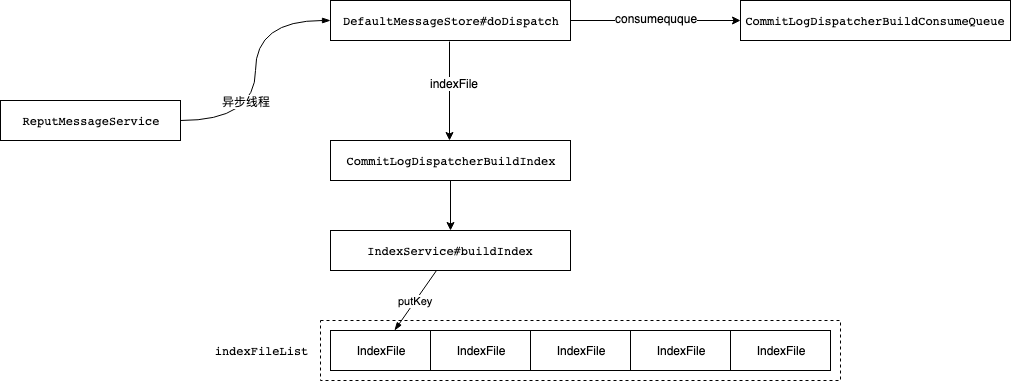
First, let's look at the process of indexfile, and then analyze and debug the source code step by step. In addition to providing the messages stored in MessageStore to consumer s through ConsumeQueue, it also supports querying messages through MessageID or MessageKey; When using ID query, because the ID is generated by broker+offset (msgId here refers to the server), it is easy to find the corresponding commitLog file to read the message. For querying messages with MessageKey, the MessageStore builds an index to improve the reading speed
quote Gap Original words:
The entire slotTable+indexLinkedList can be understood as a java HashMap. Whenever a new message index is put in, first take the hashCode of the MessageKey, and then use the hashCode to model the total number of slots to get which slot should be put in. The total number of slots is 500W by default. As long as you take a hash, you will inevitably face the problem of hash conflict. Like HashMap, IndexFile also uses a linked list structure to solve hash conflict. The only difference between this and HashMap is that the latest index pointer is placed in the slot. This is because in general, you must give priority to the latest messages.
The pointer value placed in each slot is the offset of the index in the indexFile. As shown in the figure above, the size of each index is 20 bytes, so it is easy to locate the position of the index according to the number (offset) of the current index in the file. Then, each index saves the position of the previous index in the same slot, and so on to form a linked list structure. Let's look at the process of creating a new index through the code
1. IndexFile file storage structure
Through the source code, we know how a storage structure of IndexFile is. The following figure is quoted from CSDN zhanqiu's article Principle analysis of RocketMQ

The index file consists of the index file header, IndexHeader, The Slot slot and the index content of the message are composed of three parts. Next, each part is analyzed
- IndexHeader: the header information of the index file consists of 40 bytes

//8-bit storage time (disk dropping time) of the first message of the index file
this.byteBuffer.putLong(beginTimestampIndex, this.beginTimestamp.get());
//8-bit storage time (disk dropping time) of the last message of the index file
this.byteBuffer.putLong(endTimestampIndex, this.endTimestamp.get());
//8-bit physical location offset of the first message of the index file in the commitlog (message storage file) (the message can be obtained directly through the physical offset)
this.byteBuffer.putLong(beginPhyoffsetIndex, this.beginPhyOffset.get());
//8-bit physical location offset of the last message (Message) in the commitlog (message storage file) of the index file
this.byteBuffer.putLong(endPhyoffsetIndex, this.endPhyOffset.get());
//4-bit the current number of hash slot s in the index file
this.byteBuffer.putInt(hashSlotcountIndex, this.hashSlotCount.get());
//Current index number of 4-bit index files
this.byteBuffer.putInt(indexCountIndex, this.indexCount.get());- Slot. By default, there are 5 million slots configured in each file, and each slot is 4-bit integer data
Slot how many index data does each node hold
//Data storage location of slot 40 + keyHash% (500W) * 4 int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize; //Slot Table //4 bytes //Record the current index of the slot. If the hash conflicts (i.e. the absSlotPos are consistent), it will be used as the pre index of the next new slot this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount()); - Index the message content, and the message length is fixed at 20 bits

//Index Linked list //hash value of topic+message key this.mappedByteBuffer.putInt(absIndexPos, keyHash); //The message is in the physical file address of CommitLog, and you can directly query the message (the core mechanism of indexing) this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset); //The difference between the drop time of the message and the beginTimestamp in the header (in order to save storage space, if the drop time of the message is directly saved, it must be 8 bytes) this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff); //9. Record the last index of the slot //The key to hash conflict handling is the index of the previous message index of the same hash value (if the current message index is the first index of the hash value, prevIndex=0, which is also the stop condition for message index lookup). The prevIndex of the first message in each slot position is 0 this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
2. IndexFile file data writing
/**
*
* @param key topic + uniqKey
* @param phyOffset Physical offset
* @param storeTimestamp
* @return
*/
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
//1. Judge whether the index is full, and return failure
if (this.indexHeader.getIndexCount() < this.indexNum) {
//2. Calculate the non negative hashCode of the key
int keyHash = indexKeyHashMethod(key);
//3. Slot keyhash% 500W where the key should be stored
int slotPos = keyHash % this.hashSlotNum;
//3. Data storage location of slot 40 + keyHash% (500W) * 4
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
// fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
// false);
//5. If there is a hash conflict, get the count of the previous index stored in this slot. If there is no hash conflict, the value is 0
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
//6. Calculate the seconds difference between the storage time of the current msg and the first msg
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
//Here in order to save space; The direct timestamp is 8 bits
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
//7. Get the actual stored position of the index
//Sequence number of 40 + 500W * 4 + index * 40;
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
//8,Index Linked list
//hash value of topic+message key
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
//The message is in the physical file address of CommitLog, and you can directly query the message (the core mechanism of indexing)
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
//The difference between the drop time of the message and the beginTimestamp in the header (in order to save storage space, if the drop time of the message is directly saved, it must be 8 bytes)
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
//9. Record the last index of the slot
//The key to hash conflict handling is the index of the previous message index of the same hash value (if the current message index is the first index of the hash value, prevIndex=0, which is also the stop condition for message index lookup). The prevIndex of the first message in each slot position is 0
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
//Slot Table
//4 bytes
//10. Record the current index of the slot. If the hash conflicts (i.e. the absSlotPos are consistent), it will be used as the pre index of the next new slot
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
//11. If it is the first message, update the start offset and start time in the header
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
//12. Cumulative indexHeader
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
} catch (Exception e) {
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
}
} else {
log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ "; index max num = " + this.indexNum);
}
return false;
}
The above code is the index data writing process. Step 5 is to obtain whether the value of the slot exists. If so, the hash conflicts. In step 9, set the value to the previous index of the current index, and in step 10, set the value of the slot to the current index; This is a bit similar to the linked list operation of HashMap. When creating files, a corresponding daemon thread is established to perform asynchronous disk brushing operation
3. IndexFile data query
/**
*
* @param topic Query messages by topic dimension, because the key is topic+MessageKey when the index is generated
* @param key MessageKey
* @param maxNum The maximum number of returned messages. Because the key is set by the user and is not guaranteed to be unique, multiple messages may be retrieved; At the same time, only hash is stored in the index, so the same message as hash will be taken out
* @param begin Start time
* @param end End time
* @return
*/
public QueryOffsetResult queryOffset(String topic, String key, int maxNum, long begin, long end) {
List<Long> phyOffsets = new ArrayList<Long>(maxNum);
long indexLastUpdateTimestamp = 0;
long indexLastUpdatePhyoffset = 0;
//No more than 64
maxNum = Math.min(maxNum, this.defaultMessageStore.getMessageStoreConfig().getMaxMsgsNumBatch());
try {
this.readWriteLock.readLock().lock();
if (!this.indexFileList.isEmpty()) {
//1. Look forward from the last file. The last file is the latest
for (int i = this.indexFileList.size(); i > 0; i--) {
IndexFile f = this.indexFileList.get(i - 1);
boolean lastFile = i == this.indexFileList.size();
if (lastFile) {
indexLastUpdateTimestamp = f.getEndTimestamp();
indexLastUpdatePhyoffset = f.getEndPhyOffset();
}
//2. Judge whether the index file contains all or part of begin and end
if (f.isTimeMatched(begin, end)) {
//3. Get offset from index file
f.selectPhyOffset(phyOffsets, buildKey(topic, key), maxNum, begin, end, lastFile);
}
if (f.getBeginTimestamp() < begin) {
break;
}
if (phyOffsets.size() >= maxNum) {
break;
}
}
}
} catch (Exception e) {
log.error("queryMsg exception", e);
} finally {
this.readWriteLock.readLock().unlock();
}
return new QueryOffsetResult(phyOffsets, indexLastUpdateTimestamp, indexLastUpdatePhyoffset);
}public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum,
final long begin, final long end, boolean lock) {
if (this.mappedFile.hold()) {
//1. Calculate the non negative hashCode of the key
int keyHash = indexKeyHashMethod(key);
//2. Slot keyhash% 500W where the key should be stored
int slotPos = keyHash % this.hashSlotNum;
//3. Data storage location of slot 40 + keyHash% (500W) * 4
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
if (lock) {
// fileLock = this.fileChannel.lock(absSlotPos,
// hashSlotSize, true);
}
//4. Get the last index location stored in the slot for backtracking
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
// if (fileLock != null) {
// fileLock.release();
// fileLock = null;
// }
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()
|| this.indexHeader.getIndexCount() <= 1) {
} else {
for (int nextIndexToRead = slotValue; ; ) {
//5. Returns if the query entry is satisfied
if (phyOffsets.size() >= maxNum) {
break;
}
//6. Get the actual stored position of the index
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
//7. The physical offset is the offset of the commitLog
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
//The storage time of the current msg differs from the first msg by seconds
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
if (timeDiff < 0) {
break;
}
timeDiff *= 1000L;
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
//8. If the hash is consistent and the time is between begin and end, add it to the result set
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
//9. Read 0, indicating that there is no data readable
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
//10. The previous one is not equal to 0. Continue to read the previous one and backtrack
nextIndexToRead = prevIndexRead;
}
}
} catch (Exception e) {
log.error("selectPhyOffset exception ", e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
this.mappedFile.release();
}
}
}