I. Threads
What is a thread?
The basic unit of CPU scheduling and allocation. When the current thread CPU time slice is exhausted, it will cause the next operating system scheduling, such as CPU, to execute when it is its turn.The operating system does not allocate memory for threads, but groups of threads can share the resources of the processes they belong to, such as files, databases, code snippets of processes, open file descriptors, current directories of processes, global variables, static variables, and so on.
What is the role of threads?
The unit running in the process runs threads (processes do not run, but occupy resources). If the threads do not run, the process is not necessary.Multiple threads running in the same process can improve event processing efficiency.For example, there are many things such as cooking, sweeping, cleaning tables, shopping, etc. If a person does it one by one (a main thread), it must be done one by one sequentially, which is obviously slow. How can I improve efficiency?We let multiple people (threads) do it, each person does different things, so that several things can happen at the same time, and efficiency is up.
- Concurrent execution: refers to how a process is executed when the number of processes executed simultaneously on the operating system is greater than the number of CPU s
- Parallel execution: refers to the way in which processes on the operating system execute simultaneously without preempting the CPU when the number of processes is not greater than the number of CPUs, i.e. one CPU per process
Code Explanation
We all know that if a singer just keeps singing and does not have any body movements, our experience will be poor. Here's the code: the singer sings and then dances (sequentially)
1. A simple demo
import time def sing(): """Singing for 3 seconds""" for i in range(3): print("----Singing----%d" % i) time.sleep(1) def dance(): """Dance for 3 seconds""" for i in range(3): print("----Dancing----%d" % i) time.sleep(1) def main(): sing() dance() if __name__ == "__main__": main()

Obviously, the experience is poor and singing and dancing are not performed together, which is not what we want.Here we use multithreading to implement two tasks together (that is, two functions together)
import time import threading def sing(): """Singing for 5 seconds""" for i in range(5): print("----Singing----%d" % i) time.sleep(1) def dance(): """Dance for 3 seconds""" for i in range(3): print("----Dancing----%d" % i) time.sleep(1) def main(): t1 = threading.Thread(target=sing) # Here the main thread creates the first normal object t2 = threading.Thread(target=dance) # Here the main thread creates the second normal object t1.start() # Thread Generation and Start Execution t2.start() while True: num = len(threading.enumerate()) if num == 1: # Exit when only the main thread is left in the thread queue print("Current number of threads:{}".format(num)) break print("Current number of threads:{}".format(num)) if __name__ == "__main__": main()

You can see that now singing and dancing are done together.Next, let's talk about the points of interest in the code.
- If the function executing by the create thread runs out, it means that the child thread is dead
- Normally, the main thread waits by default for all the sub-threads to finish executing, and then ends
- If the main thread dies prematurely, the sub-threads will also die
- A call to threading.Thread() simply creates a normal object, and there is no more than one thread in the thread queue threading.enumerate(), and no new thread will be added to the thread queue until start is called
2. Class implements multithreading
Custom classes for multithreading require inheriting the threading.Thread class and overriding the run method, which automatically calls the run method inside the class when the start method is called
import threading import time class MyThread(threading.Thread): # Inherit threading.Thread class and implement run method def run(self): for i in range(3): time.sleep(1) msg = "I'm " + self.name + "@" + str(i) # Name encapsulates the name of the current thread print(msg) def main(): t1 = MyThread() t2 = MyThread() t1.start() # Automatically invoke run method t2.start() # Automatically invoke run method if __name__ == "__main__": main()
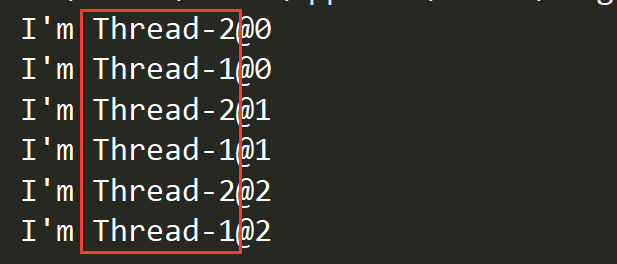
You can see that the thread name section appears alternately, indicating that we have implemented concurrent execution by calling the start method.Hmm?Not that calling the start method automatically calls the run method, but what if we call the run method directly?Just try it.
def main(): t1 = MyThread() t2 = MyThread() t1.run() # Manual call to run method t2.run() # Manual call to run method
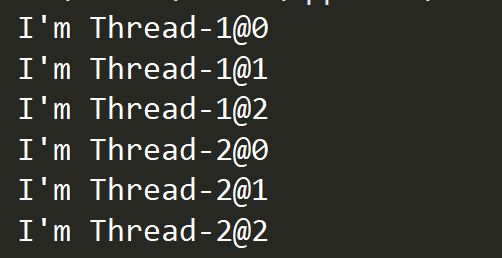
Obviously this becomes sequential execution, not concurrent execution. As mentioned earlier, new threads are added to the thread queue only after start is called, and the run method is called directly through the object. No new threads are generated in the thread queue (there is always only one main thread), so it becomes normal sequential execution.Do you understand now?
3. Multi-threaded sharing of part of the process's resources (global variables as an example)
We let a thread add 1 to the global variable, and then let a thread get the value of the global variable. If it gets the original value, it does not share the resource. If it gets the value after +1, it shares the resource.Delayed operation is used to ensure execution sequence.
import threading import time num = 100 # Put global variable + 1 def test1(): global num num += 1 print("-----in test1----num:%s" % num) # Get global variables and output def test2(): print("-----in test2----num:%s" % num) def main(): t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() time.sleep(1) t2.start() time.sleep(1) print("-----in main----num:%s" % num) if __name__ == '__main__': main()
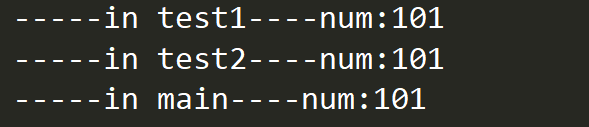
It is clear that both the main thread and the child thread share the resources of the process they belong to
4. Problems caused by multi-threaded sharing of resources
Multithreading allows you to handle multiple events with high efficiency. Is there any drawback?Yes, of course. Let's look at the following code
import threading import time num = 0 def test1(times): global num for i in range(times): num += 1 def test2(times): global num for i in range(times): num += 1 def main(): t1 = threading.Thread(target=test1, args=(1000000,)) t2 = threading.Thread(target=test2, args=(1000000,)) t1.start() t2.start() time.sleep(10) print("-----in main----num:%s" % num) if __name__ == '__main__': main()

Hmm? Two threads add 1000000 to the same global variable. The result should be 2000000.This is not what we want, because the CPU divides num+=1 into many steps, such as
- Get the value of num
- The value to be obtained + 1
- Store the calculated value and let num point to the changed storage space
It is possible that the execution process is as follows:
Initially num=0, when a thread A gets a value of 0, plus 1, which is very unfortunate, the time slice is exhausted, but thread A gives up the CPU to let another thread execute.Thread B gets a value of 0 in the first step, adds 1, and saves, and num becomes 1.The time slice is up, it is thread A's turn to execute, thread A executes from step 3, saves the result of calculation 1, and changes the value of num to 1.So far, both threads have done a plus 1 operation, and the result is equal to 1.
The following resolves this resource conflict issue.
5. Mutex Lock Resolves Resource Conflicts
The first thing to know is that multithreading destroys the atomicity of events (an event either does not execute or finishes execution).To keep events atomic, we need to have a mutex.When a thread is executing an event, it must get the lock, or it will wait until another thread releases the lock, and the lock will be successfully locked to execute the corresponding event.As mentioned above, num += 1 is divided into many steps. We wrap up the event with the lock operation acquire() and the unlock operation release() to ensure that all steps of the event can be performed.
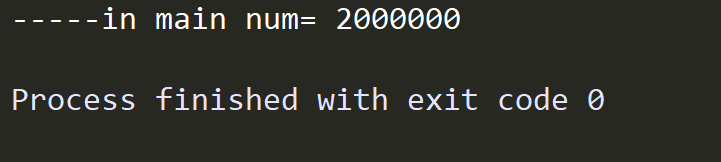
import threading import time # Create Mutex mutex = threading.Lock() num = 0 def test1(times): global num for i in range(times): mutex.acquire() # Lock, if there was no lock before, lock successfully at this time, otherwise block until lock is unlocked, mutex lock can be used again num += 1 mutex.release() def test2(times): global num for i in range(times): mutex.acquire() # Lock, if there was no lock before, lock successfully at this time, otherwise block until lock is unlocked num += 1 mutex.release() def main(): t1 = threading.Thread(target=test1, args=(1000000,)) t2 = threading.Thread(target=test2, args=(1000000,)) t1.start() t2.start() time.sleep(2) # Wait for two sub-threads to finish executing print("-----in main num=", num) if __name__ == "__main__": main()
6. Problems caused by locking: Deadlock
As we mentioned above, unlocking can solve the problem of sharing resource conflicts. What new problems will lock cause?Let's look at the code below
import time import threading mutex_1 = threading.Lock() mutex_2 = threading.Lock() class MyThread1(threading.Thread): def run(self): mutex_1.acquire() print(self.name + "-------mutex_1 Occupied-------") time.sleep(1) print(self.name + "-------wait for mutex_2-------") mutex_2.acquire() # At this point mutex_2 is occupied and blocked until mutex_2 is released mutex_1.release() mutex_2.release() class MyThread2(threading.Thread): def run(self): mutex_2.acquire() print(self.name + "-------mutex_2 Occupied-------") time.sleep(1) print(self.name + "-------wait for mutex_1-------") mutex_1.acquire() # At this point mutex_1 is occupied and blocked until mutex_1 is released mutex_1.release() mutex_2.release() def main(): t1 = MyThread1() t2 = MyThread2() t1.start() t2.start() if __name__ == '__main__': main()
Run result: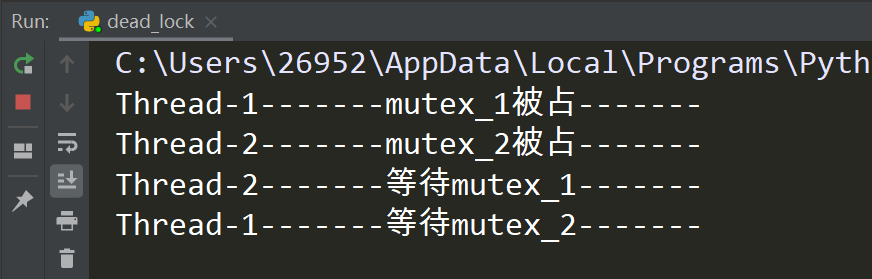
The result was embarrassing and the program stuck.The simple reason is that mutex_1 is occupied by Thread-1 and mutex_2 is occupied by Thread-2. To continue executing the program, they need to acquire the lock occupied by the other party, which is blocked all the time because they are waiting for the lock to be released.
The solution is also simple, just set a timeout.
2. Process
1. What is a process
- Process = executed program + allocated resources.For example, in windows, an EXE file is a program. After double-clicking exe, the program executes. After the operating system allocates memory space, CPU, IO and other resources to the program, there is an additional process on the operating system.
- A process is a unit of resource allocation, such as QQ running as a process. The resources allocated are camera, cursor, speaker, keyboard and so on.QQ multi-open is a multi-process
- Method area in a process, which stores code snippets in a process, is shared by threads
- A process is not an executable entity, it is an entity that consumes system resources, but a process has at least one main thread to execute the program
2. Do not share resources among multiple processes (global variables as an example)
Let process 1 operate on global variables, and process 2 operate on global variables, get the results of the operations, and print the id
import multiprocessing import time g_num = [1] def test1(num): for i in range(num): g_num.append(2) print("-----in test1---g_num=", g_num) print("-----in test1---id(g_num) =", id(g_num)) def test2(num): for i in range(num): g_num.append(3) print("-----in test2---g_num=", g_num) print("-----in test2---id(g_num) =", id(g_num)) def main(): # Process is multitasking and resource intensive p1 = multiprocessing.Process(target=test1, args=(1,)) p2 = multiprocessing.Process(target=test2, args=(1,)) p1.start() # Main Process Create Subprocess time.sleep(2) p2.start() print("-----in main---g_num=", g_num) print("-----in main---id(g_num) =", id(g_num)) if __name__ == "__main__": print("--------id(g_num) =", id(g_num)) main()
Run result: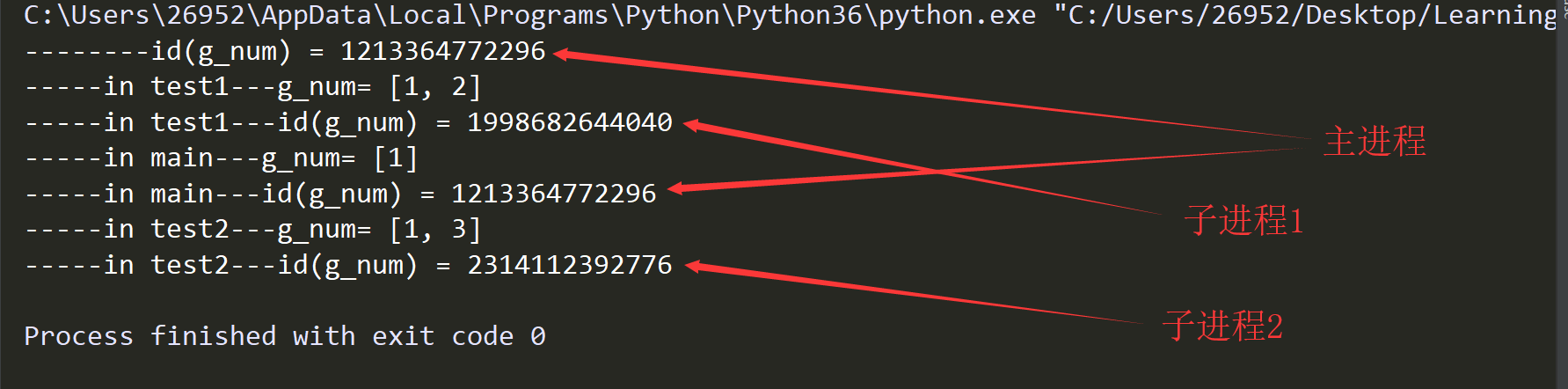
By printing the id, we can see that all the child processes and the parent process use different g_num addresses, which means that after the child process is created, the child process copies the parent process's resources and executes the code. The resources are not shared between processes.
5. Interprocess Communication
Inter-process communication can be done in many ways by having one process store data in an intermediate area and then another process fetch it.For example:
- socket: stores data to the Internet through ip and port, and another process fetches data at the specified port
- File: A process writes data to a file, and a process reads data from a file
- Queue Queue: A process places data in a queue and a process retrieves data from the queue
Here we use Queue queues for interprocess communication
The main functions used are:
1. q = multiprocessing.Queue() # Create Queue
2. q.put() # Put data in and get blocked when the queue is full
3. q.put_nowait() # Put in data to get an exception when the queue is full
4. q.get() # Get data, get clogged when queue is empty
5. q.get_nowait() # Get data, get queue empty exception
6. q.full() # Determine if the queue is full
7. q.empty() # Determine if the queue is empty
import multiprocessing import time def put_data(queue): data = [11, 22, 33, 44] for temp in data: queue.put(temp) print("----Store data to queue complete----") def get_data(queue): data_list = list() while True: data = queue.get() data_list.append(data) if queue.empty(): break print("---Get data from queue complete---") print(data_list) def main(): # Create a Queue q = multiprocessing.Queue() # Create multiple processes and pass a reference to Queue as an argument to them p1 = multiprocessing.Process(target=put_data, args=(q,)) p2 = multiprocessing.Process(target=get_data, args=(q,)) p1.start() time.sleep(1) p2.start() if __name__ == '__main__': main()
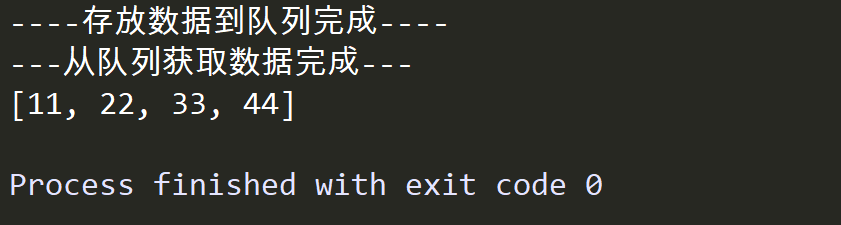
4. Process Pool
Why use process pools?
If you have a large number of tasks that need to be accomplished by multiple processes, you may need to create and delete processes frequently, which will result in more resource consumption for your computer.So we prepare a process pool to put an appropriate number of processes into it. When events need to be handled, we can use the process in the process pool to handle them. After processing is complete, we do not destroy the process, but reuse the process to handle other events.
Usage method:
- Create a process pool and place an appropriate number of processes
- Add an event to the waiting queue of the process pool, where the process in the process pool begins processing the event
- Close process pool
- Recycle process pool
Create process pool
pool = Pool()
Add tasks to the process pool waiting queue and carry parameters
pool.apply_async( function,(args,) )
When the process pool is closed, the pool no longer receives new events
pool.close()
Join blocked the main process.In a process pool, the main process does not wait for the child process to finish executing and needs to be blocked manually.If there is no join, the main process may end prematurely and all child processes will die
pool.join()
from multiprocessing import Pool import os, time, random def worker(msg): t_start = time.time() print("%s The process number is%d" % (msg, os.getpid())) time.sleep(random.random()*2) t_stop = time.time() print(msg, "Completed execution of event #, time consuming%0.2f second" % (t_stop-t_start)) def main(): pool = Pool(2) # Define a process pool with a maximum capacity of 2 for i in range(5): pool.apply_async(worker, (i,)) print("-----start----") pool.close() pool.join() print("-----end-----") if __name__ == '__main__': main()
Run result: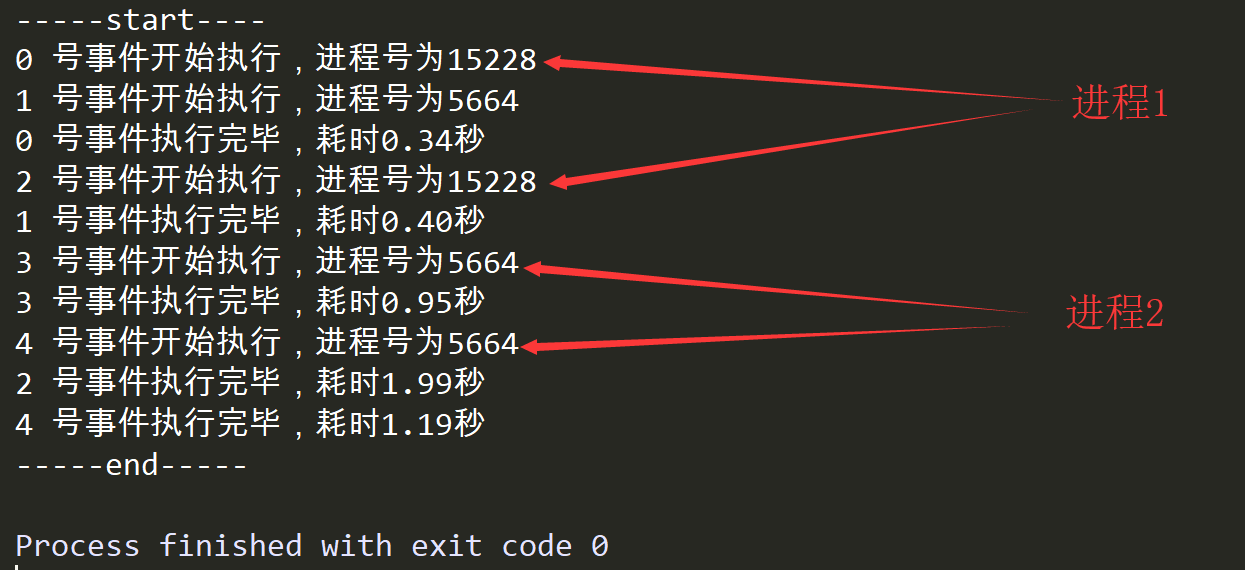
You can see that only two of the five events are executing alternately
3. Analysis and Comparison of Processes and Threads
The picture below is still very graphic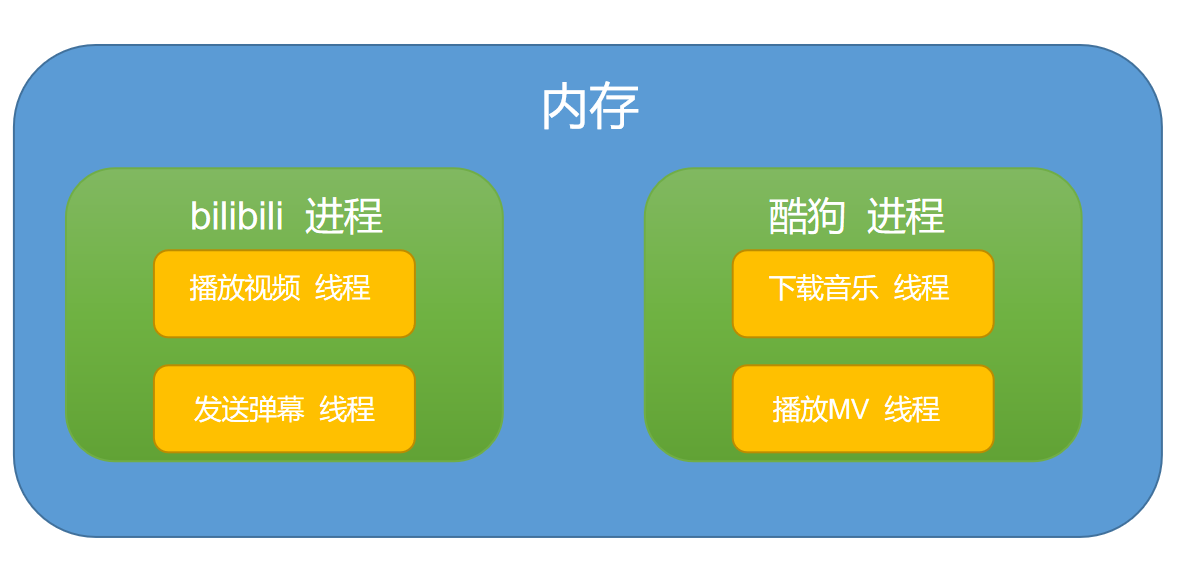
Compare:
- Essential: The process is the basic unit of operating system resource allocation, and the thread is the basic unit of task scheduling and execution.A process is just a unit of resource allocation. Threads use these resources to do things. A process has at least one main thread to do things.
- Resource sharing: Resources are independent and not shared between processes.Thread groups can share the resources of the process they belong to.
- Memory allocation: When the system is running, it allocates different memory space for each process and establishes a data table to maintain code, stack, and data segments. Except for the CPU, the system does not allocate memory for threads, which use resources from the process to which they belong.
- Communication: Processes communicate through sockets, files, message queues, and so on, while threads communicate by sharing data such as global variables, static variables, and so on.
- Robustness: Resources between each process are independent and do not affect other processes when one process crashes; threads of the same process share the resources of this process, and threads crash when this process crashes.Threads are prone to problems caused by sharing and resource competition, such as deadlocks
-
Overhead: Each process has its own code and data space, and switching between processes has a greater overhead; threads can be seen as lightweight processes, sharing code and data space with the same type of thread, each thread has its own running program counters and stacks, and switching between threads costs less
Selection of processes and threads:
Choice:
- Destroyed priority threads need to be created frequently.Because creating and destroying a process is expensive, resources need to be allocated continuously; frequent calls by threads only change the execution of the CPU
- Threads switch quickly and require a lot of computation. Threads are used when switching frequently
- Time-consuming operations use threads to improve application responsiveness
- Threads use CPU s more efficiently, processes with multiple machine distributions, and threads with multiple cores
- Cross-machine migration required, process preference
- When more stability and security are needed, priority should be given to process-
- Threads are preferred when speed is required
- Threads are preferred when parallelism is high
Referencehttps://www.javanav.com/interview/c1c5c5964574489c8d010c3e1a6f3362.html

