Druid is the best database connection pool in Java language, which can provide powerful sql monitoring and extension functions. The industry compares Druid with HikariCP. Although the performance of HikariCP is higher than Druid, Druid includes many dimensions of statistical and analysis functions, so this is why everyone chooses to use it.
First, add the following in maven project pom.xml:
<!-- druid Data connection pool -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.0</version>
</dependency>
Second, configure druid_datasource.properties
spring.datasource.url=jdbc:mysql://ip:3306/XXX?useUnicode=true&characterEncoding=utf-8&useSSL=false spring.datasource.username=root spring.datasource.password=root spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.driver-class-name=com.mysql.jdbc.Driver # The following is the supplementary settings of the connection pool, which are applied to all data sources above # Initialization size, min, Max spring.datasource.initialSize=5 spring.datasource.minIdle=5 spring.datasource.maxActive=20 # Configure the timeout time for getting connection waiting spring.datasource.maxWait=60000 # Configure how often to check the interval. Check the idle connections that need to be closed, in milliseconds spring.datasource.timeBetweenEvictionRunsMillis=60000 # Configure the minimum lifetime of a connection in the pool, in milliseconds spring.datasource.minEvictableIdleTimeMillis=300000 spring.datasource.validationQuery=SELECT 1 spring.datasource.testWhileIdle=true spring.datasource.testOnBorrow=false spring.datasource.testOnReturn=false # Open PSCache and specify the size of PSCache on each connection spring.datasource.poolPreparedStatements=true spring.datasource.maxPoolPreparedStatementPerConnectionSize=20 # Configure the filters intercepted by monitoring statistics. After the filters are removed, the monitoring interface sql cannot be counted. The 'wall' is used for the firewall spring.datasource.filters=stat,wall,log4j # Open mergeSql function through connectProperties property; slow SQL record spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 # Merge monitoring data from multiple druiddatasources # spring.datasource.druid.useGlobalDataSourceStat=true
Third, configure druid to spring boot container:
@Configuration
public class DruidConfiguration {
/**
* Register a: ServletRegistrationBean
* @return
*/
@Bean
public ServletRegistrationBean DruidStatViewServle2() {
//org.springframework.boot.context.embedded.ServletRegistrationBean provides class registration
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
//Add initialization parameter: initParams
//Login user name:
servletRegistrationBean.addInitParameter("allow","127.0.0.1");
//IP Blacklist (deny takes precedence over allow when there is a common one): if deny is satisfied, prompt: sorry, you are not allowed to view this page
// servletRegistrationBean.addInitParameter("deny", "192.168.1.1");
//Login to view the account password of the information
servletRegistrationBean.addInitParameter("loginUsername","root");
servletRegistrationBean.addInitParameter("loginPassword","123456");
//Whether the data can be reset
servletRegistrationBean.addInitParameter("resetEnable","false");
return servletRegistrationBean;
}
/**
* Register a: filterRegistrationBean
* @return
*/
@Bean
public FilterRegistrationBean druidStatFilter2(){
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
//Add filter rule
filterRegistrationBean.addUrlPatterns("/*");
//Add formatting information that does not need to be ignored
filterRegistrationBean.addInitParameter("exclusions","*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return filterRegistrationBean;
}
}
The third step above has another way, as follows:
//Add filter
@WebFilter(filterName = "druidWebStatFilter", urlPatterns = "/*",
initParams = {
@WebInitParam(name = "exclusions", value = "*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*")// Ignore resources
})
public class DruidStatFilter extends WebStatFilter {
}
Add DruidStatViewServlet.java service class by annotation
import com.alibaba.druid.support.http.StatViewServlet;
import javax.servlet.annotation.WebInitParam;
import javax.servlet.annotation.WebServlet;
@SuppressWarnings("serial")
@WebServlet(urlPatterns = "/druid/*", initParams = {
@WebInitParam(name = "allow", value = ""), // IP white list
@WebInitParam(name = "deny", value = ""),
// IP blacklist
@WebInitParam(name = "loginUsername", value = "root"), // User name
@WebInitParam(name = "loginPassword", value = "admin*druid"), // Password
@WebInitParam(name = "resetEnable", value = "true")})
public class DruidStatViewServlet extends StatViewServlet {
}
Here's a very important thing. Don't forget to add the servlet scanning annotation to the startup class
@ServletComponentScan(value = own package)
@PropertySource(value = "classpath:druid_datasource.properties", encoding = "utf-8")
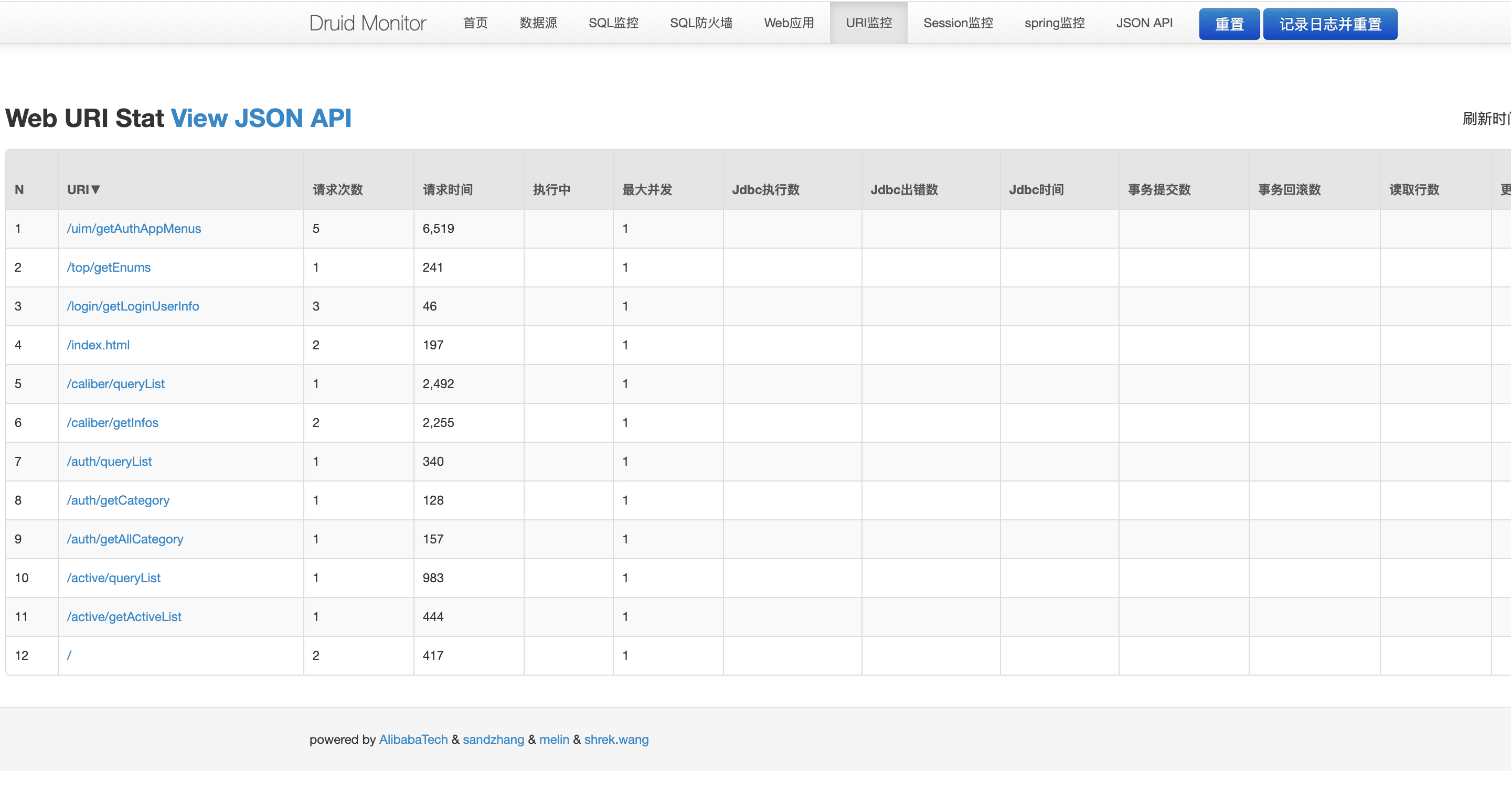
Finally, it is reasonable to say that Druid is set up and can be accessed normally through http://localhost:8080/druid/index.html, but I found that sql monitoring does not play a role in the operation