spark shell is only used to test and validate our programs. In production environment, programs are usually programmed in IDE, then packaged into jar packages and submitted to the cluster. The most commonly used method is to create a Maven project to manage the dependencies of jar packages by Maven. First, edit Maven project on IDEA, fill in wordcount code in src of maven project, run on xshell (need to connect cluster nodes). Because wordcount program needs txt document, it also involves some basic operations on hdfs.
I. Writing the spark Program of maven (WordCount) on IDEA
1. New maven project, fill in GroupId, ArtifactId(groupid (company name + person name + project name) artifactid (project name), jar package with maven, the package name is the project in artifactid)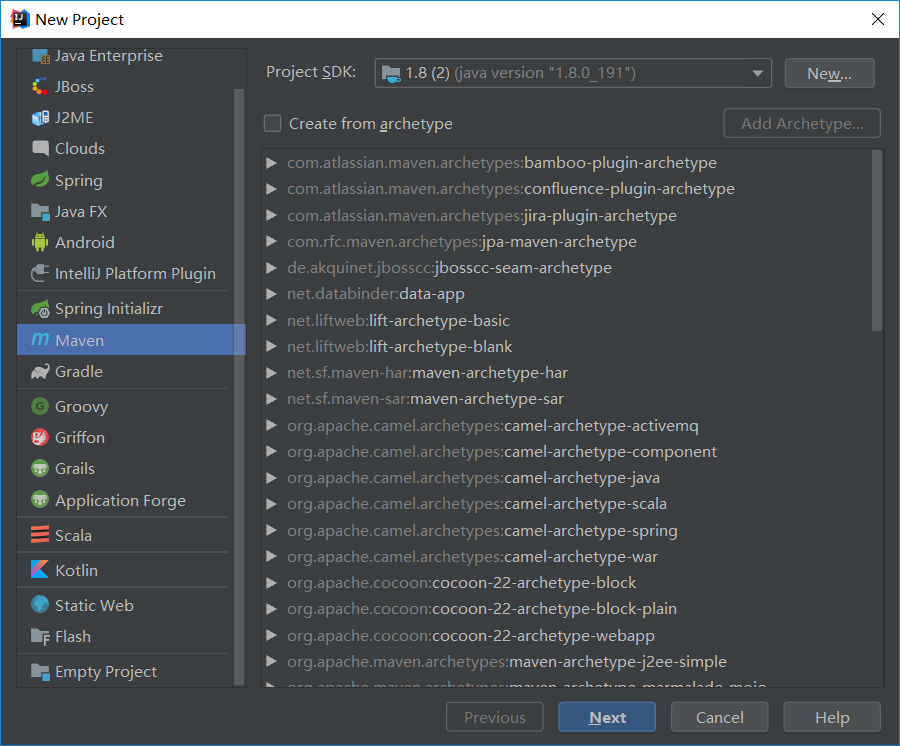
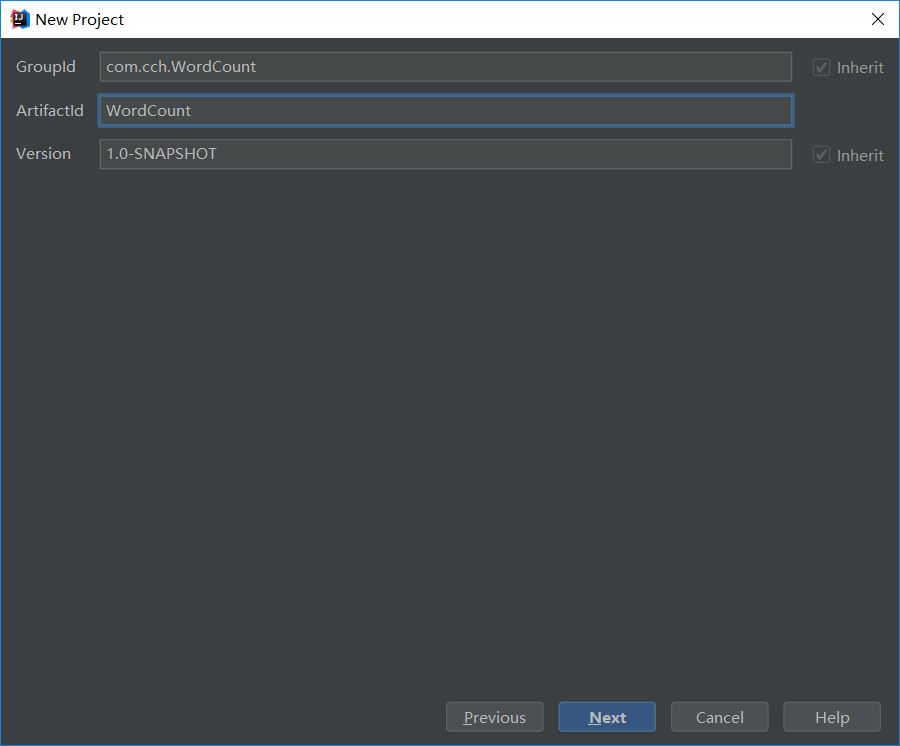
2. Copy the following program in Maven's pom.xml file
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.cai</groupId>
<artifactId>wordcount1</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.10.6</scala.version>
<scala.compat.version>2.10</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.cch.WordCount.wordcount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Note: After configuring pom.xml, click Enable Auto-Import. Hole to see if your hadoop version (mine is 2.6.9) matches the above pom.xml and changes the location accordingly.
3. Modify src/main/java and src/test/java to src/main/scala and src/test/scala respectively, which are consistent with the configuration in pom.xml ();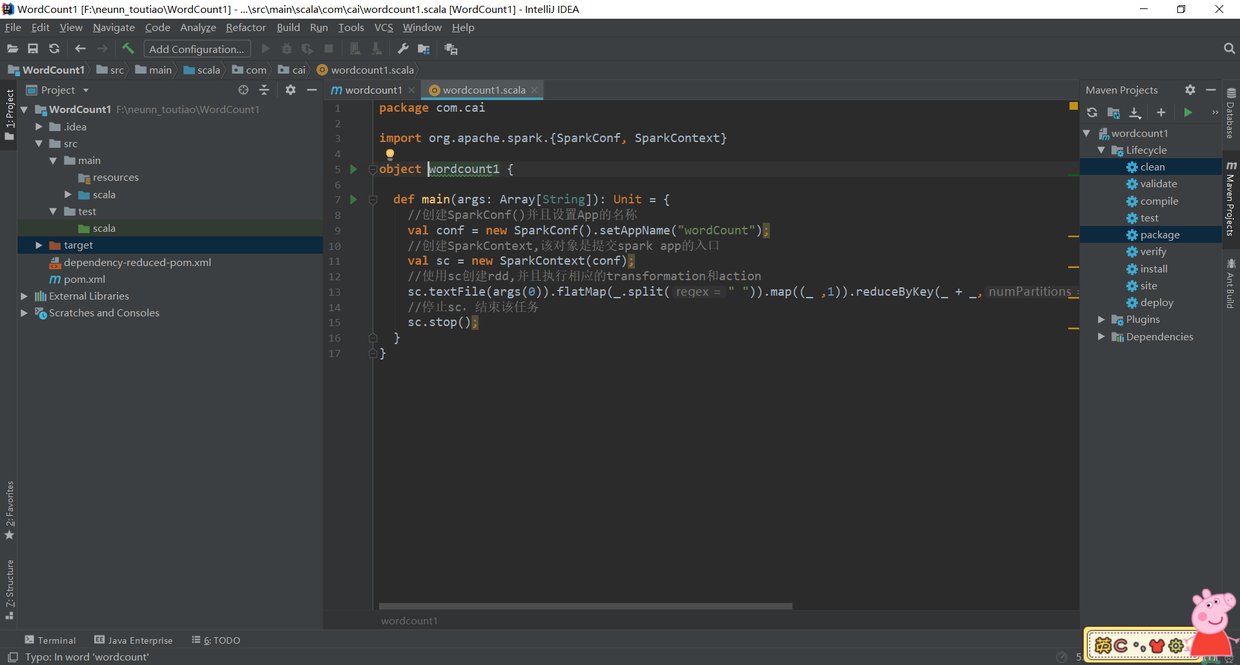
4. Packing with Maven: Firstly, modify the program entry in pom.xml to correspond to its own program. The program entry in this paper is com.cai.wordcount1. Then click the Maven Project option on the right side of idea, click Lifecycle, select clean and package, and click RUN: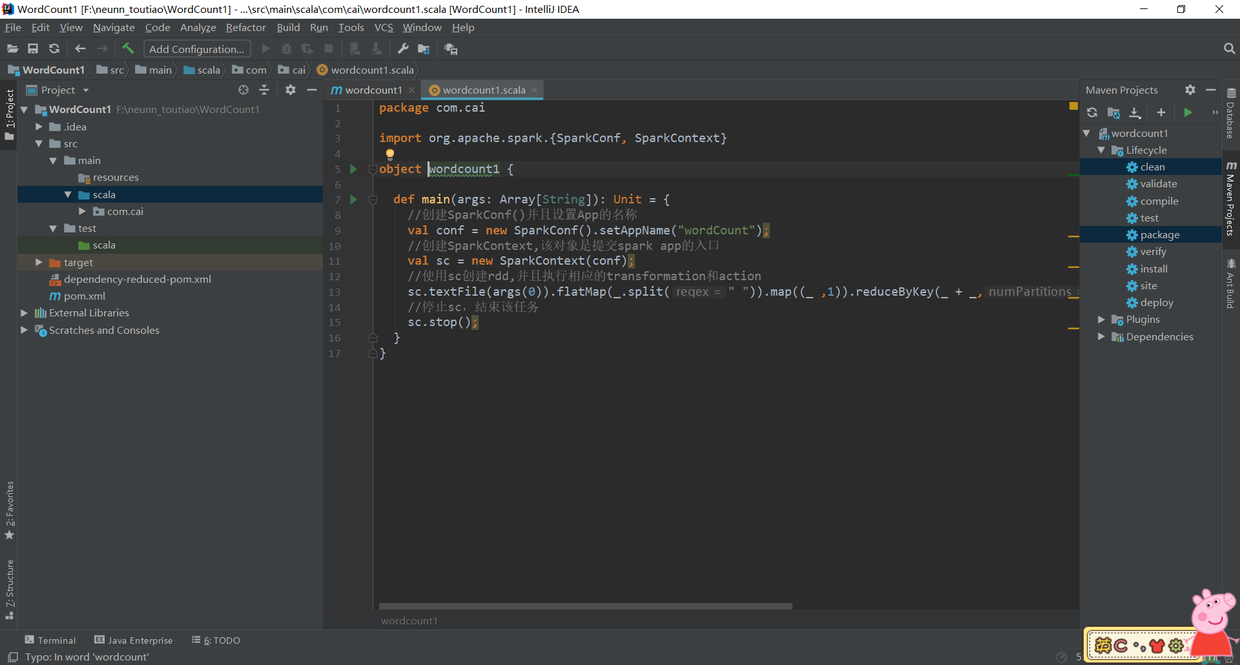
The program in the figure is the wordcountspark source code.
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//Create SparkConf() and set the name of App
val conf = new SparkConf().setAppName("wordCount");
//Create SparkContext, which is the entry to submit spark app
val sc = new SparkContext(conf);
//Create rdd with sc and execute corresponding transformation s and action s
sc.textFile(args(0)).flatMap(_.split(" ")).map((_ ,1)).reduceByKey(_ + _,1).sortBy(_._2,false).saveAsTextFile(args(1));
//Stop sc and end the task
sc.stop();
}
}
5. Waiting for compilation to complete, select the jar package that compiled successfully and upload the change jar to a node in the Spark cluster. The jar package is wordcount 1-1.0-SNAPSHOT.jar in the target on the left side of the image above.
2. Upload to spark Cluster and run the program. It needs xshell and xftp tools (download well on the official website first).
1. Open the Xshell - > New - > Fill in the host address of the link - > Enter the username and password after the new one, and establish the connection (link your own computer and the computer of the linux system on your server through the xshell).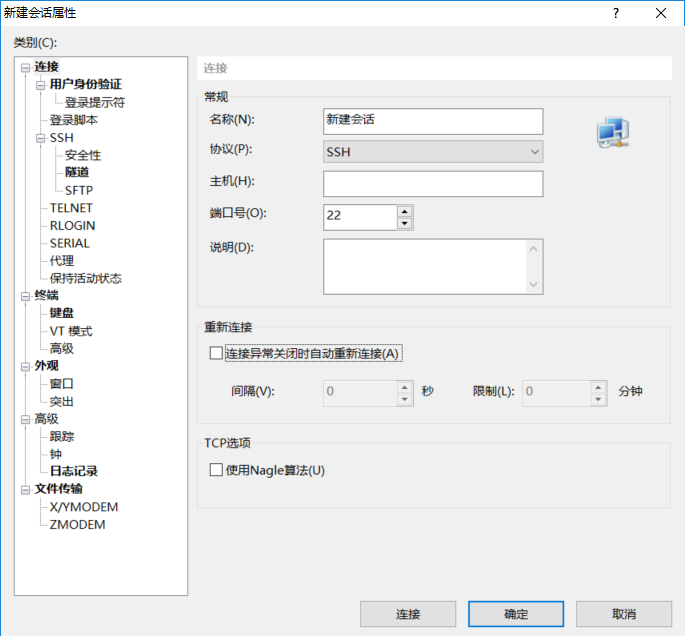
2. Using xftp, xftp is a tool for transferring local files to remote Linux systems. It is as follows: uploading jar packages and WordCount.txt can be realized by dragging them right to / home/hdfs (self-built folders).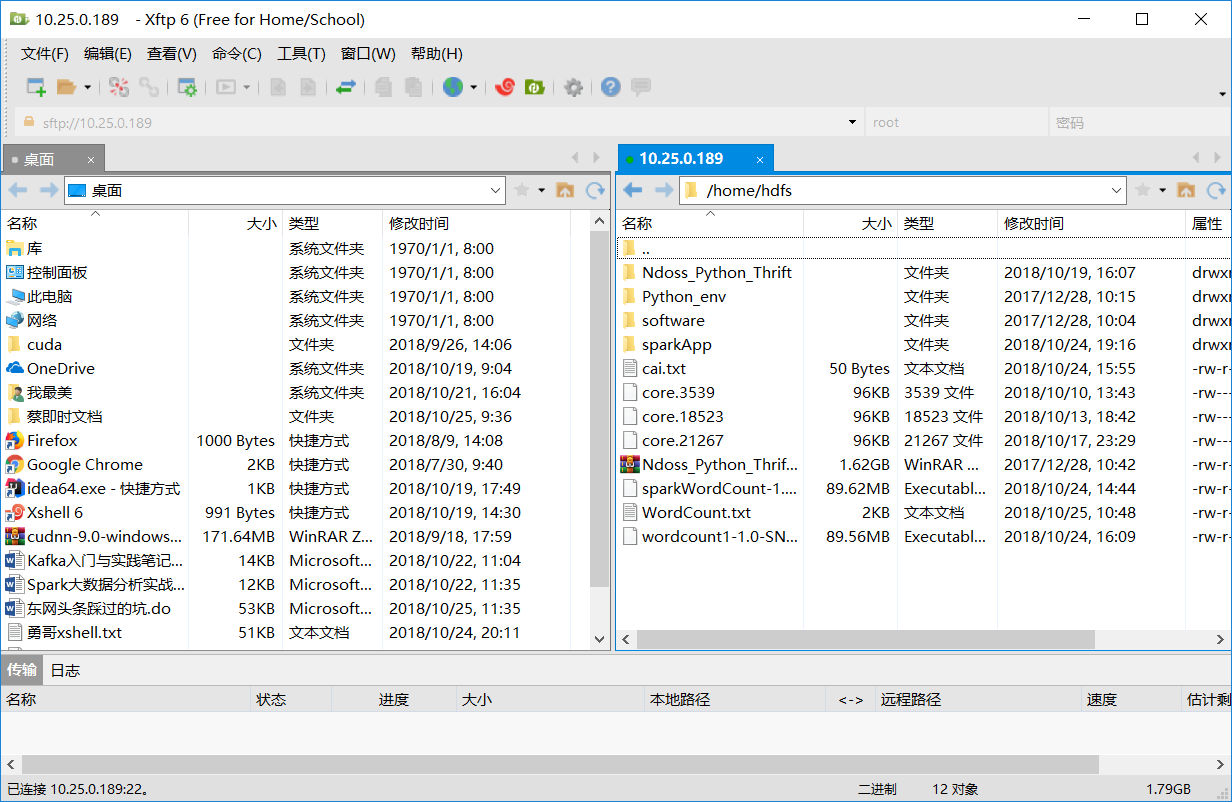
Because our program needs to count the number of words in WordCount document and write a WordCount.txt program in advance for statistics. This paper wants to achieve distributed storage, so we need to upload WordCount.txt to hdfs in distributed file storage system. The specific code is as follows:
[root@data6 ~]# su hdfs // switch to hdfs user (root user has no permission) [hdfs@data6 root]$ cd /home/hdfs/software/hadoop/bin //Switch to the bin directory in hadoop, because the bin folder of Hadoop is the interface for hdfs operation, so that hdfs can be operated on [hdfs@data6 bin]$ ./hadoop fs -mkdir /inn //Create an inn directory on the hdfs system that we can't see [hdfs@data6 bin]$ ./hadoop fs -ls / //View the directory created
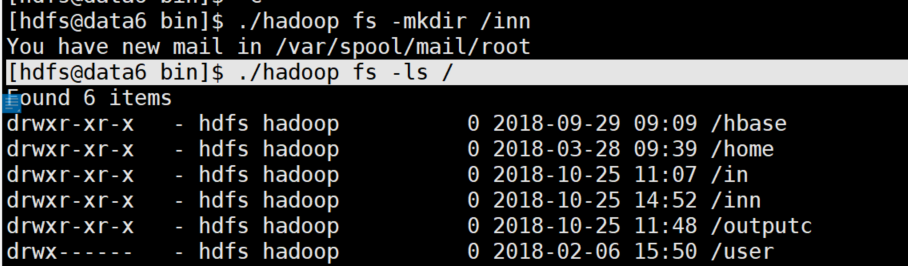
You can see from the picture that the inn folder already exists in the hdfs system
[hdfs@data6 bin]$ ./hadoop fs -put /home/hdfs/WordCount.txt /inn //Upload the WordCount.txt file from hdfs in the local folder home to the inn directory
 Now that the required documents are submitted, all you need to do is run the jar package
Now that the required documents are submitted, all you need to do is run the jar package
jar Wrapped in/home/hdfs Under the directory, so first return the current directory to the personal user directory [hdfs@data6 /]$ cd ~ //With this command, the following command line becomes [hdfs@data6 ~]$, representing the individual user in HDFS [hdfs@data6 ~]$ /home/hdfs/software/spark/bin/spark-submit --class com.bie.WordCount sparkWordCount-1.0-SNAPSHOT.jar hdfs://#########:9000/inn/WordCount.txt hdfs://#######:9000/outputc
The last command explains that because of the spark cluster, it is first entered (in the bin folder of spark / home/hdfs/software/spark/bin /)+ (spark-submit command) +(- class, which means the entry of this program, which is com.bie.WordCount) + (jar package name).
+ (WordCount.txt location, in our cluster inn folder)+ (here is the location of the results, if not, it will directly create a new directory output c), if run successfully, it will directly display the next command.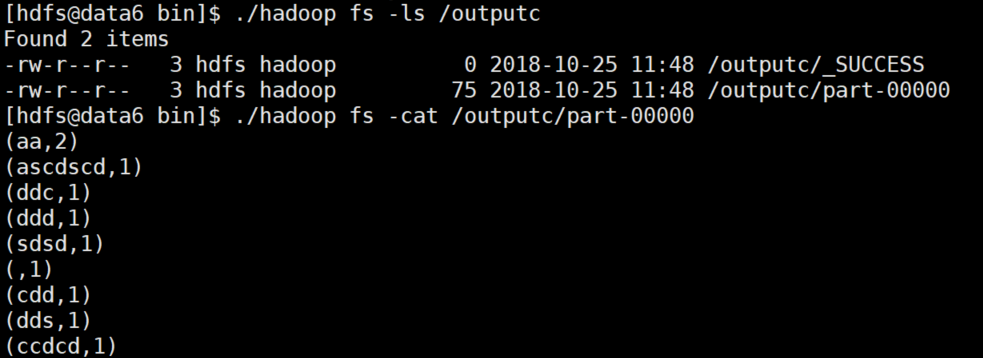
Look at the results directory output c, and see the contents of the part-00000 results file under the directory, and it's done with great success.
Original works. No reprinting!!!