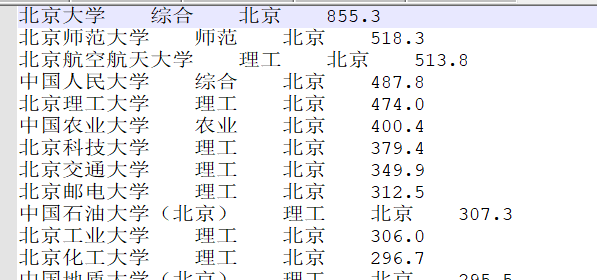
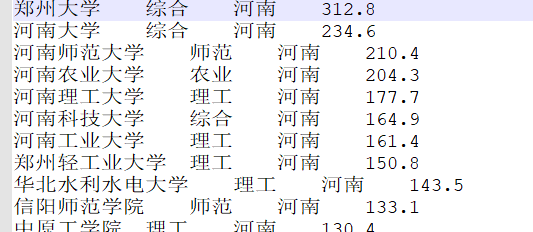
Ranking statistics of Chinese Universities Based on MapReduce
Overall thinking
① Fileinputformat reads data
② Mapper stage is simple for data processing
③ Serialization implements custom sorting
④ Partition partition processing
⑤ Reducer writes out data
⑥ Main class settings
The specific implementation is as follows
Driver main class, including loading jar package path, setting Mapper and Reducer classes, output type, partition partition setting, file input and output path, etc. note that the number of reductions set during partition partition should be consistent with the number of partitions. If it is more or less, an error will be reported, resulting in the stop of Map Reduce program.
public class RankDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// Get job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// Load main class
job.setJarByClass(RankDriver.class);
// Set Mapper and Reducer classes
job.setMapperClass(RankMapper.class);
job.setReducerClass(RankReducer.class);
// Sets the data type of Mapper data
job.setMapOutputKeyClass(RankBean.class);
job.setMapOutputValueClass(Text.class);
// Set the data type of the final data
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(RankBean.class);
// Set Partition and number of partitions
job.setPartitionerClass(RankPartitioner.class);
job.setNumReduceTasks(6);
// File input / output path
FileInputFormat.setInputPaths(job, new Path("E:\\test\\data\\*"));
FileOutputFormat.setOutputPath(job, new Path("E:\\test\\RankTopKOut"));
// Submit job
boolean result = job.waitForCompletion(true);
// End of judgment
System.exit(result ? 0 : 1);
}
}
For Bean object serialization class, pay attention to the following points
① Implement the WritableComparable interface and pass in the comparison object. Generally speaking, the comparison object is itself.
② Set null argument constructor
③ Rewrite serialization methods (write and readFields)
④ Override the compareTo method, and the method body is used to implement custom sorting
⑤ Override the toString method for the final data write out.
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class RankBean implements WritableComparable<RankBean> {
private String module; // School type
private double score; // School score
private String position; // School location
public RankBean() {
}
public String getModule() {
return module;
}
public void setModule(String module) {
this.module = module;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public String getPosition() {
return position;
}
public void setPosition(String position) {
this.position = position;
}
@Override
public int compareTo(RankBean o) {
if (this.score > o.score) {
return -1;
}else if (this.score < o.score) {
return 1;
}else {
return 0;
}
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(module);
out.writeDouble(score);
out.writeUTF(position);
}
@Override
public void readFields(DataInput in) throws IOException {
this.module = in.readUTF();
this.score = in.readDouble();
this.position = in.readUTF();
}
@Override
public String toString() {
return module + "\t" + position + "\t" + score ;
}
}
Mapper class implements data reading, processing and writing operations. When writing out operations, in order to realize custom sorting, outKey means that the written key must be an object and serialized to realize custom sorting. Otherwise, the underlying logic of MapReduce will automatically sort the output keys in the way of fast scheduling, such as wordCount program.
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class RankMapper extends Mapper<LongWritable, Text, RankBean, Text> {
private RankBean outK = new RankBean();
private Text outV = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\t");
// Get corresponding data by segmentation
String name = split[0];
String position = split[1];
String mold = split[2];
String score = split[3];
// Store data
outV.set(name);
outK.setModule(mold);
outK.setPosition(position);
outK.setScore(Double.parseDouble(score));
// Write data
context.write(outK,outV);
}
}
Partition partition class, which realizes the partition merging of different fields and finally stores the data in different files. The specific implementation steps are as follows:
① Inherit the Partitioner class, and the generic type is Mapper's data type
② Rewrite getPartition method to realize partition
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class RankPartitioner extends Partitioner<RankBean, Text> {
@Override
public int getPartition(RankBean rankBean, Text text, int numPartitions) {
int partition;
if ("Beijing".equals(rankBean.getPosition())) {
partition = 0;
}else if ("Shanghai".equals(rankBean.getPosition())) {
partition = 1;
}else if ("Tianjin".equals(rankBean.getPosition())) {
partition = 2;
}else if ("Jiangsu".equals(rankBean.getPosition())) {
partition = 3;
}else if ("Henan".equals(rankBean.getPosition())) {
partition = 4;
}else {
partition = 5;
}
return partition;
}
}
The Reducer class implements the write out operation of data.
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class RankReducer extends Reducer<RankBean, Text, Text, RankBean> {
@Override
protected void reduce(RankBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value,key);
}
}
}
So far, the ranking of Chinese universities has been written into different documents according to the zoning of key provinces. The final output is shown below.