1, Experimental purpose
- Master the basic MapReduce programming methods through experiments;
- Master the methods to solve some common data processing problems with MapReduce, including data merging, data De duplication, data sorting and data mining.
2, Experimental platform
- Operating system: Ubuntu 18.04 (or Ubuntu 16.04)
- Hadoop version: 3.2.2
3, Experiment contents and requirements
1. Task requirements
First, we create two files locally, files A and B.
For two input files, file A and file B, please write MapReduce program to merge the two files and eliminate the duplicate contents to get A new output file C. The following is an example of an input file and an output file for reference.
Document A reads as follows:
China is my motherland I love China
Document B reads as follows:
I am from China
The program obtained by merging input files A and B shall output the results in the following form:
I 2 is 1 China 3 my 1 love 1 am 1 from 1 motherland 1
2. Write Map processing logic
The Python code for writing Map is as follows (mapper.py):
#!/usr/bin/env python3
# encoding=utf-8
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\t%s" % (word, 1))
3. Write Reduce processing logic
The Python code of Reduce is as follows (reducer.py):
#!/usr/bin/env python3
# encoding=utf-8
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\t%s" % (current_word, current_count))
current_count = count
current_word = word
if word == current_word:
print("%s\t%s" % (current_word, current_count))
4. Simple test
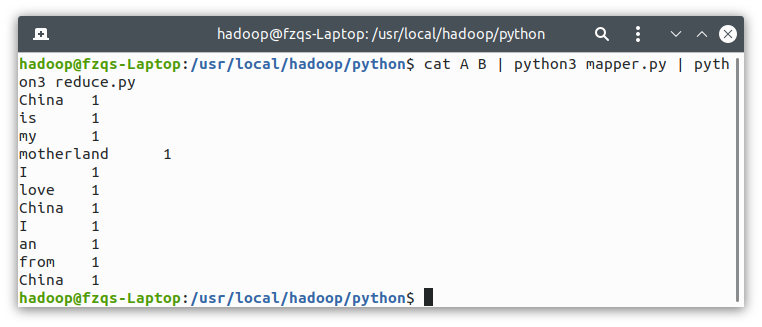
Simply test locally and run the following code:
cat A B | python3 mapper.py | python3 reducer.py
The output is as follows:
At the end of the article, I will introduce how to apply Python programs to HDFS file system.
4, Running Python programs in HDFS
Start Hadoop first:
cd /usr/local/hadoop sbin/start-dfs.sh
Create an input folder and transfer our data files (note the location of your A and B data files here):
bin/hdfs dfs -mkdir /input bin/hdfs dfs -copyFromLocal /usr/local/hadoop/MapReduce/python/A /input bin/hdfs dfs -copyFromLocal /usr/local/hadoop/MapReduce/python/B /input
Ensure that the output folder does not exist before:
bin/hdfs dfs -rm -r /output
We only need to use the Jar package provided by Hadoop to provide an interface for our Python program. The Jar package we use here is generally in this directory:
ls /usr/local/hadoop/share/hadoop/tools/lib/
Locate the package named hadoop-streaming-x.x.x.jar:
hadoop@fzqs-Laptop:/usr/local/hadoop/MapReduce/sample3$ ls /usr/local/hadoop/share/hadoop/tools/lib/
...
hadoop-streaming-3.2.2.jar
...
Call this package and pass in our local Python file as a parameter (note that my streaming package here is 3.2.2, depending on your version number):
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.2.2.jar \ -file /usr/local/hadoop/MapReduce/sample1/mapper.py -mapper /usr/local/hadoop/MapReduce/sample1/mapper.py \ -file /usr/local/hadoop/MapReduce/sample1/reducer.py -reducer /usr/local/hadoop/MapReduce/sample1/reducer.py \ -input /input/* -output /output
View our output:
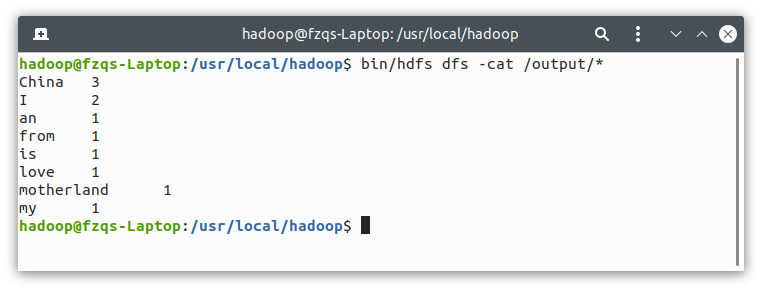
bin/hdfs dfs -cat /output/*
Correct output and successful execution: