I. Preface
For guaranteed customer group, how to conduct detailed analysis and mining on the guaranteed customer group type? As shown in Figure 1, how do I get the label and how do I label it?
| Figure 1: Sample Diagram |
|---|
Using graph technology, you can label the triangle directly.
Algorithmic steps
- Guarantee association data cleaning;
- Construct guarantee map by using guarantee association relationship;
- Calculate 5-degree full path for guarantee customer;
- Use louvain for community (guest) groups;
- Community type analysis within the group;
- Summary of Guaranteed Customer Types.
Algorithmic Description
- Model input: Guarantee relationship data;
- Model results: Guaranteed customer map type;
- Model application: Label each customer with a profile, focus on some unusual profiles, prevent violation of warranty, and reduce risk.
2. Data Description
demo data is constructed using faker in python, which mainly generates guarantee relationship data.
#Import Module Package
import warnings
warnings.filterwarnings('ignore')
import random
import pandas as pd
import multiprocessing
import timeit
from faker import Faker
fake = Faker("zh-CN")
import os
#Guarantee Relationship Data Cleanup
if os.path.isfile('rela_demo.csv'):
os.remove('rela_demo.csv')
#Guaranteed Customer Data Cleanup
if os.path.isfile('node_demo.csv'):
os.remove('node_data.csv')
#Generate Guarantee Relation Data
def demo_data_(edge_num):
s = []
for i in range(edge_num):
#Guarantee Company, Guaranteed Company, Guarantee Amount, Guarantee Time
s.append([fake.company(), fake.company(), random.random(), fake.date(pattern="%Y-%m-%d", end_datetime=None)])
demo_data = pd.DataFrame(s, columns=['guarantee', 'guarantor', 'money', 'data_date'])
print("-----demo_data describe-----")
print(demo_data.info())
print("-----demo_data head---------")
print(demo_data.head())
return demo_data
#Determine if the two columns of the DataFrame are equal
def if_same(a, b):
if a==b:
return 1
else:
return 0
#demeo data processing
def rela_data_(demo_data):
print('Number of raw data records', len(demo_data))
#Remove self-insurance
demo_data['bool'] = demo_data.apply(lambda x: if_same(x['guarantor'], x['guarantee']), axis=1)
demo_data = demo_data.loc[demo_data['bool'] != 1]
#Remove non-empty
demo_data = demo_data[(demo_data['guarantor'] != '')&(demo_data['guarantee'] != '')]
#Remove duplicate guarantor, guarantee items by date
demo_data = demo_data.sort_values(by=['guarantor', 'guarantee', 'data_date'], ascending=False).drop_duplicates(keep='first', subset=['guarantor', 'guarantee']).drop_duplicates().reset_index()
demo_data[['guarantee', 'guarantor', 'money', 'data_date']].to_csv('rela_demo.csv', index = False)
return demo_data[['guarantee', 'guarantor', 'money', 'data_date']]
#Node Data
#Nodes are extracted from relational data
def node_data_(demo_data):
node_data = pd.concat([demo_data[['guarantor']].rename(columns = {'guarantor':'cust_id'}), demo_data[['guarantee']].rename(columns = {'guarantee':'cust_id'})])[['cust_id']].drop_duplicates().reset_index()
print('Number of nodes', len(node_data['cust_id'].unique()))
node_data[['cust_id']].to_csv('node_data.csv', index = False)
return node_data[['cust_id']]
if __name__ == '__main__':
#edge_num Sample Relation Bars
demo_data = demo_data_(edge_num=1000)
rela_demo = rela_data_(demo_data)
#node_num Sample Node Number
node_data = node_data_(demo_data)
3. Introduction to Neo4j
1. Python, Neo4j Interaction
As a common software for data analysis, Python can use Python to process and calculate Neo4j's graph analysis data, and a module package py2neo needs to be downloaded.
#Connection Diagram Database
from py2neo import Graph, Node, Relationship
def connect_graph():
graph = Graph("http://*.*.*.*:7474", username = "neo4j", password = ' password')
return (graph)
#graph = connect_graph()
2. Neo4j chart entry
- Neo4j supports multiple tag entries;
- Neo4j imports are best in the form of local file imports.
def create_graph(graph, load_node_path, load_rel_path, load_node_name, load_rel_name, guarantee_edges):
guarantee_edges.to_csv(load_rel_path,encoding = 'utf-8', index = False)
x = guarantee_edges[:]
x1 = pd.DataFrame(x['Guarantor_Id'][:].drop_duplicates())
x1.columns = ['Cust_id']
x2 = pd.DataFrame(x['Guarantee_Id'][:].drop_duplicates())
x2.columns = ['Cust_id']
x3 = x1.merge(x2,left_on = 'Cust_id',right_on = 'Cust_id',how = 'inner')[:]
x1 = x1.append(x3)
x1 = x1.append(x3)
x1 = x1.drop_duplicates(keep = False)[:]
x2 = x2.append(x3)
x2 = x2.append(x3)
x2 = x2.drop_duplicates(keep = False)[:]
x3.insert(loc = 0,column = 'label1',value = 'Cust')
x3.insert(loc = 0,column = 'label2',value = 'Guarantor')
x3.insert(loc = 0,column = 'label3',value = 'Guarantee')
x1.insert(loc = 0,column = 'label1',value = 'Cust')
x1.insert(loc = 0,column = 'label2',value = 'Guarantor')
x1.insert(loc = 0,column = 'label3',value = '')
x2.insert(loc = 0,column = 'label1',value = 'Cust')
x2.insert(loc = 0,column = 'label2',value = '')
x2.insert(loc = 0,column = 'label3',value = 'Guarantee')
x4 = pd.DataFrame(pd.concat([x1, x2, x3]))
x4 = x4.drop_duplicates()
x4.to_csv(load_node_path,encoding = 'utf-8', index = False)
#Clear up historical relationships and nodes
graph.run("MATCH p=()-[r:guarantee]->() delete p")
graph.run("MATCH (n:Cust) delete n")
#Create Index
graph.run("CREATE INDEX ON:Cust(Cust_id)")
graph.run("CREATE INDEX ON:Guarantor(Cust_id)")
graph.run("CREATE INDEX ON:Guarantee(Cust_id)")
#Import Node
graph.run("USING PERIODIC COMMIT 1000 LOAD CSV WITH HEADERS FROM 'file://%s' AS line MERGE (p:Cust{Cust_id:line.Cust_id}) ON CREATE SET p.Cust_id=line.Cust_id ON MATCH SET p.Cust_id = line.Cust_id WITH p, [line.label1, line.label2, line.label3] AS sz CALL apoc.create.removeLabels(p, apoc.node.labels(p)) YIELD node as n CALL apoc.create.addLabels(p, sz) YIELD node RETURN count(p)" % load_node_path)
print("%s INFO : Load%s Complete." % (time.ctime(), load_node_name))
#Import Relationships
graph.run("USING PERIODIC COMMIT 1000 LOAD CSV WITH HEADERS FROM 'file://%s' AS line match (s:Cust{Cust_id:line.Guarantor_Id}),(t:Cust{Cust_id:line.Guarantee_Id}) MERGE (s)-[r:guarantee{Money:toFloat(line.Money)}]->(t) ON CREATE SET r.Dt = line.Dt, r.Money = toFloat(line.Money), r.link_strength = 1 ON MATCH SET r.Dt = line.Dt, r.Money = toFloat(line.Money), r.link_strength = 1" % load_rel_path)
print("%s INFO : Load%s Complete." % (time.ctime(), load_rel_name))
3. Neo4j diagram analysis
| Sequence Number | Graph calculation |
|---|---|
| 1 | Node Entry |
| 2 | Node Outbound |
| 3 | Degree of node |
| 4 | Node Mediation Degree |
| 5 | Node center eigenvector value |
| 6 | pagerank value of node |
| 7 | 5-degree path of node |
#Calculate Node Entry
def guarantee_indegree_(graph):
x1 = pd.DataFrame(graph.run("call algo.degree.stream('Cust','guarantee',{direction:'incoming'})yield nodeId,score return algo.getNodeById(nodeId).Cust_id as Guarantee_Id,score as guarantee_indegree order by guarantee_indegree desc").data()).drop_duplicates()
x2 = pd.DataFrame(guarantee_edges['Guarantee_Id']).drop_duplicates()[:]
guarantee_indegree = pd.merge(x2, x1, how = 'left', on = ['Guarantee_Id']).drop_duplicates()[:]
if len(guarantee_indegree) == 0:
guarantee_indegree.insert(loc = 0,column = 'name',value = '')
guarantee_indegree.insert(loc = 0,column = 'guarantee_indegree',value = '')
return (guarantee_indegree)
#guarantee_indegree = guarantee_indegree_(graph)
#Calculate node outbound
def guarantee_outdegree_(graph):
x1 = pd.DataFrame(graph.run("call algo.degree.stream('Cust','guarantee',{direction:'out'})yield nodeId,score return algo.getNodeById(nodeId).Cust_id as Guarantor_Id,score as guarantee_outdegree order by guarantee_outdegree desc").data()).drop_duplicates()
x2 = pd.DataFrame(guarantee_edges['Guarantor_Id']).drop_duplicates()[:]
guarantee_outdegree = pd.merge(x2, x1, how = 'left', on = ['Guarantor_Id']).drop_duplicates()[:]
if len(guarantee_outdegree) == 0:
guarantee_outdegree.insert(loc = 0,column = 'name',value = '')
guarantee_outdegree.insert(loc = 0,column = 'guarantee_outdegree',value = '')
return (guarantee_outdegree)
#guarantee_outdegree = guarantee_outdegree_(graph)
#Calculate the degree of a node
def guarantee_degree_(graph):
x1 = pd.DataFrame(guarantee_edges[['Guarantee_Id','Guarantor_Id']]).drop_duplicates()[:]
x2 = pd.merge(x1, guarantee_indegree, how = 'left', on = ['Guarantee_Id']).drop_duplicates()[:]
guarantee_degrees = pd.merge(x2, guarantee_outdegree, how = 'left', on = ['Guarantor_Id']).drop_duplicates()[:]
if len(guarantee_degrees) == 0:
guarantee_degrees.insert(loc = 0,column = 'name',value = '')
guarantee_degrees.insert(loc = 0,column = 'guarantee_degrees',value = '')
return (guarantee_degrees)
#guarantee_degrees = guarantee_degree_(graph)
#Calculate the Mediation of Nodes
def guarantee_btw_(graph):
guarantee_btw = pd.DataFrame(graph.run("call algo.betweenness.stream('Cust','guarantee',{direction:'outer'}) yield nodeId,centrality return algo.getNodeById(nodeId).Cust_id as name,centrality order by centrality desc").data())
if len(guarantee_btw) == 0:
guarantee_btw.insert(loc = 0,column = 'name',value = '')
guarantee_btw.insert(loc = 0,column = 'centrality',value = '')
return (guarantee_btw)
#guarantee_btw = guarantee_btw_(graph)
#Calculate the central eigenvector value of a node
def guarantee_eigencentrality_(graph):
guarantee_eigencentrality = pd.DataFrame(graph.run("call algo.eigenvector.stream('Cust','guarantee',{normalization:'l2norm', weightProperty:'Money'}) yield nodeId,score return algo.getNodeById(nodeId).Cust_id as name,score as eigenvector order by eigenvector desc").data())
if len(guarantee_eigencentrality) == 0:
guarantee_eigencentrality.insert(loc = 0,column = 'name',value = '')
guarantee_eigencentrality.insert(loc = 0,column = 'eigenvector',value = '')
return (guarantee_eigencentrality)
#guarantee_eigencentrality = guarantee_eigencentrality_(graph)
#Calculate the pagerank value of a node
def guarantee_pagerank_(graph):
sum = pd.DataFrame(graph.run("call algo.pageRank.stream('Cust','guarantee',{iterations:1000,dampingFacter:0.85, weightProperty:'Money'})yield nodeId,score return sum(score) as sum").data())['sum'][0]
guarantee_pagerank = pd.DataFrame(graph.run("call algo.pageRank.stream('Cust','guarantee',{iterations:1000,dampingFacter:0.85, weightProperty:'Money'})yield nodeId,score return algo.getNodeById(nodeId).Cust_id as name,score/%f as pageRank order by pageRank desc" %(sum)).data())
if len(guarantee_pagerank) == 0:
guarantee_pagerank.insert(loc = 0,column = 'name',value = '')
guarantee_pagerank.insert(loc = 0,column = 'pageRank',value = '')
return (guarantee_pagerank)
#guarantee_pagerank = guarantee_pagerank_(graph)
def all_paths_(graph):
all_paths = pd.DataFrame(graph.run("MATCH p = (n:Cust{})-[r:guarantee*..5]->(m) where SIZE(apoc.coll.toSet(NODES(p))) = length(p)+1 RETURN m.Cust_id as id, REDUCE(s=[], x in NODES(p) | s + x.Cust_id) as path, length(p) + 1 as path_len, n.Cust_id as start ").data())
all_paths['path'] = (['->'.join(x) for x in all_paths['path']])
all_paths = all_paths.drop_duplicates()[:]
return (all_paths)
#all_paths = all_paths_(graph)
4. Map Patterns
Take circle as an example:
- Get full path data;
- The filter path is longer than 2;
- Path data is associated with relational data, which indicates the existence of a circle.
Supplementary: Triangles can refer directly to algo.triangle
def guarantee_cycle_(all_paths):
x1 = all_paths.drop_duplicates()[:]
x2 = guarantee_edge[['Guarantor_Id','Guarantee_Id']].drop_duplicates()[:]
x2.columns = ['id','start']
x2['cycle_flag'] = 1
x3 = x1.loc[x1['path_len'] > 2].drop_duplicates()[:]
x4 = pd.merge(x3, x2, how = 'left',on = ['id','start']).drop_duplicates()[:]
x5 = x4.loc[x4['cycle_flag'] == 1].drop_duplicates()[:]
x6 = pd.merge(x1, x5, how = 'left',on = ['id','start','path','path_len']).drop_duplicates()[:]
x7 = x6.fillna(0).drop_duplicates()[:]
return (x7)
#triangle patterns
def triangle_(graph):
x = pd.DataFrame(graph.run("call algo.triangle.stream('Cust','guarantee',{}) yield nodeA, nodeB, nodeC return algo.getNodeById(nodeA).Cust_id as node1, algo.getNodeById(nodeB).Cust_id as node2, algo.getNodeById(nodeC).Cust_id as node3").data())
return (x)
#triangle = triangle_(graph)
5. Model Description
Community type, the need to group customers, and then study the customer type within the group, such as through the number of nodes, edges, road length, and so on.
6. Model examples
The model results in a wide table of customer patterns
| Customer Number | Community Number | Route | Type type | Community Density | pageRank |
|---|---|---|---|---|---|
| A | 1 | A->B->C | triangle | 1 | * |
The format is illustrated directly in the figure above: financing, tower, triangle, circle
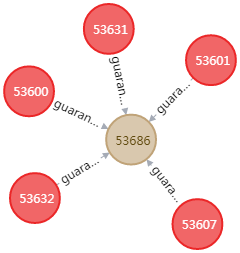
| Figure 2: Financing |
|---|
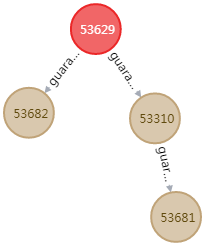
| Figure 3: Towers |
|---|

| Figure 4: Triangles |
|---|

| Fig. 5: Circles |
|---|
7. Prospect
- A study of community patterns can identify high-risk groups.
- Readers can also portray styles themselves.