Catalog
II. Running in Hadoop environment
Zero, code Xian inspirational
I. running in Linux
First, create the following directory in Linux, do not put anything in it, and then enter the directory
/home/hadoopuser/mydoc/py

Then create a ddd.txt file in it

Write the following in it
aaa bbb aaa bbb ddd ccc ddd

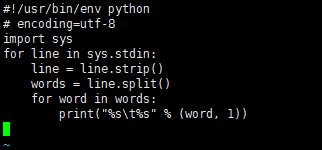
Then create a new mapper.py file

Write the following in it
#!/usr/bin/env python
# encoding=utf-8
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\t%s" % (word, 1))
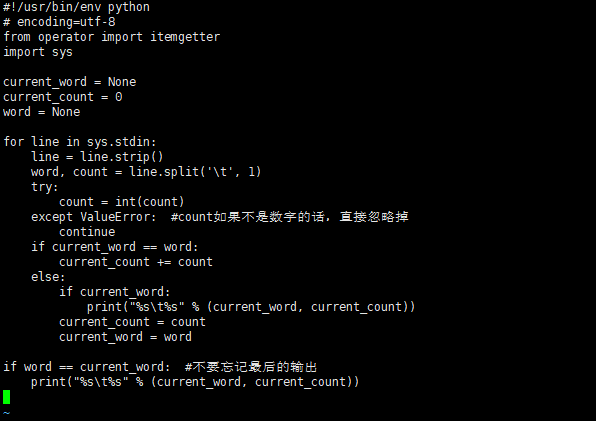
Then create a new reduce.py file

Write the following in it
#!/usr/bin/env python
# encoding=utf-8
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: #If count is not a number, ignore it directly
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\t%s" % (current_word, current_count))
current_count = count
current_word = word
if word == current_word: #Don't forget the last output
print("%s\t%s" % (current_word, current_count))
There are three files at this time

Then add execution permission to mapper.py
chmod 777 mapper.py

Then add execute permission to reduce.py
chmod 777 reduce.py

Let's start running
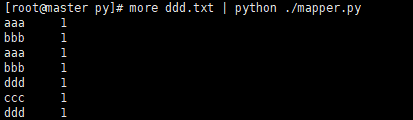
mapper.py program running
more ddd.txt | python ./mapper.py
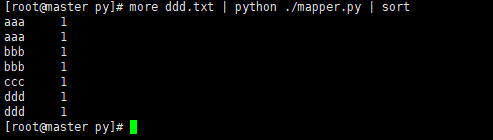
Sort operation
more ddd.txt | python ./mapper.py | sort
more ddd.txt | python ./mapper.py | sort -k1,1
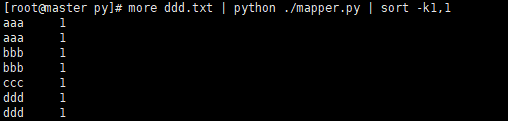
Two programs running at the same time
more ddd.txt | python ./mapper.py | sort -k1,1 | ./reduce.py

II. Running in Hadoop environment
Create a new run.sh file in this directory
The contents are as follows
hadoop jar /opt/hadoop/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.5.jar \ -file /home/hadoopuser/mydoc/py/mapper.py -mapper /home/hadoopuser/mydoc/py/mapper.py \ -file /home/hadoopuser/mydoc/py/reduce.py -reducer /home/hadoopuser/mydoc/py/reduce.py \ -input /tmp/py/input/* -output /tmp/py/output

The first line configures the location of hadoop-streaming-2.7.5.jar, which can be modified according to your specific situation
My environment is based on the following blog
Then add executable permissions to run.sh
chmod 777 run.sh

Then create a new folder in the hdfs environment
hdfs dfs -mkdir -p /tmp/py/input

Then upload ddd.txt
hdfs dfs -put ddd.txt /tmp/py/input

Then run run run.sh
source run.sh
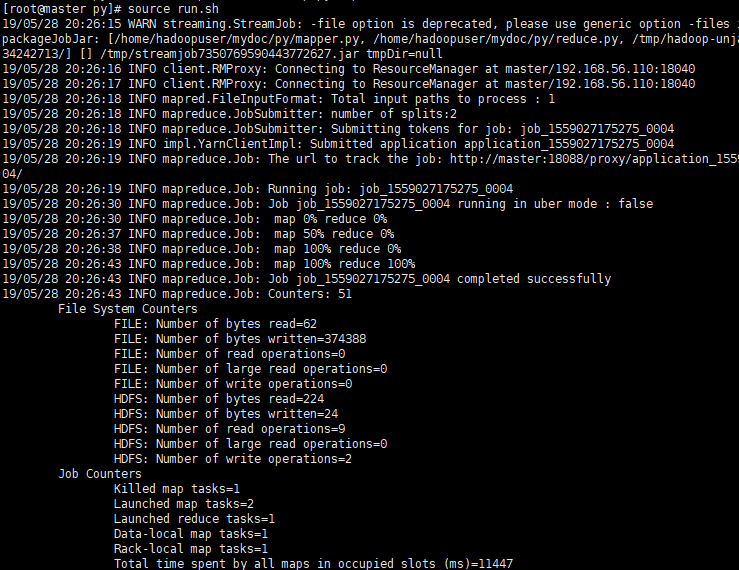
Then look at the generated file
hdfs dfs -ls /tmp/py/output

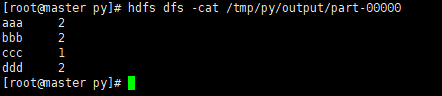
part-00000 is the operation result. Open it and have a look
hdfs dfs -cat /tmp/py/output/part-00000
Then save the running results locally
hdfs dfs -get /tmp/py/output/part-00000 /home/hadoopuser/mydoc/py

Check whether it is saved successfully
