Preface
One of the most common ways in anti crawler is to determine the frequency of your requests. If you send a large number of requests in a short period of time, whether you are a person or not, first seal your account or IP for a period of time. At this time, in order to achieve the goal of their own crawler, we need to use proxy IP to disguise themselves. Next, we use multithreading to crawl the proxy IP and verify it.
Analysis
The source of this free proxy ip is Free agent IP , see the figure below:
Source code analysis: from the figure below, I choose to extract directly with xpath. Compared with beautiful soup, xpath is not only fast but also brief, with less code.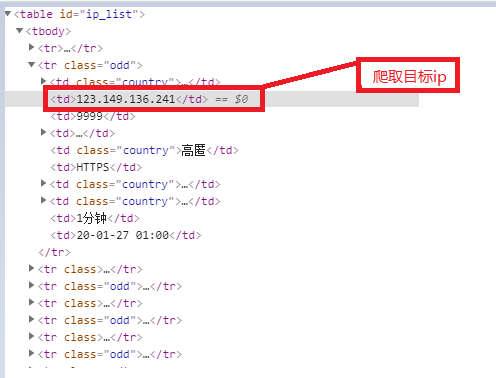
Code
Grab Code:
def get_info(Queue,flag): while Queue: url=Queue.get() txt=requests.get(url,headers=headers).text html=etree.HTML(txt) ip=html.xpath('//tr[@class=""]/td[2]/text()') for i in ip: Queue3.put([i,flag]) yz(Queue3)
Verification Code:
def yz(Queue): while Queue: cc=Queue.get() ip,flag=cc[0],cc[1] try: proxies={flag:ip} response=requests.get('https://www.baidu.com',proxies=proxies,timeout=2) if flag=='http' else requests.get('http://www.baidu.com',proxies=proxies,timeout=2) if response.status_code ==200: print(flag,ip,'yes') else: print(flag,ip,'no') except Exception as e: print(e)
Full code:
import requests from lxml import etree import queue import threading Queue1=queue.Queue(23) Queue2=queue.Queue(18) Queue3=queue.Queue(10000) for i in range(1,10): Queue1.put("https://www.xicidaili.com/wt/%d"%i) #Put the ip proxy web page into the queue, which is convenient to use multithreading in the future for i in range(1,10): Queue2.put("https://www.xicidaili.com/wn/%d"%i) headers={'User-Agent': 'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',} def yz(Queue): while Queue: cc=Queue.get() ip,flag=cc[0],cc[1] try: proxies={flag:ip} response=requests.get('https://www.baidu.com',proxies=proxies,timeout=2) if flag=='http' else requests.get('http://www.baidu.com',proxies=proxies,timeout=2) if response.status_code ==200: print(flag,ip,'yes') else: print(flag,ip,'no') except Exception as e: print(e) def get_info(Queue,flag): while Queue: url=Queue.get() txt=requests.get(url,headers=headers).text html=etree.HTML(txt) ip=html.xpath('//tr[@class=""]/td[2]/text()') for i in ip: Queue3.put([i,flag]) yz(Queue3) if __name__ == '__main__': for i in range(3): th=threading.Thread(target=get_info,args=[Queue1,'http']) th.start() for i in range(3): td=threading.Thread(target=get_info,args=[Queue2,'https']) td.start()
Effect screenshots
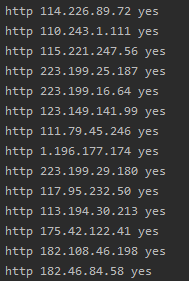
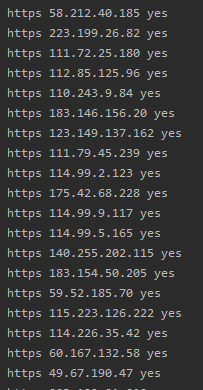
Reflection and summary
- The purpose of reptiles is to crawl useful information. Do not crawl unnecessary information, which can save time and improve efficiency.
- When writing a crawler, you should consider the common anti crawler strategy, so that you can save the later change time due to the anti crawler.
- Control desire, analyze website. There are tens of thousands of ip agents on this website, all of which are obtained. Obviously, I have made this mistake. Careful analysis of the website is because I found that the ip verification time behind is 2016. As for me, I should choose the latest one. It's not to doubt it's useless, it's just unnecessary.
- Get the agent, in addition to this one can also buy ip, but the Internet said that the stability of the purchased ip is not good. Free ip can sometimes fail. In addition, the api is used to obtain ip automatically, but it also has defects. The website corresponding to the api used is introduced.

