Catalog
2. Writing Code + Packaging Project in intellij idea
3. Upload jar package to Linux in xftp
4. Preparing input data + Running jar package + Viewing input results in hadoop
1. Problem Description
With MapReduce, for each user, A suggests 10 users who are not friends with A, but have the most common friends with A.
Input:
The input file contains an adjacency list with multiple lines in the list, each in the following format
0 1,2,3,...
Here, "0" is the unique integer ID, corresponding to the unique user, and "1,2,3..." is a comma-separated list of unique IDs, corresponding to friends of users with unique IDs. Note that these friends are mutual (that is, they are undirected): if A is a friend of B, then B is also a friend of A.
Output:
Output results to a txt file, which should contain one line per user, each in the following format
1 2,4,5,10,...
Among them, "1" is the unique ID corresponding to the user, "2,4,5,10,..." is a comma-separated list of unique IDs corresponding to the number of people the algorithm's recommendation may know, ranking the number of common friends in decreasing order.
2. Writing Code + Packaging Project in intellij idea
1. Create Project
2. Importing jar packages
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<name>hadoop</name>
<!-- FIXME change it to the project's website -->
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
</project>3. Write MR code
(Project structure)
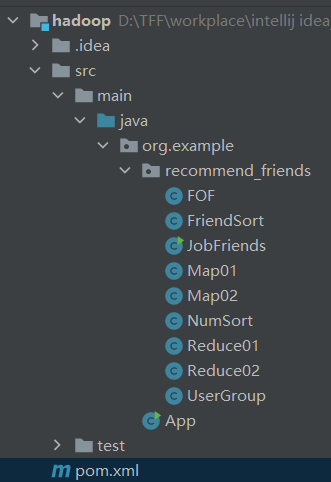
(FOF)
Type Definition Since A:B and B:A are the same list of potential friends, for easy statistics, they are sorted by dictionary and output in A:B format.
package org.example.recommend_friends;
import org.apache.hadoop.io.Text;
public class FOF extends Text {
public FOF(){
super();
}
public FOF(String friend01,String friend02){
set(getof(friend01,friend02));
}
private String getof(String friend01,String friend02){
int c = friend01.compareTo(friend02);
if(c>0){
return friend02+"\t"+friend01;
}
return friend01+"\t"+friend02;
}
}
(Map01)
package org.example.recommend_friends;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
//Mapp01, statistics of FOF relationships between friends (potential friendships)
public class Map01 extends Mapper<LongWritable,Text,FOF,IntWritable> {
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String lines = value.toString(); //List of all users'friends
String userAndFriends[] = StringUtils.split(lines,'\t');
String user = userAndFriends[0];
String[] friends;
if(userAndFriends.length == 1){
return;
}else if (userAndFriends[1].length() == 1){
friends = new String[]{userAndFriends[1]};
}else{
friends = userAndFriends[1].split(",");
}
//FOF Relationship Matrix Between Friends
for(int i=0;i<friends.length;i++){
String friend = friends[i];
context.write(new FOF(user,friend),new IntWritable(0)); // Output Friends
for(int j=i+1;j< friends.length;j++){
String friend2 = friends[j];
context.write(new FOF(friend,friend2),new IntWritable(1));
}
}
}
}
(Reduce01)
package org.example.recommend_friends;
//import com.sun.deploy.util.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
//reduce function, counting the coefficients of all FOF relation lists
public class Reduce01 extends Reducer<FOF,IntWritable,Text,NullWritable> {
@Override
protected void reduce(FOF key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
boolean f = true;
for(IntWritable i : values){
if(0==i.get()){ //Already a friend
f = false;
break;
}
sum+=i.get(); //Cumulative, statistical FOF coefficients
}
if (f) {
String msg = StringUtils.split(key.toString(), '\t')[0]+" "+StringUtils.split(key.toString(), '\t')[1]+" "+sum;
System.out.println(msg);
context.write(new Text(msg), NullWritable.get()); //Output key is a potential friend pair, value is the number of occurrences
}
}
}
(FriendSort)
package org.example.recommend_friends;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FriendSort implements WritableComparable<FriendSort> {
private String friend;
private int hot;
public String getFriend(){
return friend;
}
public void setFriend(String friend){
this.friend = friend;
}
public int getHot(){
return hot;
}
public void setHot(int hot){
this.hot = hot;
}
public FriendSort(){
super();
}
public FriendSort(String friend,int hot){
this.hot = hot;
this.friend = friend;
}
//Deserialize
@Override
public void readFields(DataInput in) throws IOException{
this.friend = in.readUTF();
this.hot = in.readInt();
}
//serialize
@Override
public void write(DataOutput out) throws IOException{
out.writeUTF(friend);
out.writeInt(hot);
}
//Determine if it is the same user and sort by the hot value
@Override
public int compareTo(FriendSort newFriend){
int c = friend.compareTo(newFriend.getFriend());
int e = -Integer.compare(hot,newFriend.getHot());
if (c==0){
return e;
}
return c;
}
}
(Map02)
package org.example.recommend_friends;
//import com.sun.deploy.util.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
//map function, a list of recommended friends for each user, sorted by recommended index from large to small
public class Map02 extends Mapper<LongWritable,Text,FriendSort,Text> {
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String lines = value.toString();
String friend01 = StringUtils.split(lines,' ')[0];
String friend02 = StringUtils.split(lines,' ')[1]; //Recommended Friends
int hot = Integer.parseInt(StringUtils.split(lines,' ')[2]); // Recommendation factor for this recommended friend
System.out.println(friend01+" "+friend02+" "+hot);
System.out.println(friend02+" "+friend01+" "+hot);
context.write(new FriendSort(friend01,hot),new Text(friend02+":"+hot)); //mapkey Output User and Friend Recommendation Factor
context.write(new FriendSort(friend02,hot),new Text(friend01+":"+hot)); //Friends are mutual
}
}
(NumSort)
package org.example.recommend_friends;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
//Sort key s by user name and order
public class NumSort extends WritableComparator {
public NumSort(){
super(FriendSort.class,true);
}
public int compare(WritableComparable a,WritableComparable b){
FriendSort o1 = (FriendSort) a;
FriendSort o2 = (FriendSort) b;
int r =o1.getFriend().compareTo(o2.getFriend());
if(r==0){
return -Integer.compare(o1.getHot(), o2.getHot());
}
return r;
}
}
(UserGroup)
package org.example.recommend_friends;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class UserGroup extends WritableComparator {
public UserGroup(){
super(FriendSort.class,true);
}
public int compare(WritableComparable a,WritableComparable b){
FriendSort o1 =(FriendSort) a;
FriendSort o2 =(FriendSort) b;
return o1.getFriend().compareTo(o2.getFriend());
}
}
(Reduce02)
package org.example.recommend_friends;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class Reduce02 extends Reducer<FriendSort,Text,Text,Text> {
@Override
protected void reduce(FriendSort user,Iterable<Text> friends,Context context) throws IOException,InterruptedException{
String msg="";
//
for(Text friend : friends){
msg += friend.toString() +",";
}
context.write(new Text(user.getFriend()),new Text(msg));
}
}
(JobFriends)
package org.example.recommend_friends;
import com.sun.org.apache.xpath.internal.operations.Bool;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobFriends {
public static void main(String[] args){
Boolean flag = jobOne();
if(flag){
jobTwo();
}
}
//MapReduce01
private static Boolean jobOne(){
Configuration config = new Configuration();
boolean flag = false;
try {
Job job = Job.getInstance(config);
job.setJarByClass(JobFriends.class);
job.setJobName("fof one job");
job.setMapperClass(Map01.class);
job.setReducerClass(Reduce01.class);
job.setOutputKeyClass(FOF.class);
job.setOutputValueClass(IntWritable.class);
// The paths here are the paths to input and output data under the hdfs file system/txt/input.txt(input)/txt/output1.txt(intermediate result)/txt/output2.txt(output)
Path input = new Path("/txt/input.txt");
FileInputFormat.addInputPath(job, input);
Path output = new Path("/txt/output1.txt");
//Delete files if they exist for subsequent debugging
if(output.getFileSystem(config).exists(output)){
output.getFileSystem(config).delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
flag = job.waitForCompletion(true);
if(flag){
System.out.println("job1 success...");
}
}catch (Exception e){
e.printStackTrace();
}
return flag;
}
private static Boolean jobTwo(){
Configuration config = new Configuration();
Boolean flag = false;
try {
Job job = Job.getInstance(config);
job.setJarByClass(JobFriends.class);
job.setJobName("fof two job");
job.setMapperClass(Map02.class);
job.setReducerClass(Reduce02.class);
job.setSortComparatorClass(NumSort.class);
job.setGroupingComparatorClass(UserGroup.class);
job.setMapOutputKeyClass(FriendSort.class);
job.setMapOutputValueClass(Text.class);
Path input = new Path("/txt/output1.txt");
FileInputFormat.addInputPath(job, input);
Path output = new Path("/txt/output2.txt");
//Delete files if they exist for subsequent debugging
if(output.getFileSystem(config).exists(output)){
output.getFileSystem(config).delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
flag = job.waitForCompletion(true);
if(flag){
System.out.println("job2 success...");
}
}catch (Exception e){
e.printStackTrace();
};
return flag;
}
}
(App)
Comment out the main method, or delete the App class directly
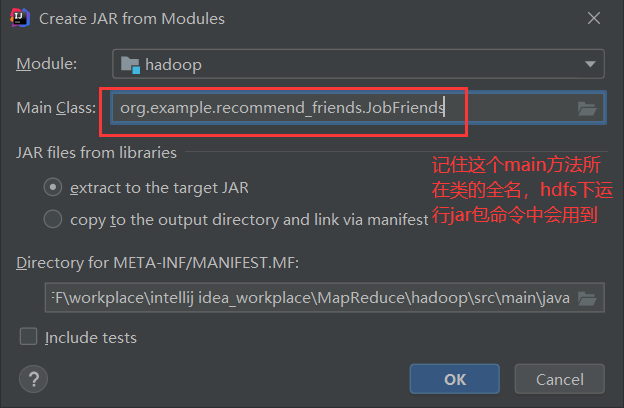
4. Packaging Project
Project Right Click Open Module Settings Artifacts
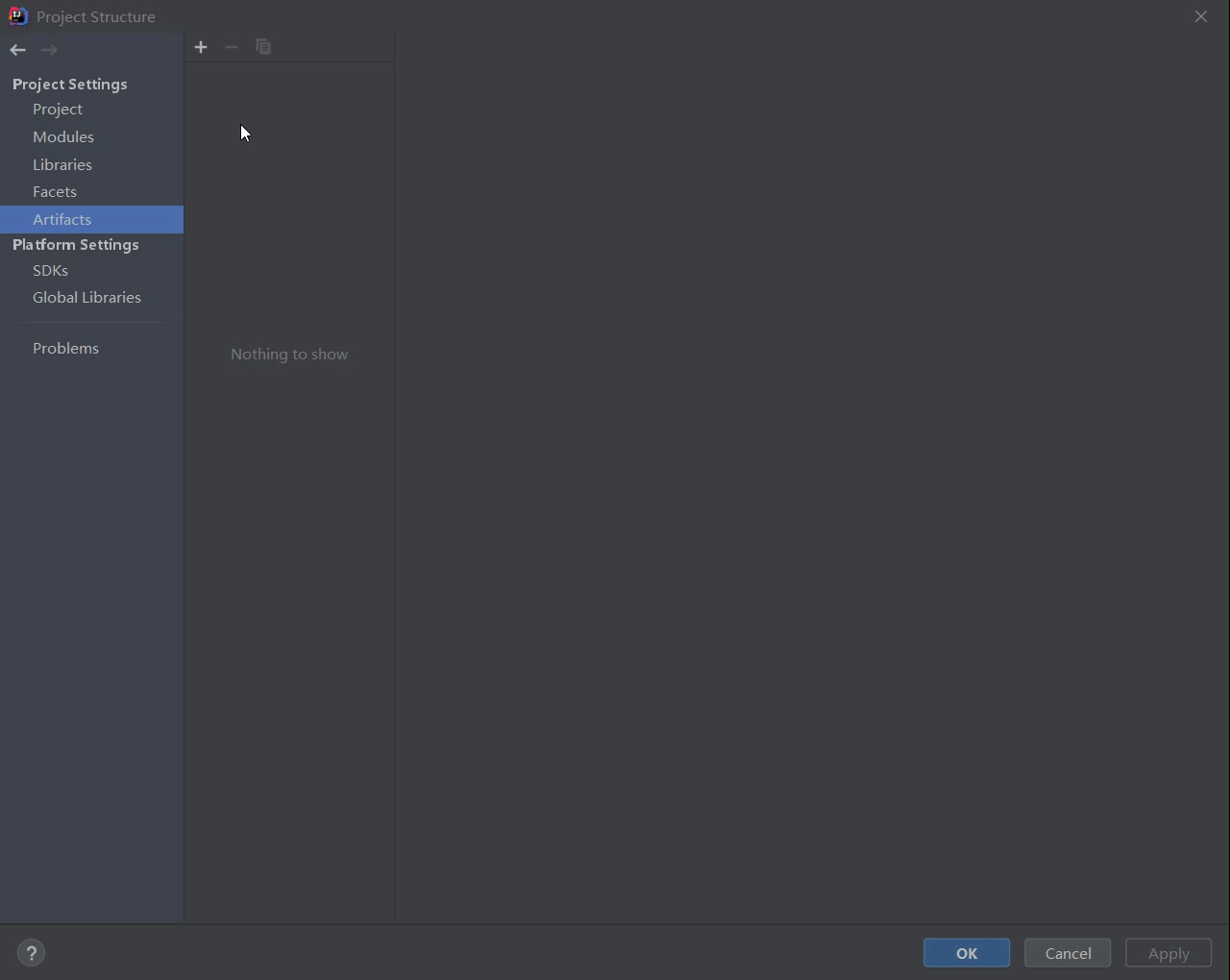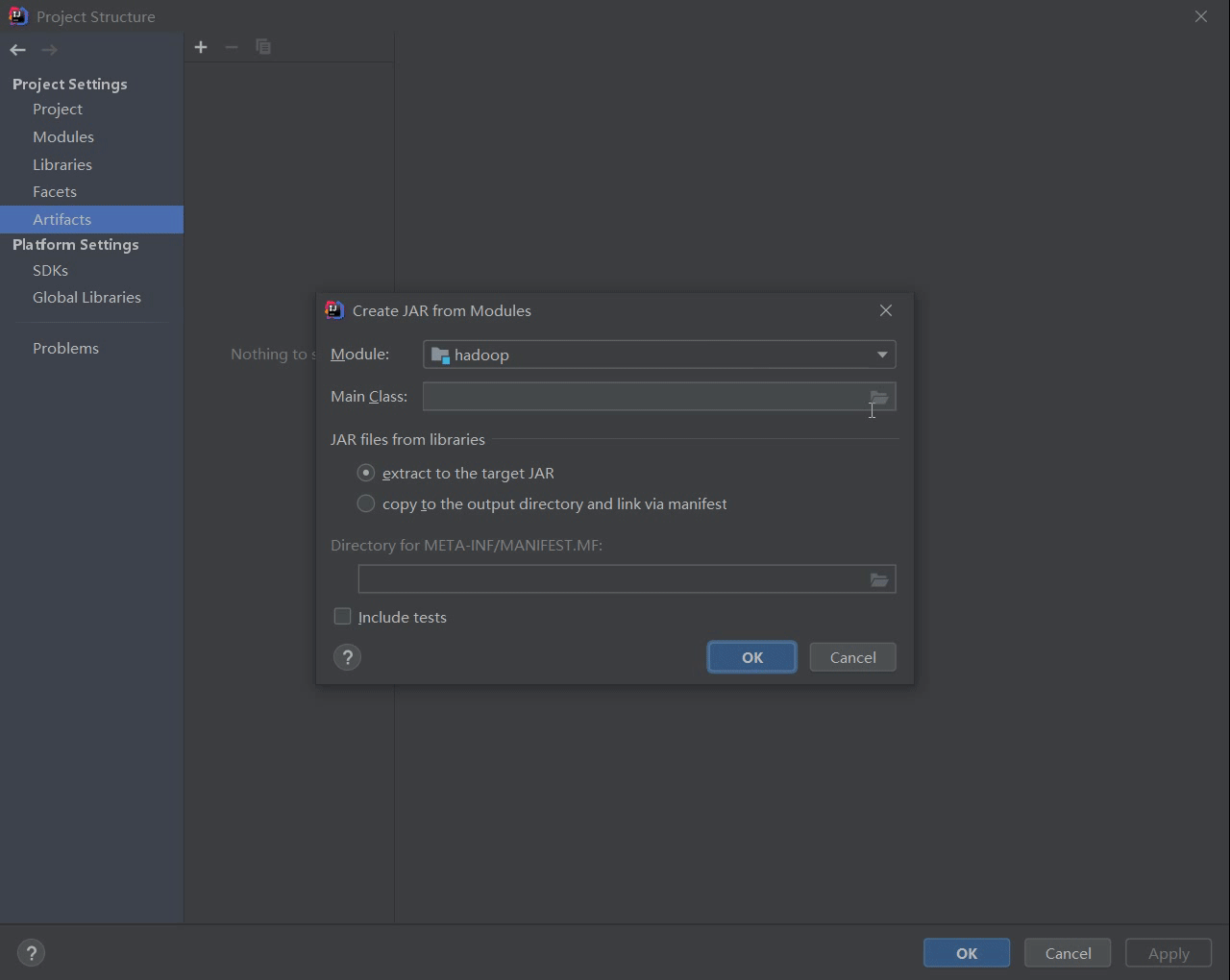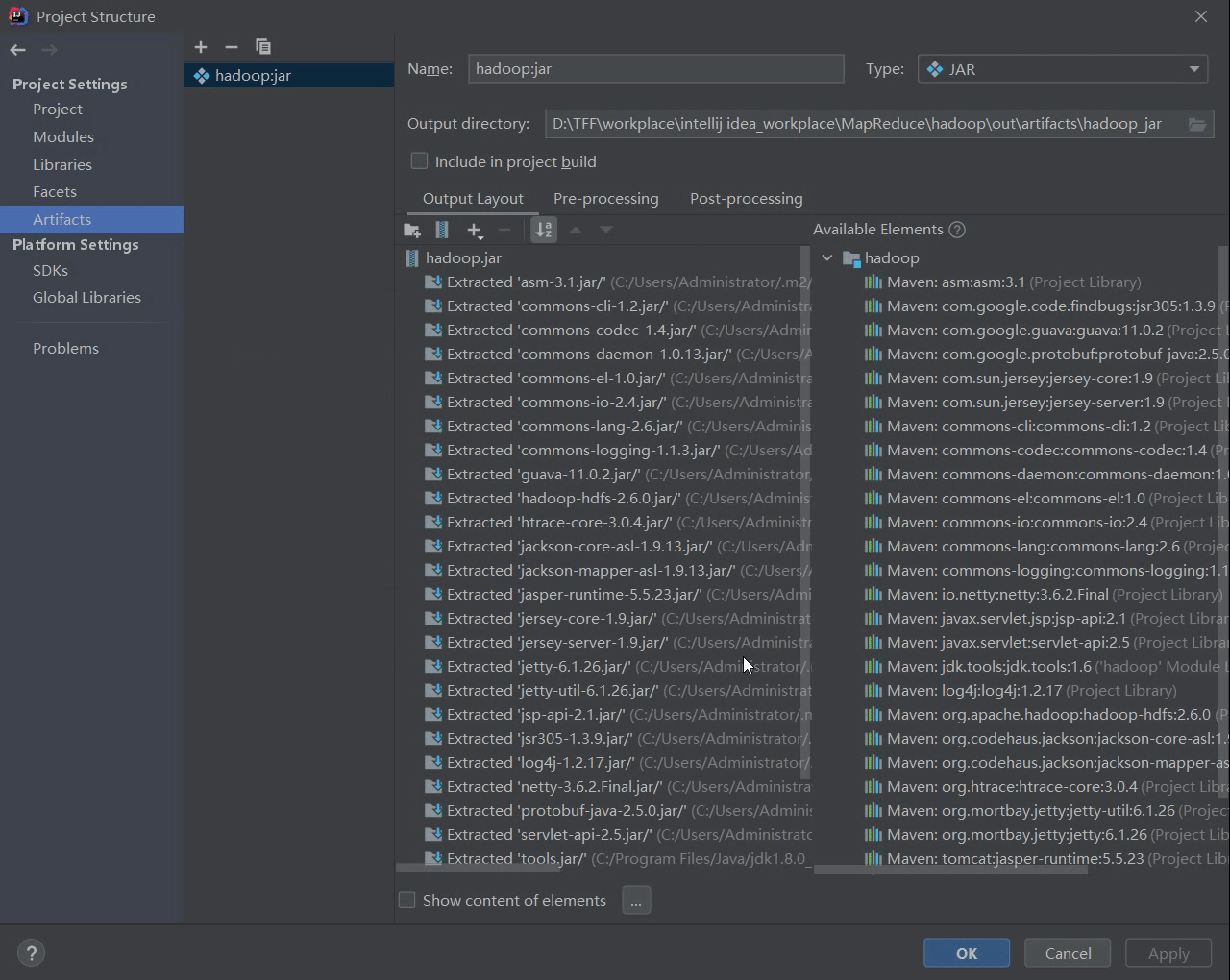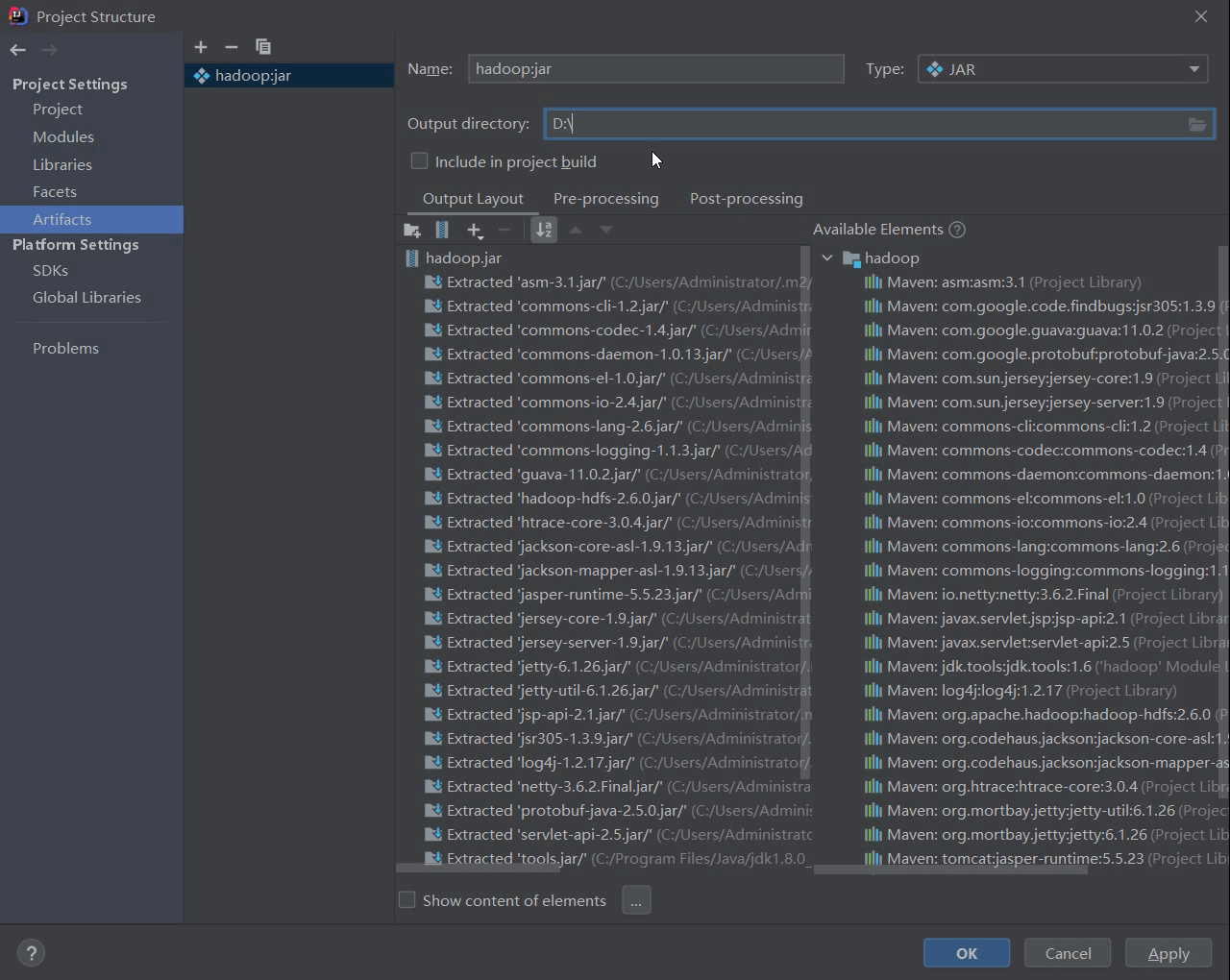
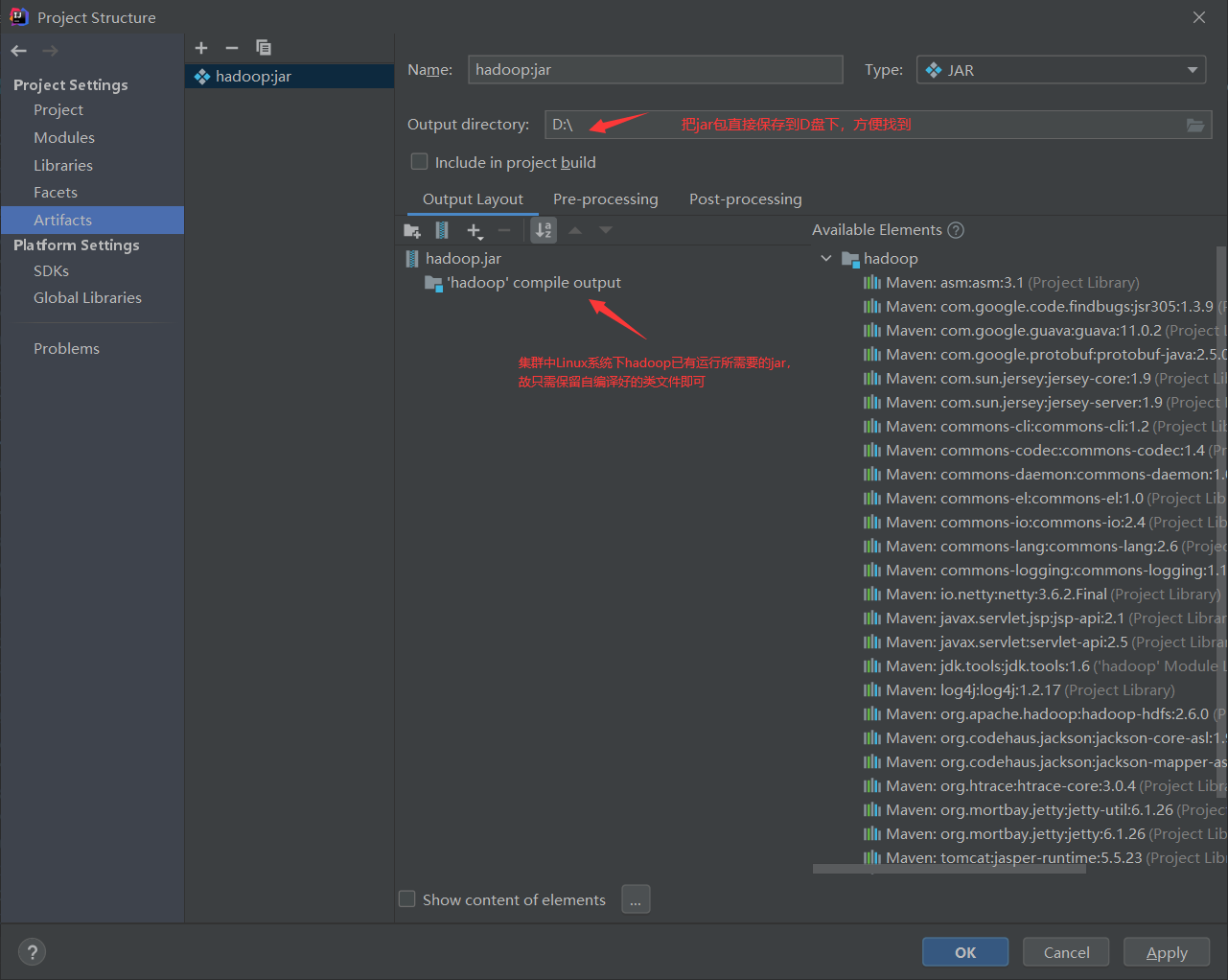
Click OK, then
 ps:
ps:
3. Upload jar package to Linux in xftp
Upload packaged jar s to Linux via xftp
4. Preparing input data + Running jar package + Viewing input results in hadoop
1. Preparing to enter data
Download Data Source

Modify txt file name

Upload input.txt from local to hdfs file system
2. Run jar package

3. View the output
output1.txt (intermediate result of initial data via one MR) and output2.txt (final result of intermediate result via one MR) were added to the / TXT file.

View output1.txt, output2.txt, respectively


This completes the second degree Friend Recommendation using MapReduce algorithm in Hadoop2.6.0+Linux Centos7+idea environment.
Reference Blog:
Summer of running MapReduce case WordCount-Residue with Hadoop2.6.0 under CentOS 7.6