The previous article introduced the past and present of quickdraw:
However, in the process of generation, the cpu utilization is very low, and it is difficult to use it on a large scale. For example, it took seven days and seven nights to generate 10k image s in a single category, let alone use all hundreds of classes. It is necessary to fundamentally solve the problem of efficiency! This article from simple to deep, step by step, hand-in-hand to take you to completely solve this problem. The same solution can be reused in other deep learning tasks.
catalogue
Multithreading - the cost of creating / destroying is huge, and the gain is not worth the loss
Thread pool -- pool technology solves the overhead of thread creation / destruction
Why is CPU utilization still so low?
Python multithreading caused by GIL global interpreter lock is like a dummy
Multi process parallel computing
baseline task
In the previous article, a class was encapsulated and reused directly.
import cv2
import os
from PIL import Image
import matplotlib
from matplotlib.pyplot import imshow
import matplotlib.pyplot as plt
# from sketch_processing import draw_three
import numpy as np
import random
class DrawSketch(object):
def __init__(self):
pass
def scale_sketch(self, sketch, size=(448, 448)):
[_, _, h, w] = self.canvas_size_google(sketch)
if h >= w:
sketch_normalize = sketch / np.array([[h, h, 1]], dtype=np.float)
else:
sketch_normalize = sketch / np.array([[w, w, 1]], dtype=np.float)
sketch_rescale = sketch_normalize * np.array([[size[0], size[1], 1]], dtype=np.float)
return sketch_rescale.astype("int16")
def canvas_size_google(self, sketch):
"""
:param sketch: google sketch, quickDraw
:return: int list,[x, y, h, w]
"""
# get canvas size
vertical_sum = np.cumsum(sketch[1:], axis=0)
xmin, ymin, _ = np.min(vertical_sum, axis=0)
xmax, ymax, _ = np.max(vertical_sum, axis=0)
w = xmax - xmin
h = ymax - ymin
start_x = -xmin - sketch[0][0]
start_y = -ymin - sketch[0][1]
# sketch[0] = sketch[0] - sketch[0]
return [int(start_x), int(start_y), int(h), int(w)]
def draw_three(self, sketch, random_color=False, show=False, img_size=512):
"""
:param sketches: google quickDraw, (n, 3)
:param thickness: pass
:return: None
"""
# print("three ")
# print(sketch)
# print("-" * 70)
thickness = int(img_size * 0.025)
sketch = self.scale_sketch(sketch, (img_size, img_size)) # scale the sketch.
[start_x, start_y, h, w] = self.canvas_size_google(sketch=sketch)
start_x += thickness + 1
start_y += thickness + 1
canvas = np.ones((max(h, w) + 3 * (thickness + 1), max(h, w) + 3 * (thickness + 1), 3), dtype='uint8') * 255
if random_color:
color = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
else:
color = (0, 0, 0)
pen_now = np.array([start_x, start_y])
first_zero = False
for stroke in sketch:
delta_x_y = stroke[0:0 + 2]
state = stroke[2:]
if first_zero:
pen_now += delta_x_y
first_zero = False
continue
cv2.line(canvas, tuple(pen_now), tuple(pen_now + delta_x_y), color, thickness=thickness)
if int(state) == 1: # next stroke
first_zero = True
if random_color:
color = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
else:
color = (0, 0, 0)
pen_now += delta_x_y
if show:
key = cv2.waitKeyEx()
if key == 27: # esc
cv2.destroyAllWindows()
exit(0)
return cv2.resize(canvas, (img_size, img_size))
class SketchData(object):
def __init__(self, dataPath, model="train"):
self.dataPath = dataPath
self.model = model
# Load data
def load(self):
dataset_origin_list = []
category_list = self.getCategory()
for each_name in category_list:
# npz_test = np.load(f"./{self.dataPath}/{each_name}", encoding="latin1", allow_pickle=True)["test"]
npz_tmp = np.load(f"./{self.dataPath}/{each_name}", encoding="latin1", allow_pickle=True)[self.model]
print(f"dataset: {each_name} added.")
dataset_origin_list.append(npz_tmp)
return dataset_origin_list
# Get category list
def getCategory(self):
category_list = os.listdir(self.dataPath)
return category_list
if __name__ == '__main__':
sketchdata = SketchData(dataPath='./dataset_npz')
category_list = sketchdata.getCategory()
dataset_origin_list = sketchdata.load()
# Mapping
for category_index in range(len(category_list)):
sample_category_name = category_list[category_index]
print(sample_category_name)
save_name = sample_category_name.replace(".npz", "")
# create folder
folder = os.path.exists(f"./save_img/{save_name}/")
if not folder:
os.makedirs(f"./save_img/{save_name}/")
print(f"./save_img/{save_name}/ is new mkdir!")
drawsketch = DrawSketch()
# Mapping
for image_index in range(10):
# sample_sketch = dataset_origin_list[sample_category_name.index(sample_category_name)][index]
sample_sketch = dataset_origin_list[category_list.index(sample_category_name)][image_index]
sketch_cv = drawsketch.draw_three(sample_sketch, True)
plt.xticks([]) # Remove the x-axis
plt.yticks([]) # Remove the y-axis
plt.axis('off') # Remove the coordinate axis
plt.imshow(sketch_cv)
plt.savefig(f"./save_img/{save_name}/{image_index}.jpg")
print(f"{save_name}/{image_index}.jpg is saved!")Multithreading - the cost of creating / destroying is huge, and the gain is not worth the loss
this is a bad idea.
This may be a good method when several threads are needed, but we hope to create dozens / hundreds of crazy run s, which certainly won't work.
Thread pool -- pool technology solves the overhead of thread creation / destruction
In order to solve the overhead of thread creation / destruction, we introduce thread pool technology. Compared with the pooling technology in C + +, Python interpretive language has high development efficiency and is written quickly.
But note that we need a global lock to lock the queue to prevent deadlock when fetching. The general framework is as follows:
#!/usr/bin/python3
# Multi thread generation of sketch image
from concurrent.futures import ThreadPoolExecutor
from queue import Queue
import threading
# Global queue locking
indexQueue = Queue(maxsize=10000)
queueLock = threading.Lock()
for i in range(0, 10000):
indexQueue.put(i)
def worker():
# Lock the sketch subscript that is not drawn in the queue every time
queueLock.acquire()
if not indexQueue.empty():
index = indexQueue.get()
else:
print("queue is empty")
queueLock.release()
print(f"thread write {index} image!")
# print(f'thread is over')
if __name__ == '__main__':
# Open a thread pool
with ThreadPoolExecutor(max_workers=1000) as t:
while not indexQueue.empty():
t.submit(worker)
exit()
The complete code is as follows:
#!/usr/bin/python3
# Multi thread generation of sketch image
from concurrent.futures import ThreadPoolExecutor
from queue import Queue
import threading
import cv2
import os
import matplotlib.pyplot as plt
import numpy as np
import random
import asyncio
class DrawSketch(object):
def __init__(self):
pass
def scale_sketch(self, sketch, size=(448, 448)):
[_, _, h, w] = self.canvas_size_google(sketch)
if h >= w:
sketch_normalize = sketch / np.array([[h, h, 1]], dtype=np.float)
else:
sketch_normalize = sketch / np.array([[w, w, 1]], dtype=np.float)
sketch_rescale = sketch_normalize * np.array([[size[0], size[1], 1]], dtype=np.float)
return sketch_rescale.astype("int16")
def canvas_size_google(self, sketch):
"""
:param sketch: google sketch, quickDraw
:return: int list,[x, y, h, w]
"""
# get canvas size
vertical_sum = np.cumsum(sketch[1:], axis=0)
xmin, ymin, _ = np.min(vertical_sum, axis=0)
xmax, ymax, _ = np.max(vertical_sum, axis=0)
w = xmax - xmin
h = ymax - ymin
start_x = -xmin - sketch[0][0]
start_y = -ymin - sketch[0][1]
# sketch[0] = sketch[0] - sketch[0]
return [int(start_x), int(start_y), int(h), int(w)]
def draw_three(self, sketch, random_color=False, show=False, img_size=512):
"""
:param sketches: google quickDraw, (n, 3)
:param thickness: pass
:return: None
"""
thickness = int(img_size * 0.025)
sketch = self.scale_sketch(sketch, (img_size, img_size)) # scale the sketch.
[start_x, start_y, h, w] = self.canvas_size_google(sketch=sketch)
start_x += thickness + 1
start_y += thickness + 1
canvas = np.ones((max(h, w) + 3 * (thickness + 1), max(h, w) + 3 * (thickness + 1), 3), dtype='uint8') * 255
if random_color:
color = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
else:
color = (0, 0, 0)
pen_now = np.array([start_x, start_y])
first_zero = False
for stroke in sketch:
delta_x_y = stroke[0:0 + 2]
state = stroke[2:]
if first_zero:
pen_now += delta_x_y
first_zero = False
continue
cv2.line(canvas, tuple(pen_now), tuple(pen_now + delta_x_y), color, thickness=thickness)
if int(state) == 1: # next stroke
first_zero = True
if random_color:
color = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
else:
color = (0, 0, 0)
pen_now += delta_x_y
if show:
key = cv2.waitKeyEx()
if key == 27: # esc
cv2.destroyAllWindows()
exit(0)
return cv2.resize(canvas, (img_size, img_size))
class SketchData(object):
def __init__(self, dataPath, model="train"):
self.dataPath = dataPath
self.model = model
# Load data
def load(self):
dataset_origin_list = []
category_list = self.getCategory()
for each_name in category_list:
# npz_test = np.load(f"./{self.dataPath}/{each_name}", encoding="latin1", allow_pickle=True)["test"]
npz_tmp = np.load(f"./{self.dataPath}/{each_name}", encoding="latin1", allow_pickle=True)[self.model]
print(f"dataset: {each_name} added.")
dataset_origin_list.append(npz_tmp)
return dataset_origin_list
# Get category list
def getCategory(self):
category_list = os.listdir(self.dataPath)
return category_list
# Global queue locking
MAXQUEUESIZE = 10000
MAXTHREADSIZE = 100
indexQueue = Queue(maxsize=MAXQUEUESIZE)
queueLock = threading.Lock()
for i in range(0, MAXQUEUESIZE):
indexQueue.put(i)
def worker():
# Lock the sketch subscript that is not drawn in the queue every time
if not queueLock.acquire(blocking=False):
print(f"queueLock acquire is timeout!")
return
if not indexQueue.empty():
try:
image_index = indexQueue.get_nowait()
except:
# timeout return and release
print(f"queue get is timeout!")
queueLock.release()
return
else:
print("queue is empty")
queueLock.release()
sample_sketch = dataset_origin_list[category_list.index(sample_category_name)][image_index]
sketch_cv = drawsketch.draw_three(sample_sketch)
plt.xticks([]) # Remove the x-axis
plt.yticks([]) # Remove the y-axis
plt.axis('off') # Remove the coordinate axis
plt.imshow(sketch_cv)
plt.savefig(f"./sketch_image/{save_name}/{save_name}_{image_index}.png")
print(f"{save_name}/{save_name}_{image_index}.png is saved!")
if __name__ == '__main__':
sketchdata = SketchData(dataPath='./sketch_dataset_airplane')
category_list = sketchdata.getCategory()
dataset_origin_list = sketchdata.load()
# Mapping
for category_index in range(len(category_list)):
sample_category_name = category_list[category_index]
print(sample_category_name)
save_name = sample_category_name.replace(".npz", "")
# create folder
folder = os.path.exists(f"./sketch_image/{save_name}/")
if not folder:
os.makedirs(f"./sketch_image/{save_name}/")
print(f"./sketch_image/{save_name}/ is new mkdir!")
drawsketch = DrawSketch()
with ThreadPoolExecutor(max_workers=MAXTHREADSIZE) as t:
while not indexQueue.empty():
# t.shutdown(wait=False)
t.submit(worker)
exit()
Why is CPU utilization still so low?
I thought I could run straight to 90%. It's so comfortable. But still only about 1%?
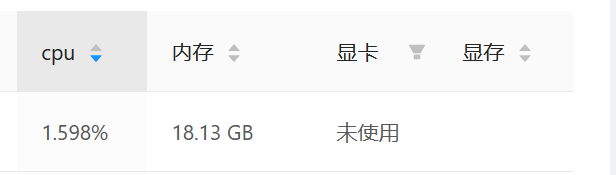
Python multithreading caused by GIL global interpreter lock is like a dummy
It should not be pointed out here that multithreading in python is not really multithreading.
The execution of Python code is controlled by the python virtual machine (interpreter). At the beginning of Python design, only one thread is executing in the main loop. Just like running multiple processes in a single CPU system, multiple programs can be stored in memory, but only one program runs in the CPU at any time. Similarly, although the Python interpreter can run multiple threads, only one thread runs in the interpreter.
Access to the Python virtual machine is controlled by the global interpreter lock (GIL), which ensures that only one thread is running at the same time. In a multithreaded environment, the Python virtual machine executes as follows:
- 1. Set GIL.
- 2. Switch to a thread for execution.
- 3. Operation.
- 4. Set the thread to sleep.
- 5. Unlock GIL.
- 6. Repeat the above steps again.
Multi process parallel computing
In order to reduce the overhead of process creation, we continue to use process pool technology to solve this problem.
Python provides a very easy-to-use multiprocessing package multiprocessing. You only need to define a function, and python will do everything else. With this package, you can easily complete the transformation from single Process to concurrent execution. Multiprocessing supports subprocesses, communication and data sharing, and performs different forms of synchronization. It provides Process, Queue, Pipe, Lock and other components.
For detailed study, please see the following blog:
Python multi process programming - jihite - blog Park
I created 128 processes at once, ran crazy and felt comfortable. Ha ha ha. Note, however, that you need to create blocking processes and lock free operations. Because the drawing operation takes time, if it is non blocking, all processes will return directly. This lock free design is much more perfect than the previous lock operation. The specific code is as follows:
#!/usr/bin/python
# Multi thread generation of sketch image
from concurrent.futures import ThreadPoolExecutor
from queue import Queue
import threading
import cv2
import os
import matplotlib.pyplot as plt
import numpy as np
import random
import asyncio
import multiprocessing
class DrawSketch(object):
def __init__(self):
pass
def scale_sketch(self, sketch, size=(448, 448)):
[_, _, h, w] = self.canvas_size_google(sketch)
if h >= w:
sketch_normalize = sketch / np.array([[h, h, 1]], dtype=np.float)
else:
sketch_normalize = sketch / np.array([[w, w, 1]], dtype=np.float)
sketch_rescale = sketch_normalize * np.array([[size[0], size[1], 1]], dtype=np.float)
return sketch_rescale.astype("int16")
def canvas_size_google(self, sketch):
"""
:param sketch: google sketch, quickDraw
:return: int list,[x, y, h, w]
"""
# get canvas size
vertical_sum = np.cumsum(sketch[1:], axis=0)
xmin, ymin, _ = np.min(vertical_sum, axis=0)
xmax, ymax, _ = np.max(vertical_sum, axis=0)
w = xmax - xmin
h = ymax - ymin
start_x = -xmin - sketch[0][0]
start_y = -ymin - sketch[0][1]
# sketch[0] = sketch[0] - sketch[0]
return [int(start_x), int(start_y), int(h), int(w)]
def draw_three(self, sketch, random_color=False, show=False, img_size=512):
"""
:param sketches: google quickDraw, (n, 3)
:param thickness: pass
:return: None
"""
thickness = int(img_size * 0.025)
sketch = self.scale_sketch(sketch, (img_size, img_size)) # scale the sketch.
[start_x, start_y, h, w] = self.canvas_size_google(sketch=sketch)
start_x += thickness + 1
start_y += thickness + 1
canvas = np.ones((max(h, w) + 3 * (thickness + 1), max(h, w) + 3 * (thickness + 1), 3), dtype='uint8') * 255
if random_color:
color = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
else:
color = (0, 0, 0)
pen_now = np.array([start_x, start_y])
first_zero = False
for stroke in sketch:
delta_x_y = stroke[0:0 + 2]
state = stroke[2:]
if first_zero:
pen_now += delta_x_y
first_zero = False
continue
cv2.line(canvas, tuple(pen_now), tuple(pen_now + delta_x_y), color, thickness=thickness)
if int(state) == 1: # next stroke
first_zero = True
if random_color:
color = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
else:
color = (0, 0, 0)
pen_now += delta_x_y
if show:
key = cv2.waitKeyEx()
if key == 27: # esc
cv2.destroyAllWindows()
exit(0)
return cv2.resize(canvas, (img_size, img_size))
class SketchData(object):
def __init__(self, dataPath, model="train"):
self.dataPath = dataPath
self.model = model
# Load data
def load(self):
dataset_origin_list = []
category_list = self.getCategory()
for each_name in category_list:
# npz_test = np.load(f"./{self.dataPath}/{each_name}", encoding="latin1", allow_pickle=True)["test"]
npz_tmp = np.load(f"./{self.dataPath}/{each_name}", encoding="latin1", allow_pickle=True)[self.model]
print(f"dataset: {each_name} added.")
dataset_origin_list.append(npz_tmp)
return dataset_origin_list
# Get category list
def getCategory(self):
category_list = os.listdir(self.dataPath)
return category_list
MAXQUEUESIZE = 10000
MAXTHREADSIZE = 128
drawsketch = DrawSketch()
def func(image_index, sample_category_name, save_name):
sample_sketch = dataset_origin_list[category_list.index(sample_category_name)][image_index]
sketch_cv = drawsketch.draw_three(sample_sketch)
plt.xticks([]) # Remove the x-axis
plt.yticks([]) # Remove the y-axis
plt.axis('off') # Remove the coordinate axis
plt.imshow(sketch_cv)
plt.savefig(f"./sketch_image/{save_name}/{save_name}_{image_index}.png")
print(f"{save_name}/{save_name}_{image_index}.png is saved!")
if __name__ == '__main__':
sketchdata = SketchData(dataPath='./sketch_dataset_17')
category_list = sketchdata.getCategory()
dataset_origin_list = sketchdata.load()
pool = multiprocessing.Pool(processes=MAXTHREADSIZE)
# Mapping
for category_index in range(len(category_list)):
sample_category_name = category_list[category_index]
print(sample_category_name)
save_name = sample_category_name.replace(".npz", "")
# create folder
folder = os.path.exists(f"./sketch_image/{save_name}/")
if not folder:
os.makedirs(f"./sketch_image/{save_name}/")
print(f"./sketch_image/{save_name}/ is new mkdir!")
for i in range(0, MAXQUEUESIZE):
# The total number of processes to be executed is processes. When a process is completed, a new process will be added
# pool.apply_async(func, (i,)) # Non blocking
pool.apply(func, (i, sample_category_name, save_name)) # block
pool.close()
pool.join() # Call the close function before calling join, otherwise an error will occur. After closing, no new process will be added to the pool. The join function waits for all child processes to end
print(f"all process is end! save path is ./sketch_image/{save_name}/, category_list is {category_list}")
exit()
'''
# Global queue locking
MAXQUEUESIZE = 1000
MAXTHREADSIZE = 10
indexQueue = Queue(maxsize=MAXQUEUESIZE)
queueLock = threading.Lock()
for i in range(0, MAXQUEUESIZE):
indexQueue.put(i)
def worker():
# Lock the sketch subscript that is not drawn in the queue every time
if not queueLock.acquire(blocking=False):
print(f"queueLock acquire is timeout!")
return
if not indexQueue.empty():
try:
image_index = indexQueue.get_nowait()
except:
# timeout return and release
print(f"queue get is timeout!")
queueLock.release()
return
else:
print("queue is empty")
queueLock.release()
sample_sketch = dataset_origin_list[category_list.index(sample_category_name)][image_index]
sketch_cv = drawsketch.draw_three(sample_sketch)
plt.xticks([]) # Remove the x-axis
plt.yticks([]) # Remove the y-axis
plt.axis('off') # Remove the coordinate axis
plt.imshow(sketch_cv)
plt.savefig(f"./sketch_image/{save_name}/{save_name}_{image_index}.png")
print(f"{save_name}/{save_name}_{image_index}.png is saved!")
if __name__ == '__main__':
sketchdata = SketchData(dataPath='./sketch_dataset_airplane')
category_list = sketchdata.getCategory()
dataset_origin_list = sketchdata.load()
# Mapping
for category_index in range(len(category_list)):
sample_category_name = category_list[category_index]
print(sample_category_name)
save_name = sample_category_name.replace(".npz", "")
# create folder
folder = os.path.exists(f"./sketch_image/{save_name}/")
if not folder:
os.makedirs(f"./sketch_image/{save_name}/")
print(f"./sketch_image/{save_name}/ is new mkdir!")
drawsketch = DrawSketch()
with ThreadPoolExecutor(max_workers=MAXTHREADSIZE) as t:
while not indexQueue.empty():
# t.shutdown(wait=False)
t.submit(worker)
exit()
'''
Well, that's the end of today's sharing. Here is the fishing time based on running data. Ha ha ha~