the configuration file)
// Record the correspondence between JdbcType and TypeHandle private final Map<JdbcType, TypeHandler<?>> jdbcTypeHandlerMap = new EnumMap<>(JdbcType.class); // Record the TypeHandle that needs to be used when converting a Java type to the specified JdbcType private final Map<Type, Map<JdbcType, TypeHandler<?>>> typeHandlerMap = new ConcurrentHashMap<>(); private final TypeHandler<Object> unknownTypeHandler; // Record all TypeHandle types and corresponding TypeHandle objects private final Map<Class<?>, TypeHandler<?>> allTypeHandlersMap = new HashMap<>(); // The identity of an empty TypeHandle private static final Map<JdbcType, TypeHandler<?>> NULL_TYPE_HANDLER_MAP = Collections.emptyMap();
Then, the TypeHandler provided by the system is registered in the constructor method:
The code is too long, please check it yourself. Note that the key implementations of register() method are as follows:
private <T> void register(Type javaType, TypeHandler<? extends T> typeHandler) {
// Get @ MappedJdbcTypes annotation
MappedJdbcTypes mappedJdbcTypes = typeHandler.getClass().getAnnotation(MappedJdbcTypes.class);
if (mappedJdbcTypes != null) {
// Traverse to get the JdbcType type specified in the annotation
for (JdbcType handledJdbcType : mappedJdbcTypes.value()) {
// Call the next overloaded method
register(javaType, handledJdbcType, typeHandler);
}
if (mappedJdbcTypes.includeNullJdbcType()) {
// When the JdbcType type is empty
register(javaType, null, typeHandler);
}
} else {
register(javaType, null, typeHandler);
}
}
private void register(Type javaType, JdbcType jdbcType, TypeHandler<?> handler) {
if (javaType != null) {// If not empty
// Get the corresponding collection according to the Java type from the TypeHandle collection
Map<JdbcType, TypeHandler<?>> map = typeHandlerMap.get(javaType);
if (map == null || map == NULL_TYPE_HANDLER_MAP) {
// If not, create a new one
map = new HashMap<>();
}
// Add the corresponding jdbc type and processor to the map collection
map.put(jdbcType, handler);
// Then save the java type and the above map collection into the container of TypeHandle
typeHandlerMap.put(javaType, map);
}
// The processor is also added to the container that holds all the processors
allTypeHandlersMap.put(handler.getClass(), handler);
}
There are registered methods. Of course, there are also methods to obtain TypeHandler from the Registrar and getTypeHandler. This method also has multiple overloaded methods. The method that overloaded methods will eventually execute is.
/**
* Find the corresponding TypeHandle according to the corresponding Java type and Jdbc type
*/
private <T> TypeHandler<T> getTypeHandler(Type type, JdbcType jdbcType) {
if (ParamMap.class.equals(type)) {
return null;
}
// Get the collection container of the corresponding Jdbc type and TypeHandle according to the Java type
Map<JdbcType, TypeHandler<?>> jdbcHandlerMap = getJdbcHandlerMap(type);
TypeHandler<?> handler = null;
if (jdbcHandlerMap != null) {
// Obtain the corresponding processor according to the Jdbc type
handler = jdbcHandlerMap.get(jdbcType);
if (handler == null) {
// Get the processor corresponding to null
handler = jdbcHandlerMap.get(null);
}
if (handler == null) {
// #591
handler = pickSoleHandler(jdbcHandlerMap);
}
}
// type drives generics here
return (TypeHandler<T>) handler;
}
Of course, in addition to using the TypeHandler provided by the system, we can also create our own TypeHandler, as mentioned in previous projects.
5. TypeAliasRegistry
We often use aliases in the application of MyBatis, which can greatly simplify our code. In fact, we use aliases in MyBatis. Managed by the TypeAliasRegistry class. First, aliases of common types of the system will be injected into the construction method. This register will be used when initializing the configuration.

The method logic of registration is also relatively simple:
public void registerAlias(String alias, Class<?> value) {
if (alias == null) {
throw new TypeException("The parameter alias cannot be null");
}
// issue #748 aliases are uniformly converted to lowercase
String key = alias.toLowerCase(Locale.ENGLISH);
if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
}
// Add aliases and types to the Map collection
typeAliases.put(key, value);
}
How do we specify the alias path through package and specify the alias through @ Alisa annotation in actual use? It is also implemented in TypeAliasRegistry:
/**
* Specify according to packagename
* @param packageName
* @param superType
*/
public void registerAliases(String packageName, Class<?> superType) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> typeSet = resolverUtil.getClasses();
for (Class<?> type : typeSet) {
// Ignore inner classes and interfaces (including package-info.java)
// Skip also inner classes. See issue #6
if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
registerAlias(type);
}
}
}
/**
* Scan @ Alias annotation
* @param type
*/
public void registerAlias(Class<?> type) {
String alias = type.getSimpleName();
// Scan @ Alias annotation
Alias aliasAnnotation = type.getAnnotation(Alias.class);
if (aliasAnnotation != null) {
// Gets the alias name defined in the annotation
alias = aliasAnnotation.value();
}
registerAlias(alias, type);
}
6. Application of typehandler
6.1 SqlSessionFactory
When building SqlSessionFactory, the instantiation of TypeHandlerRegistry and TypeAliasRegistry is completed in the member variable when the Configuration object is instantiated.

The TypeHandler of common types is registered in the construction method of TypeHandlerRegistry; Complete the registration of common Java type aliases in typealias registry; In the Configuration constructor, type alias data will be registered in TypeAliasRegistry for various common types. (see the screenshot above.)
The above steps have completed the initialization of TypeHandlerRegistry and TypeAliasRegistry.
Then, when parsing the global configuration file, we can register the alias and TypeHandler we added by parsing the tag and tag.

The two methods of specific analysis are very simple. You can open the source code and have a look.
Because we specify the corresponding alias in the global configuration file, we can abbreviate our type in the mapping file. In this way, we also need to deal with the alias when parsing the mapping file. In XMLStatementBuilder:

This parameterType can be the alias defined by us, and then the corresponding processing will be performed in resolveClass:
protected <T> Class<? extends T> resolveClass(String alias) {
if (alias == null) {
return null;
}
try {
return resolveAlias(alias);
} catch (Exception e) {
throw new BuilderException("Error resolving class. Cause: " + e, e);
}
}
6.2 executing SQL statements
TypeHandler type processors are often used to bind parameter values in SQL statements, query results and attribute mapping in objects.
Let's first enter the DefaultParameterHandler to see how the parameters are handled:
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
Then enter the getRowValue method in DefaultResultSetHandler:

Then enter the applyAutomaticMappings method to view:

Returns the value of the corresponding type according to the corresponding TypeHandler.
Log module
First of all, logs play a very important role in our development process. They are a bridge between development and operation and maintenance management. There are many log frameworks in Java, such as log4j, log4j2, Apache common log, java.util.logging, slf4j, etc. the external interfaces of these tools are also different. In order to unify these tools, MyBatis defines a set of unified log interfaces for the upper layer. First of all, you should understand the adapter mode.
1. LOG
Four Log levels are defined in the Log interface. Compared with other Log frameworks, they are very concise, but they can also meet most common uses. It is located in the source code logging package.
public interface Log {
boolean isDebugEnabled();
boolean isTraceEnabled();
void error(String s, Throwable e);
void error(String s);
void debug(String s);
void trace(String s);
void warn(String s);
}
2. LogFactory
The LogFactory factory class is responsible for creating the log component adapter:
static {
// Load the corresponding log components in sequence and load them from top to bottom. If the above is successful, the following will not be loaded
/**
* tryImplementation(LogFactory::useSlf4jLogging); Equivalent to
* tryImplementation(new Runnable(){
* void run(){
* useSlf4jLogging();
* }
* })
*/
tryImplementation(LogFactory::useSlf4jLogging);
tryImplementation(LogFactory::useCommonsLogging);
tryImplementation(LogFactory::useLog4J2Logging);
tryImplementation(LogFactory::useLog4JLogging);
tryImplementation(LogFactory::useJdkLogging);
tryImplementation(LogFactory::useNoLogging);
}
When the LogFactory class is loaded, its static code block will be executed. Its logic is to load and instantiate the adapter of the corresponding log component in order, and then use the static field LogFactory.logConstructor to record the adapter of the currently used third-party log component. The specific code is as follows. Each method is relatively simple and will not be repeated one by one.
3. Log application
So how to choose the logging framework when the MyBatis system is started? First, we can set the corresponding log type selection in the global configuration file.
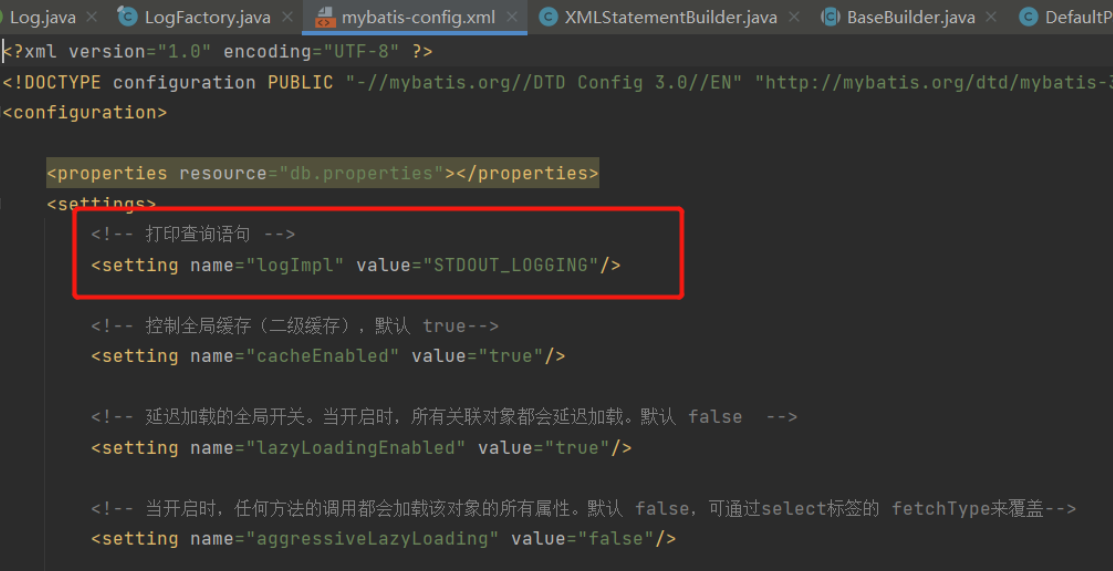
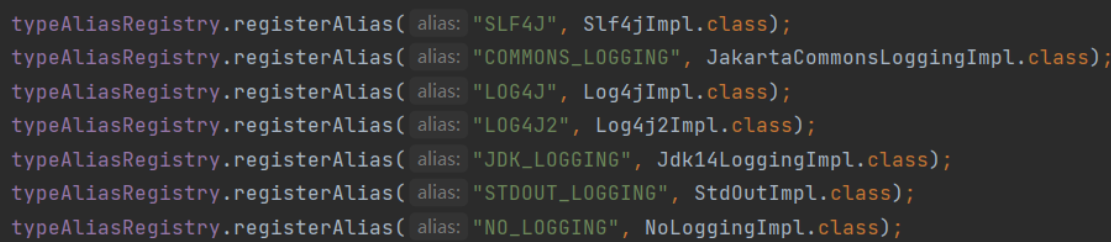
How did this "STDOUT_LOGGING" come from? In the Configuration construction method, the alias of each log implementation is actually set.
Then, the log settings will be processed when parsing the global configuration file:
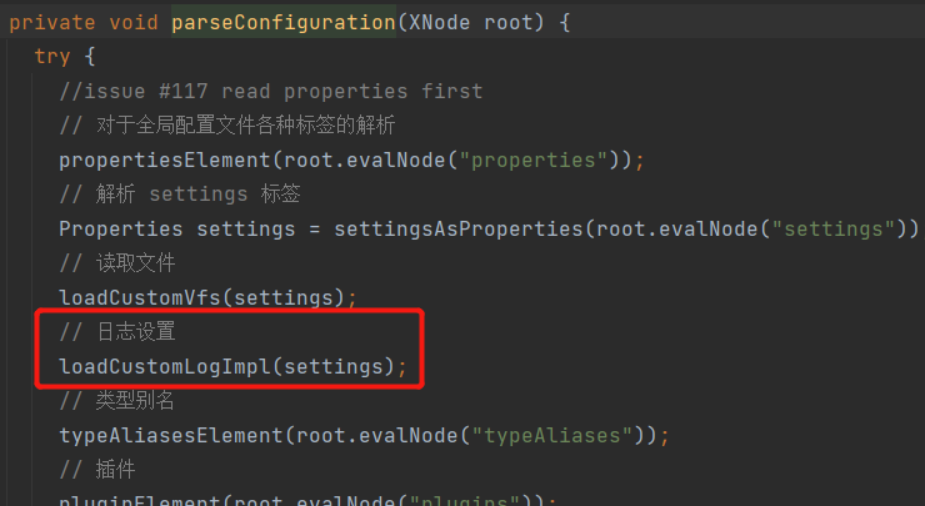
Entry method:
private void loadCustomLogImpl(Properties props) {
// Gets the log type of the logImpl setting
Class<? extends Log> logImpl = resolveClass(props.getProperty("logImpl"));
// Set log
configuration.setLogImpl(logImpl);
}
Enter the setLogImpl method:
public void setLogImpl(Class<? extends Log> logImpl) {
if (logImpl != null) {
this.logImpl = logImpl; // Type of log
// Set adaptation selection
LogFactory.useCustomLogging(this.logImpl);
}
}
Then enter the useCustomLogging method:
public static synchronized void useCustomLogging(Class<? extends Log> clazz) {
setImplementation(clazz);
}
private static void setImplementation(Class<? extends Log> implClass) {
try {
// Gets the constructor of the specified adapter
Constructor<? extends Log> candidate = implClass.getConstructor(String.class);
// Instantiate adapter
Log log = candidate.newInstance(LogFactory.class.getName());
if (log.isDebugEnabled()) {
log.debug("Logging initialized using '" + implClass + "' adapter.");
}
// Initialize logConstructor field
logConstructor = candidate;
} catch (Throwable t) {
throw new LogException("Error setting Log implementation. Cause: " + t, t);
}
}
This is related to the code we saw in LogFactory earlier, and the log seen by starting the test method corresponds to that in the source code. In addition, our own settings will overwrite the default configuration of the sl4j log framework.

4. JDBC log
When we enable the log management of STDOUT, when we execute SQL operations, we find that the relevant log information can be printed in the console.
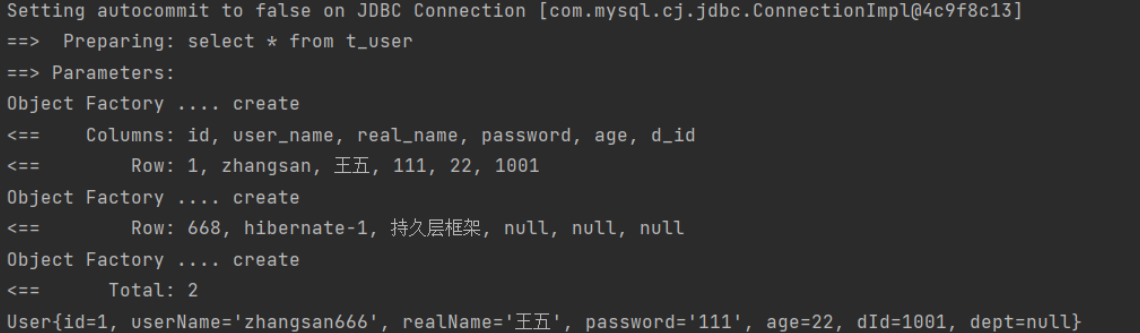
How do you print these log information? Originally, the log module in MyBatis contains a JDBC package, which does not save the log information to the database through JDBC operation, but prints the JDBC operation through the specified log framework through the JDK dynamic agent. Let's take a look at how it is implemented.
4.1 BaseJdbcLogger
BaseJdbcLogger is an abstract class, which is the parent class of other loggers under the jdbc package. The inheritance relationship is as follows:

We can also see from the figure that all four implementations implement the InvocationHandler interface. The meaning of attribute is as follows:
// Record the common set * () methods defined in the PreparedStatement interface protected static final Set<String> SET_METHODS; // Records the methods related to executing SQL statements in the Statement interface and PreparedStatement interface protected static final Set<String> EXECUTE_METHODS = new HashSet<>(); // The key value pairs set by the PreparedStatement.set * () method are recorded private final Map<Object, Object> columnMap = new HashMap<>(); // The key set by PreparedStatement.set * () method is recorded private final List<Object> columnNames = new ArrayList<>(); // The Value set by the PreparedStatement.set * () method is recorded private final List<Object> columnValues = new ArrayList<>(); protected final Log statementLog;// Log object for log output protected final int queryStack; // The number of layers of SQL is recorded, which is used to format the output SQL
4.2 ConnectionLogger
The function of ConnectionLogger is to record the log information related to database Connection. In the implementation, a Connection proxy object is created. We can realize the log operation before and after each Connection operation.
public final class ConnectionLogger extends BaseJdbcLogger implements InvocationHandler {
// Real Connection object
private final Connection connection;
private ConnectionLogger(Connection conn, Log statementLog, int queryStack) {
super(statementLog, queryStack);
this.connection = conn;
}
@Override
public Object invoke(Object proxy, Method method, Object[] params)
throws Throwable {
try {
// If you are calling methods inherited from Object, you can directly call toString,hashCode,equals, etc
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
// If the prepareStatement method is called
if ("prepareStatement".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
// Create PreparedStatement
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
// Then create a proxy object enhancement for PreparedStatement
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
// ditto
} else if ("prepareCall".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
// ditto
} else if ("createStatement".equals(method.getName())) {
Statement stmt = (Statement) method.invoke(connection, params);
stmt = StatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else {
return method.invoke(connection, params);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
/**
* Creates a logging version of a connection.
*
* @param conn - the original connection
* @return - the connection with logging
*/
public static Connection newInstance(Connection conn, Log statementLog, int queryStack) {
InvocationHandler handler = new ConnectionLogger(conn, statementLog, queryStack);
ClassLoader cl = Connection.class.getClassLoader();
// The proxy object of Connection is created to enhance the Connection object and add logging function to it
return (Connection) Proxy.newProxyInstance(cl, new Class[]{Connection.class}, handler);
}
/**
* return the wrapped connection.
*
* @return the connection
*/
public Connection getConnection() {
return connection;
}
}
The implementation of other xloggers is almost the same as that of ConnectionLogger. I won't repeat it again. Please watch it yourself.
4.3 application realization
How does the log module work during actual processing?
We need to obtain the Statement object before executing the SQL Statement, and the Statement object is obtained through Connection, so we can see the relevant code in simpleexecution.
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
// Get Statement object
stmt = handler.prepare(connection, transaction.getTimeout());
// Set parameters for Statement
handler.parameterize(stmt);
return stmt;
}
Enter the getConnection method first:
protected Connection getConnection(Log statementLog) throws SQLException {
Connection connection = transaction.getConnection();
if (statementLog.isDebugEnabled()) {
// Create log proxy object for Connection
return ConnectionLogger.newInstance(connection, statementLog, queryStack);
} else {
return connection;
}
}
After entering the handler.prepare method:
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
// When the prepareStatement method is executed, it will enter the invoker method of ConnectionLogger
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
return connection.prepareStatement(sql);
} else {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}

When executing sql statements:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// To the JDBC process
ps.execute();
// Processing result set
return resultSetHandler.handleResultSets(ps);
}
If it is a query operation, the following ResultSet result set operations are also handled through ResultSetLogger. The previous ones are clear, and the latter ones are easy.
binding module
Next, let's take a look at the Binding module provided to us under the org.apache.ibatis.binding package. This module has been used before.
// 3. Obtain the SqlSession object according to the SqlSessionFactory object SqlSession sqlSession = factory.openSession(); // 4. Operate the database through the API methods provided in SqlSession UserMapper mapper = sqlSession.getMapper(UserMapper.class);
1. MapperRegistry
From the name, we can see that this is obviously a registration center. This registration is used to save MapperProxyFactory objects. Therefore, the functions provided in this register must focus on the addition and acquisition of MapperProxyFactory. Let's take a look at the specific code logic.
Member variables:
private final Configuration config; // Record the relationship between Mapper interface and MapperProxyFactory private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();
addMapper method:
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) { // Check whether the type is an interface
if (hasMapper(type)) { // Check whether the interface has been installed
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// ! Map<Class<?>, MapperProxyFactory<?>> It stores the relationship between the interface type and the corresponding factory class
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
// After registering the interface, start parsing annotations on all methods according to the interface, such as @ Select > >
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
getMapper method:
/**
* Get the proxy object corresponding to Mapper interface
*/
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// Gets the MapperProxyFactory object corresponding to the Mapper interface
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
In essence, what is obtained through this method is the proxy object of Mapper interface.
2. MapperProxyFactory
MapperProxyFactory is a factory object that is specifically responsible for creating MapperProxy objects. The meanings and functions of the core fields are as follows:
/*** MapperProxyFactory You can create a proxy object for the mapperInterface interface
* The interface to be implemented by the created proxy object */
private final Class<T> mapperInterface;
// cache
private final Map<Method, MapperMethodInvoker> methodCache = new ConcurrentHashMap<>();
//
....
/*** Create a proxy object that implements the mapperInterface interface */
protected T newInstance(MapperProxy<T> mapperProxy) {
// 1: Class loader: 2: the interface implemented by the proxy class; 3: the trigger management class that implements InvocationHandler
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
3. MapperProxy
MapperProxy created through MapperProxyFactory is the proxy object of Mapper interface and implements the InvocationHandler interface. Through the dynamic proxy mode explained earlier, this part is very simple.
private final SqlSession sqlSession; // Record the associated SqlSession object private final Class<T> mapperInterface; // Class object corresponding to Mapper interface // Used to cache MapperMethod objects. key is the Method object corresponding to the Mapper interface Method, and value is the corresponding MapperMethod object‘ // MapperMethod object will complete parameter conversion and SQL statement execution // Note: no status information is recorded in MapperMethod and can be shared among multiple threads private final Map<Method, MapperMethodInvoker> methodCache;
MapperProxy.invoke() method is the main logic executed by the proxy object. Its implementation is as follows:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// toString hashCode equals getClass and other methods do not need to go to the SQL execution process
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// Improve the efficiency of obtaining mapperMethod by invoking mapperMethod invoke r (internal interface)
// The normal method will go to the invoke of PlainMethodInvoker (inner class)
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
Then, the cachedInvoker is mainly responsible for maintaining the cache collection of methodCache:
private MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
try {
// The Map method in Java 8 obtains the value according to the key. If the value is null, assign the value of the following Object to the key
// If you can't get it, create it
// The MapperMethodInvoker (Interface) object is obtained, and there is only one invoke method
// Get it from the methodCache according to the method. If it returns null, fill it with the second parameter
return methodCache.computeIfAbsent(method, m -> {
if (m.isDefault()) {
// The default method of the interface (Java 8). As long as the interface is implemented, it will inherit the default method of the interface, such as List.sort()
try {
if (privateLookupInMethod == null) {
return new DefaultMethodInvoker(getMethodHandleJava8(method));
} else {
return new DefaultMethodInvoker(getMethodHandleJava9(method));
}
} catch (IllegalAccessException | InstantiationException | InvocationTargetException
| NoSuchMethodException e) {
throw new RuntimeException(e);
}
} else {
// Created a MapperMethod
return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
});
} catch (RuntimeException re) {
Throwable cause = re.getCause();
throw cause == null ? re : cause;
}
}
4. MapperMethod
MapperMethod encapsulates the information of corresponding methods in Mapper interface and SQL statements. We can regard MapperMethod as a bridge between SQL statements defined in configuration file and Mapper interface.

Properties and construction methods:
// statement id (for example: com.gupaoedu.mapper.BlogMapper.selectBlogById) and SQL type
private final SqlCommand command;
// Method signature, mainly the type of return value
private final MethodSignature method;
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
4.1 SqlCommand
SqlCommand is an internal class defined in MapperMethod, which records the SQL statement name and corresponding types (unknown, insert, update, delete, select, flow):
public static class SqlCommand {
private final String name; // The name of the SQL statement
private final SqlCommandType type; // Type of SQL statement
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
// Get method name
final String methodName = method.getName();
final Class<?> declaringClass = method.getDeclaringClass();
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,
configuration);
if (ms == null) {
if (method.getAnnotation(Flush.class) != null) {
name = null;
type = SqlCommandType.FLUSH;
} else {
throw new BindingException("Invalid bound statement (not found): "
+ mapperInterface.getName() + "." + methodName);
}
} else {
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
public String getName() {
return name;
}
public SqlCommandType getType() {
return type;
}
private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName,
Class<?> declaringClass, Configuration configuration) {
// statementId = Mapper interface full path + method name, for example: com.gupaoedu.mapper.UserMapper
String statementId = mapperInterface.getName() + "." + methodName;
if (configuration.hasStatement(statementId)) {// Check if there is an SQL statement with that name
return configuration.getMappedStatement(statementId);
} else if (mapperInterface.equals(declaringClass)) {
return null;
}
// If the Mapper interface has a parent class, it will be processed recursively
for (Class<?> superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
MappedStatement ms = resolveMappedStatement(superInterface, methodName,
declaringClass, configuration);
if (ms != null) {
return ms;
}
}
}
return null;
}
}
4.2 MethodSignature
MethodSignature is also an internal class of MapperMethod, which encapsulates the method related information defined in Mapper interface.
private final boolean returnsMany; // Judge whether the return is of Collection type or array type private final boolean returnsMap; // Whether the return value is of Map type private final boolean returnsVoid; // Whether the return value type is void private final boolean returnsCursor; // Whether the return value type is Cursor type private final boolean returnsOptional; // Whether the return value type is Optional private final Class<?> returnType; // return type private final String mapKey; // If the return value type is Map, mapKey records the column name as the key private final Integer resultHandlerIndex; // Used to mark the position of the ResultHandler type parameter in the method parameter list private final Integer rowBoundsIndex; // Used to mark the position of the rowBounds type parameter in the method parameter list private final ParamNameResolver paramNameResolver; // The ParamNameResolver object corresponding to this method
The initialization of relevant information is completed in the construction method:
public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) {
// Gets the return type of the interface method
Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface);
if (resolvedReturnType instanceof Class<?>) {
this.returnType = (Class<?>) resolvedReturnType;
} else if (resolvedReturnType instanceof ParameterizedType) {
this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType();
} else {
this.returnType = method.getReturnType();
}
this.returnsVoid = void.class.equals(this.returnType);
this.returnsMany = configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray();
this.returnsCursor = Cursor.class.equals(this.returnType);
this.returnsOptional = Optional.class.equals(this.returnType);
this.mapKey = getMapKey(method);
this.returnsMap = this.mapKey != null;
// getUniqueParamIndex finds the position of the parameter of the specified type in the parameter list
this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);
this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);
this.paramNameResolver = new ParamNameResolver(configuration, method);
}
The main function of getUniqueParamIndex is to find the position of the parameter of the specified type in the parameter list:
private Integer getUniqueParamIndex(Method method, Class<?> paramType) {
Integer index = null;
// Get the parameter list of the corresponding method
final Class<?>[] argTypes = method.getParameterTypes();
// ergodic
for (int i = 0; i < argTypes.length; i++) {
// Determine whether it is the type to be found
if (paramType.isAssignableFrom(argTypes[i])) {
// Record the position of the corresponding type in the parameter list
if (index == null) {
index = i;
} else {
// There can only be one parameter of RowBounds and ResultHandler types, which cannot be repeated
throw new BindingException(method.getName() + " cannot have multiple " + paramType.getSimpleName() + " parameters");
}
}
}
return index;
}
4.3 execute
Finally, we need to take a look at the core method execute method in MapperMethod, which completes the database operation:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) { // Call the method corresponding to SqlSession according to the type of SQL statement
case INSERT: {
// The args [] array is processed by the ParamNameResolver to associate the argument passed in by the user with the specified parameter name
Object param = method.convertArgsToSqlCommandParam(args);
// sqlSession.insert(command.getName(), param) calls the insert method of SqlSession
// The rowCountResult method converts the result according to the return value type of the method recorded in the method field
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
// Method whose return value is null and ResultSet is processed by ResultHandler
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
// Method whose return value is a single object
Object param = method.convertArgsToSqlCommandParam(args);
// Execution entry of normal select statement > >
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
Some of the corresponding branch methods in this method are relatively simple. The core module has gone through the selectone method before, and others can be consulted by yourself.
4.4 core process series
First, let's see where the parser module plays a role in the specific operation of the system:
First, load the resolved location in the mapping file.
public void parse() {
// In general, two things are done, the registration of statements and the registration of interfaces
if (!configuration.isResourceLoaded(resource)) {
// 1. Specific addition, deletion, modification and query of label analysis.
// One label, one MappedStatement. > >
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
// 2. Bind the namespace (interface type) to the factory class and put it into a map.
// One namespace, one mapperproxyfactory > >
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
In bindMapperForNamespace, the Mapper interface will be registered and the addMapper method described above will be called.
Then we execute.
// 4. Operate the database through the API methods provided in SqlSession UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> list = mapper.selectUserList();
For the internal logic of these two lines of code, first look at the getMapper method:
@Override
public <T> T getMapper(Class<T> type) {
return configuration.getMapper(type, this);
}
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// Mapper related information registered in mapperRegistry called addMapper method when parsing mapping file
return mapperRegistry.getMapper(type, sqlSession);
}
Then get the corresponding MapperProxyFactory object from MapperRegistry.
/**
* Get the proxy object corresponding to Mapper interface
*/
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// Gets the MapperProxyFactory object corresponding to the Mapper interface
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
Then obtain the proxy object corresponding to the Mapper interface according to the MapperProxyFactory object.
/**
* Create a proxy object that implements the mapperInterface interface
*/
protected T newInstance(MapperProxy<T> mapperProxy) {
// 1: Class loader: 2: the interface implemented by the proxy class; 3: the trigger management class that implements InvocationHandler
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
Sequence diagram:
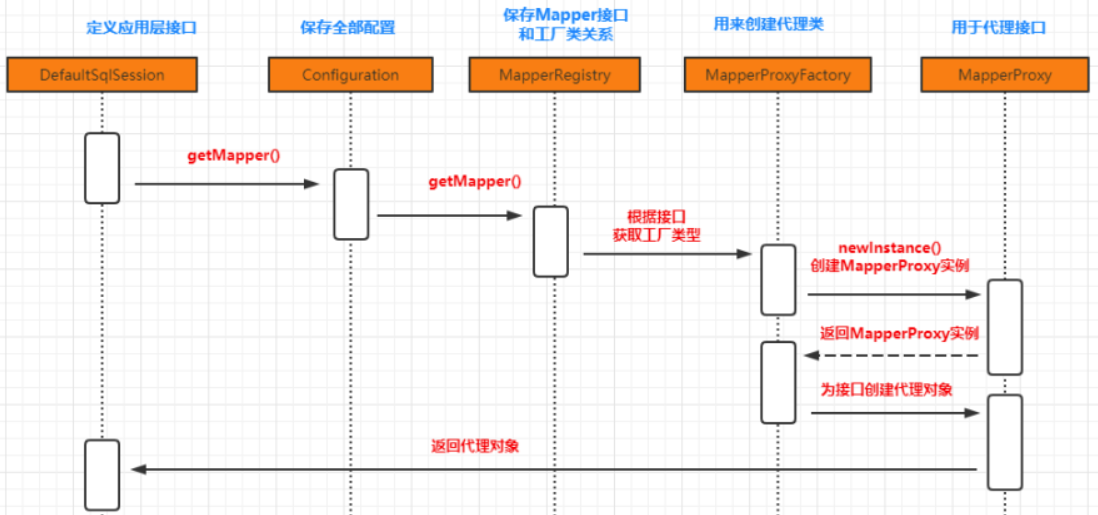
Then let's look at the execution order of the methods in the calling proxy object:
List<User> list = mapper.selectUserList();
It will enter the Invoker method of MapperProxy:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// toString hashCode equals getClass and other methods do not need to go to the SQL execution process
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// Improve the efficiency of obtaining mapperMethod by invoking mapperMethod invoke r (internal interface)
// The normal method will go to the invoke of PlainMethodInvoker (inner class)
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
Then enter the invoke method in PlainMethodInvoker:
@Override
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable {
// The real starting point for SQL execution
return mapperMethod.execute(sqlSession, args);
}
Then it will enter the execute method of MapperMethod:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) { // Call the method corresponding to SqlSession according to the type of SQL statement
case INSERT: {
// The args [] array is processed by the ParamNameResolver to associate the argument passed in by the user with the specified parameter name
Object param = method.convertArgsToSqlCommandParam(args);
// sqlSession.insert(command.getName(), param) calls the insert method of SqlSession
// The rowCountResult method converts the result according to the return value type of the method recorded in the method field
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
// Method whose return value is null and ResultSet is processed by ResultHandler
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
// Method whose return value is a single object
Object param = method.convertArgsToSqlCommandParam(args);
// Execution entry of normal select statement > >
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
Then, the corresponding method in SqlSession will be called according to the corresponding SQL type to perform the operation.
Cache module
As a powerful persistence layer framework, mybatis Cache is one of its essential functions. The Cache in mybatis is divided into level 1 Cache and level 2 Cache. But they are essentially the same. They are all implemented using the Cache interface. The Cache is located in the org.apache.ibatis.cache package.
By looking at the source code structure, we can find that the Cache actually uses the decorator mode to realize Cache processing. First of all, you need to review the relevant contents of decorator mode. Let's first look at the API of the basic class in Cache.
// Pancakes with eggs and sausages "Decorator mode( Decorator Pattern)It refers to attaching functions to objects without changing the original objects, providing a more flexible alternative than inheritance (extending the functions of the original objects). "

1. Cache interface
The Cache interface is the core interface in the Cache module. It defines the basic behavior of all caches. The definition of the Cache interface is as follows:
public interface Cache {
/**
* ID of the cache object
* @return The identifier of this cache
*/
String getId();
/**
* Add data to the cache. Generally, key is the cachekey and value is the query result
* @param key Can be any object but usually it is a {@link CacheKey}
* @param value The result of a select.
*/
void putObject(Object key, Object value);
/**
* Find the corresponding result object in the cache according to the specified key
* @param key The key
* @return The object stored in the cache.
*/
Object getObject(Object key);
/**
* As of 3.3.0 this method is only called during a rollback
* for any previous value that was missing in the cache.
* This lets any blocking cache to release the lock that
* may have previously put on the key.
* A blocking cache puts a lock when a value is null
* and releases it when the value is back again.
* This way other threads will wait for the value to be
* available instead of hitting the database.
* Delete the cached data corresponding to the key
*
* @param key The key
* @return Not used
*/
Object removeObject(Object key);
/**
* Clears this cache instance.
* wipe cache
*/
void clear();
/**
* Optional. This method is not called by the core.
* Number of caches.
* @return The number of elements stored in the cache (not its capacity).
*/
int getSize();
/**
* Optional. As of 3.2.6 this method is no longer called by the core.
* <p>
* Any locking needed by the cache must be provided internally by the cache provider.
* Get read / write lock
* @return A ReadWriteLock
*/
default ReadWriteLock getReadWriteLock() {
return null;
}
}
There are many implementation classes of Cache interface, but most of them are decorators. Only PerpetualCache provides the basic implementation of Cache interface.
2. PerpetualCache
Perpetual cache plays the role of ConcreteComponent in the cache module. Its implementation is relatively simple. The underlying layer uses HashMap to record cache items. The specific implementation is as follows:
public class PerpetualCache implements Cache {
private final String id; // Unique identification of the Cache object
// The Map object used to record the cache
private final Map<Object, Object> cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
// Only care about ID
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
// Only care about ID
return getId().hashCode();
}
}
Then we can take a look at the decorators provided under the cache.decorators package. They all implement the Cache interface. These decorators provide some additional functions on the basis of PerpetualCache, and realize some special requirements through multiple combinations.
3. BlockingCache
Through the name, we can see that it is a cache blocking synchronization, which ensures that only one thread goes to the cache to find the data corresponding to the specified key.
public class BlockingCache implements Cache {
private long timeout; // Blocking timeout
private final Cache delegate; // Decorated underlying Cache object
// Each key has a ReentrantLock object
private final ConcurrentHashMap<Object, ReentrantLock> locks;
public BlockingCache(Cache delegate) {
// Decorated Cache object
this.delegate = delegate;
this.locks = new ConcurrentHashMap<>();
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
@Override
public void putObject(Object key, Object value) {
try {
// Executes methods in the decorated Cache
delegate.putObject(key, value);
} finally {
// Release lock
releaseLock(key);
}
}
@Override
public Object getObject(Object key) {
acquireLock(key); // Acquire lock
Object value = delegate.getObject(key); // Get cached data
if (value != null) { // If there is data, release the lock, otherwise continue to hold the lock
releaseLock(key);
}
return value;
}
@Override
public Object removeObject(Object key) {
// despite of its name, this method is called only to release locks
releaseLock(key);
return null;
}
@Override
public void clear() {
delegate.clear();
}
private ReentrantLock getLockForKey(Object key) {
return locks.computeIfAbsent(key, k -> new ReentrantLock());
}
private void acquireLock(Object key) {
Lock lock = getLockForKey(key);
if (timeout > 0) {
try {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
lock.lock();
}
}
private void releaseLock(Object key) {
ReentrantLock lock = locks.get(key);
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
public long getTimeout() {
return timeout;
}
public void setTimeout(long timeout) {
this.timeout = timeout;
}
}
Through the source code, we can find that BlockingCache essentially implements the locking and unlocking operations through the ReentrantLock object before and after we operate the cached data. Other specific implementation classes can be consulted by yourself.
| Cache implementation class | describe | effect | Decoration conditions |
|---|---|---|---|
| Basic cache | Cache basic implementation class | The default is perpetual cache. You can also customize cache classes with basic functions, such as RedisCache and EhCache | nothing |
| LruCache | Caching of LRU policies | When the cache reaches the upper limit, delete the least recently used cache | Occurrence = "LRU" (default) |
| FifoCache | FIFO policy cache | When the cache reaches the upper limit, delete the first queued cache | Occurrence = "LRU" (default) |
| SoftCacheWeakCache | Cache with cleanup policy | The soft reference and weak reference of the JVM are used to implement the cache. When the JVM memory is insufficient, these caches will be automatically cleaned up based on SoftReference and WeakReference | eviction="SOFT"eviction="WEAK" |
| LoggingCache | Caching with logging | For example: output cache hit rate | basic |
| SynchronizedCache | Synchronous cache | Based on the synchronized keyword implementation, the concurrency problem is solved | basic |
| BlockingCache | Blocking cache | By locking in the get/put mode, only one thread operation cache is guaranteed, which is implemented based on Java reentry lock | blocking=true |
| SerializedCache | Serialized cache supported | After serializing the object, it is stored in the cache and deserialized when taken out | readOnly=false (default) |
| ScheduledCache | Scheduled cache | Before performing get/put/remove/getSize and other operations, judge whether the cache time exceeds the set maximum cache time (one hour by default). If so, empty the cache -- that is, empty the cache every other period of time | flushInterval is not empty |
| TransactionalCache | Transaction cache | Used in L2 cache, it can store multiple caches at a time and remove multiple caches | Maintain correspondence with Map in transactional cache manager |
4. Application of cache
4.1 initialization corresponding to cache
During Configuration initialization, corresponding aliases will be registered for our various Cache implementations:

When parsing the settings tag, the default values set are as follows:
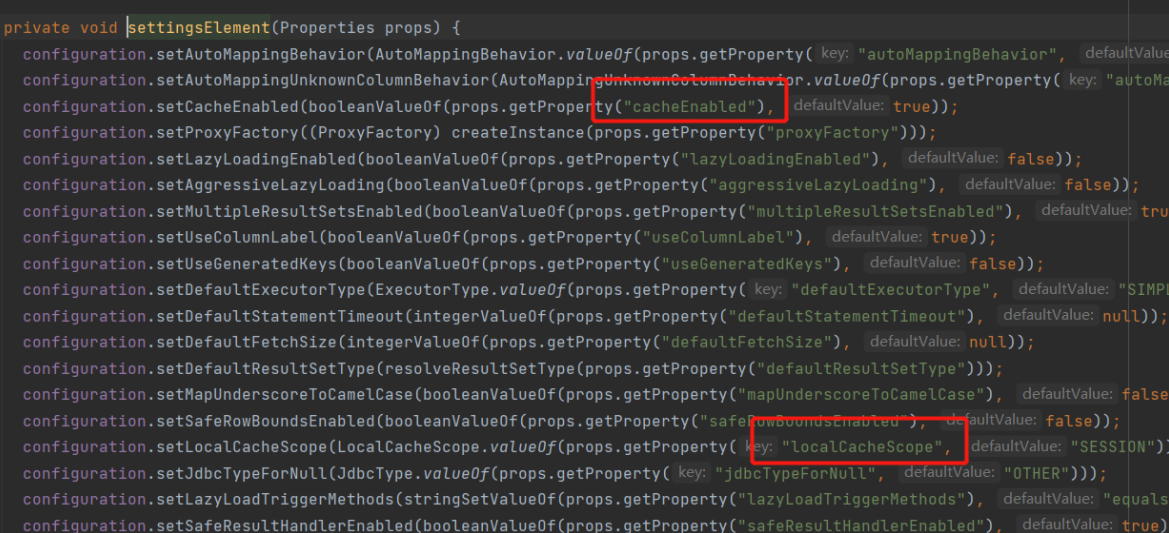
cacheEnabled defaults to true, and localCacheScope defaults to SESSION.
When parsing the mapping file, we will parse our relevant cache tags:
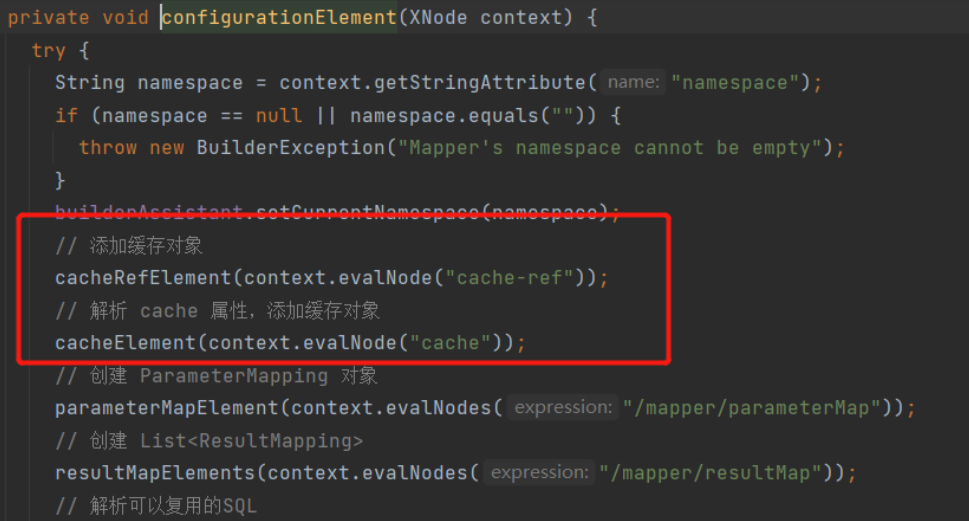
Then, after parsing the cache tag of the mapping file, the corresponding data will be added to the Configuration object
private void cacheElement(XNode context) {
// Only when the cache tag is not empty can it be resolved
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
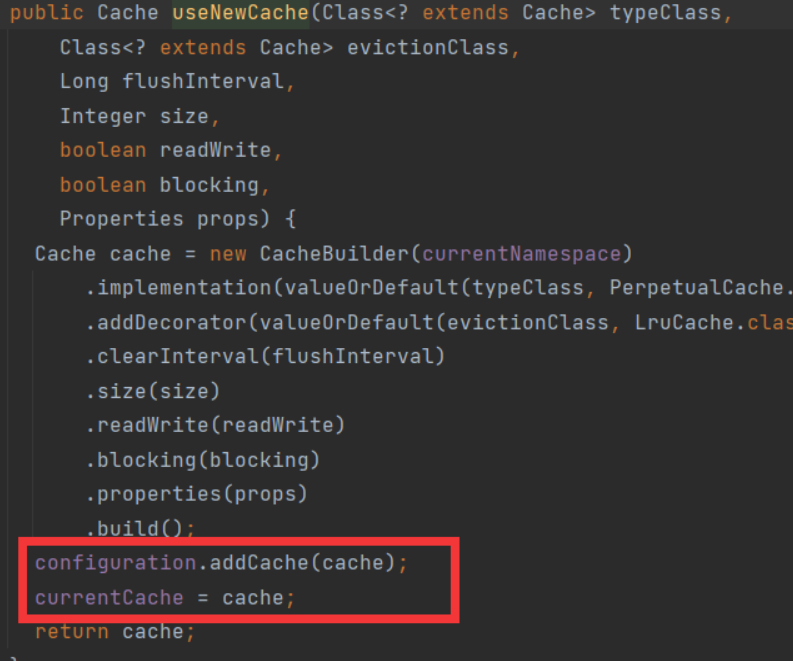
Then we can find that if the Cache tag is stored, the corresponding Cache object will be saved in the currentCache attribute. (in the steps of parsing the mapping file)

Further, the cache object is saved in the cache attribute of the MapperStatement object.
Then let's take a look at the operations done during openSession. There will be cache operations when creating the corresponding actuator.
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
// Default simpleexecution
executor = new SimpleExecutor(this, transaction);
}
// L2 cache switch. cacheEnabled in settings is true by default
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// The logic of the plug-in has been implanted. So far, all the four objects have been intercepted
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
That is, if cacheEnabled is true, the executor object will be decorated through cacheingexecution, and then the specific use of cache will be involved when executing SQL operations. This is divided into L1 cache and L2 cache, which we will introduce respectively.
4.2 L1 cache
The L1 cache is also called Local Cache. The L1 cache of MyBatis is cached at the session level. The first level cache of MyBatis is turned on by default and does not need any configuration (if you want to turn it off, set localCacheScope to state). There is logic to close the L1 cache in the query method of the BaseExecutor object.
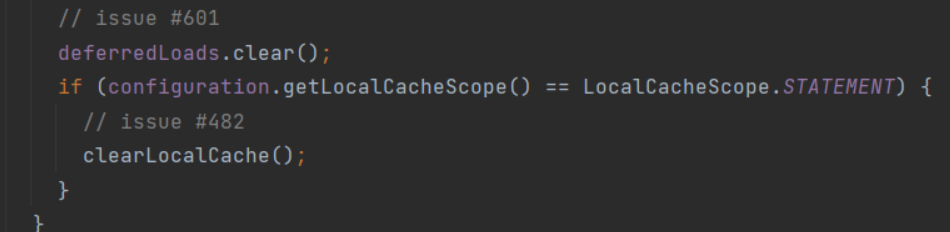
Then we need to consider where the next level 1 cache object is created. Because the level 1 cache is a Session level cache, it must be created within the Session range. In fact, the instantiation of the PerpetualCache is created in the construction method of BaseExecutor.
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
this.deferredLoads = new ConcurrentLinkedQueue<>();
this.localCache = new PerpetualCache("LocalCache");
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
this.wrapper = this;
}
The specific implementation of L1 cache is also implemented in the query method of BaseExecutor:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// ErrorContext of exception system
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// When flushCache="true", the L1 cache is emptied even for queries
clearLocalCache();
}
List<E> list;
try {
// Prevent recursive query duplicate processing cache
queryStack++;
// Query L1 cache
// Difference between ResultHandler and ResultSetHandler
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// Real query process
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
Verification of L1 cache:
Multiple same operations in the same Session:
@Test
public void test1() throws Exception {
// 1. Get configuration file
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
// 2. Load the parsing configuration file and get the SqlSessionFactory object
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
// 3. Obtain the SqlSession object according to the SqlSessionFactory object
SqlSession sqlSession = factory.openSession();
// 4. Operate the database through the API methods provided in SqlSession
List<User> list = sqlSession.selectList("com.demo.mapper.UserMapper.selectUserList");
// for (User user : list) {
// System.out.println(user);
// }
System.out.println(list.size());
// L1 cache test
System.out.println("---------");
list = sqlSession.selectList("com.demo.mapper.UserMapper.selectUserList");
System.out.println(list.size());
// 5. Close the session
sqlSession.close();
}
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@ef9296d] ==> Preparing: select * from t_user ==> Parameters: Object Factory .... create <== Columns: id, user_name, real_name, password, age, d_id <== Row: 1, zhangsan, Wang Wu, 111, 22, 1001 Object Factory .... create <== Row: 668, hibernate-1, Persistence layer framework, null, null, null Object Factory .... create <== Total: 2 2 --------- 2
You can see that the second query has not been operated by the database.
Same operation for multiple session s:
@Test
public void test1() throws Exception {
// 1. Get configuration file
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
// 2. Load the parsing configuration file and get the SqlSessionFactory object
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
// 3. Obtain the SqlSession object according to the SqlSessionFactory object
SqlSession sqlSession = factory.openSession();
// 4. Operate the database through the API methods provided in SqlSession
List<User> list = sqlSession.selectList("com.demo.mapper.UserMapper.selectUserList");
// for (User user : list) {
// System.out.println(user);
// }
sqlSession.close();
sqlSession = factory.openSession();
System.out.println(list.size());
// L1 cache test
System.out.println("---------");
list = sqlSession.selectList("com.demo.mapper.UserMapper.selectUserList");
System.out.println(list.size());
// 5. Close the session
sqlSession.close();
}
Through the output, we can find that the L1 cache does not work for the same operation in different sessions.
4.3 L2 cache
L2 cache is used to solve the problem that L1 cache cannot be shared across sessions. The scope is namespace level, which can be shared by multiple sqlsessions (as long as it is the same method in the same interface), life cycle and application synchronization.
For L2 cache settings, first of all, cacheEnabled in settings should be set to true. Of course, the default is true. This step determines whether to decorate the Executor object through cacheingexecution when creating the Executor object.
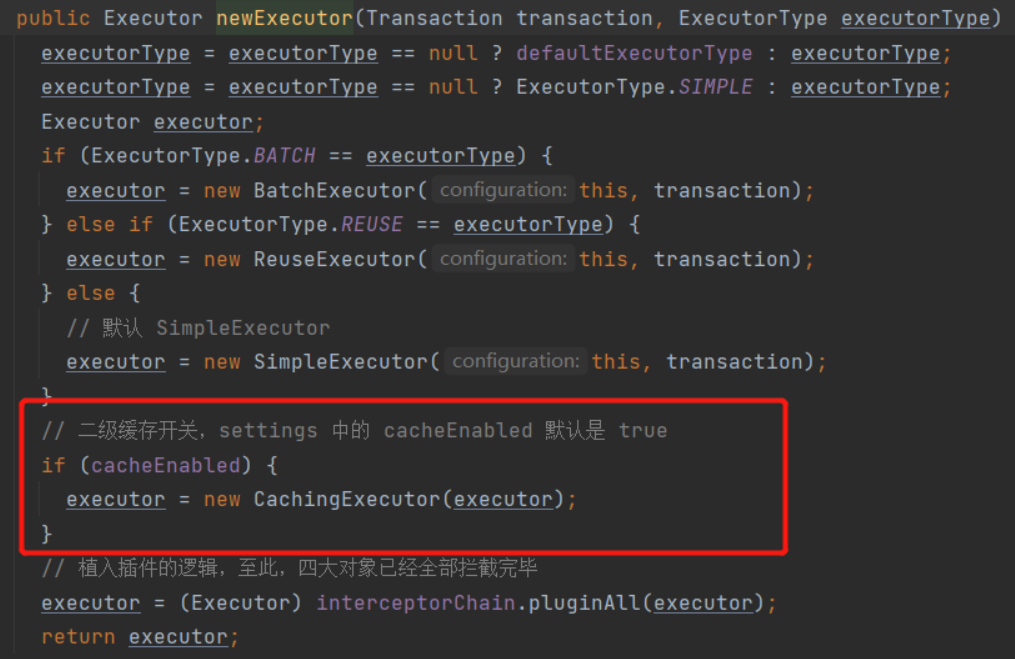
Does setting the cacheEnabled tag to true mean that the L2 cache must be available? Of course not. We also need to add a cache tag to the corresponding mapping file.
<!-- Declare this namespace Use L2 cache -->
<cache type="org.apache.ibatis.cache.impl.PerpetualCache"
size="1024" <!—The maximum number of cache objects is 1024 by default-->
eviction="LRU" <!—Recycling strategy-->
flushInterval="120000" <!—Auto refresh time ms,When not configured, only refresh on call-->
readOnly="false"/> <!—The default is false(Security), replace with true When reading and writing, the object must support serialization -->
Detailed explanation of cache attributes:
| attribute | meaning | Value |
|---|---|---|
| type | Cache implementation class | The Cache interface needs to be implemented. The default is perpetual Cache, and a third-party Cache can be used |
| size | Maximum number of caches | Default 1024 |
| eviction | Recycling strategy | LRU – least recently used: removes objects that have not been used for the longest time (default). FIFO – first in first out: remove objects in the order they enter the cache. SOFT – SOFT reference: removes objects based on garbage collector status and SOFT reference rules. WEAK – WEAK references: more actively remove objects based on garbage collector status and WEAK reference rules. |
| flushInterval | Periodically and automatically empty the cache interval | Automatic refresh time, unit: ms. if it is not configured, it can only be refreshed when calling |
| readOnly | Read only | true: read only cache; The same instance of the cache object is returned to all callers. Therefore, these objects cannot be modified. This provides important performance advantages. False: read / write cache; A copy of the cached object is returned (through serialization) and is not shared. This will be slower, but safe, so the default is false. When changed to false, the object must support serialization. |
| blocking | Enable blocking cache | By locking in the get/put mode, only one thread operation cache is guaranteed, which is implemented based on Java reentry lock |
Let's look at the embodiment of the cache tag in the source code. Create a cacheKey:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// Get SQL
BoundSql boundSql = ms.getBoundSql(parameterObject);
// Create CacheKey: what kind of SQL is the same SQL? > >
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
createCacheKey goes in to check:
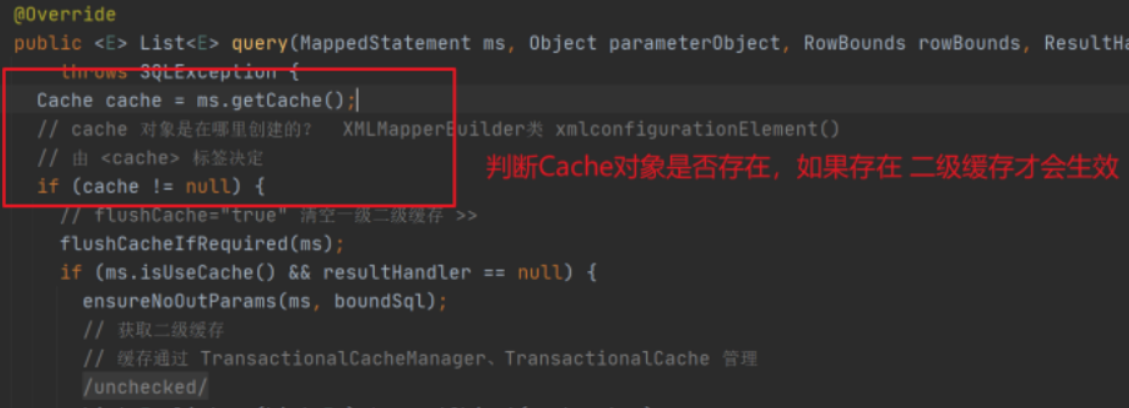

This corresponds to the cache tag parsing operation we saw earlier during cache initialization. So we need to enable L2 cache. Both conditions must be met.
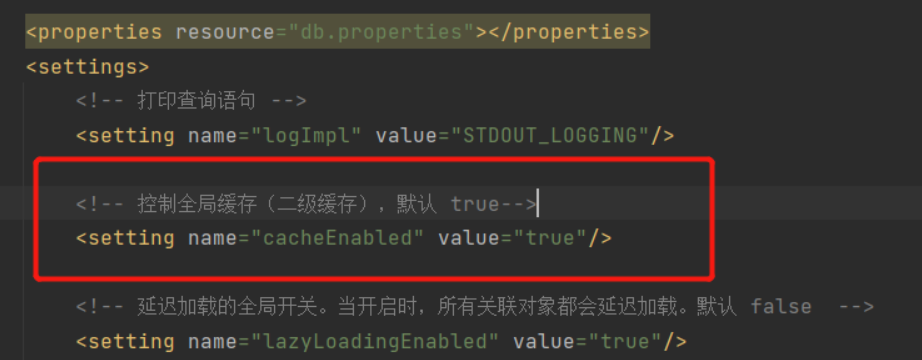

Such a setting means that the related query operations in the current mapping file will trigger the L2 cache, but what if we don't want to use the L2 cache for some individual methods? We can add a useCache=false in the tag to realize the setting without using L2 cache.
In addition, when we perform the corresponding DML operation, the corresponding L2 cache and L1 cache will be emptied in MyBatis.
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
// The tag of adding, deleting and modifying query has the attribute: flushCache="true" (the default value of the select statement is false)
// The L1 and L2 caches are cleaned up
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
When parsing the mapping file, the DML operation flushCacheRequired is true.
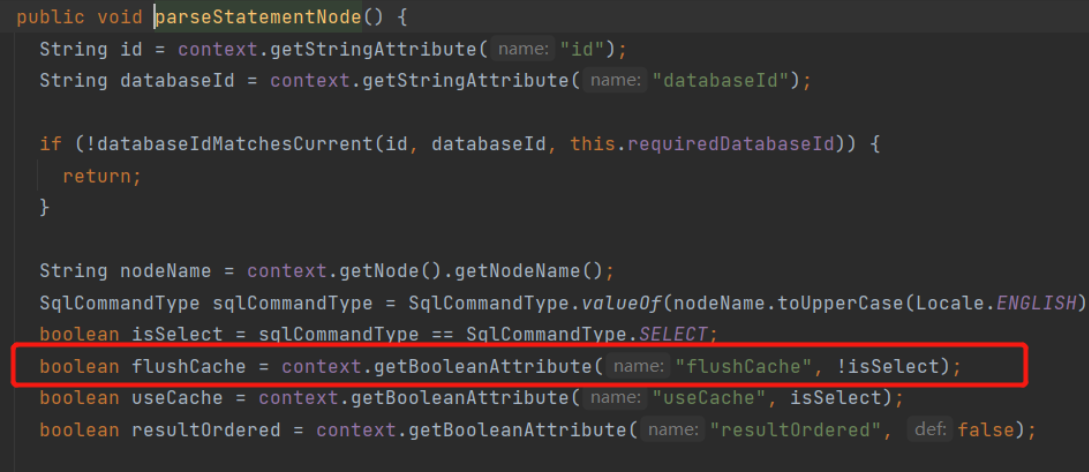
4.4 third party cache
In actual development, we rarely use the second-level cache provided by MyBatis. At this time, we will use the third-party cache tool Ehcache to obtain Redis for implementation. How do they implement it?
https://github.com/mybatis/redis-cache
Add dependency
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
Then add the configuration of Cache tag
<cache type="org.mybatis.caches.redis.RedisCache" eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
Then add the redis attribute file
host=127.0.0.1 port=6379 connectionTimeout=5000 soTimeout=5000 database=0
Test effect (test code or code when testing multiple session operations before)

The data is stored in Redis

Then, you can also analyze how the third-party Cache replaces the PerpetualCache, because the PerpetualCache is processed based on HashMap, and RedisCache stores cached data based on Redis.
Tips:

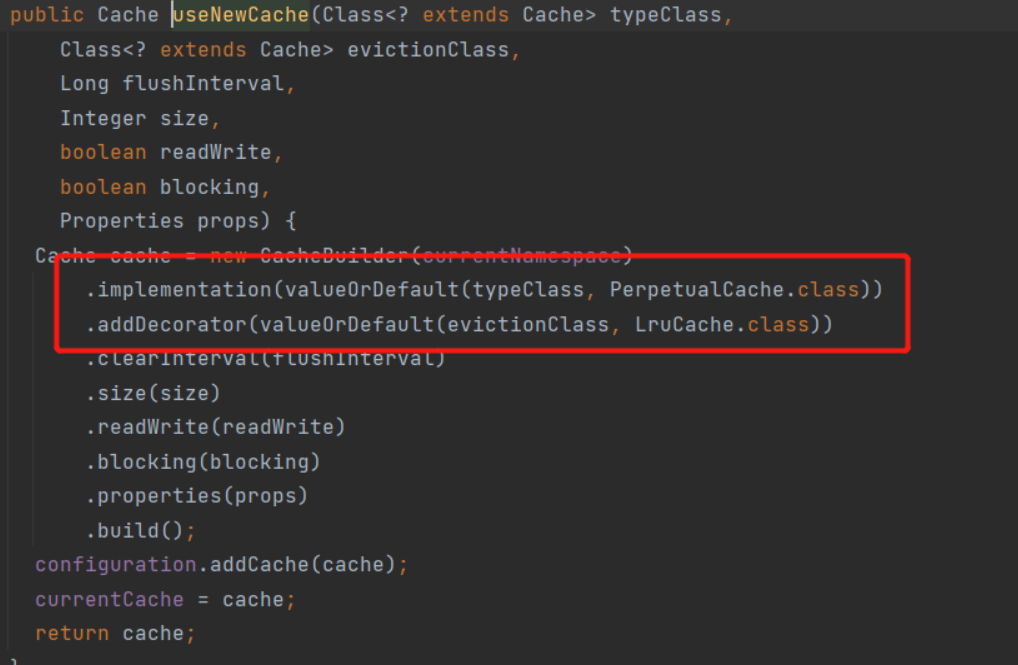
This is the cache module. Then you can systematically sort out the process of the core processing layer based on the basic support layer introduced above.