Three components
- JobClient (prepare to run environment)
- JobTracker (receive job)
- TaskTracker (initialize job)
Note that this is written in version 1.x and Hadoop 2. X and is managed by yarn. There are no JobTracker and TaskTracker
Comparison between old and new Hadoop MapReduce frameworks
1. The client remains unchanged, and most of its call API s and interfaces remain compatible. This is also to make the development user transparent and do not need to make major changes to the original code. However, the JobTracker and TaskTracker of the original framework are missing and replaced by the three parts of ResourceManager, applicationmaster and nodemanager.
2. Resource manager is a central service that schedules and starts the Application Master to which each Job belongs, and monitors the existence of the Application Master. The monitoring, restart and other contents of the task in the Job are missing, which is why the ApplicationMaster exists. The ResourceManager is responsible for scheduling jobs and resources, receiving jobs submitted by the JobSubmitter, starting the scheduling process according to the Job context information and the status information collected from the NodeManager, and assigning a Container as the Application Master
3. NodeManager has a specific function, that is, it is responsible for maintaining the Container status and maintaining the heartbeat to RM.
4. The ApplicationMaster is responsible for all work in the life cycle of a Job, similar to the JobTracker in the old framework, but note that every Job (not every Job) has an ApplicationMaster, which can run on machines other than the resource manager
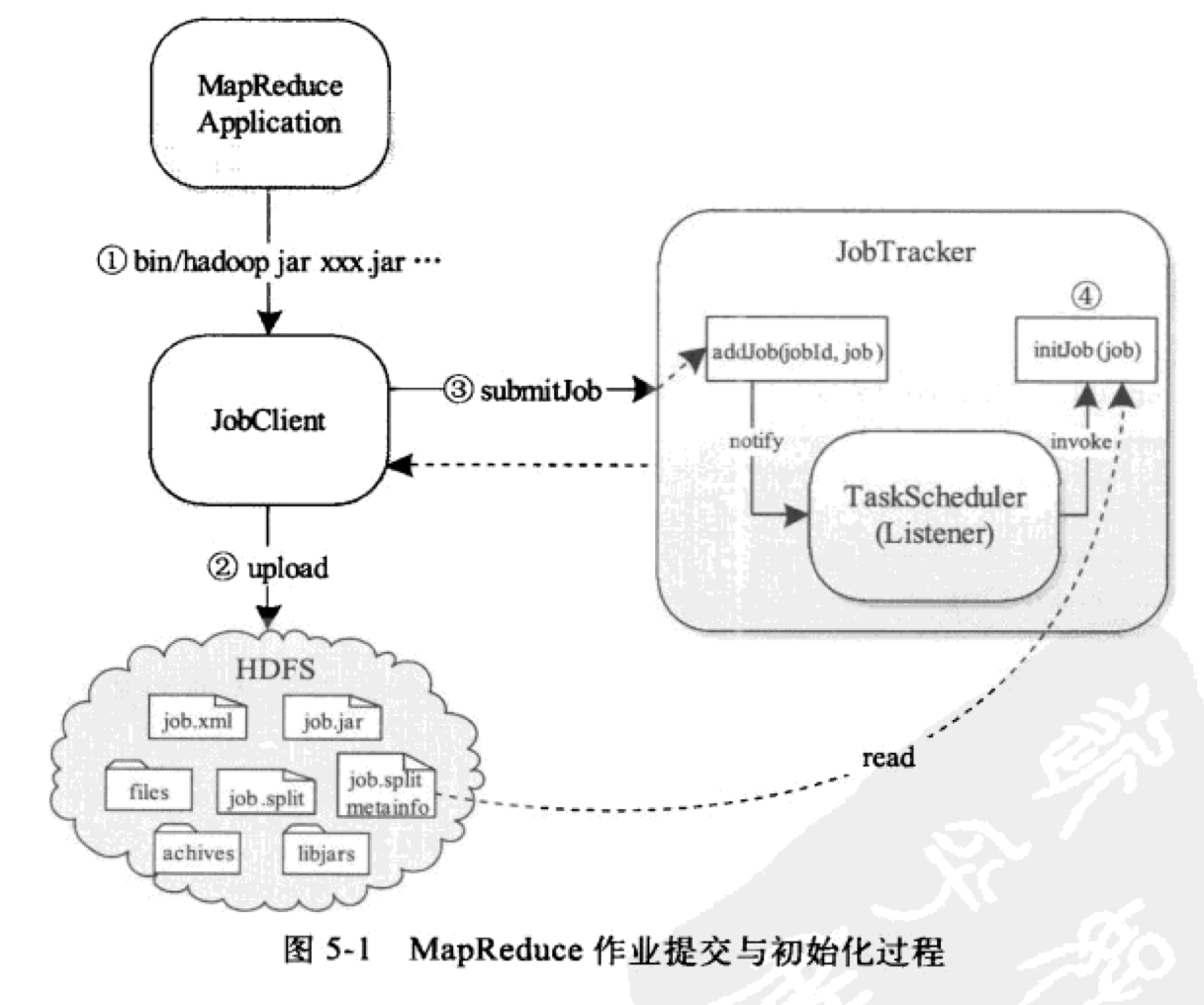
Four steps
- User submitted job
- JobClient uploads the files required for job operation to a directory in the JobTracker file system (usually HDFS, and the files in HDFS are shared by all nodes) according to the job configuration information (Jobconf)
- JobClient calls RPC interface to submit job to JobTracker
- After receiving the job, JobTracker informs the TaskScheduler of it, and the TaskScheduler initializes the job
Specific details
Job submission process
Execute shell commands
After the user writes the program, it is packaged into a jar package, and then executes the jar command to submit the job to the RunJar class for processing. After decompressing the jar package and setting the environment variables, the main function in the RunJar class passes the operation parameters to the MapReduce program and runs it.
/**
* Unpack a jar file into a directory.
*
* This version unpacks all files inside the jar regardless of filename.
*
* @param jarFile the .jar file to unpack
* @param toDir the destination directory into which to unpack the jar
*
* @throws IOException if an I/O error has occurred or toDir
* cannot be created and does not already exist
*/
public static void unJar(File jarFile, File toDir) throws IOException {
unJar(jarFile, toDir, MATCH_ANY);
}
/**
* Creates a classloader based on the environment that was specified by the
* user. If HADOOP_USE_CLIENT_CLASSLOADER is specified, it creates an
* application classloader that provides the isolation of the user class space
* from the hadoop classes and their dependencies. It forms a class space for
* the user jar as well as the HADOOP_CLASSPATH. Otherwise, it creates a
* classloader that simply adds the user jar to the classpath.
*/
private ClassLoader createClassLoader(File file, final File workDir)
throws MalformedURLException {
ClassLoader loader;
// see if the client classloader is enabled
if (useClientClassLoader()) {
StringBuilder sb = new StringBuilder();
sb.append(workDir).append("/").
append(File.pathSeparator).append(file).
append(File.pathSeparator).append(workDir).append("/classes/").
append(File.pathSeparator).append(workDir).append("/lib/*");
// HADOOP_CLASSPATH is added to the client classpath
String hadoopClasspath = getHadoopClasspath();
if (hadoopClasspath != null && !hadoopClasspath.isEmpty()) {
sb.append(File.pathSeparator).append(hadoopClasspath);
}
String clientClasspath = sb.toString();
// get the system classes
String systemClasses = getSystemClasses();
List<String> systemClassesList = systemClasses == null ?
null :
Arrays.asList(StringUtils.getTrimmedStrings(systemClasses));
// create an application classloader that isolates the user classes
loader = new ApplicationClassLoader(clientClasspath,
getClass().getClassLoader(), systemClassesList);
} else {
List<URL> classPath = new ArrayList<>();
classPath.add(new File(workDir + "/").toURI().toURL());
classPath.add(file.toURI().toURL());
classPath.add(new File(workDir, "classes/").toURI().toURL());
File[] libs = new File(workDir, "lib").listFiles();
if (libs != null) {
for (File lib : libs) {
classPath.add(lib.toURI().toURL());
}
}
// create a normal parent-delegating classloader
loader = new URLClassLoader(classPath.toArray(new URL[classPath.size()]));
}
return loader;
}
The user's MapReduce program configuring all kinds of information (Mapper class, Reduce class, Reduce Task number, etc.) of the job runtime. Finally, the JobClient.runJob function is called in the main function to submit the job, and the operation is submitted to the JobTracker end.
/**
* Utility that submits a job, then polls for progress until the job is
* complete.
* Submit the job, and then poll the progress until the job is completed
* @param job the job configuration.
* @throws IOException if the job fails
*/
public static RunningJob runJob(JobConf job) throws IOException {
JobClient jc = new JobClient(job);
RunningJob rj = jc.submitJob(job);
try {
if (!jc.monitorAndPrintJob(job, rj)) {
throw new IOException("Job failed!");
}
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
return rj;
}
/**
* Submit a job to the MR system.
* This returns a handle to the {@link RunningJob} which can be used to track
* the running-job.
* Submit a job to the MR system. This will return a handle to {@ link RunningJob} that can be used to track running jobs.
* @param conf the job configuration.
* @return a handle to the {@link RunningJob} which can be used to track the
* running-job.
* @throws FileNotFoundException
* @throws IOException
*/
public RunningJob submitJob(final JobConf conf) throws FileNotFoundException,
IOException {
return submitJobInternal(conf);
}
public RunningJob submitJobInternal(final JobConf conf)
throws FileNotFoundException, IOException {
try {
conf.setBooleanIfUnset("mapred.mapper.new-api", false);
conf.setBooleanIfUnset("mapred.reducer.new-api", false);
Job job = clientUgi.doAs(new PrivilegedExceptionAction<Job> () {
@Override
public Job run() throws IOException, ClassNotFoundException,
InterruptedException {
Job job = Job.getInstance(conf);
job.submit();
return job;
}
});
Cluster prev = cluster;
// update our Cluster instance with the one created by Job for submission
// (we can't pass our Cluster instance to Job, since Job wraps the config
// instance, and the two configs would then diverge)
cluster = job.getCluster();
// It is important to close the previous cluster instance
// to cleanup resources.
if (prev != null) {
prev.close();
}
return new NetworkedJob(job);
} catch (InterruptedException ie) {
throw new IOException("interrupted", ie);
}
}
Job file upload
Before submitting a job to the JobTracker side, JobClent needs to initialize, including obtaining the job ID, creating the HDFS directory, uploading the job file and generating the Split file. These tasks are implemented by submitJobInternal(job).
The upload and download of MapReduce job files are completed by the DistributedCache tool, and the whole workflow is transparent to users. The files are submitted to HDFS on the JobClient side.
Generate InputSplit file
After submitting MapReduce job, JobClient will call getSplits method of InputFormat to generate InputSplit related information, which includes two parts:
- InputSplit metadata information: used by JobTracker to generate data structures related to Task locality
- The original InputSplit information is used when the Map Task is initialized to obtain the data to be processed
InputSplit operation mainly includes three classes: JobSplit, JobSplitWriter and SplitMetaInfoReader
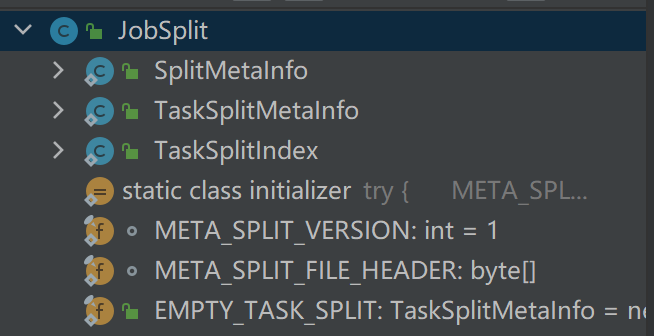
JobSplit encapsulates the basic classes related to reading and writing InputSplit, as shown in the above figure
SplitMetaInfo: saved in the file job.splitmetainfo. When initializing the JobTracker side, you need to read this file to create a MapTask
/**
* This represents the meta information about the task split.
* The main fields are
* - start offset in actual split
* - data length that will be processed in this split
* - hosts on which this split is local
* This represents meta information about task splitting. The main fields are - starting offset in actual splitting - length of data to be processed in this splitting - host where this splitting is located
*/
public static class SplitMetaInfo implements Writable {
private long startOffset;
private long inputDataLength;
private String[] locations;
public SplitMetaInfo() {}
public SplitMetaInfo(String[] locations, long startOffset,
long inputDataLength) {
this.locations = locations;
this.startOffset = startOffset;
this.inputDataLength = inputDataLength;
}
public SplitMetaInfo(InputSplit split, long startOffset) throws IOException {
try {
this.locations = split.getLocations();
this.inputDataLength = split.getLength();
this.startOffset = startOffset;
} catch (InterruptedException ie) {
throw new IOException(ie);
}
}
TaskSplitMetaInfo: the data structure that holds the InputSplit meta information. This information is obtained by JobTracker from the file job.splitmetainfo when the job is initialized. The host list is an important factor for the task scheduler to judge whether the task is local. The splitIndex information holds the index of the data location information to be processed by the new task in the file job.split, which is received by TaskTracker After receiving this message, you can read the InputSplit information from the job.split file and run a new task.
/**
* This represents the meta information about the task split that the
* JobTracker creates
*/
public static class TaskSplitMetaInfo {
private TaskSplitIndex splitIndex; //Location of Split meta information in job.split file
private long inputDataLength; //Data length of InputSplit
private String[] locations;//List of host s where InputSplit is located
public TaskSplitMetaInfo(){
this.splitIndex = new TaskSplitIndex();
this.locations = new String[0];
}
public TaskSplitMetaInfo(TaskSplitIndex splitIndex, String[] locations,
long inputDataLength) {
this.splitIndex = splitIndex;
this.locations = locations;
this.inputDataLength = inputDataLength;
}
public TaskSplitMetaInfo(InputSplit split, long startOffset)
throws InterruptedException, IOException {
this(new TaskSplitIndex("", startOffset), split.getLocations(),
split.getLength());
}
public TaskSplitMetaInfo(String[] locations, long startOffset,
long inputDataLength) {
this(new TaskSplitIndex("",startOffset), locations, inputDataLength);
}
public TaskSplitIndex getSplitIndex() {
return splitIndex;
}
public String getSplitLocation() {
return splitIndex.getSplitLocation();
}
public long getInputDataLength() {
return inputDataLength;
}
public String[] getLocations() {
return locations;
}
public long getStartOffset() {
return splitIndex.getStartOffset();
}
}
TaskSplitIndex: when jobtracker assigns a new task to TaskTracker, TaskSplitIndex is used to specify the index of the pending data location information of the new task in the job.split file.
/**
* This represents the meta information about the task split that the
* task gets
*/
public static class TaskSplitIndex {
private String splitLocation; //Location of the job.split file
private long startOffset;//Location of InputSplit information in the job.split file
public TaskSplitIndex(){
this("", 0);
}
public TaskSplitIndex(String splitLocation, long startOffset) {
this.splitLocation = splitLocation;
this.startOffset = startOffset;
}
public long getStartOffset() {
return startOffset;
}
public String getSplitLocation() {
return splitLocation;
}
public void readFields(DataInput in) throws IOException {
splitLocation = Text.readString(in);
startOffset = WritableUtils.readVLong(in);
}
public void write(DataOutput out) throws IOException {
Text.writeString(out, splitLocation);
WritableUtils.writeVLong(out, startOffset);
}
}
Submit job to JobTracker
JobClient calls the RPC method submitJob to submit the job to JobTracker. In JobTracker.submitJob, perform the following operations in turn (because I see the source code of Hadoop 2. X, I won't put the source code in this part):
- Create JobInProgress object for the job: this object maintains the runtime information of the job and is mainly used to track the running status and progress of the running job.
- Check whether the user has the job submission permission of the specified queue: Hadoop manages jobs and resources by queue. Each queue is allocated with a certain amount of resources. Each user belongs to one or more queues and uses the resources in the queue intelligently.
- Check whether the memory usage of job configuration is reasonable
- Notify TaskScheduler to initialize the job: JobTracker will not initialize the job immediately after receiving it, but will hand it over to the scheduler to initialize the job according to certain policies.
JobTracker uses the observer design pattern to tell TsakTracker of the event "submit new job"
Job initialization process
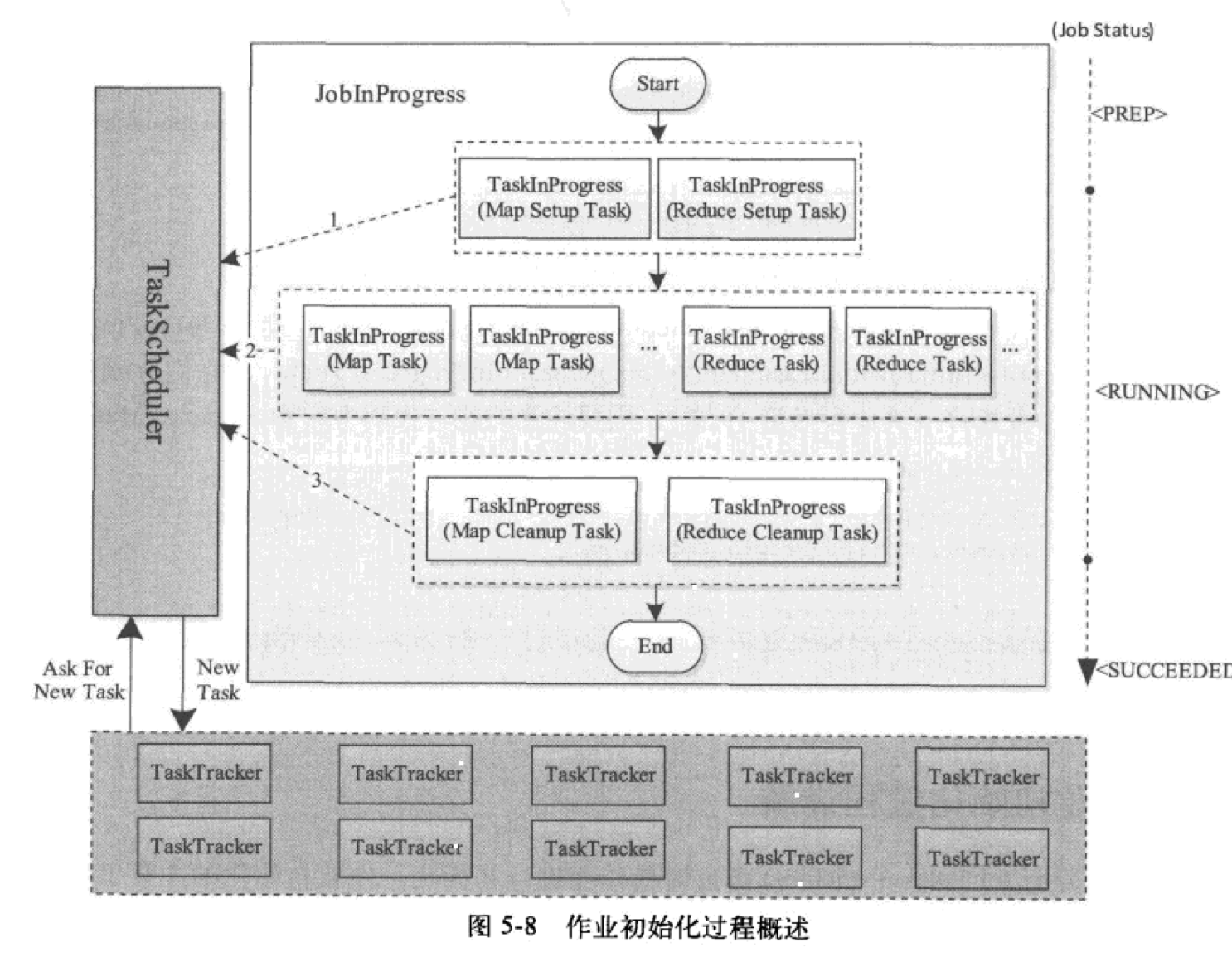
The main work of initialization is to construct Map Task and Reduce Task and initialize them.
Hadoop decomposes each job into four types of tasks: Setup Task, Map Task, Reduce Task and Cleanup Task
Their runtime information is maintained by the TaskInProgress class, so creating these tasks is actually creating TaskInProgress objects.
Setup Task: an identifying task for job initialization.
Do a simple initialization task. After the task is completed, start running Map Task. This type of task is divided into Map Setup Task and Reduce Setup Task. Each job has one. When running, it occupies one Map Slot and Reduce Slot respectively. The functions of these two tasks are the same, and only one runs at the same time.
Map Task: the task of processing data in the map phase. Its number and corresponding processing data fragments are determined by the InputFormat of the application.
Reduce Task: the number of data processing tasks in the reduce phase is specified by the user through the parameter mapred.reduce.tasks. Hadoop will only schedule map tasks at first, and will not start scheduling reduce tasks until the number of map tasks reaches a certain proportion (5% by default)
Cleanup Task: an identifying task at the end of a job to complete job cleaning, such as deleting some temporary directories used in the job RUNNING process. After the task is completed, the job changes from RUNNING status to SUCCEEDED status.