MongoDB sorting / indexing / aggregation / replication / fragmentation
1, MongoDB sorting (sort() method)
In MongoDB, use the sort() method to sort the data. The sort() method can specify the fields to be sorted through parameters, and use 1 and - 1 to specify the sorting method, where 1 is ascending and - 1 is descending.
The basic syntax of sort() method is as follows:
db.collection_name.find().sort({KEY:1})
example:
The data in col set is as follows:
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP course", "description" : "PHP Is a powerful server-side scripting language for creating dynamic interactive sites.", "by" : "Rookie tutorial", "url" : "http://www.runoob.com", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java course", "description" : "Java By Sun Microsystems The high-level programming language launched by the company in May 1995.", "by" : "Rookie tutorial", "url" : "http://www.runoob.com", "tags" : [ "java" ], "likes" : 150 }
{ "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB course", "description" : "MongoDB It's a Nosql database", "by" : "Rookie tutorial", "url" : "http://www.runoob.com", "tags" : [ "mongodb" ], "likes" : 100 }
The following example demonstrates that the data in the col set is arranged in descending order by the field likes:
>db.col.find({},{"title":1,_id:0}).sort({"likes":-1})
{ "title" : "PHP course" }
{ "title" : "Java course" }
{ "title" : "MongoDB course" }
When skip(), family (), sort() are executed together, the order of execution is first sort(), then skip(), and finally the displayed limit().
2, MongoDB index (createIndex() method)
Index is a special data structure. Index is stored in a data set that is easy to traverse and read. Index is a structure that sorts the values of one or more columns in the database table.
The basic syntax format of createIndex() method is as follows:
>db.collection.createIndex(keys, options)
In the syntax, the Key value is the index field to be created. 1 specifies to create the index in ascending order. If you want to create the index in descending order, specify - 1.
example
>db.col.createIndex({"title":1})
In the createIndex() method, you can also set multiple fields to create indexes (called composite indexes in relational databases)
>db.col.createIndex({"title":1,"description":-1})
createIndex() receives optional parameters. The list of optional parameters is as follows:

Create index in the background:
db.values.createIndex({open: 1, close: 1}, {background: true})
By adding the background:true option when creating an index, the creation can be performed in the background
1. View collection index
db.col.getIndexes()
2. View collection index size
db.col.totalIndexSize()
3. Delete all indexes of the collection
db.col.dropIndexes()
4. Deletes the specified index of the collection
db.col.dropIndex("Index name")
3, MongoDB aggregation (aggregate() method)
Aggregation in MongoDB is mainly used to process data (such as statistical average, summation, etc.) and return calculated data results.
The basic syntax format of the aggregate() method is as follows:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
example
The data in the collection is as follows:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
Now let's calculate the number of articles written by each author through the above set, and use aggregate() to calculate the results as follows:
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "runoob.com",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
In the above example, we use the field by_ The user field groups the data and calculates by_ The sum of the same values for the user field.
The following table shows some aggregate expressions:

Concept of pipeline
Pipes are generally used in Unix and Linux to take the output of the current command as the parameter of the next command.
The MongoDB aggregation pipeline passes the MongoDB document to the next pipeline for processing after one pipeline is processed. Pipeline operations can be repeated.
Expressions: process input documents and output. The expression is stateless. It can only be used to calculate the document of the current aggregation pipeline and cannot process other documents.
Here we introduce some common operations in the aggregation framework:
- $project: modify the structure of the input document. It can be used to rename, add, or delete fields, or to create calculation results and nested documents.
- m a t c h : use to too filter number according to , only transport Out symbol close strip piece of writing files . match: used to filter data and output only qualified documents. match: used to filter data and output only qualified documents. match uses MongoDB's standard query operations.
- $limit: used to limit the number of documents returned by the MongoDB aggregation pipeline$ Skip: skip the specified number of documents in the aggregation pipeline and return the remaining documents.
- $unwind: split an array type field in the document into multiple pieces, each containing a value in the array.
- $group: groups documents in the collection, which can be used to count results.
- $sort: sort the input documents and output them
- $geoNear: output ordered documents close to a geographic location.
Pipe operator instance
1. $project instance
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
);
In this case, there will only be_ id, tile, and author are three fields. By default_ The id field is included. If you want to exclude it_ If yes, it can be as follows:
db.article.aggregate(
{ $project : {
_id : 0 ,
title : 1 ,
author : 1
}});
2.$match instance
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
m
a
t
c
h
use
to
Obtain
take
branch
number
large
to
70
Small
to
or
etc.
to
90
remember
record
,
however
after
take
symbol
close
strip
piece
of
remember
record
give
reach
lower
one
rank
paragraph
match is used to obtain records with scores greater than 70 and less than or equal to 90, and then send qualified records to the next stage
match is used to obtain records with scores greater than 70 and less than or equal to 90, and then send qualified records to the next stage for processing.
3.$skip instance
db.article.aggregate(
{ $skip : 5 });
4, MongoDB replication
MongoDB replication is the process of synchronizing data on multiple servers.
Replication provides redundant backup of data and stores data copies on multiple servers, which improves data availability and ensures data security.
Replication also allows you to recover data from hardware failures and service outages.
MongoDB replication principle
mongodb replication requires at least two nodes. One of them is the master node, which is responsible for processing client requests, and the other is the slave node, which is responsible for copying the data on the master node.
The common collocation methods of mongodb nodes are: one master and one slave, one master and many slaves.
The master node records all operations oplog on it. The slave node polls the master node regularly to obtain these operations, and then performs these operations on its own data copy, so as to ensure that the data of the slave node is consistent with that of the master node.
The MongoDB replication structure is as follows:
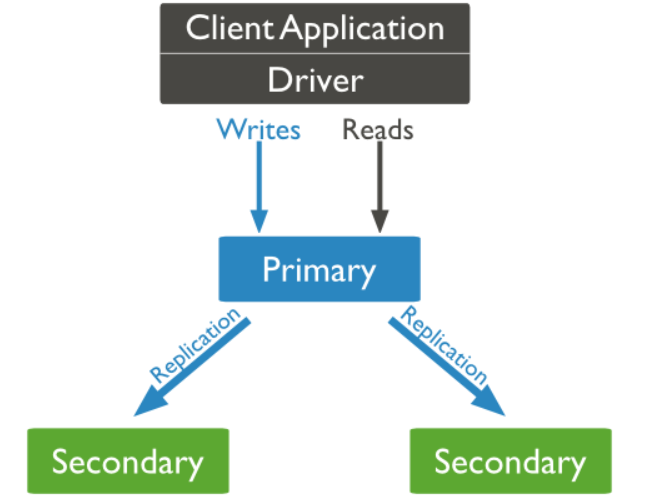
In the above structure diagram, the client reads data from the master node. When the client writes data to the master node, the master node interacts with the slave node to ensure data consistency.
Replica set characteristics:
- N-node cluster
- Any node can be the master node
- All writes are on the primary node
- Automatic failover
- Automatic recovery
5, MongoDB fragmentation
Slice
There is another kind of cluster in mongodb, namely, sharding technology, which can meet the demand of large growth of mongodb data volume.
When MongoDB stores a large amount of data, one machine may not be enough to store data, or it may not be enough to provide acceptable read and write throughput. At this time, we can split the data on multiple machines, so that the database system can store and process more data.
Why use shards
- Copy all writes to the master node
- The delayed sensitive data will be queried at the master node
- A single replica set is limited to 12 nodes
- When the amount of requests is huge, there will be insufficient memory.
- Insufficient local disk
- Vertical expansion is expensive
MongoDB fragmentation
The following figure shows the distribution of sharded cluster structure in MongoDB:

In the figure above, there are three main components as follows:
- Shard:
It is used to store actual data blocks. In the actual production environment, a shard server role can be assumed by a replica set of several machine groups to prevent a single point of failure of the host. - Config Server:
mongod instance, which stores the entire ClusterMetadata, including chunk information. - Query Routers:
Front end routing enables the client to access, and makes the whole cluster look like a single database. Front end applications can be used transparently.
Slice instance
The port distribution of slice structure is as follows:
Shard Server 1: 27020 Shard Server 2: 27021 Shard Server 3: 27022 Shard Server 4: 27023 Config Server : 27100 Route Process: 40000
Step 1: start Shard Server
[root@100 /]# mkdir -p /www/mongoDB/shard/s0 [root@100 /]# mkdir -p /www/mongoDB/shard/s1 [root@100 /]# mkdir -p /www/mongoDB/shard/s2 [root@100 /]# mkdir -p /www/mongoDB/shard/s3 [root@100 /]# mkdir -p /www/mongoDB/shard/log [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork .... [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 --dbpath=/www/mongoDB/shard/s3 --logpath=/www/mongoDB/shard/log/s3.log --logappend --fork
Step 2: start Config Server
[root@100 /]# mkdir -p /www/mongoDB/shard/config [root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
Note: here, we can start the mongodb service as normal, without adding - shardsvr and configsvr parameters. Because the function of these two parameters is to change the startup port, we can specify the port ourselves.
Step 3: start Route Process
/usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500
In mongos startup parameters, chunkSize is used to specify the size of chunks. The unit is MB, and the default size is 200MB.
Step 4: configure Sharding
Next, we use the MongoDB Shell to log in to mongos and add the Shard node
[root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000
MongoDB shell version: 2.0.7
connecting to: 127.0.0.1:40000/admin
mongos> db.runCommand({ addshard:"localhost:27020" })
{ "shardAdded" : "shard0000", "ok" : 1 }
......
mongos> db.runCommand({ addshard:"localhost:27029" })
{ "shardAdded" : "shard0009", "ok" : 1 }
mongos> db.runCommand({ enablesharding:"test" }) #Set the database for sharding storage
{ "ok" : 1 }
mongos> db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}})
{ "collectionsharded" : "test.log", "ok" : 1 }
Step 5: without much change in the program code, directly connect the database to the access interface 40000 as connecting to the ordinary mongo database