Reprinted: http://blog.csdn.net/luotuo44/article/details/42963793
Warm Tip: This article uses some global variables that can be set at the start of memcached. The meaning of these global variables can be referred to.< Detailed explanation of start-up parameters of memcached " For these global variables, the approach is like< How to read memcached source code > Take it directly as you say Default value . In addition, LRU queues are mentioned in this article, and an introduction to LRU queues can be consulted.< LRU Queues and item Structures>.
Overdue Failure Treatment:
An item expires in two cases: 1. The item's exptime stamp arrives. 2. Users use the flush_all command to make all items expired. Readers may say that the touch command can also expire an item, which is actually the first case mentioned earlier.
Overtime failure:
For the first type of expiration, memcached uses lazy processing: it does not actively detect whether an item is expired or not. When the worker thread accesses the item, it detects whether the item's exptime stamp has arrived. It's relatively simple. We don't paste the code here, but we will paste it later.
The flush_all command:
The second expiration is set by the user flush_all command. Flush_all will render all items expired. What items do all items refer to? Because multiple clients are constantly inserting items into memcached, it is important to understand what all items refer to. Is it bounded by the moment the worker thread receives this command or by the moment it deletes it?
When the worker thread receives the flush_all command, the oldest_live member of the global variable settings stores the time at which it receives the command (to be precise, the worker thread parses that it knows this is a flush_all command, minus one at the moment), the code is settings.oldest_live= current_time-1; then the item_flush_expired function is called to lock the cache_lock, and then The do_item_flush_expired function is then called to complete the work.
The do_item_flush_expired function traverses all LRU queues and detects the time members of each item. It is reasonable to detect time members. If the time member is less than settings.oldest_live, the item already exists when the worker thread receives the flush_all command (the time member represents the last access time of the item). Then it's time to delete the item.
It seems that memcached is bounded by the moment the worker thread receives the flush_all command. Wait a minute, see clearly!! In the do_item_flush_expired function, the item is not deleted when the time member of the item is less than settings.oldest_live, but when it is larger. In the sense of time member variables, what is greater than that? Do you have anything larger than that? Strange! "T" & T $
In fact, memcached is bounded by the moment of deletion. Why does settings.oldest_live store the timestamp when the worker thread receives the flush_all command? Why judge whether ITER - > time is larger than settings.oldest_live?
In general, delete all items on the hash table and LRU directly in the do_item_flush_expired function. That's really what we can achieve. However, during the processing of this worker thread, other worker threads can't work at all (because the caller of do_item_flush_expired has locked cache_lock). There may be a lot of data in the LRU queue, and the process of overdue processing may be very long. Other worker threads are totally unacceptable.
The author of memcached must be aware of this problem, so he wrote a strange do_item_flush_expired function to accelerate it. Do_item_flush_expired deletes only a few special items. How to use the special method will be explained in the following code comments. For many other items, memcached handles them lazily. Only when the worker thread attempts to access the item does it detect whether the item has been set to expire. In fact, you can detect whether the item is expired without any settings, using the settings.oldest_live variable. This laziness is the same as the first item that failed to expire.
Now let's look at the do_item_flush_expired function and see the special item.
Laziness delete:
Now read item's lazy deletion. Note the comments in the code.
As you can see, after finding an item, you need to check whether it has expired. If it fails, delete it.
In addition to the do_item_get function, the do_item_alloc function also handles expired items. The do_item_alloc function does not delete the expired item, but takes it for its own use. Because the function of this function is to apply for an item, if an item expires, it will occupy the memory of the item directly. Let's take a look at the code.
The flush_all command can have time parameters. This time, like other times, ranges from 1 to REALTIME_MAXDELTA(30 days). If the command is flush_all 100, then all items expire after 99 seconds. The settings.oldest_live value is current_time+100-1, and the do_item_flush_expired function is useless (it will never be preempted for 99 seconds). It is for this reason that we need to add the judgment of settings.oldest_live<= current_time in do_item_get to prevent premature deletion of items.
There is obviously a bug here. Suppose client A submits the flush_all10 command to the server. After five seconds, client B submits the command flush_all100 to the server. Client A's commands will fail and do nothing.
LRU crawler:
As mentioned earlier, memcached is lazy to delete expired items. So even if the user uses the flush_all command on the client to expire all items, these items still occupy the hash table and LRU queues and are not returned to the slab allocator.
LRU crawler threads:
Is there any way to force the removal of these expired item s, no longer occupy the hash table and LRU queue space, and return them to slabs? Of course there is. memcached provides LRU crawlers for this purpose.
To use LRU crawlers, you must use the lru_crawler command on the client side. The memcached server processes according to the specific command parameters.
Memcached is a special thread responsible for clearing these expired item s. This article will call this thread LRU crawler thread. By default, memcached does not start this thread, but you can start this thread by adding the parameter - o lru_crawler when starting memcached. It can also be started by client command. Even if the LRU crawler thread is started, it will not work. Additional commands are required to indicate which LRU queue to clear. Now let's see what parameters lru_crawler has.
LRU crawler command:
-
Lru_crawler <enable | disable> starts or stops an LRU crawler thread. At most one LRU crawler thread at any time. This command assigns settings.lru_crawler to true or false
-
Lru_crawler crawl <classid, classid, CLassID | all> can use lists like 2,3,6 to indicate which LRU queue to clear. You can also use all to process all LRU queues
-
Lru_crawler sleep < microseconds > LRU crawler thread will occupy lock when cleaning item, which will hinder the normal business of worker thread. So LRU crawlers need to sleep from time to time when they are dealing with it. The default dormancy time is 100 microseconds. This command assigns settings.lru_crawler_sleep
-
Lru_crawler to crawl <32u> An LRU queue may have many expired items. If it is checked and cleaned up all the time, it will inevitably hinder the normal business of worker threads. This parameter is used to specify how many items are checked for each LRU queue at most. The default value is 0, so it won't work unless specified. This command assigns settings.lru_crawler_tocrawl
If you want to start an LRU crawler to actively delete expired items, you need to do this: First start an LRU crawler thread using the lru_crawler enable command. Then use the lru_crawler to crawl num command to determine that each LRU queue checks num-1 items at most. Finally, use the command lru_crawler Crawl < classid, classid, CLassID | all > specifies the LRU queue to be processed. lru_crawler sleep may not be set, but if it is to be set, it can be set before the lru_crawler crawl command.
Start the LRU crawler thread:
Now let's see how LRU reptiles work. Let's first look at what global variables memcached defines for LRU crawlers.
The code is relatively simple, let's not talk about it here. Let's look at the lru_crawler enable and disable commands. The enable command will start an LRU crawler thread, and disable will stop the LRU crawler thread, not call pthread_exit directly to stop the thread. The pthread_exit function is a dangerous function and should not appear in the code.
You can see that the worker thread starts an LRU crawler thread after receiving the "lru_crawler enable" command. This LRU crawler thread has not yet performed the task, because no task has been specified. The command "lru_crawler to crawlnum" does not start a task. For this command, the worker thread simply assigns settings.lru_crawler_tocrawl to num.
Clear the invalid item:
The command "lru_crawler crawl < classid, classid, CLassID | all >" is the specified task. This command specifies which LRU queue to clean up. If all is used, then all RU queues are cleaned up.
Before looking at memcached's cleanup code, consider one question: How to clean up an LRU queue?
The most intuitive approach is to first lock (lock cache_lock) and then traverse an entire LRU queue. Judge each item in the LRU queue directly. Obviously, there is a problem with this method. If memcached has a large number of items, traversing an LRU queue will take too long. This hinders the normal business of worker threads. Of course, we can consider using divide and conquer method, only a few items at a time, many times, and ultimately achieve the goal of processing the entire LRU queue. However, LRU queues are linked lists and do not support random access. Processing an item in the middle of the queue requires sequential access from the head or tail of the list, with time complexity of O(n).
Pseudo item:
memcached uses a clever method to achieve random access. It inserts a pseudo-item at the end of the LRU queue, and then drives the pseudo-item to the head of the queue, one at a time.
This pseudoitem is a global variable, and LRU crawler threads can access the pseudoitem directly without traversing the head or tail of the LRU queue. With the next and prev pointers of this pseudoitem, you can access the real item. Thus, the LRU crawler thread can directly access an item in the middle of the LRU queue without traversing it.
Let's look at the lru_crawler_crawl function, where memcached inserts pseudoitems into the end of the LRU queue. This function is called when the worker thread receives the lru_crawler crawl < classid, classid, CLassID | all > command. Because users may require LRU crawler threads to clean up expired items from multiple LRU queues, a pseudo-item array is required. The size of pseudoitem arrays is equal to the number of LRU queues, and they correspond one to one.
Now let's look at how pseudo-item moves forward in the LRU queue. Let's first look at a pseudo-item forward diagram.
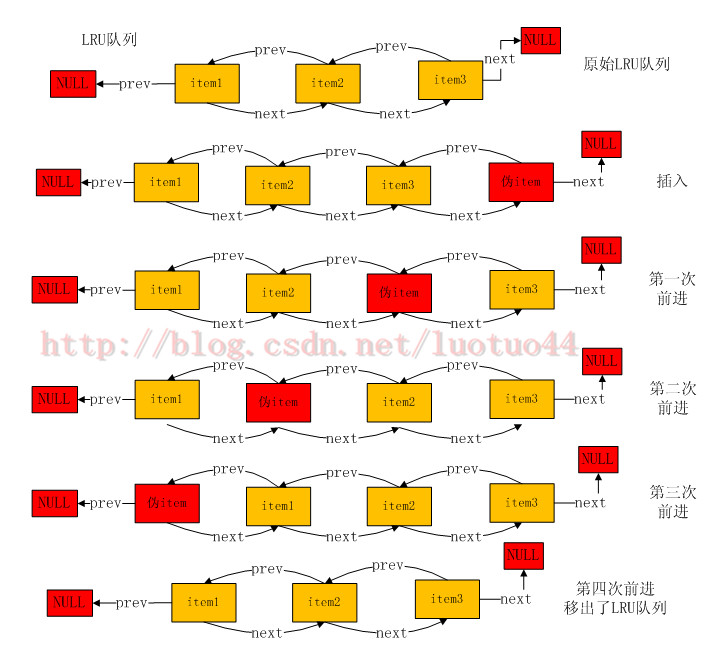
As can be seen from the figure above, pseudoitem advances by exchanging positions with the precursor nodes. If the pseudoitem is the head node of the LRU queue, then move the pseudoitem out of the LRU queue. The function crawler_crawl_q completes this exchange operation and returns the precursor node of the pseudo item before the exchange (which, of course, becomes the precursor node of the pseudo item after the exchange). If the pseudoitem is at the head of the LRU queue, it returns to NULL (there are no precursor nodes at this time). The pointers in the crawler_crawl_q function are flying all over the sky, so no code is posted here.
The above figure, although pseudoitem traverses the LRU queue, does not delete an item. The first is to look good, and the second is to traverse the LRU queue without necessarily deleting items (items will not be deleted if they expire).
Clean up item:
As mentioned earlier, the command lru_crawler to crawl num can be used to specify that each LRU queue can only check num-1 items at most. Look clearly, it's the number of checks, not deletions, and it's num-1. First, call the item_crawler_evaluate function to check if an item is expired, and if so, delete it. If the num-1 is checked and the pseudo-item has not reached the head of the LRU queue, then the pseudo-item is deleted from the LRU queue directly. Let's look at the item_crawler_thread function.
Real LRU phasing out:
Although the word LRU has been used many times before in this article, the function names in memcached code also use the LRU prefix, especially the lru_crawler command. But in fact, it has nothing to do with the elimination of LRU!!
Be deceived and scold: & & *%... %%,%... #%@%...
Readers can recall operating system LRU inside algorithm . The item s deleted in this article are expired and should have been deleted. Overdue still dominate the position, a bit like the Mao pit not shit. The LRU algorithm in the operating system is kicked because of insufficient resources, and the kicked is helpless. It's not the same, so it's not LRU.
Where does the RU of memcached reflect? do_item_alloc function!! Previous blogs have always mentioned this godlike function, but never given a complete version. Of course, the full version will not be given here. Because there are still some things in this function that can't be explained to readers for the time being. Now it is estimated that readers will appreciate it.< How to read memcached source code > Written in: There is too much correlation between memcached modules.