1, Compression optimization design
When running MapReduce program, disk I/O operation, network data transmission, shuffle and merge take a lot of time, especially in the case of large data scale and intensive workload. Since disk I/O and network bandwidth are valuable resources of Hadoop, data compression is very helpful to save resources and minimize disk I/O and network transmission. If disk I/O and network bandwidth affect MapReduce job performance, enabling compression at any MapReduce stage can improve end-to-end processing time and reduce I/O and network traffic.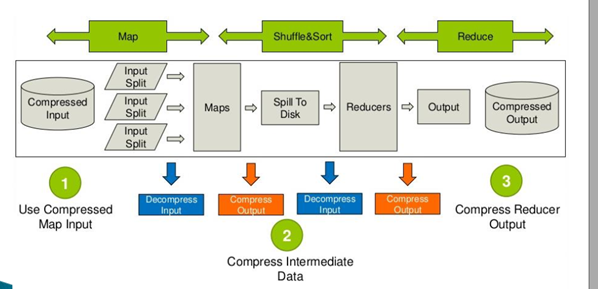
Compression is an optimization strategy of mapreduce: compress the output of mapper or reducer through compression coding,
To reduce disk IO and improve the running speed of MR program, its advantages and disadvantages are as follows:
Advantages of compression:
- Reduce file storage space
- Speed up the file transfer efficiency, so as to improve the processing speed of the system
- Reduce the number of IO reads and writes
Disadvantages of compression
- When using data, you need to decompress the file first to increase the CPU load. The more complex the compression algorithm is, the longer the decompression time is
2, Compression support
1. Check the compression algorithm supported by Hadoop: hadoop checknative
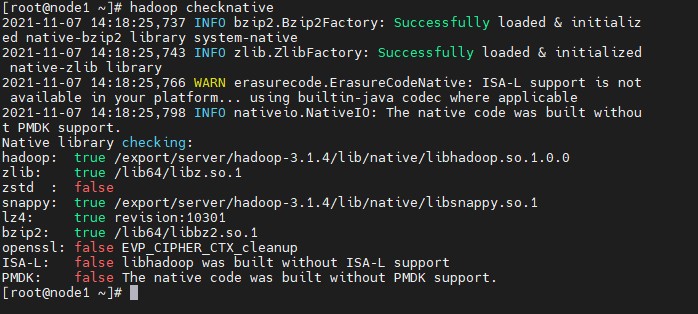
2. Compression algorithm supported by Hadoop
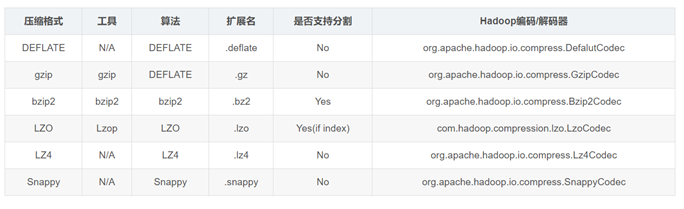
3. Comparison of compression performance of each compression algorithm
| compression algorithm | advantage | shortcoming |
|---|---|---|
| Gzip | The compression ratio is higher in the four compression modes; hadoop itself supports. Processing gzip files in an application is the same as directly processing text; hadoop native library; Most linux systems come with gzip command, which is easy to use | split is not supported |
| Lzo | The compression / decompression speed is also relatively fast and the compression rate is reasonable; Support split, which is the most popular compression format in hadoop; Support hadoop native library; The lzop command needs to be installed under linux system, which is convenient to use | The compression ratio is lower than gzip; hadoop itself is not supported and needs to be installed; lzo supports split, but the lzo file needs to be indexed. Otherwise, hadoop will treat the lzo file as an ordinary file (in order to support split, the inputformat needs to be specified as lzo format) |
| Bzip2 | Support split; It has a high compression ratio, which is higher than gzip compression ratio; hadoop itself supports, but does not support native; bzip2 command comes with linux system, which is easy to use | Slow compression / decompression speed; native is not supported |
| Snappy | Fast compression speed; Support hadoop native library | split is not supported; Low compression ratio; hadoop itself is not supported and needs to be installed; There is no corresponding command under linux system |
4. Compression ratio for data of the same size
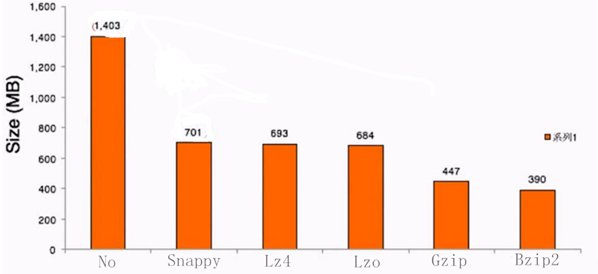
5. Compression time and decompression time
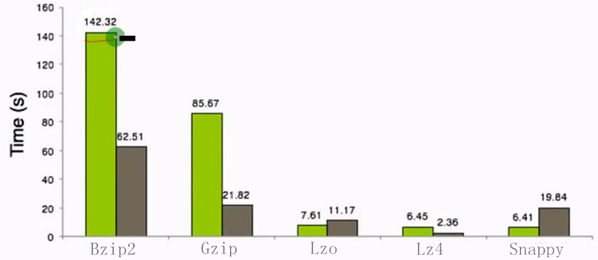
From the above comparison, it can be seen that the higher the compression ratio, the longer the compression time. The compression algorithm with medium compression ratio and compression time should be selected
3, Gzip compression
1. Generate Gzip compressed file
1. Requirements: read the ordinary text file and compress the ordinary text file into Gzip format
2. Ideas
- Input reads a normal text file
- Direct output of Map and Reduce
- Configure Output output
- Output compressed to Gzip format
3. Code implementation
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* @ClassName MRWriteGzip
* @Description TODO Read ordinary file data and compress the data in Gzip format
*/
public class MRWriteGzip extends Configured implements Tool {
//Build, configure, and submit a MapReduce Job
public int run(String[] args) throws Exception {
//Build Job
Job job = Job.getInstance(this.getConf(),this.getClass().getSimpleName());
job.setJarByClass(MRWriteGzip.class);
//Input: configuration input
Path inputPath = new Path(args[0]);
TextInputFormat.setInputPaths(job,inputPath);
//Map: configure map
job.setMapperClass(MrMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
//Reduce: configure reduce
job.setReducerClass(MrReduce.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
//Output: configure output
Path outputPath = new Path(args[1]);
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true) ? 0 : -1;
}
//Program entry, call run
public static void main(String[] args) throws Exception {
//Used to manage all configurations of the current program
Configuration conf = new Configuration();
//The configuration output results are compressed into Gzip format
conf.set("mapreduce.output.fileoutputformat.compress","true");
conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.GzipCodec");
//Call the run method to submit and run the Job
int status = ToolRunner.run(conf, new MRWriteGzip(), args);
System.exit(status);
}
/**
* Define Mapper class
*/
public static class MrMapper extends Mapper<LongWritable, Text, NullWritable, Text>{
private NullWritable outputKey = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Direct output of each data
context.write(this.outputKey,value);
}
}
/**
* Define Reduce class
*/
public static class MrReduce extends Reducer<NullWritable,
Text,NullWritable, Text> {
@Override
protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//Direct output of each data
for (Text value : values) {
context.write(key, value);
}
}
}
}
2. Read Gzip compressed file
1. Requirements: read Gzip compressed file and restore it to normal text file
2. Ideas
- Input directly reads the compression result file of the previous step
- Direct output of Map and Reduce
Output saves the results as a normal text file
3. Code development
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRReadGzip * @Description TODO Read the data in Gzip format and restore it to a normal text file */ public class MRReadGzip extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { //Build Job Job job = Job.getInstance(this.getConf(),this.getClass().getSimpleName()); job.setJarByClass(MRReadGzip.class); //Input: configuration input Path inputPath = new Path(args[0]); TextInputFormat.setInputPaths(job,inputPath); //Map: configure map job.setMapperClass(MrMapper.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); //Reduce: configure reduce job.setReducerClass(MrReduce.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); //Output: configure output Path outputPath = new Path(args[1]); TextOutputFormat.setOutputPath(job,outputPath); return job.waitForCompletion(true) ? 0 : -1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); //The configuration output results are compressed into Gzip format // conf.set("mapreduce.output.fileoutputformat.compress","true"); // conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.GzipCodec"); //Call the run method to submit and run the Job int status = ToolRunner.run(conf, new MRReadGzip(), args); System.exit(status); } /** * Define Mapper class */ public static class MrMapper extends Mapper<LongWritable, Text, NullWritable, Text>{ private NullWritable outputKey = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Direct output of each data context.write(this.outputKey,value); } } /** * Define Reduce class */ public static class MrReduce extends Reducer<NullWritable, Text,NullWritable, Text> { @Override protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //Direct output of each data for (Text value : values) { context.write(key, value); } } } }3, Snappy compression
1. Configure Hadoop to support Snappy
Hadoop supports Snappy compression algorithm and is also the most commonly used compression algorithm. However, the official compiled installation package of Hadoop does not provide Snappy support. Therefore, if you want to use Snappy compression, you must download the Hadoop source code, compile it yourself, and add Snappy support during compilation. For the specific compilation process, please refer to the Hadoop 3 compilation and installation manual.
2. Generate Snappy compressed file: Map output is not compressed
1. Requirements: read ordinary text files and convert them into Snappy compressed files
2. Ideas
- Input reads a normal text file
- Direct output of Map and Reduce
Output configures that the output is compressed to Snappy type
3. Code development
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRWriteSnappy * @Description TODO Read ordinary file data and compress the data in Snappy format */ public class MRWriteSnappy extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { //Build Job Job job = Job.getInstance(this.getConf(),this.getClass().getSimpleName()); job.setJarByClass(MRWriteSnappy.class); //Input: configuration input Path inputPath = new Path(args[0]); TextInputFormat.setInputPaths(job,inputPath); //Map: configure map job.setMapperClass(MrMapper.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); //Reduce: configure reduce job.setReducerClass(MrReduce.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); //Output: configure output Path outputPath = new Path(args[1]); TextOutputFormat.setOutputPath(job,outputPath); return job.waitForCompletion(true) ? 0 : -1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); //Configure the output results to be compressed into Snappy format conf.set("mapreduce.output.fileoutputformat.compress","true"); conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec"); //Call the run method to submit and run the Job int status = ToolRunner.run(conf, new MRWriteSnappy(), args); System.exit(status); } /** * Define Mapper class */ public static class MrMapper extends Mapper<LongWritable, Text, NullWritable, Text>{ private NullWritable outputKey = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Direct output of each data context.write(this.outputKey,value); } } /** * Define Reduce class */ public static class MrReduce extends Reducer<NullWritable, Text,NullWritable, Text> { @Override protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //Direct output of each data for (Text value : values) { context.write(key, value); } } } }
2. Generate Snappy compressed file: Map output compression
1. Requirements: read ordinary text files, convert them into Snappy compressed files, and use Snappy compression for the results output from Map
2. Idea: add the configuration of Map output compression to the code in the previous step
3. Code development
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* @ClassName MRMapOutputSnappy
* @Description TODO Read ordinary file data and compress the data output from Map in Snappy format
*/
public class MRMapOutputSnappy extends Configured implements Tool {
//Build, configure, and submit a MapReduce Job
public int run(String[] args) throws Exception {
//Build Job
Job job = Job.getInstance(this.getConf(),this.getClass().getSimpleName());
job.setJarByClass(MRMapOutputSnappy.class);
//Input: configuration input
Path inputPath = new Path(args[0]);
TextInputFormat.setInputPaths(job,inputPath);
//Map: configure map
job.setMapperClass(MrMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
//Reduce: configure reduce
job.setReducerClass(MrReduce.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
//Output: configure output
Path outputPath = new Path(args[1]);
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true) ? 0 : -1;
}
//Program entry, call run
public static void main(String[] args) throws Exception {
//Used to manage all configurations of the current program
Configuration conf = new Configuration();
//Configure Map output results to be compressed into Snappy format
conf.set("mapreduce.map.output.compress","true");
conf.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
//Configure the compression of Reduce output results into Snappy format
conf.set("mapreduce.output.fileoutputformat.compress","true");
conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
//Call the run method to submit and run the Job
int status = ToolRunner.run(conf, new MRMapOutputSnappy(), args);
System.exit(status);
}
/**
* Define Mapper class
*/
public static class MrMapper extends Mapper<LongWritable, Text, NullWritable, Text>{
private NullWritable outputKey = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Direct output of each data
context.write(this.outputKey,value);
}
}
/**
* Define Reduce class
*/
public static class MrReduce extends Reducer<NullWritable, Text,NullWritable, Text> {
@Override
protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//Direct output of each data
for (Text value : values) {
context.write(key, value);
}
}
}
}
4. Read Snappy compressed file
1. Requirements: read the Snappy file generated in the previous step and restore it to a normal text file
2. Ideas:
- Input read Snappy file
- Direct output of Map and Reduce
Output outputs directly to the normal text type
3. Code:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRReadSnappy * @Description TODO Read the data in Snappy format and restore it to a normal text file */ public class MRReadSnappy extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { //Build Job Job job = Job.getInstance(this.getConf(),this.getClass().getSimpleName()); job.setJarByClass(MRReadSnappy.class); //Input: configuration input Path inputPath = new Path(args[0]); TextInputFormat.setInputPaths(job,inputPath); //Map: configure map job.setMapperClass(MrMapper.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); //Reduce: configure reduce job.setReducerClass(MrReduce.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); //Output: configure output Path outputPath = new Path(args[1]); TextOutputFormat.setOutputPath(job,outputPath); return job.waitForCompletion(true) ? 0 : -1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); //Call the run method to submit and run the Job int status = ToolRunner.run(conf, new MRReadSnappy(), args); System.exit(status); } /** * Define Mapper class */ public static class MrMapper extends Mapper<LongWritable, Text, NullWritable, Text>{ private NullWritable outputKey = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Direct output of each data context.write(this.outputKey,value); } } /** * Define Reduce class */ public static class MrReduce extends Reducer<NullWritable, Text,NullWritable, Text> { @Override protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //Direct output of each data for (Text value : values) { context.write(key, value); } } } }5, Lzo compression
1. Configure Hadoop to support Lzo
Hadoop itself does not support LZO compression. It needs to be installed separately, and LZO compression algorithm support is added during compilation. For the compilation process, please refer to the compilation manual Apache Hadoop 3-1-3 compilation, installation and deployment LZO compression guide.
After compilation, please implement the following configuration to make the current Hadoop support Lzo compression- Add lzo support jar package
cp hadoop-lzo-0.4.21-SNAPSHOT.jar /export/server/hadoop-3.1.4/share/hadoop/common/
- Synchronize to all nodes
cd /export/server/hadoop-3.1.4/share/hadoop/common/ scp hadoop-lzo-0.4.21-SNAPSHOT.jar node2:$PWD scp hadoop-lzo-0.4.21-SNAPSHOT.jar node3:$PWD
- Modify core-site.xml
<property> <name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property>
- Synchronize core-site.xml to all other nodes
cd /export/server/hadoop-3.1.4/etc/hadoop scp core-site.xml node2:$PWD scp core-site.xml node3:$PWD
- Restart Hadoop cluster
2. Generate Lzo compressed file
1. Requirements: read ordinary text files and generate Lzo compression result files
2. Ideas
- Read normal text file
- Direct output of Map and Reduce
Configure Output compression to Lzo type
3. Code development
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRWriteLzo * @Description TODO Read ordinary file data and compress the data in Lzo format */ public class MRWriteLzo extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { //Build Job Job job = Job.getInstance(this.getConf(),this.getClass().getSimpleName()); job.setJarByClass(MRWriteLzo.class); //Input: configuration input Path inputPath = new Path(args[0]); TextInputFormat.setInputPaths(job,inputPath); //Map: configure map job.setMapperClass(MrMapper.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); //Reduce: configure reduce job.setReducerClass(MrReduce.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); //Output: configure output Path outputPath = new Path(args[1]); TextOutputFormat.setOutputPath(job,outputPath); return job.waitForCompletion(true) ? 0 : -1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); //Configure the output results to be compressed into Lzo format conf.set("mapreduce.output.fileoutputformat.compress","true"); conf.set("mapreduce.output.fileoutputformat.compress.codec","com.hadoop.compression.lzo.LzopCodec"); //Call the run method to submit and run the Job int status = ToolRunner.run(conf, new MRWriteLzo(), args); System.exit(status); } /** * Define Mapper class */ public static class MrMapper extends Mapper<LongWritable, Text, NullWritable, Text>{ private NullWritable outputKey = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Direct output of each data context.write(this.outputKey,value); } } /** * Define Reduce class */ public static class MrReduce extends Reducer<NullWritable, Text,NullWritable, Text> { @Override protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //Direct output of each data for (Text value : values) { context.write(key, value); } } } }3. Read Lzo compressed file
1. Requirements: read Lzo compressed file and restore it to normal text file
2. Code development
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRReadLzo * @Description TODO Read the data in Lzo format and restore it to a normal text file */ public class MRReadLzo extends Configured implements Tool { //Build, configure, and submit a MapReduce Job public int run(String[] args) throws Exception { //Build Job Job job = Job.getInstance(this.getConf(),this.getClass().getSimpleName()); job.setJarByClass(MRReadLzo.class); //Input: configuration input Path inputPath = new Path(args[0]); TextInputFormat.setInputPaths(job,inputPath); //Map: configure map job.setMapperClass(MrMapper.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); //Reduce: configure reduce job.setReducerClass(MrReduce.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); //Output: configure output Path outputPath = new Path(args[1]); TextOutputFormat.setOutputPath(job,outputPath); return job.waitForCompletion(true) ? 0 : -1; } //Program entry, call run public static void main(String[] args) throws Exception { //Used to manage all configurations of the current program Configuration conf = new Configuration(); //The configuration output results are compressed into Gzip format // conf.set("mapreduce.output.fileoutputformat.compress","true"); // conf.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.GzipCodec"); //Call the run method to submit and run the Job int status = ToolRunner.run(conf, new MRReadLzo(), args); System.exit(status); } /** * Define Mapper class */ public static class MrMapper extends Mapper<LongWritable, Text, NullWritable, Text>{ private NullWritable outputKey = NullWritable.get(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Direct output of each data context.write(this.outputKey,value); } } /** * Define Reduce class */ public static class MrReduce extends Reducer<NullWritable, Text,NullWritable, Text> { @Override protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //Direct output of each data for (Text value : values) { context.write(key, value); } } } }