Article directory
1. Preface
By default, Map will sort keys automatically, but sometimes it needs to sort keys as well as value s, which is called quadratic sorting.
2. Demand analysis
Assuming that there are two columns in each row, the separator between columns is a tab (" t"), and the output is first arranged in ascending order of the first field. If the value of the first column is equal, the output is arranged in ascending order of the second field.
Take a chestnut:
3 1
3 5
1 3
1 2
2 1
5 1
1 1
3 3
If the above data is the same, the result of the second sorting should be as follows:
1 1
1 2
1 3
------
2 1
------
3 1
3 3
3 5
------
5 1
3. The Realization Principle of Quadratic Sorting
- Mapper task receives input fragments, and then calls map function constantly to process the read data. After processing, it converts to a new key value pair for output, where the new key value pair is: key = < 1, 1 >, value = 1.
- The partition function is called for the key pair output by map function, and the data is partitioned. Data from different partitions is sent to different Reducer tasks.
- Data in different partitions is sorted by key, where the key must implement the Writable Comparable interface. This interface implements the Comparable interface, so it can be compared and sorted.
- For sorted < key, value >, groups are grouped according to key. If the keys are the same, then the < key, value > of the same keys is grouped into a group. Finally, each group calls the reduce function once.
- The sorted and grouped data is sent to the Reducer node.
4. Upload files
All at once:
Upload files:
hadoop fs -put secondsort /secondsort
5. Code Implementation
Class MyKey:
package com.mapreduce.secondarysort; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class MyKey implements WritableComparable<MyKey> { private int first = 0; private int second = 0; public void set(int first, int second){ this.first = first; this.second = second; } public int getFirst() { return first; } public int getSecond() { return second; } //This is the key to comparison, and the compareTo() method is called by default when comparing keys. @Override public int compareTo(MyKey o) { if(first != o.first){ return first - o.first; }else if(second != o.second){ return second - o.second; }else{ return 0; } } @Override public void write(DataOutput out) throws IOException { out.writeInt(first); out.writeInt(second); } @Override public void readFields(DataInput in) throws IOException { first = in.readInt(); second = in.readInt(); } @Override public String toString(){ return "<"+ first + ", "+ second + ">"; } /* @Override public int hashCode(){ return first+"".hashCode()+second+"".hashCode(); } @Override public boolean equals(Object right){ if(right instanceof MyKey){ MyKey myKey = (MyKey)right; return myKey.first == first && myKey.second == second; }else { return false; } } */ }
MyMapper class:
package com.mapreduce.secondarysort; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class MyMapper extends Mapper<LongWritable, Text, MyKey, IntWritable> { private final MyKey key = new MyKey(); private final IntWritable value = new IntWritable(); @Override public void map(LongWritable inkey, Text invalue, Context context) throws IOException, InterruptedException{ String[] strs = invalue.toString().split("\t"); System.out.println(Integer.parseInt(strs[0])+ "\t" + Integer.parseInt(strs[1])); key.set(Integer.parseInt(strs[0]), Integer.parseInt(strs[1])); value.set(Integer.parseInt(strs[1])); System.out.println("MyMappr : "); System.out.println("key = "+ key + ", value = "+ value); context.write(key, value); } }
GroupingComparator class:
package com.mapreduce.secondarysort; import org.apache.hadoop.io.RawComparator; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.io.file.tfile.RawComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class GroupingComparator extends WritableComparator { public GroupingComparator(){super(MyKey.class, true);} @Override public int compare(WritableComparable a, WritableComparable b){ MyKey myKey = (MyKey)a; MyKey myKey1 = (MyKey)b; //If the result is 0, it is assigned to a group, and each group calls Reducer once. return myKey.getFirst() - myKey1.getFirst(); } }
MyReducer class:
package com.mapreduce.secondarysort; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MyReducer extends Reducer<MyKey, IntWritable, Text, IntWritable> { private final Text SIGN = new Text("********************"); private final Text first = new Text(); @Override public void reduce(MyKey key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{ System.out.println("Reducer : "); System.out.print("MyKey = "+key.toString() + "values = "); context.write(SIGN, null);//Grouping symbol first.set(Integer.toString(key.getFirst())); // Get the first value and pass it into the key for(IntWritable value : values){ // Values values are sorted automatically System.out.print(value+" "); context.write(first, value); } System.out.println(); } }
SecondarySortApp class:
package com.mapreduce.secondarysort; import com.mapreduce.wordcount.WordCountMapper; import com.mapreduce.wordcount.WordCountReducer; import com.mapreduce.wordcount.WordCountRunJob; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.net.URI; public class SecondarySortApp { private static final String INPUT_PATH = "hdfs://master002:9000/secondsort"; private static final String OUTPUT_PATH = "hdfs://master002:9000/outputsecondsort"; public static void main(String[] args) throws Exception{ System.setProperty("HADOOP_USER_NAME", "hadoop"); Configuration conf = new Configuration(); //Enhance code robustness final FileSystem fileSystem = FileSystem.get(URI.create(INPUT_PATH), conf); if(fileSystem.exists(new Path(OUTPUT_PATH))){ fileSystem.delete(new Path(OUTPUT_PATH), true); } Job job = Job.getInstance(conf, "SecondarySortApp"); //Main method of run jar class job.setJarByClass(SecondarySortApp.class); //Set map job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(MyKey.class); job.setMapOutputValueClass(IntWritable.class); //Set reduce job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //Set Group job.setGroupingComparatorClass(GroupingComparator.class); //Setting input format job.setInputFormatClass(TextInputFormat.class); FileInputFormat.addInputPath(job, new Path(INPUT_PATH)); //Setting output format job.setOutputFormatClass(TextOutputFormat.class); FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); //Submit job System.exit(job.waitForCompletion(true) ? 0 : 1); } }
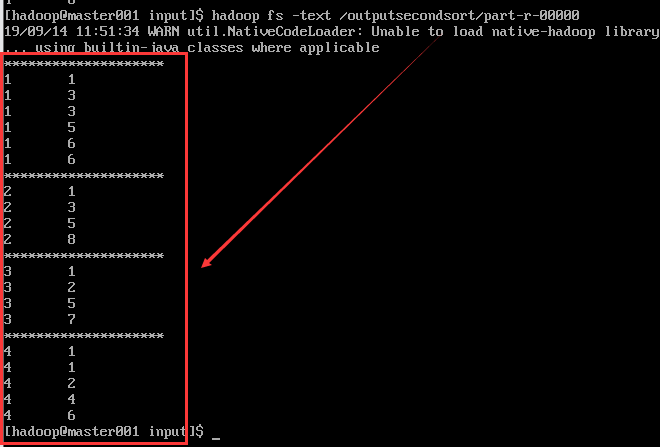
6. Effect screenshots
hadoop fs -text /outputsecondsort/part-r-00000