Why use distributed Crawlers
- It's been a while since learning crawlers were implemented in a python file, without considering performance, efficiency, etc. So as a qualified spider, we need to learn about distributed crawlers.
- What distributed crawler? In short, it is to use multiple servers to get data, let these servers cooperate and assign their own tasks.
Distributed crawler design
One of the most commonly used is the master-slave distributed crawler. In this paper, Redis server will be used as the task queue.
As shown in the picture: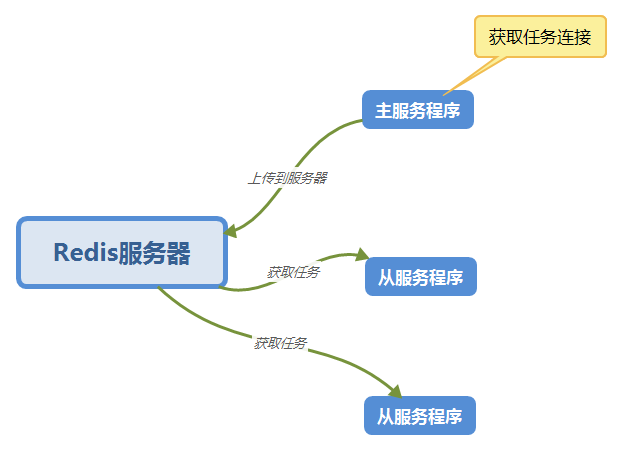
Preparation
- Install python3 and Redis
- Install requests and Redis related libraries
pip install requests pip install pyquery pip install redis
Code
Main function (main.py)
import os
import requests
from pyquery import PyQuery as pq
import re
import json
import config
from cache import RedisCache
from model import Task
def parse_link(div):
'''
//Get connection
'''
e = pq(div)
href = e.find('a').attr('href')
return href
def get_from_url(url):
'''
//Get list connection
'''
page = get_page(url)
e = pq(page)
items = e('.epiItem.video')
links = [parse_link(i) for i in items]
print(len(links))
links.reverse()
return links
def get_page(url):
'''
//Get pages
'''
proxies = config.proxies
try:
res = requests.get(url,proxies=proxies)
# print(res.text)
except requests.exceptions.ConnectionError as e:
print('Error',e.args)
page = res.content
return page
def get_all_file(path, fileList=[]):
'''
//Get all files in the directory
'''
get_dir = os.listdir(path) #Traverse the current directory to get the file list
for i in get_dir:
sub_dir = os.path.join(path,i) # Add the file obtained in the first step to the path
# print(sub_dir)
if os.path.isdir(sub_dir): #If it is still a folder, call recursively
get_all_file(sub_dir, fileList)
else:
ax = os.path.abspath(sub_dir) #If the current path is not a folder, put the filename in the list
# print(ax)
fileList.append(ax)
return fileList
def init_finish_task(path):
'''
//Initialize completed tasks
'''
redis_cache = RedisCache()
fileList = []
fileList = get_all_file(path, fileList)
# print(fileList)
for file in fileList:
file_name = os.path.basename(file)
task_id = file_name[:5]
# print(task_id)
redis_cache.sadd('Task:finish', task_id)
print('init_finish_task...end')
def init_task_url():
'''
//Initialize finished task url
'''
redis_cache = RedisCache()
url = config.list_url
link_list = get_from_url(url)
for link in link_list:
task_url = config.task_url_head+link
# print(task_url)
task_id = task_url[-5:]
# redis_cache.set('Task:id:{}:url'.format(task_id),task_url)
t = task_from_url(task_url)
# print('add task {}'.format(t.__dict__))
print('add task_id {}'.format(task_id))
redis_cache.set('Task:id:{}'.format(task_id), t.__dict__)
# print(t)
print('init_task_url...end')
def task_from_url(task_url):
'''
//Getting tasks
'''
page = get_page(task_url)
e = pq(page)
task_id = task_url[-5:]
title = e('.controlBar').find('.epi-title').text().replace('/', '-').replace(':',': ')
file_url = e('.audioplayer').find('audio').attr('src')
ext = file_url[-4:]
file_name = task_id+'.'+title+ext
# content = e('.epi-description').html()
t = Task()
t.id = task_id
t.title = title
t.url = task_url
t.file_name = file_name
t.file_url = file_url
# t.content = content
return t
def main():
init_task_url()
init_finish_task(config.down_folder)
if __name__ == '__main__':
main()Slave function (salver.py)
import os
import requests
from pyquery import PyQuery as pq
import re
import json
import config
from cache import RedisCache
def get_page(url):
'''
//Get pages
'''
proxies = config.proxies
try:
res = requests.get(url,proxies=proxies)
# print(res.text)
except requests.exceptions.ConnectionError as e:
print('Error',e.args)
page = res.content
return page
def begin_task(task_id, file_name, file_url):
print('begin task {}'.format(task_id))
redis_cache = RedisCache()
# Add to downloading list
redis_cache.sadd('Task:begin', task_id)
print('download...{}'.format(file_name))
folder = config.down_folder
path = os.path.join(folder, file_name)
download(file_url, path)
print('end task {}'.format(task_id))
def download(link, path):
redis_cache = RedisCache()
proxies = config.proxies
if os.path.exists(path):
print('file exist')
else:
try:
r = requests.get(link,proxies=proxies,stream=True)
total_length = int(r.headers['Content-Length'])
with open(path, "wb") as code:
code.write(r.content)
# Is the document complete
length = os.path.getsize(path)
print('length={}'.format(length))
print('total_length={}'.format(total_length))
if total_length != length:
# Delete old files
os.remove(path)
# Re Download
download(path, link)
else:
print('download success')
# Add to downloaded
file_name = os.path.basename(path)
content_id = file_name[:5]
redis_cache.srem('Task:begin', content_id)
redis_cache.sadd('Task:finish', content_id)
# print(r.text)
except requests.exceptions.ConnectionError as e:
print('Error',e.args)
def main():
redis_cache = RedisCache()
# Check if the task list is in the downloaded list
keys = redis_cache.keys('Task:id:[0-9]*')
# print(keys)
new_key = [key.decode() for key in keys]
# print(new_key)
# Sort by id
new_key = sorted(new_key,key = lambda i:int(i.split(':')[2]))
# print(new_key)
for key in new_key:
task_id = key.split(':')[2]
# print(task_id)
is_finish = redis_cache.sismember('Task:finish', task_id)
is_begin = redis_cache.sismember('Task:begin', task_id)
if is_finish==1:
print('Task {} is finish'.format(task_id))
elif is_begin==1:
print('Task {} is begin'.format(task_id))
else:
file_name = json.loads(redis_cache.get(key).decode('utf-8').replace("\'", "\""))['file_name']
file_url = json.loads(redis_cache.get(key).decode('utf-8').replace("\'", "\""))['file_url']
# print(file_url)
begin_task(task_id, file_name, file_url)
if __name__ == '__main__':
main()